| 46.文献阅读笔记 |
||
| 简介 |
题目 |
Learning a Recurrent Visual Representation for Image Caption Generation |
| 作者 |
Xinlei Chen, C. Lawrence Zitnick, arXiv:1411.5654. |
|
| 原文链接 |
||
| 关键词 |
2014年rnn图像特征和文本特征相互描述 |
|
| 研究问题 |
图像和基于句子的描述之间的双向映射。 句子生成、句子检索和图像检索。 目标: 能够根据一组视觉观察结果或特征生成句子,根据之前生成的单词集 Wt-1 = w1, ... , wt-1 和观察到的视觉特征 V,计算出单词 wt 在 t 时刻生成的概率。 其次,希望在一组口语或阅读单词 Wt 的情况下,能够计算视觉特征 V 的可能性,从而生成场景的视觉表征或执行图像搜索。 |
|
| 研究方法 |
提出使用循环神经网络来学习这个映射。与以前的方法将句子和图像映射到一个共同的嵌入不同,我们允许在给定图像的情况下生成新的句子。使用相同的模型,我们也可以在给定图像的视觉描述的情况下,重建与图像相关的视觉特征。 使用一种新颖的循环视觉记忆,自动学习记忆长期的视觉概念,以帮助句子生成和视觉特征重建。 Rnn:从句子中生成图像特征,从图像特征中生成句子 |
|
| 研究结论 |
学习长期的交互、反复出现的视觉记忆来学习重建视觉特征 |
|
| 创新不足 |
None |
|
| 额外知识 |
None |
|
| 47.文献阅读笔记 |
||
| 简介 |
题目 |
From Captions to Visual Concepts and Back |
| 作者 |
Hao Fang, Saurabh Gupta, Forrest Iandola, Rupesh Srivastava, Li Deng, Piotr Dollár, Jianfeng Gao, Xiaodong He, Margaret Mitchell, John C. Platt, C. Lawrence Zitnick, Geoffrey Zweig, CVPR, 2015. |
|
| 原文链接 |
http://arxiv.org/pdf/1411.4952 |
|
| 关键词 |
自动生成图像描述 |
|
| 研究问题 |
学习图像描述生成新的图像描述 |
|
| 研究方法 |
直接从图像标题数据集中学习视觉检测器、语言模型和多模态相似性模型。 该系统在图像和对应的字幕上进行训练,并学习从图像中的区域中提取名词、动词和形容词。这些检测到的单词然后指导一个语言模型生成阅读良好并包含检测到的单词的文本。最后,我们使用本文引入的全局深度多模态相似性模型对候选字幕进行重排序。 CNN AlexNet 或 VGG CNN DMSM学习两个神经网络,将图像和文本片段映射到一个共同的向量表示。我们通过度量图像和文本对应向量之间的余弦相似度来度量图像和文本之间的相似度。 |
|
| 研究结论 |
比人类书写快 |
|
| 创新不足 |
很难评 |
|
| 额外知识 |
image captions:图像描述 |
|
| 48.文献阅读笔记 |
||
| 简介 |
题目 |
Show, Attend, and Tell: Neural Image Caption Generation with Visual Attention |
| 作者 |
Kelvin Xu, Jimmy Lei Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhutdinov, Richard S. Zemel, Yoshua Bengio, arXiv:1502.03044 / ICML 2015 |
