| 20.文献阅读笔记 |
||
| 简介 |
题目 |
Online Tracking by Learning Discriminative Saliency Map with Convolutional Neural Network |
| 作者 |
Seunghoon Hong, Tackgeun You, Suha Kwak, Bohyung Han |
|
| 原文链接 |
arXiv:1502.06796. |
|
| 关键词 |
online visual tracking algorithm |
|
| 研究问题 |
离线分类器在概念上不适合视觉跟踪,并且由于网络规模大和缺乏训练数据,基于CNN的在线学习并不简单。 从深层结构提取的特征可能不适合用于视觉跟踪,因为从顶层提取的视觉特征编码了语义信息,总体上表现出相对较差的定位性能。 |
|
| 研究方法 |
learning discriminative saliency map using Convolutional Neural Network 使用cnn学习可区分的显著性地图 Offline:Given a CNN pre-trained on a large-scale image repository 线下:cnn预训练大规模图片库 takes outputs from hidden layers of the network as feature descriptors 隐藏层的输出作为特征描述 Online:The features are used to learn discriminative target appearance models using an online Support Vector Machine (SVM). 线上:用SVM判别隐藏层得到的特征 construct target-specific saliency map by backpropagating CNN features with guidance of the SVM 在svm的指导下通过cnn反向传播构建可区分的显著性地图 and obtain the final tracking result in each frame based on the appearance model generatively constructed with the saliency map. 基于生成式模型构建的可区分的显著性地图将检测出的跟踪结果表现在每一帧里。 |
|
| 研究结论 |
目标定位精度提升;实现了像素级别的分割。 |
|
| 创新不足 |
网络架构比较老,精度和速度应该比较一般。 使用的网络是浅层的,因为使用有限数量的训练样本学习深度网络是具有挑战性的,并且算法未能利用从深度CNN中提取的丰富信息。 |
|
| 额外知识 |
目标跟踪的成功取决于目标外观表示的稳定性。 因此目标外观建模取得了积极研究。 可分为生成式和判别式模型。 生成式模型: sparse representation:稀疏表示 online density estimation:在线密度估计 incremental subspace learning:增量子空间学习 判别式模型:学习一个分类器将目标从背景中区分出来。 online boosting、multiple instance learning、structured support vector machine、online random forest 过于依赖人工设计的特征:template, Haar-like features, histogram features这些特征都过于简单所以不能应对视频中有序信息的挑战。 |
|
| 21.文献阅读笔记 |
||
| 简介 |
题目 |
DeepTrack: Learning Discriminative Feature Representations Online for Robust Visual Tracking |
| 作者 |
Hanxi Li, Yi Li, Fatih Porikli |
|
| 原文链接 |
arXiv:1503.00072. |
|
| 关键词 |
Object tracking algorithm |
|
| 研究问题 |
Object tracking algorithm |
|
| 研究方法 |
使用单个卷积神经网络( CNN )来学习目标对象的有效特征表示,以纯粹的在线方式。 方式:我们采用了一种基于检测的跟踪策略:一个四层的CNN模型来区分目标物体和周围的背景。我们的CNN对给定帧中物体位置(物体状态)的所有可能假设生成分数。然后选择得分最高的假设作为当前帧中物体状态的预测。我们以纯粹的在线方式更新这个CNN模型。也就是说,所提出的跟踪器只基于感兴趣目标的视频帧进行学习,不需要额外的信息或离线训练。 随机梯度下降法:优化cnn参数 应对偶尔检测到的假阳性:temporal sampling mechanism时间采样机制。object patches停留时间比background时间长。 目标位置的不确定性看作是标签噪声问题。 建议在时间变量(帧索引)和样本类的联合分布中对训练数据进行抽样。在这里,计算样本类的条件概率,给定帧索引,基于该帧中跟踪质量的新度量。 使用多个图像线索(低级图像特征,如归一化灰度图像和图像梯度)作为独立通道作为网络输入 通过迭代地独立训练每个通道来更新CNN参数,然后在融合层上进行联合训练,该融合层替换来自多个通道的最后一个完全连接层。 cnn模型只有在物体发生重大外观变化时才会更新。 |
|
| 研究结论 |
