GNN简单来讲, 旨在通过融合顶点和边的特征进而提取出图(Graph)中的信息. 一个直觉的想法是, 在MOT中, 我们可以用顶点表示目标的特征, 边表示目标之间的关系, 进而一个构成的图就可以作为解决关联问题的一个很好的入口, GNN就可以成为解决问题的工具.
我想总结几篇经典的利用GNN做MOT的文献. 力争持续更新.
1. Learning a Neural Solver for Multiple Object Tracking(MOTSolv, Offline, CVPR2020)
解决Offline的MOT问题, 主流是依靠最小(大)流算法. 这篇文章本质上利用GNN来对最小流算法进行求解.
1.1 Abstract
摘要中说, MOT方法大家热衷于研究特征提取的策略, 然而本篇文章主要针对数据关联进行研究. 文章提出了一个消息传递网络, 来解决网络流问题. 换言之, 将网络流这个最优化问题变得可微了.
1.2 用图问题描述跟踪
我们首先来建模, 弄清图中顶点与边的含义. 假定我们有了所有的检测, 定义检测集合 O = { o i } ∣ i = 1 n \mathcal{O}=\{o_i\}|_{i=1}^n O={ oi}∣i=1n, 其中每个 o i o_i oi代表一个检测, 一个检测包含位置与时间信息, 因此令 o i = { a i , p i , t i } o_i=\{a_i,p_i,t_i\} oi={ ai,pi,ti}, 其中 a i a_i ai表示原始像素(tracking-by-detection范式, 我们有现成的检测框), p i p_i pi表示位置, t i t_i ti表示这个检测所处的时间. 显然, 一个轨迹就可以用一系列的检测表示: T i = { o i k } ∣ k = 1 n i T_i=\{o_{ik}\}|_{k=1}^{n_i} Ti={ oik}∣k=1ni.
我们现在构建图 G = ( V , E ) , V = { f i } , E ⊂ V × V G=(V,E), V=\{f_i\}, E\subset V\times V G=(V,E),V={ fi},E⊂V×V, 其中 f i f_i fi对应目标特征, 边的含义是, 这两个检测之间是否构成轨迹. 具体来说, 我们用 T i = { o i k } ∣ k = 1 n i T_i=\{o_{ik}\}|_{k=1}^{n_i} Ti={ oik}∣k=1ni 描述一个轨迹, 也等价于使用边集合 { ( i 1 , i 2 ) , ( i 2 , i 3 ) , . . . , } \{(i_1,i_2),(i_2,i_3),...,\} {(i1,i2),(i2,i3),...,}描述. 根据轨迹的特点, 一个目标仅能和最多一条轨迹相连. 那么用GNN解决最小流问题, 实际上就是, 将边进行分类, 判定其是否属于一条轨迹.
如果用 y ( i , j ) ∈ { 0 , 1 } y(i,j)\in\{0,1\} y(i,j)∈{
0,1}表示对边 ( i , j ) (i,j) (i,j)的分类结果, 则最小流问题叙述为:
min ∑ ( i , j ) ∈ E c ( i , j ) y ( i , j ) s . t . y ( i , j ) ∈ { 0 , 1 } \min\sum_{(i,j)\in E}c(i,j)y(i,j) \\ s.t. \quad y(i,j)\in\{0,1\} min(i,j)∈E∑c(i,j)y(i,j)s.t.y(i,j)∈{
0,1}
1.3 消息传递网络的设计
我们知道, GNN在前向传播的过程中要不断聚合顶点与边的信息, 也就是跟CNN类似的感受野的效果. 那么如何设置聚合信息的策略, 也是一个值得研究的课题.
前已说过, 顶点表示目标, 边表示目标间的联系. 具体地, 在初始化时.顶点用目标的特征进行编码. 特征是利用现成的Re-ID网络提取的.
对于边, 用几何和外观两种特征来衡量目标之间的联系. 假设两个目标的位置分别为 ( x i , y i , h i , w i ) , ( x j , y j , h j , w j ) (x_i,y_i,h_i,w_i), (x_j,y_j,h_j,w_j) (xi,yi,hi,wi),(xj,yj,hj,wj), 外观特征分别为 f i , f j f_i, f_j fi,fj, 我们还需要时间差来衡量时间上的远近, 则边的初始特征向量为:
h i , j 0 = ( 2 ( x j − x i ) h i + h j , 2 ( y j − y i ) h i + h j , log h i h j , log w i w j , t j − t i , ∣ ∣ f i − f j ∣ ∣ 2 ) h_{i,j}^{0}=(\frac{2(x_j-x_i)}{h_i+h_j}, \frac{2(y_j-y_i)}{h_i+h_j}, \log{\frac{h_i}{h_j}},\log{\frac{w_i}{w_j}},t_j-t_i,||f_i-f_j||_2) hi,j0=(hi+hj2(xj−xi),hi+hj2(yj−yi),loghjhi,logwjwi,tj−ti,∣∣fi−fj∣∣2)
在GNN一层一层传递的过程中, 既要边向顶点传递信息, 也要顶点向边传递信息, 先顶点到边,再边到顶点, 也就是如下的流程:

具体地, 在顶点向边传递的过程中, 会将两顶点的特征和边特征concat起来输入MLP N e \mathcal{N}_e Ne, 在边向顶点传递信息的过程中, 对于和该顶点相连的每条边, 首先将上一步计算出的边的特征和顶点的concat输入MLP N v \mathcal{N}_v Nv, 之后将得到的结果进行sum, 也就是如下两式:

还有一个细节, 为了在MLP中加入时间的先验信息, 在计算边到顶点信息传递时, 按照与该顶点相邻的顶点是past还是future分别进行计算, 并总是利用初始信息:

例如: 我们要计算下图中中间节点的更新的feature, 与它相连的有过去两个节点和未来两个节点, 则利用两个MLP分别计算过去节点和未来节点对应的结果, concat之后, 再输入一个MLP进行计算.

