Tacotron2
摘要
这篇论文描述了Tacotron2,一个从文字直接转化为语音的神经网络。这个体系是由字符嵌入到梅尔频谱图的循环序列到序列神经网络组成的,然后是经过一个修改过后的WaveNet,该模型的作用是将频谱图合成波形图。这个模型取得了不错的效果MOS4.53。为了验证我们的设计选择,我们介绍了系统关键组件的简化测试以及评估了使用梅尔频谱图作为WaveNet的条件输入的影响(不是语言,持续时间和功能)。我们进一步展示了,使用这种紧凑的声学中间表示形式可以大幅度减小WaveNet体系结构的大小。
引言
TTS尽管进行了数十年的调查,但还是有一个大问题。随着时间的推移,不同的技术在这片领域中施展拳脚。单端选择的级联合成,将预先记录的波形拼在一起在之前好长时间都是比较先进的技术。统计参数语音合成,它直接生成语音特征的平滑轨迹是由声码器合成,随后解决了级联合成在声音边界不真实的问题。然而,与人类声音比起来,还是稍显不自然。
WaveNet,是一个时域生成模型,产生的声音可以跟人类媲美,现在好多TTS系统已经在用了。但是WaveNet的输入(语言特征,预测对数基本频率和音素持续时间),需要大量的专业领域知识才能产生,其中包含精心设计的文本分析系统以及强大的词典(发音指南)。
Tacotron,是一个序列到序列的结构,可以从一系列的字符产生频谱图,简化了传统语音合成流程,仅仅根据数据训练的单个网络来代替了语言和声学特征。为了对所得的频谱图进项语音编码,Tacotron使用了Griffin-Lim算法进行相位估计,然后进行短时傅立叶逆变换。按作者所说,这个只是一个临时用的,与Griffin_Lim相比,WaveNet在质量上更有优势。
这篇文章中,我们描述了一个统一的,结合了以前经验的最佳方法,全部由神经网络完成:一个可以产生梅尔频谱图的序列到序列的Tacotron样式的模型,跟一个WaveNet声码器。直接对字符和相应的波形进行训练,模型的效果很好,和真人效果不分伯仲。
DeepVoice3也是一个相似的方法,然而,不同于我们的系统,他做出来的声音还没有证明出和人一样。Char2Wav也是相似的方法,加了一个神经声码器,然而,他们用到了不用的中间表示形式,并且其模型架构也有很大差异。
2 模型架构
我们提出的系统包含两个组件,如下图所示。
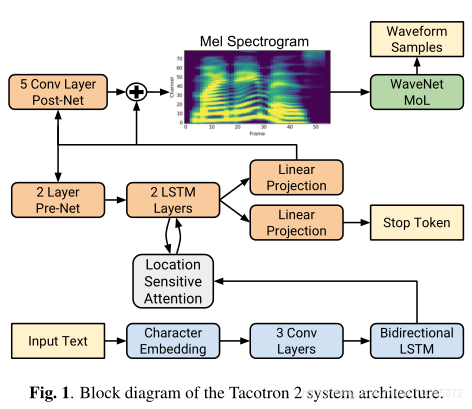
- 一个有注意力机制的循环序列到序列特征预测网络,该网络很具输入的序列字符可以预测梅尔频谱图的序列。
- 一个改进版本的WaveNet它可以根据梅尔频谱图产生时域波形图
2.1 内部特征表示
在这次工作中,我们选了一个低级的声音表示:梅尔频谱图,来连接两个部分。使用时域波形计算的表示形式,我们可以更加容易地分别训练两个分量。这个表示也比波形样本更加平滑,而且使用平方误差损失也更好训练,因为它在每一帧内的相位都是不变的。
梅尔频谱图和线性频谱图相关的,也就是,短时傅立叶变化。它是通过对STFT的频率轴进行非线性变换而获得的,并受到来自人类听觉系统的测量相应启发,并以较少的纬度总结了频率内容。然后就是介绍了梅尔频谱图的优势吧,在较低的频率中强调细节,还能踢出杂音,因为这个,所以就霸占了好多年。
线性频谱图会丢弃相位信息,而诸如Griffin-Lim之类的算法能够估算丢弃的信息,从而可以通过短时傅立叶逆变换进行时域转换。梅尔频谱图甚至丢掉了更多的信息,提出了具有挑战性的逆问题。然而,和WaveNet中使用的语言和声学特征相比,梅尔频谱图又是简便的,音频信号的低级表示。
2.2 频谱图预测网络
和Tacotron一样,梅尔频谱图是通过使用50ms帧大小,12.5ms帧移,汉宁窗截取的短时傅立叶变化计算的。我们以5ms的帧移进行了实验,以匹配原始WaveNet中的条件输入频率,但是有许多发音问题。
我们使用跨度为125Hz到7,6kHz的80通道梅尔滤波器将STFT转换为梅尔标度,然后进行对数动态范围压缩。在对数压缩之前,将滤波器的输出幅度限制为最小值0.01,以限制对数域中的动态范围。
这个网络用注意力机制的编码器和解码器组成。解码器包含一个字符转换为隐形的表征,解码器将其消融然后预测出频谱图。用学习到了512维字符嵌入来表示输入的字符,字符嵌入就会经过3个卷积层,每个卷积层包含512个形状为5*1的过滤器,即每个过滤器跨越5个字符,然后进行批归一化和ReLU激活。像在Tacotron一样,这些卷积层再输入字符序列中模拟长句子上下文。最后卷积层的输出传递到包含512个单位(每个方向256个)的单个双向LSTM层中,已生成编码特征。