introduce a novel truncated structural loss function:引进新的截断损失函数。保持更多样本损失并且减少累积误差。 增强了CNN训练中的普通随机梯度下降方法:通过稳健的样本选择机制。采样机制从不同的时间分布中随机产生正负样本,这些样本是通过考虑时间关系和标签噪声而产生的。 为CNN训练设计了一种懒惰但有效的更新方案:对视觉跟踪中长期存在的一些困难如遮挡或错误检测具有鲁棒性,而不会丢失对显著外观变化的有效适应。 超过了所有比较的先进方法。 |
|
| 创新不足 |
还没看出来 |
|
| 额外知识 |
drift problem:偏移问题。之所以会产生这个问题是因为干扰不足也就是负样本不足,造成网络对目标和背景没有很高的辨别能力。这里告诉我们负样本对于训练也很重要。 |
|
| 22.文献阅读笔记 |
||
| 简介 |
题目 |
Learning a Deep Compact Image Representation for Visual Tracking |
| 作者 |
N Wang, DY Yeung |
|
| 原文链接 |
Learning a Deep Compact Image Representation for Visual Tracking (neurips.cc) |
|
| 关键词 |
Object tracking、DLT、SDAE |
|
| 研究问题 |
tracking the trajectory of a moving object in a video with possibly very complex background 在尽可能复杂背景的视频中跟踪目标的移动轨迹 |
|
| 研究方法 |
DLT:deep learning tracker 试图结合生成性跟踪器和判别性跟踪器的思想,开发一个鲁棒的判别性跟踪器。 更强调无监督的特征学习问题; Specifically, by using auxiliary natural images, we train a stacked denoising autoencoder (SDAE) offline to learn generic image features that are more robust against variations. 通过使用辅助的自然图像,我们离线训练一个堆叠的去噪自编码器,以学习对变化更稳定的通用图像特征。 This is then followed by knowledge transfer from offline training to the online tracking process. 随后是知识转移从线下培训到线上跟踪的过程。 Online tracking involves a classification neural network which is constructed from the encoder part of the trained autoencoder as a feature extractor and an additional classification layer. 在线跟踪涉及一个分类神经网络,该网络由训练好的自编码器的编码器部分作为特征提取器和一个额外的分类层构建而成。 Both the feature extractor and the classifier can be further tuned to adapt to appearance changes of the moving object. 特征提取器和分类器都可以进行进一步的调整以适应移动对象的外观变化。 |
|
| 研究结论 |
相比其他跟踪器,在保持低计算成本和实时性的情况下更准确 |
|
| 创新不足 |
it would be an interesting direction to investigate a shift-variant CNN. 目前的跟踪器中的分类层只是一个线性分类器。将其扩展到更强大的分类器中,就像在其他判别跟踪器中一样,可能会为进一步的性能提升提供更大的空间。 |
|
| 额外知识 |
生成式和判别式方法: 生成式:假设被跟踪的对象可以用某种生成式过程来描述,因此跟踪相当于在可能无限多的候选对象中找到最可能的候选对象。关键是开发更加稳定的图像表示。 灵感来源于robust estimation and sparse coding,such as the alternating direction method of multipliers (ADMM) and accelerated gradient methods。Some popular generative trackers include incremental visual tracking (IVT) , which represents the tracked object based on principal component analysis (PCA), and the l1 tracker (L1T)。 判别式:判别式方法将跟踪视为一个二分类问题,学习将被跟踪对象与其背景明确区分开来。 Some representative trackers in this category are the online AdaBoost (OAB) tracker [6], multiple instance learning (MIL) tracker [3], and structured output tracker (Struck). 对比:由于使用了更丰富的图像表示,生成式跟踪器通常在较不复杂的环境下产生更准确的结果,而判别式跟踪器由于明确地将背景考虑在内,因此对强遮挡和变化具有更强的鲁棒性。 The particle filter framework:粒子滤波框架 一种基于序列观测值估计动力系统潜在状态变量的序贯蒙特卡洛重要性采样方法。它通过一组粒子来近似后验状态分布,而不仅仅是像模式这样的单点。对于视觉跟踪而言,这一特性使得跟踪器更容易从错误的跟踪结果中恢复 Kalman filter卡尔曼滤波: 比较先进的跟踪器:MTT, CT , VTD , MIL, a latest variant of L1T, TLD, and IVT. |