1.4 评价
这是一个offline的方法, 利用GNN里比较常见的策略, 将匹配问题转化为graph中边分类问题. 做的一点小改动是将相连的顶点分为past和future. 不过迷惑的一点是, 没有看明白将edge进行分类后, 是如何满足约束条件的.
\space
2. GSM: Graph Similarity Model for Multi-Object Tracking(GSM, Online, IJCAI2020)
2.1 Abstract
文章主要针对直接利用外观特征匹配的不稳定性问题, 提出了用图匹配来加入拓扑关系信息的方法. 文章也是利用图匹配问题来解决两帧之间目标匹配问题, 对每个顶点都构建一个有向图, 顶点表示外观特征, 边表示位置关系特征, 随后计算两帧间每个目标的图相似度进而进行匹配. 因为有FP和FN的情况, 导致拓扑关系可能不稳定. 针对该问题, 文章提出了软匹配, 即更多地考虑了外观特征.
2.2 Method
设 t − 1 t-1 t−1帧有M个目标, t t t帧有N个目标. 现在的任务是进行数据关联, 为此构造cost matrix C ∈ R M × N C\in\mathbb R ^{M\times N} C∈RM×N, 对于每个 C C C中元素, 我们利用目标的图之间的相似度来衡量, 即:
c i , j = C G ( d i t − 1 , d j t ) = 1 − s i , j c_{i,j}=C_G(d_{i}^{t-1}, d_{j}^{t})=1-s_{i,j} ci,j=CG(dit−1,djt)=1−si,j
其中 d d d表示检测, s i , j s_{i,j} si,j表示图相似度(归一化的).
现在我们来构建图. 对第 t t t帧的第 i i i个目标 d i t d_{i}^{t} dit, 考虑与其最近的K个目标, 构造有向图 G = ( V , E ) G=(V,E) G=(V,E), ∣ V ∣ = ∣ E ∣ = K + 1 |V|=|E|=K+1 ∣V∣=∣E∣=K+1, V V V中的每个元素表示对应目标的外观特征向量, E E E中的每个元素代表与 d i t d_{i}^{t} dit的拓扑关系特征, 定义为:
e i , k t = f ( r i , k t ) ∈ R 256 , r i , k t = [ x i − x k w i , y i − y k h i , log ( h k / h i ) , log ( w k / w i ) , x i − x k w 0 , y i − y k h 0 , log ( ( w k − w ) / w 0 ) , log ( ( h k − h ) / h 0 ) ] ∈ R 8 e_{i,k}^t=f(r_{i,k}^t)\in\mathbb R^{256} ,\\ r_{i,k}^t=[\frac{x_i-x_k}{w_i}, \frac{y_i-y_k}{h_i}, \log{(h_k/h_i)}, \log{(w_k/w_i)},\\ \frac{x_i-x_k}{w_0}, \frac{y_i-y_k}{h_0}, \log{((w_k-w)/w_0)}, \log{((h_k-h)/h_0)} ]\in\mathbb R^{8} ei,kt=f(ri,kt)∈R256,ri,kt=[wixi−xk,hiyi−yk,log(hk/hi),log(wk/wi),w0xi−xk,h0yi−yk,log((wk−w)/w0),log((hk−h)/h0)]∈R8
其中 f : R 8 → R 256 f:\mathbb R^{8}\rightarrow \mathbb R^{256} f:R8→R256为一个升维的非线性函数. w 0 , h 0 w_0,h_0 w0,h0表示原图尺寸.
这样, 对于两帧间的两个目标, 它们各自有 K K K个最近邻点, 我们有了两个图 G i , G j G_i, G_j Gi,Gj, 现在要计算这两个图的相似度.
首先将相似度定义为边顶点的相似度的整合, 对于 G i G_i Gi的第 m m m个顶点和 G j G_j Gj的第 n n n个顶点(注意第0个顶点为我们关注的目标 i , j i,j i,j), 相似度为:
s i , j m , n = f ( concat [ ∣ ∣ v i m , t − 1 − v j n , t ∣ ∣ 2 2 , ∣ ∣ e i m , t − 1 − e j n , t ∣ ∣ 2 2 ] ) s_{i,j}^{m,n}=f(\text{concat}[||v_i^{m,t-1}-v_j^{n,t}||_2^2,||e_i^{m,t-1}-e_j^{n,t}||_2^2]) si,jm,n=f(concat[∣∣vim,t−1−vjn,t∣∣22,∣∣eim,t−1−ejn,t∣∣22])
其中 f f f是一个二分类器, 将向量映射到 [ 0 , 1 ] [0,1] [0,1].
由 s i , j m , n s_{i,j}^{m,n} si,jm,n构成了相似度矩阵 S i , j ∈ [ 0 , 1 ] ( K + 1 ) × ( K + 1 ) S_{i,j}\in[0, 1]^{(K+1)\times (K+1)} Si,j∈[0,1](K+1)×(K+1). 显然, 两个图中除了第0个顶点是我们规定的目标本身外, 其余顶点并不是一一对应的. 为此, 我们对剩余的顶点的相似度进行一次linear assignment, 这样就可以确定匹配关系进而更好地计算相似度的差异, 具体地, G i , G j G_i, G_j Gi,Gj最终的相似度定义为:
s ^ i , j = 1 K + 1 ( s i , j 0 , 0 + f L A ( S i , j ^ ) ) \hat{s}_{i,j}=\frac{1}{K+1}(s_{i,j}^{0, 0}+f_{LA}(\hat{S_{i,j}})) s^i,j=K+11(si,j0,0+fLA(Si,j^))
其中: f L A f_{LA} fLA是利用linear assignment匹配后计算相似度差异之和, 因此总共需要 1 K + 1 \frac{1}{K+1} K+11进行归一化. S i , j ^ ∈ [ 0 , 1 ] ( K ) × ( K ) \hat{S_{i,j}}\in[0, 1]^{(K)\times (K) } Si,j^∈[0,1](K)×(K)表示 S i , j S_{i,j} Si,j去除(0,0)元素后剩余部分.
这样设计有一个好处, 就是利用linear assignment部分地消除FP与FN对graph整体造成的影响.
整体流程如下图:

2.3 评价
这篇文章的可取之处在于对每个目标建立graph, 这样就很具体地对拓扑结构进行了计算, 然而这样计算量也是比较expensive的.
\space
3. Graph Networks for Multiple Object Tracking(GNMOT, Online, WACV2020)
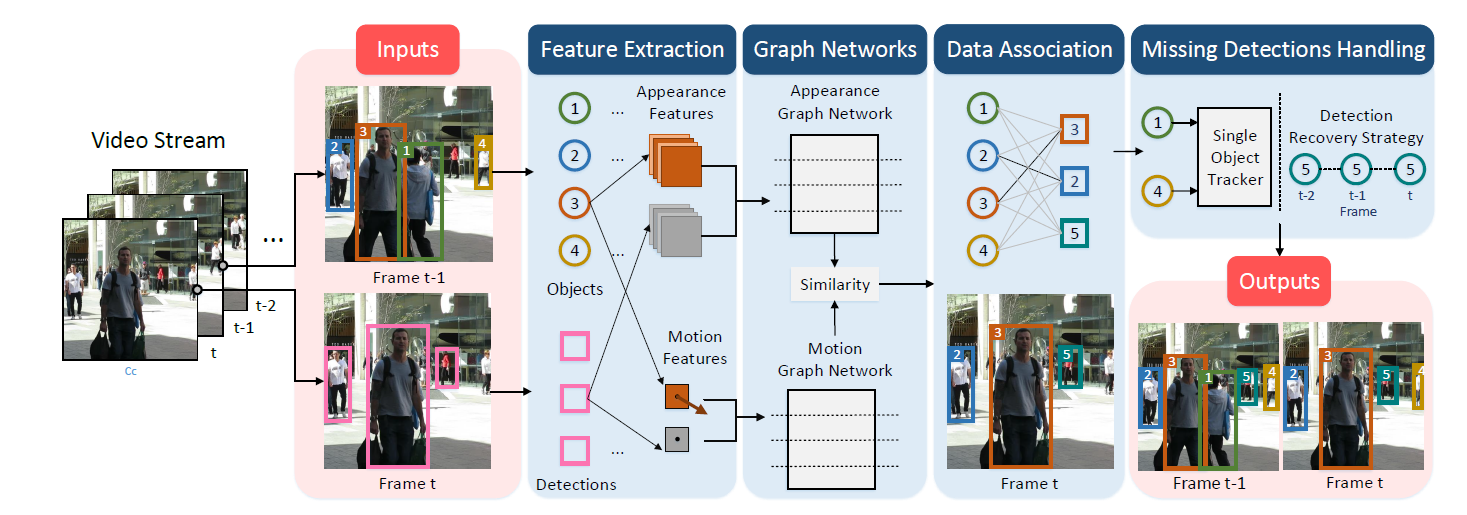
3.1 Abstract
当前一些利用图网络解决MOT的工作都是静态图, 本篇文章提出了动态图, 设计了一个外观图和一个运动图, 来计算轨迹与检测之间的关系. 采用了边, 顶点和全局变量来更新图的特征.
3.2 简述
这篇文章也是一个用图网络做多目标跟踪的方法, 不过这篇文章的方法比较朴素, 整体就是利用消息传递来更新边特征, 再用匈牙利算法匹配.
算法整体流程是这样:
1.根据过去帧轨迹和现在帧检测, 构建两个图: 外观图与运动图, 只有轨迹与检测的边是相连的.
图的目的是为了构造代价矩阵, 构造的方式是, 第 i i i个轨迹和第 j j j个检测的匹配得分按照如下方法算出:
F ( i , j ) = α A p p e a r a n c e G r a p h N e t w o r k ( i , j ) + ( 1 − α ) M o t i o n G r a p h N e t w o r k ( i , j ) F(i, j) = \alpha AppearanceGraphNetwork(i, j) + (1 - \alpha)MotionGraphNetwork(i, j) F(i,j)=αAppearanceGraphNetwork(i,j)+(1−α)MotionGraphNetwork(i,j)
由 F ( i , j ) F(i, j) F(i,j)就构成了匹配矩阵
2.那么两个网络是如何搭建的呢?
外观图网络:
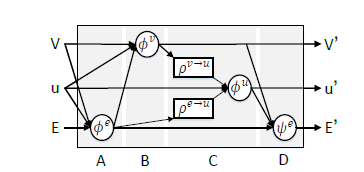
每一次消息传递, 更新分为四步:对于两个顶点 v v v和其相连的边 e e e, 设置一个表示图的全局变量 u u u,
(1) 首先进行边更新, 设这部分网络为 ϕ e , 1 \phi_{e, 1} ϕe,1, 该网络的输入为两个顶点特征, 边特征, 和全局变量特征, 得到更新的边特征
(2) 再进行顶点更新, 设这部分网络为 ϕ v \phi_{v} ϕv, 该网络的输入为两个顶点特征, (1)中更新的边特征, 和全局变量特征. 注意这一步只更新检测的顶点, 目的是将轨迹
的历史信息融入到检测当中.
(3) 再进行全局变量更新, 设这部分网络为 ϕ u \phi_{u} ϕu, 将所有顶点与边的特征作平均作为平均特征, 和 u u u一起输入到该网络得到更新的 u u u
(4) 最后进行边更新, 设这部分网络为 ϕ e , 2 \phi_{e, 2} ϕe,2, 输入为更新的边, 轨迹顶点, 更新的检测顶点, 更新的全局
运动图网络:
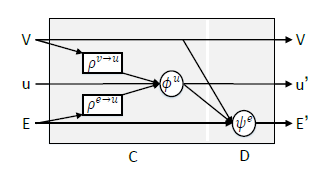
同理, 只是少了(1) (2), 只有(3) (4)
- 如何训练:
外观图把(1)和(2)(3)(4)分开训练, 运动图一起训练, 损失函数的思路是采用交叉熵, 来计算匹配的对不对.
3.3 评价
本工作采用了比较传统的消息传递形式, 利用两个网络计算出的轨迹与检测的得分得到匹配矩阵, 此外还加入了轨迹管理, 也就是未匹配的轨迹可以加入以后的匹配, 以及未匹配的检测用SOT单独进行检测等.
4. TrackMPNN: A Message Passing Graph Neural Architecture for Multi-Object Tracking(TrackMPNN, Online, arxiv2101)
4.1 Abstract
该工作采用无向动态图, 来表示多目标跟踪的关联. 该消息传递网络仅仅利用了目标的位置与类别信息, 没有利用外观信息, 因此速度很快. 此外, 还可以处理丢失的检测等.
4.2 Method
首先定义该消息传递网络中的两种节点:
- 检测节点(detection node): 表示之前帧或当前帧的检测, 特征表示就是由边界框与类别的one-hot编码拼起来的
- 关联节点(association node): 在两个检测节点之间, 表示这两个节点之间相连(是同一轨迹) 的可能性(相当于边的作用)
再来看训练和推理阶段的伪代码.
首先来看几个函数:
- initialize_graph(): 初始化图, 对相邻两帧之间的检测构造二部图, 在每一对的检测节点之间, 加入一个关联节点
- update_graph(): 更新图, 加入当前帧的新检测, 并在当前新检测和过去没有匹配的检测节点之间也加入关联节点(表达的意思应该是新出现的目标与未匹配的目标之间加入关联节点, 具体还要看代码). 同时移除旧的顶点与边.
- prune_graph(): 移除低概率的点和边, 减少内存占用
- decode_graph(): 利用贪心或匈牙利算法求解出当前匹配.
- TrackMPNN(): 构造函数
- TrackMPNN().forward(): 向前一步.
训练阶段伪代码:

推理阶段伪代码:
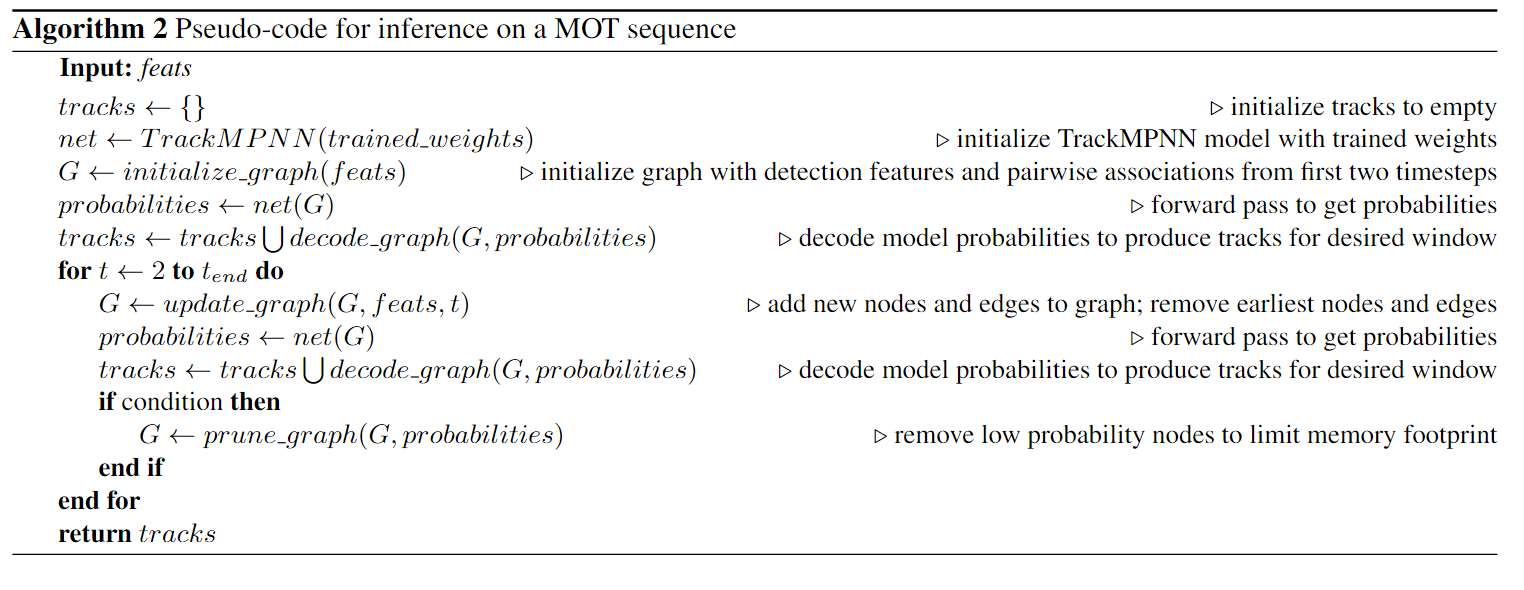
节点特征更新方式:
1.检测节点:
检测节点的初始化方式为边界框位置和类别的one-hot编码经过一个全连接层所得的向量, 这个维度很低. 在每一步更新时, 检测节点都聚合其上一层的特征与上一层的临近节点的特征, 如下式所示:
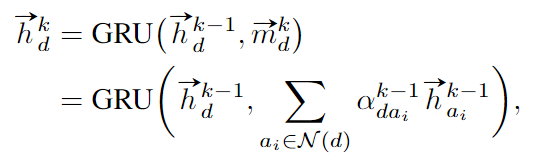
我们简单地用全连接层来预测检测的置信度:
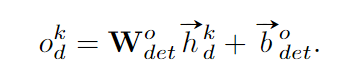
2.关联节点:
关联节点初始化为0向量, 在每一步更新时, 都聚合其过去的特征与相连的两个检测节点的过去的特征, 两个相连检测节点特征可以concat起来或作差后按照全连接层计算, 如下式所示.
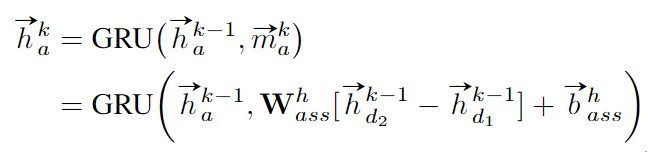
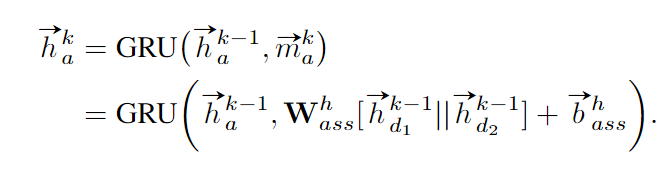
同理, 我们简单地用全连接层来预测关联节点的置信度, 该置信度应该表示两个检测节点同属于同一目标的概率.
损失函数:
直接将检测节点与关联节点的置信度按照交叉熵计算(本质上是分类问题, 两个检测是否属于同一类). 比较有趣的是, 训练时将视频划分成了一小段一小段进行训练的, 并且在计算交叉熵时, 有一部分是针对每一个检测节点, 在对过去帧的邻居和未来帧的邻居的关联节点进行交叉熵计算, 如下式:
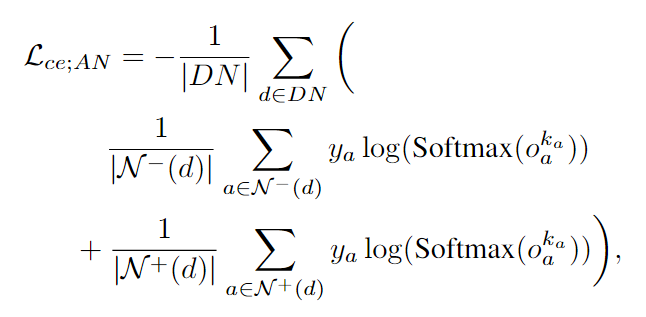
其中 N + \mathcal{N}^+ N+表示未来帧, N − \mathcal{N}^- N−表示过去帧.
其他项就是采用二元交叉熵:
检测节点与关联节点:
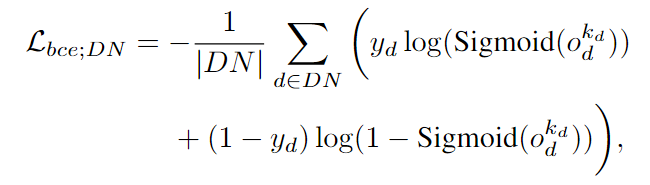
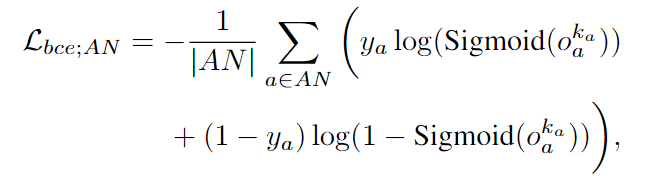
最终的损失函数即为以上三项的组合.
5. Learnable Graph Matching: Incorporating Graph Partitioning with Deep Feature Learning for MOT(GMTracker, Online, CVPR2021)
5.1 Abstract
文章主要针对三个问题:
- 现有的方法忽视了轨迹和检测之间的上下文信息,这样对遮挡不友好
- 端到端的数据关联方式太依赖DNN了,没有利用到基于优化的方式的长处。换言之,用DNN来解决优化方式比较值得怀疑
- 基于graph的方法往往需要一个独立的GNN来提取特征,这样不方便
提出的解决方法是:
利用整体的无向图来描述轨迹和检测之间的关系,将关联问题转换为图匹配问题,并且为了让整体都是可微的(端到端),将原来的图匹配放宽为连续二次规划,然后利用隐函数定理将其训练到一个深度图网络中.
整体算法的思路是, 先用GCN增强图的特征表示, 然后用图匹配问题解决关联问题.
5.2 将MOT转化为图匹配形式
图匹配问题是寻找两个图的顶点映射, 使得匹配后顶点和顶点之间的边的相似度要尽量相近. 如果我们对已有的轨迹建立一个图, 再将当前帧检测建立一个图, 那么MOT的匹配问题就是如何寻找这个顶点之间映射的问题.
我们还是先来构建图. 和MOTSolv类似, 对于检测图 G D = ( V D , E D ) G_D=(V_D,E_D) GD=(VD,ED), 顶点集合 V D V_D VD表示一个检测, 边表示检测之间的相似度. 对于轨迹图 G T = ( V T , E T ) G_T=(V_T,E_T) GT=(VT,ET), 顶点集 V T V_T VT表示该轨迹检测的集合, 边也是轨迹之间的相似度. 检测图和轨迹图都是完全图. 至于相似度如何定义, 会在后文说明.
图匹配问题, 是一个二次分配问题(QAP), 可以写成K-B形式: (数学不好, 这里背后的原理不懂)
我们必须先假定, 待匹配的两个图顶点数相同, 这是图匹配问题的规定