|
| 原文链接 |
||
| 关键词 |
图像描述 |
|
| 研究问题 |
描述了如何使用标准的反向传播技术以确定性的方式训练这个模型,并通过最大化一个变分下界来随机地训练这个模型。我们还通过可视化展示了模型如何能够在输出序列中生成相应的单词的同时,自动学习将目光固定在显著对象上。 |
|
| 研究方法 |
Cnn+lstm+注意力机制 引入了一个基于注意力的模型,该模型自动学习描述图像的内容。   注意力: “软”“硬”注意力结合。  |
|
| 研究结论 |
提出的注意力框架并不明确使用对象检测器,而是从头开始学习潜在排列。模型能够超越 "对象性",学习关注抽象概念。 利用学习到的注意力来赋予模型生成过程更多的可解释性,并证明了学习到的对齐非常符合人类的直觉。 |
|
| 创新不足 |
||
| 额外知识 |
Caption:说明文字 注意力:注意力不是将整个图像压缩成静态的表征,而是让突出的特征在需要时动态地凸显出来。当图像中存在大量杂波时,这一点尤为重要。使用表征(如来自卷积网络顶层的表征)将图像中的信息提炼为最突出的对象,是一种有效的解决方案。这种方法有一个潜在的缺点,那就是会丢失一些信息,而这些信息对于更丰富、描述性更强的字幕可能是有用的。使用更低级的表示法有助于保留这些信息。然而,使用这些特征需要一个强大的机制来引导模型获取对当前任务非常重要的信息。 Attention Mechanism:注意力机制 而在注意力机制中,每个神经元的输出不仅仅取决于前一层的所有神经元的输出,还可以根据输入数据的不同部分进行加权,即对不同部分赋予不同的权重。这样可以使模型更加关注输入序列中的关键信息,从而提高模型的精度和效率。 【深度学习】(1) CNN中的注意力机制(SE、ECA、CBAM),附Pytorch完整代码_se注意力机制_立Sir的博客-CSDN博客 |
|
| 49.文献阅读笔记(基于短语而不是单词) |
||
| 简介 |
题目 |
Phrase-based Image Captioning |
| 作者 |
Remi Lebret, Pedro O. Pinheiro, Ronan Collobert, arXiv:1502.03671 / ICML 2015 |
|
| 原文链接 |
http://arxiv.org/pdf/1502.03671 |
|
| 关键词 |
生成图像的新颖文本描述 |
|
| 研究问题 |
在给定样本图像的情况下生成描述性句子,对描述的语法有很强的专注性 |
|
| 研究方法 |
提出了一个简单的模型,能够从图像样本中推断不同的短语。从预测的短语来看,模型能够使用统计语言模型自动生成句子。  CNN获得图像特征。 短语初始化:词向量表示:通过利用这些词向量表示通过简单求和组成的能力,短语的表示可以很容易地通过元素加法来计算。  短语构成句子:在识别出图像 中最有可能的 L 个成分短语之后,从这些成分中生成句子。使用统计语言框架,给定一个句子的可能性。 对句子解码:剪枝,短语只出现一次,句法限制。 对生成的句子进行排序,以选择与图像最匹配的句子。  |
|
| 研究结论 |
在不使用复杂的循环网络的情况下,句子生成问题可以有效地实现。我们的算法,尽管比最先进的模型更简单,但在这项任务上取得了类似的结果。此外,我们的模型生成了训练集中通常不存在的新句子。 |
|
| 创新不足 |
未来的研究方向将朝着利用无监督数据和更复杂的语言模型的方向发展 |
|
| 额外知识 |
None |
|
| 50.文献阅读笔记(泛化) |
||
| 简介 |
题目 |
Learning like a Child: Fast Novel Visual Concept Learning from Sentence Descriptions of Images |