|
| 23.文献阅读笔记(分层卷积特征) |
||
| 简介 |
题目 |
Hierarchical Convolutional Features for Visual Tracking |
| 作者 |
Chao Ma, Jia-Bin Huang, Xiaokang Yang and Ming-Hsuan Yang |
|
| 原文链接 |
||
| 关键词 |
Hierarchical convolution、visual tracking |
|
| 研究问题 |
Tracking 难点:变形、突变运动、背景杂乱、遮挡。 较早的早期卷积层tracking:更精准的定位,但是对物体的改变并不稳定。不能捕获语义信息。所以使用多层CNN特征进行视觉跟踪的推理是非常重要的,因为语义对显著的外观变化具有鲁棒性,而空间细节对于精确定位是有效的。 问题1:使用神经网络作为在线分类器,其中只使用最后一层的输出来表示目标。对于高层视觉识别问题,使用来自最后一层的特征是有效的,因为它们与类别级别的语义最密切相关,并且对干扰变量(如类内变化和精确位置)最具有不变性。然而,视觉跟踪的目的是精确定位目标,而不是推断其语义类别。  问题2:训练样本的提取。训练一个鲁棒的分类器需要大量的正负样本,这在视觉跟踪中是不可能的。此外,由于在目标附近采样,正负样本高度相关,因此在确定决策边界时存在模糊性。 较早层的特征保留了更高的空间分辨率,以实现精确的定位,其低层视觉信息类似于Gabor滤波器的响应图。另一方面,后一层的特征捕获了更多的语义信息和更少的细粒度空间细节。 |
|
| 研究方法 |
将卷积层的层次结构解释为图像金字塔表示的非线性对应,并利用这些多层次的抽象来进行视觉跟踪。 早期特征缓解漂移问题(drifting):为了精准定位。 (ii)在每个CNN层上学习自适应相关滤波器,无需采样。 在每个卷积层上自适应地学习相关滤波器来对目标外观进行编码。分层推断每一层的最大响应来定位目标。缓解采样模糊问题。 我们采用由粗到精的方式,利用多级相关响应图来推断目标位置。  (iii)缓解采样二义性:将所有偏移版本的特征作为训练样本,回归到具有较小空间带宽的高斯函数,从而缓解训练二元判别分类器的采样二义性。 本文算法的主要步骤。给定一幅图像,首先裁剪以前一帧估计位置为中心的搜索窗口。使用第三,第四和第五卷积层作为我们的目标表示。然后,由i索引的每一层与学习到的线性相关滤波器w ( i )卷积生成响应图,其最大值的位置表示估计的目标位置。通过搜索多层响应图,以由粗到精的方式推断目标位置。 低的空间分辨率不足以对目标进行准确定位。通过双线性插值将每个特征图调整到固定的较大尺寸来缓解这一问题。 不使用池化层的输出,因为希望在每个卷积层上保留更多的空间分辨率。 |
|
| 研究结论 |
在准确性和鲁棒性方面优于现有的先进方法。 |
|
| 额外知识 |
optical flow:光流的概念是指在连续的两帧图像中由于图像中的物体移动或者摄像头的移动导致的图像中目标像素的移动。 光流法(optical flow methods) - 知乎 (zhihu.com) conv3 - 4层更有利于精确定位。 conv5 - 4层的空间分辨率较低。 |
|
| 24.文献阅读笔记(sel - CNN) |
||
| 简介 |
题目 |
Visual Tracking with Fully Convolutional Networks |
| 作者 |
Lijun Wang, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu |
|
| 原文链接 |
http://202.118.75.4/lu/Paper/ICCV2015/iccv15_lijun.pdf 【DeepLearning】简述Visual Tracking with Fully Convolutional Networks-CSDN博客 |
|
| 关键词 |
Visual Tracking、fcn、sel - CNN |
|
| 研究问题 |
顶层编码更抽象和更高层的语义特征,充当类别检测器,能够很好地区分不同类别的物体,对形变和遮挡具有很强的鲁棒性。 而下层携带更多的判别信息,能更好地将目标与外观相似的干扰目标分离,但是对外观的剧烈变化鲁棒性较差。
|
|
| 研究方法 |
we propose to automatically switch the usage of these two layers during tracking depending on the occurrence of distracters.
A feature map selection method is developed to remove noisy and irrelevant feature maps, which can reduce computation redundancy and improve tracking accuracy.
through proper feature selection, the noisy feature maps not related to the representation of the target are cleared out and the remaining ones can more accurately highlight the target and suppress responses from background.