(1)式:
将图匹配问题表示为该最优化问题. 其中 A A A表示图的带权邻接矩阵, Π \Pi Π表示匹配关系, 约束条件的意思是: 我们保证匹配关系是一一对应的(双射, 1 n 1_n 1n为全1矩阵). , B B B表示顶点的亲和度矩阵.
因为根据K-B形式的特性, Π \Pi Π是正交矩阵, 因此可以写为如下形式:

F表示矩阵的F范数,
这个式子更加直观, 第一项表示边的匹配关系的差值, 也就是边的差异. 第二项表示匹配结果的顶点之间的相似度. 我们应该最小化边的差异, 最大化点的相似度.
进一步地, 可以证明, 正交矩阵 Π \Pi Π位于双随机矩阵的凸包内, 因此我们可以限定 Π \Pi Π的搜索范围, 转化为如下优化问题:

然而, 在MOT问题中, 带权邻接矩阵不该是二维的, 该是三维的, 因为每个元素都代表一个特征. 我们假定特征是经过归一化的, 为此, 我们按第三维展开, 将优化问题写为:

并将其重写为(为啥)?

(5)式中:
小写字母全部是原矩阵的拉直形式, M M M是 n 2 × n 2 n^2\times n^2 n2×n2矩阵, 表示所有可能的顶点匹配.
那么根据(3)式的结论, 我们可以转化为:

那么, 边和顶点之间的相似度都是用余弦距离度量的(保证了归一化), 如下两式所示:


通过一种方式(此处略掉了)把(7)的 M e u , v M_e^{u,v} Meu,v映射到(6)式的 M M M.
5.3 GMTracker和图匹配网络
5.3.1 用于增强特征的cross-graph GCN
为什么要叫Cross-Graph呢? 是因为在增强特征的时候, 图卷积是对检测图和轨迹图一起做的, 这样可以关注到检测与轨迹的关系.
目标代表顶点, 顶点的初始特征用Re-ID网络的外观特征. 边代表两个目标之间的相似度, 对于检测图和轨迹图中内部顶点之间的边, 我们定义是边连接的顶点的特征拼接(并正则化), 即:
h i , i ′ = l 2 ( h i , h i ′ ) h_{i,i'}=l_2(h_i, h_{i'}) hi,i′=l2(hi,hi′)
其中 h h h代表特征.
聚合函数采用加权和形式, 即在第 l l l层的第 i i i个顶点:
m i ( l ) = ∑ j ∈ G T w i , j h j h i ( l + 1 ) = M L P ( h i ( l ) + ∣ ∣ h i ( l ) ∣ ∣ 2 m i ( l ) ∣ ∣ m i ( l ) ∣ ∣ 2 ) i ∈ G D , j ∈ G T m_i^{(l)}=\sum_{j\in G_T}w_{i,j}h_j \\ h_i^{(l+1)}=MLP(h_i^{(l)}+\frac{||h_i^{(l)}||_2m_i^{(l)}}{||m_i^{(l)}||_2}) \\ i\in G_D, j\in G_T mi(l)=j∈GT∑wi,jhjhi(l+1)=MLP(hi(l)+∣∣mi(l)∣∣2∣∣hi(l)∣∣2mi(l))i∈GD,j∈GT
其中的权重如何定义呢? 我们用外观特征和运动特征一起衡量. 对于轨迹的运动预测采用Kalman滤波:
m i ( l ) = c o s ( h i ( l ) , h j ( l ) ) + I o U ( g i , g j ) m_i^{(l)}=cos(h_i^{(l)},h_j^{(l)})+IoU(g_i,g_j) mi(l)=cos(hi(l),hj(l))+IoU(gi,gj)
5.3.2 可微的图匹配层
前面用数学方法描述了MOT中的图匹配问题, 作者想把这个也变成可微的, 变成网络的一部分, 跟DeepMOT一样.
作者借鉴了OptNet, 是一个用网络解决最优化问题的算法. 作者说具体的证明在附录里, 然而我没找到附录在哪!!
5.4 评价
这篇文章的可取之处在于利用跨图的GCN, 同时考虑检测和轨迹来更新特征. 并且将匹配问题转化为图匹配问题(而不再限于沟渠的二分图匹配——匈牙利算法的模式), 并且将图匹配算法变得可微.
有几个疑问之处, 一是图匹配如何具体实现可微的, 二是图匹配问题应该要求两个图的顶点个数一样, 当不一样时, 是如何处理的.
\space
6. Joint Detection and Multi-Object Tracking with Graph Neural Networks(GSDT, Online, arxiv 2021.4)
6.1 Abstract
这篇文章的亮点在于1. Joint detection and tracking 2. GNN. JDT的卖点在于数据关联可以和检测一起训练, 达到one-shot的效果.
对于过去的JDT的工作, 很多都没有考虑到object-object之间的关系. 而对于过去图网络的工作, 很多还是tracking-by-detection的(例如前两篇文献都是). 而这个工作, 是可以利用GNN的结构天然地对object-object关系进行建模, 也是JDT的, 如下图所示.

6.2 Method
GSDT的原理比较简单. 为了实现JDT, 最直接的方式是从同一个特征图同时进行检测和目标特征的预测. 为了实现Online, 我们应该把过去的轨迹和当前帧的检测关联起来.
整体结构如下图:

假设在帧 t t t, 我们有 t − 1 t-1 t−1的特征图和第 t t t帧的特征图. 我们根据已有的轨迹, 利用ROIAlign将 t − 1 t-1 t−1的特征图对应的位置抠出来, 这样就得到了轨迹的特征. 我们希望学习过去和现在的object-object关系, 但是现在帧我们只有特征图, 没有检测. 因此只能把当前特征图整个都当成潜在检测, 例如特征图维度是 R c × h × w \mathbb{R}^{c\times h \times w} Rc×h×w, 就逐像素flatten成 h w hw hw个 c c c维的向量.
我们把轨迹的特征和当前特征图flatten出的特征当作图的顶点. 由于同一帧的目标不可能相互匹配, 因此我们建图的时候只需要建立 t − 1 t-1 t−1帧顶点到 t t t顶点即可. 此外, 只有相近目标关系才大, 因此边只需要连接轨迹和相近的像素. 随后GNN对特征进行更新. 然然而, 如果采用一层GNN, 则只有时间信息而没有空间信息. 因此可以采用多层, 在迭代的过程中, 特征会传播的更远, 就可以获取空间信息. GNN部分如下图:

经过GNN后, h w hw hw个 c c c维的向量已经得到了更新, 我们再重新reshape回 R c × h × w \mathbb{R}^{c\times h \times w} Rc×h×w, 这样在此新特征图上进行不同任务的预测: 位置, 形状, 外观信息.

得到特征后, 数据关联阶段仍然采用检测的embedding和轨迹embedding计算亲和度, 匈牙利算法匹配.
6.3 评价
GSDT利用GNN对当前帧feature map进行更新, 融合过去轨迹特征和空间信息. 然而, 过去特征实际上只用了 t − 1 t-1 t−1帧的, 这样如果有的目标有模糊或者怎样, 外观信息可能不准, 可以对过去一定帧数取平均, 会好一些. GNN只利用了顶点信息:

其实对边也赋予特征可能会更丰富一点.
\space
7. Detection Recovery in Online Multi-Object Tracking with Sparse Graph Tracker(SGT, Online, arxiv 2022.5)
7.1 Abstract
文章从漏检这个问题入手, 指出MOT性能受限的一大因素是因为遮挡, 模糊等造成的漏检. 所以想用GNN来恢复漏检. 具体的做法是节点代表检测, 边代表两个检测之间的相似度(例如位置或者外观). 之后跟MOTSolv一样, 把两个检测是否属于同一目标, 转换成边分类的问题.
这个模型是Online的, 每次在相邻两帧进行, 并且不需要运动特征和额外的Re-ID网络, 是个JDT的模型(和GSDT一样).
7.2 Introduction & Related Work
在这两个部分, 作者提出了一个有趣的观点: “找到在FP和TP之间实现最佳权衡的检测阈值至关重要.” 其实, 对于以往处理漏检的方法, 主要有两个工作. 一是ByteTrack, 二是OMC. OMC没看过, ByteTrack实际上是通过降低阈值和多次匹配完成的性能提升, 然而这样会在降低FN的同时提高FP. 实际上, 像SGT这种利用特征重新关联的形式, 反而应该会好一些.
7.3 Method
SGT基于FairMOT打造, 实际上做的是匹配阶段的优化.
SGT实际上是通过边分类对即将抛弃的检测进行恢复. 边代表节点(检测)之间的相似度, 用位置, 外观和IoU三个指标衡量:

与上述方法不同的是, 顶点并不是用Re-ID特征初始化, 而是用骨干网络提取的整个特征作为顶点初始化, 所有顶点共享.
下面对SGT的过程做一个笔记.