| 作者 |
Junhua Mao, Wei Xu, Yi Yang, Jiang Wang, Zhiheng Huang, Alan L. Yuille, arXiv:1504.06692 |
|
| 原文链接 |
http://arxiv.org/pdf/1504.06692 |
|
| 关键词 |
从少量示例中学习物体新类别的问题(有时没有足够的数据来识别新概念,因此需要从以前学习过的类别中转移知识)不希望每次添加一些带有新概念的图像时都要重新训练整个模型,尤其是在数据量或模型参数非常大的情况下。 |
|
| 研究问题 |
从一些带有句子描述的图像中学习新颖的视觉概念,并且与其他概念的相互作用的任务。 识别、学习和使用新概念是人类最重要的认知功能之一。很小的时候,我们通过观察视觉世界和听父母的句子描述来学习新概念。这个过程一开始是缓慢的,但是当我们积累了足够多的已学过的概念之后,这个过程就会变得更快。
图1:句子新颖视觉概念学习( NVCS )任务示意图。我们从不包含"魁地奇"概念的图像训练的模型(即模型库)开始( 1 )。使用一些带有句子描述的"魁地奇"图像,我们的方法能够学习到"魁地奇"是由人用球打的。 |
|
| 研究方法 |
提出了一种方法,允许模型使用少量示例扩充其单词字典,以描述新概念,而无需大量的再训练。特别是,不需要在所有数据(所有以前学习过的概念和新概念)上从头开始重新训练模型。 基础模型:m-RNN
首先,提出了转置权重共享策略,大大减少了模型中的参数数量。其次,我们用长短时记忆(LSTM)层取代了中的递归层。LSTM 是一种递归神经网络,专门用于解决梯度爆炸和消失问题。
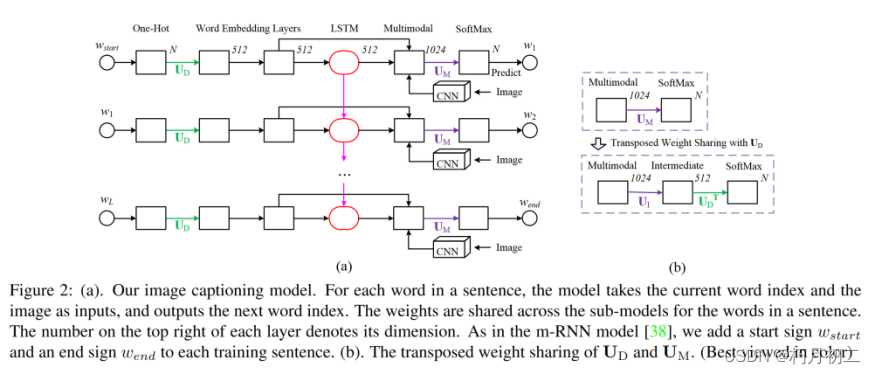
该模型由三个部分组成:语言部分、视觉部分和多模态部分。 语言组件包含两个单词嵌入层和一个 LSTM 层。它将词典中的单词索引映射到语义密集的单词嵌入空间,并将单词上下文信息存储在 LSTM 层中。 视觉组件包含一个在 ImageNet 分类任务中预先训练过的 16 层深度卷积神经网络(CNN)。我们移除了深度卷积神经网络的最后一层 SoftMax,并将顶部的全连接层(4096 维层)连接到我们的模型。这 4096 维层的激活可视为图像特征,其中包含丰富的物体和场景视觉属性。 多模态组件包含一个单层表征,其中语言部分和视觉部分的信息融合在一起。我们在多模态层之后建立了一个 SoftMax 层,用于预测下一个单词的索引。 句子中单词的子模型共享权重。与 m-RNN 模型一样,我们在每个训练句中添加了开始符号 wstart 和结束符号 wend。 在图像描述的测试阶段,我们将起始符号 wstart 输入模型,并根据 SoftMax 层选出 K 个概率最大的最佳词语。重复这一过程,直到模型生成结束符号 wend。 |
|
| 研究结论 |
提出了新颖视觉概念学习( Novel Visual Concept Learning from Sentences,NVCS )任务。在该任务中,方法需要从少量图像的句子描述中学习新颖的概念。我们描述了一种方法,它允许我们在少量包含新概念的图像上训练我们的模型。这与从头开始重新训练的模型在所有数据上的表现相当,如果新颖概念图的数量很大,并且在只有少数新颖概念的训练图像可用时表现更好。 |
|
| 创新不足 |
||
| 额外知识 |
Zero-shot and one-shot learning: Zero-shot learning:【精选】Zero Shot | 一文了解零样本学习-CSDN博客 one-shot learning:One-Shot学习/一次学习(One-shot learning)-CSDN博客 |
|