由13个卷积层和3个全连接层组成。 由于池化层和卷积层的存在,conv4 - 3和conv5 - 3层的感受野都非常大(分别为92 × 92和196 × 196像素)。 conv4 - 3层(第10层卷积层):捕获的特征对类内外观变化更加敏感,选择的特征图可以很好地将目标人物与其他非目标人物区分开。此外,不同的特征映射关注的对象部分也不同。 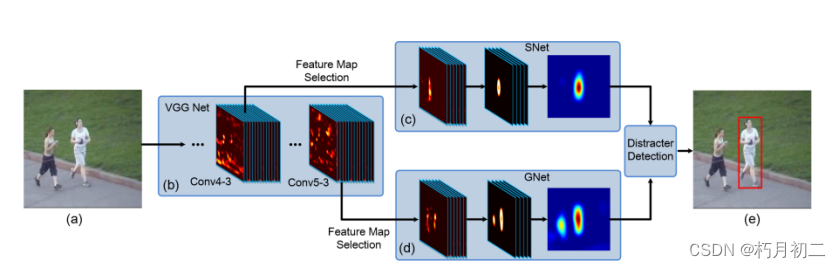 Conv5 - 3层(第13层卷积层):特征图编码了高层次的语义信息,能够更好地将人脸和非人脸物体区分开来。但它们在区分一个身份和另一个身份时的准确率低于conv4 - 3的特征图。 算法设置: sel - CNN: sel - CNN模型由一个dropout层和一个没有任何非线性变换的卷积层组成。以待选特征图( conv4-3或con5-3)为输入,预测目标热力图M,M是以真值目标位置为中心的二维高斯,方差与目标尺寸成正比。通过最小化预测的前景热图( M )与目标热图M之间的平方损失来训练模型。
为了避免在线更新引入的背景噪声,我们固定GNet,只在第一帧初始化后更新SNet。SNet的更新遵循两种不同的规则:自适应规则和判别规则,其目的分别是使SNet适应目标外观变化和提高对前景和背景的判别能力。根据自适应规则,我们每隔20帧使用间隔帧中最可信的跟踪结果微调SNet。基于判别规则,当检测到干扰项时,利用第一帧和当前帧的跟踪结果,通过最小化进一步更新SNet。
|
|
| 研究结论 |
虽然CNN特征图的感受野1较大,但激活的特征图稀疏且局部化。激活的区域与语义对象的区域高度相关。 许多CNN特征图对于从背景中区分特定目标的任务是有噪声或不相关的。 |
|
| 创新不足 |
在低分辨率(LR)的情况下:FCNT具有较高的失败率, 是因为,VGG网络是利用高分辨率的图片进行预训练的。 |
|
| 额外知识 |
前景掩码:前景掩码是指在图像处理中,将前景和背景分离的一种技术。它是一种二进制图像,其中前景像素被标记为1,背景像素被标记为0。前景掩码可以用于图像分割、目标跟踪、背景建模等应用中。在OpenCV中,可以使用不同的算法来生成前景掩码,例如基于高斯混合模型(GMM)的背景减法算法、基于自适应混合高斯模型(MOG)的背景减法算法等。 |
|
| 25.文献阅读笔记 Multi-Domain Network (MDNet) |
||
| 简介 |
题目 |
Learning Multi-Domain Convolutional Neural Networks for Visual Tracking |
| 作者 |
Hyeonseob Namand Bohyung Han |
|
| 原文链接 |
https://arxiv.org/pdf/1510.07945.pdf |
|
| 关键词 |
Multi-Domain Network (MDNet) |
|
| 研究问题 |
单个序列(视频)涉及不同类型的目标,其类别标签、移动模式和外观都不尽相同,跟踪目标也会受到遮挡、变形、光照条件变化、运动模糊等的影响。 同一类物体在一个序列中可以被认为是目标,在另一个序列中可以被认为是背景物体。 由于序列之间存在这种差异和不一致性,所以基于标准分类任务的普通学习方法并不合适,应该采用捕捉与序列无关的信息来获得更好的跟踪表征。 |
|
| 研究方法 |
通过多个带标注的视频序列大量的预训练CNN,获得通用的目标表达。 网络由共享层和多个分支组成的领域特定层构成。