- Step1. 输入(应该是相邻)的两帧 t 1 , t 2 t_1, t_2 t1,t2, 我们选择置信度最大的 K K K个检测( K K K应该比较大), 提取特征. 但是这 K K K个检测里面有置信度大的, 也有置信度小的. 这要是之前的一些方法, 低置信度的通常被丢弃了. 我们现在要通过GNN, 恢复置信度低的检测.
- Step2. 构建GNN. 注意绿色的是在 t 1 t_1 t1之前丢失的检测, 被加入到 t 1 t_1 t1侧的顶点中. 注意丢失的检测也是有寿命的.
- Step3. GNN forward, 更新顶点和边的特征.
- Step4. 对边进行二分类, 确定两个检测是否为同一个目标, 并用匈牙利算法匹配, 确保一一对应. 此时, 原本要抛弃的一些检测可能因为边分类是正类而被恢复. 为了抑制FP, 在恢复后仍然对顶点分类, 高于置信度才真正恢复.
7.4 评价
SGT实际上是针对低置信度抛弃问题的一个改进, 相比ByteTrack, 显得不那么暴力了, 而且通过顶点分类等方式有意识地抑制FP.
8. Multiplex Labeling Graph for Near-Online Tracking in Crowded Scenes(MLG, Nearly-Online, IEEE IoTJ 2020)
8.1 Abstract
基本所有MOT的常规思路是, 我们要分立处理目标. 包括如果是图网络的方法, 也是一个节点代表一个目标. 然而作者认为, 物理世界的场景都是3D的, 而2D的图像表示并不能完全代表3D信息. 这就是说, 视频中的一个像素并不一定只包含一个目标, 如果在物理世界发生了遮挡, 那么它的含义应该包含多个目标. 基于这种假设, 本文构建了nearly-online(每次只借鉴未来的少数帧, 换句话讲就是在未来帧再给出当前帧的结果)的一个图, 每个节点是可以包含多个目标, 以应对遮挡的情形.
8.2 Method
因为是Nearly-Online的, 因此采用滑动窗口的方式建图, 例如我们已经有了第 t t t帧之前的轨迹, 我们对第 t − 1 t-1 t−1帧到 t + 2 t+2 t+2帧进行建图. 建的是有向图, 边只从过去指向未来.
顶点含义: 目标
边含义: 轨迹
前面说过, 一个顶点可以包含多个目标, 以应对遮挡的情形. 而目标轨迹的确定问题就转化为在图中确定最优路径问题. 具体地, 就是寻找权重和最大的路径作为目标的轨迹, 如下式:
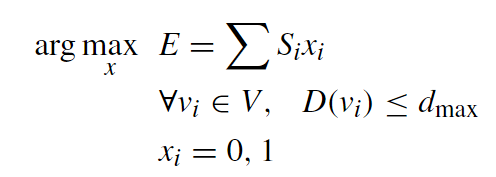
式中, E E E表示最终得到的轨迹, S i S_i Si表示路径 i i i的score, 或者说置信度, x i x_i xi为0或1, 意为选或者不选第 i i i个路径 S i S_i Si, 遍历是对所有顶点进行的, D ( v i ) D(v_i) D(vi)表示一个顶点所能代表的目标的数量, 令其不能超过 d m a x d_{max} dmax.
按照这种方式, 而不是匈牙利算法这种一一对应的匹配方式, 就可以让一个节点代表多个目标, 获得遮挡下更准确的轨迹, 如下图所示:
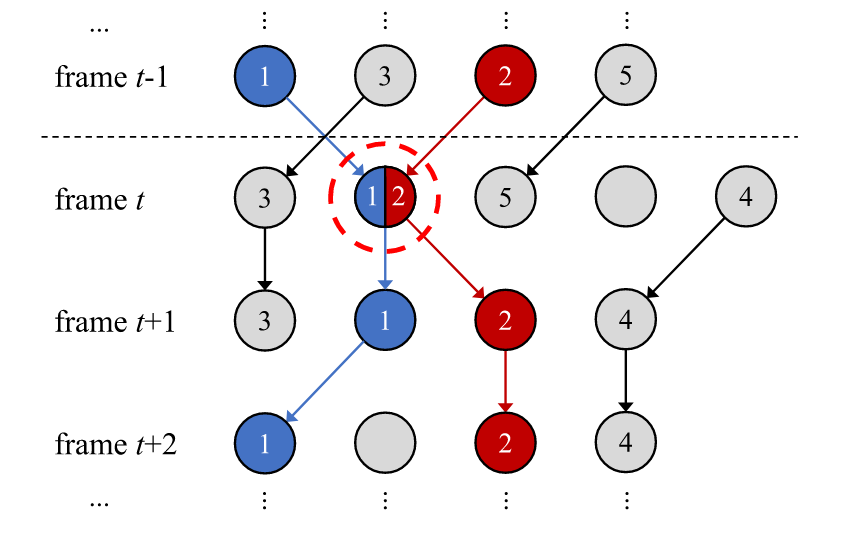
在本文中, 边权得分(两个节点是否属于同一目标)是通过LSTM进行二分类的, 许多工作也是类似的, 在此不再赘述.
在MLG的伪代码中, 大致说明了算法流程. 就是在窗口滑动之后, 对上一个的末尾节点(出度为0)与当前的所有初始节点(入度为0)构建边, 并且筛掉置信度不大的边, 再筛掉入度大于 d m a x d_{max} dmax(也就是代表的目标个数大于 d m a x d_{max} dmax的边), 就达到了上式的最优解(贪心算法).