编码器的结果被送到注意力机制中,对于每个解码器输出步骤,将完整编码的序列总结为固定长度的上下文向量。我们用了位置敏感注意力机制,它扩展了附加注意力机制,以使用先前解码器时间步长中累计注意权重作为附加功能。这个注意力机制再输入中始终向前移动,从而减轻了潜在的故障,其中包含序列被解码器重复或忽略。使用32个长度为31的一维卷积滤波器来计算位置特征,将输入和位置特征投射到128维隐藏表征中,计算出注意权重。
解码器是一个自回归循环神经网络,可从编码的输入序列一次预测一帧的梅尔频谱图。上一步预测的频谱首先被传入一个小小的预网络,这个预网络是有两层全连接,每层包含256个ReLU单元。其作为一个瓶颈预网络对于学习特征真的很重要。这个预网络的输出和注意力上下文向量拼在一起,传给一个两层堆叠的由2014单元组成的单向LSTM。LSTM输出和注意力上下文向量拼接在一起,然后经过一个线性投影来预测目标频谱帧。最终,将预测的梅尔频谱帧的通过5层卷积的后处理网络的残差网络预测频谱帧。后处理网络每层由512个5*1卷积核组成,后接批归一化层,出了最后一层卷积,每层都用tanh激活。
我们最小化后网络前后的求和均方误差(MSE),以帮助收敛。我们也通过使用混合密度网络对输出分布进行建模来对数似然损失进行了实验,以避免假设随时间的变化是恒定的牡丹石发现更加难以训练并且不会带来更好的声音样本。
与频谱帧预测并行,解码器LSTM的输出和注意力上下文向量连接在一起,投影成一个标量送到sigmoid激活函数,来预测输出的序列完成时候已完成的概率。在推断过程中stop token自发地去终止程序,而不是在固定的时间内。具体而言,生成在概率超过阈值0.5的第一帧处完成。
网络中卷积层用的是dropout 0.5,LSTM使用zoneout0.1来正则化。为了推断时引入输出变化,概率为0.5的丢失仅应用于自回归编码器的预处理网络。
和原始的Tacotron相比,这个模型更简便了,编码器和解码器都是用的是普通的LSTM和卷积层,Tacotron中使用的CBHG堆叠结构和GRU。在输出也没有使用缩小因子,每个解码步骤只输出一个单独的频谱帧。
2.3 WaveNet 声码器
我们用的是一个修改的WaveNet结构,用来吧梅尔频谱图转换成时域波形图。作为原始的结构,有30个空洞卷积,分三次进行,k层的扩张率等于2的p次方,p等于k(mod10)。为了处理频谱图帧的12.5ms帧跳,调节堆栈中仅使用两个上采样层,而不是三层。
没有像WaveNet那样使用softmax层预测离散片段,然后借鉴了PixelCNN++和Parallel WaveNet,并使用Logistic分布(MoL)的10元混合逻辑分布来生成频率24kHz的16位深的语音样本。为了计算混合逻辑分布,WaveNet的堆叠输出传给ReLU激活函数,再连接一个线性投影层来为每一个混元预测参数。损失函数使用标定真实数据的负对数似然函数计算而得。
3 实验结果
3.1 训练步骤
我们的训练过程包含了先独立训练特征预测网络,然后再基于特征预测网络的输出,来训练改良版的WaveNet。
为了训练特征训练网络,我们在单个GPU上指定训练批次为64,采用标准的最大似然训练程序,在解码器传入的不是预测结果,而是正确结果,这样的方法被称为teacher-forcing。我们使用Adam优化器并设定参数β1=0.9,β2=0.999,ε=10-6和学习率10-3在50000次迭代都开始以指数方式递减方式递减至10-5。我们也应用了权重为10-6的L2正则化。
我们然后训练修改版的WaveNet,用的是预测网络的预测结果与标定数据对齐。也就是说,预测数据都在是teacher-forcing模式下产生的:所预测的每一帧是基于编码的输入序列以及所对应的前一帧标定数据频谱,这就保证了每一个预测帧与目标波形样本完全对齐。
然后训练是在32个GPU上128批次训练,优化器还是Adam,β1=0.9,β2=0.999,ε=10-8和固定学习率10-4。它有助于使用最近的更新来优化平均模型的权重。所以我们在更新网络参数时使用衰减率为0.9999的指数加权平均,反正就是更好了,为了加速收敛,将波形图放大了127.5倍,使得混合逻辑层的初始输出更接近于最终分布。
我们训练Tacotron在北美英语数据上,包含了24.6小时的女性专业说话声音,短语也是文本标准化的。例如“16”就是sixteen
3.2 评估
在推理阶段生成语音的时候,是没有标定数据的,所以与训练的时候不一样,就直接在解码处理中穿额度上一步的预测结果。
emmm接下来就是对比实验
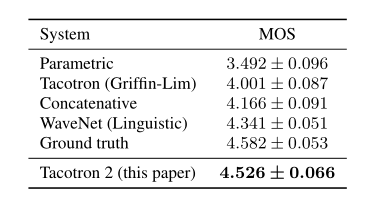
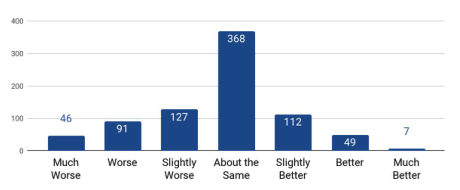


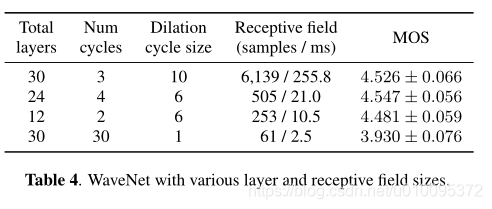 声谱预测网络(Tacotron2)
声谱预测网络(Tacotron2)
Tacotron2 论文 + 代码详解