反复训练网络中的域从而在共享层中获得通用目标表达,
长期更新是在定期使用长期收集的阳性样本进行的,而短期更新是在检测到潜在的跟踪失败时进行的。 在这两种情况下,都使用在短期内观察到的负样本,因为旧的负样本通常是多余的或与当前框架无关的。在跟踪期间维护一个单一的网络,这两种更新是根据目标外观变化的快慢来执行的。 样本不平衡问题: 大多数负样本通常是平凡的或冗余的,而只有少数分散的负样本在训练中有效。由于不充分地考虑正负样本不平衡的问题,容易出现漂移问题。 训练和测试程序交替进行,以识别硬负例,通常是假阳性,在线学习过程中采用了这个想法。 将硬负面挖掘步骤集成到小批量数据选择中,在学习过程的每一次迭代中,一个小批量数据由M +个正数和M - h个硬负数组成。通过测试M - (>> M-h)负样本和选择M - h正样本中得分最高的样本来识别困难负样本。该方法检查预定义数量的样本,并有效地识别关键负例,而不像标准的硬负例挖掘技术那样显式地运行检测器来提取假阳性。 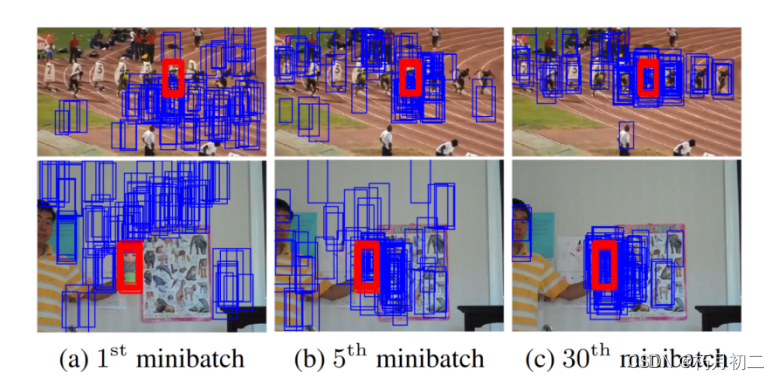 红色和蓝色包围盒分别表示每个小批量数据中的正负样本。随着训练的进行,负样本变得难以分类。
视觉跟踪仅区分目标和背景两类,比一般的视觉识别问题复杂度低得多。 深度CNN对于精确的目标定位效果较差。 视觉跟踪中的目标通常较小,因此希望输入的尺寸较小,这自然会降低网络的深度。 训练和测试是在线进行的。测试较大的网络时,算法的准确性较低,并且明显变慢。
去除了训练阶段使用的所有二分类层的现有分支,并构建一个新的单分支来计算测试序列中的目标分数。 跟踪过程中在线微调新的分类层和共享层内的全连接层以适应新的视频。 通过在线更新分别对目标的长期和短期外观变化进行建模,以实现鲁棒性和自适应性,并在学习过程中引入高效的硬负面挖掘技术。 如下图所示:多域网络的架构,它由共享层和域特定层的K个分支组成。黄色和蓝色边界框分别表示每个域中的正负样本。  输入:107×107 RGB 有五个隐藏层:包括三个卷积层(conv1-3)和两个全连接层(fc4-5)。 网络的最后一个全连接层(fc61fc6K)有 K 个分支,对应 K 个域(训练序列)。 卷积层与 VGG-M 网络的相应部分相同,只是特征图的大小根据输入大小进行了调整。 接下来的两个全连接层有 512 个输出单元,并结合了 ReLU 和 dropout。 K 个分支中的每个分支都包含一个二元分类层,该层具有 softmax 交叉熵损失,负责区分每个域中的目标和背景。请注意, fc61fc6K 称为特定领域层,而将前面所有层称为共享层。 |
|
| 研究结论 |
的跟踪算法从预训练中学习领域无关的表示,并在跟踪过程中通过在线学习捕获特定领域的信息.与针对图像分类任务设计的网络相比,所提出的网络具有简单的体系结构。整个网络离线预训练,包括单个特定领域层的全连接层在线微调。 |
|
| 创新不足 |
 对物体发生形变后的定位依旧是错误的。如下图所示。 |
|
| 额外知识 |
Multi-Domain Learning(多域学习):是指训练数据来自多个域,并将域信息融入学习过程的一种学习方法。 hard negative mining:K.-K. Sung and T. Poggio. Example-based learning for viewbased human face detection. IEEE Trans. Pattern Anal. Mach. Intell., 20(1):39–51, 1998. 4 |
|