9. Unifying Short and Long-Term Tracking with Graph Hierarchies(SUSHI, Offline, CVPR2023)
概述
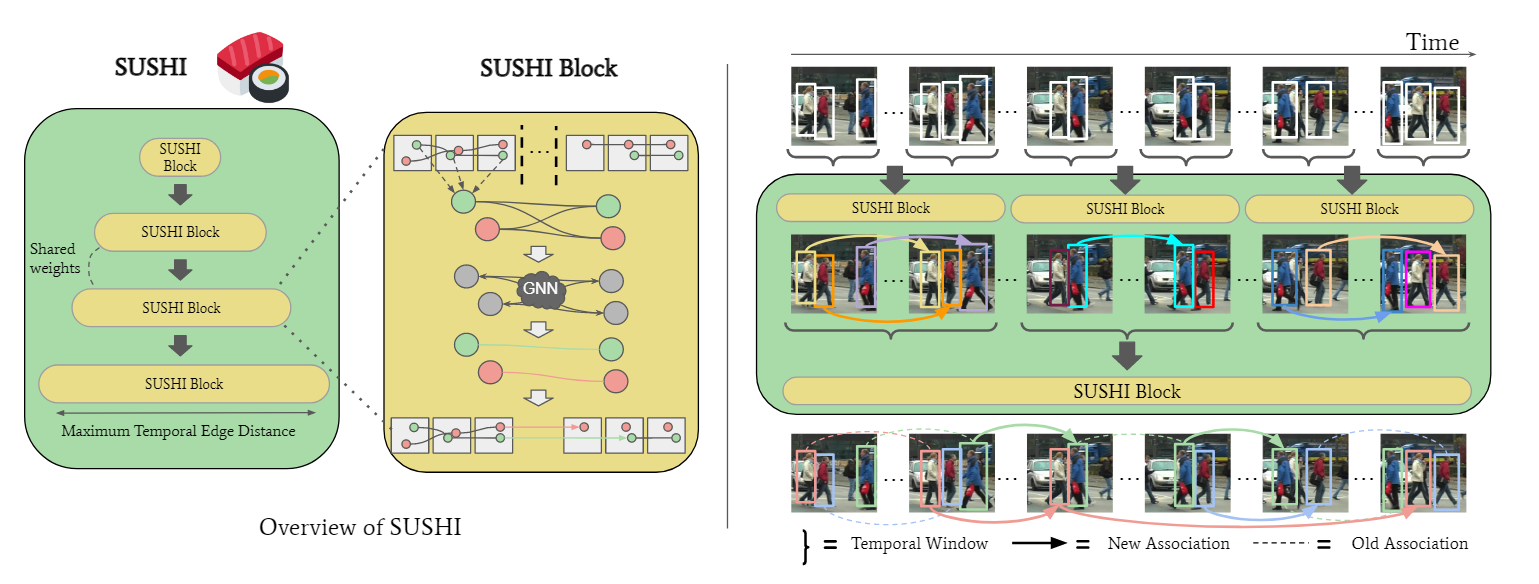
这篇文章是Learning a Neural Solver for Multiple Object Tracking的改进, 就是用递归的方式将轨迹合并, 如下图所示:
从小轨迹合并到大轨迹后, 新的节点就代表了合并后的轨迹, 如下图所示,
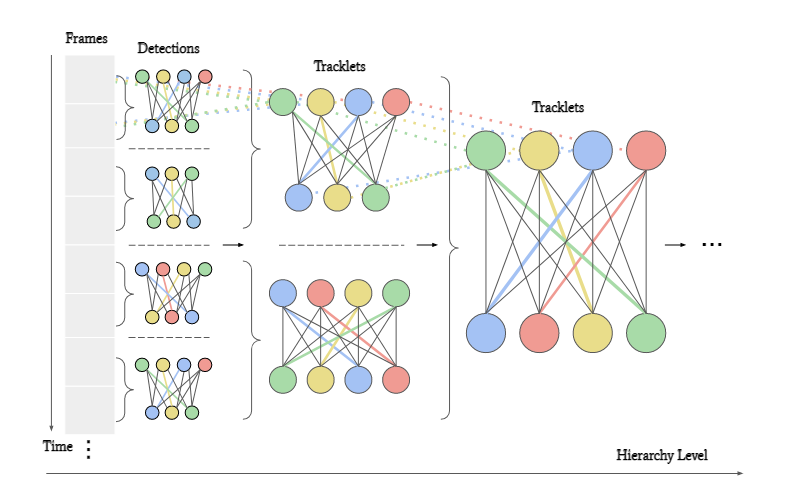
这样就减小了计算量. 每一个SUSHI block实际上就是一个GNN, 节点代表轨迹, 边代表匹配关系, 经过若干层消息传递更新特征, 用MLP决定该边代表的关联关系的可能性. 节点特征初始化为零向量, 边特征由关联的特征(Re-ID特征, 位置时间关系等)组成. 需要注意的设计是, 所有的SUSHI Block是共享特征的, 为了区分不同层的block, 作者增加了一个level embedding, 这样就允许边特征对每个层次的预期特定特征差异进行编码. 共享特征还有一个好处, 那就是无形中扩充了训练的数据量.
在实现细节上, 作者采用了四个关联层级, 分别是5, 25, 75和150帧. 建图时对于每个节点, 选取最近邻的15个节点作为边, 近邻的距离度量包括几何, 外观和运动相似度.
9. 比较
| 算法 | Online/Offline | 范式 | 整体思路 | 图形式 | 顶点含义 | 边含义 |
|---|---|---|---|---|---|---|
| MOTSolv | Offline | TBD | GNN解决最小流问题 | 完全图 | 目标的Re-ID feature | 目标相似度 |
| GSM | Online | TBD | 对每个目标都建立图, 目标间相似度用图相似度衡量 | (有向)稀疏图 | 目标的Re-ID feature | 拓扑(位置)相似度 |
| GNMOT | Online | TBD | 构建检测与轨迹的外观图与匹配图, 计算每一对匹配的得分, 再求解最佳匹配 | 二部图 | 目标的外观与运动特征 | 属于同一目标的可能性 |
| TrackMPNN | Online | TBD | 构建检测节点与关联节点, 关联节点表示匹配关系, 计算关联节点得分进行匹配 | 二部图 | 检测节点: 位置特征与类别; 关联节点: 属于同一目标的可能性 | - |
| GMTracker | Online | TBD | 将匹配问题转换为图匹配问题(顶点映射关系), 并利用隐函数定理将匹配层可微 | 完全图 | 目标的Re-ID feature | 目标相似度 |
| GSDT | Online | JDT | 利用GNN更新当前feature map, 不同head再进行不同任务 | 稀疏图 | 一侧是轨迹的Re-ID feature, 一侧是feature map的像素特征 | - |
| SGT | Online | JDT | 利用边分类来决定两个检测是否属于同一目标,以此恢复低置信度检测 | 稀疏图 | 整个feature map | 目标相似度 |
| MLG | Nearly-Online | TBD | 一个节点可以代表多个目标, 将匹配问题转化为最大流问题 | 有向稀疏图 | 目标 | 路径 |
| SUSHI | Offline | TBD | 层级递归式关联 | 无向图 | 目标(轨迹) | 目标相似度 |