| 58.文献阅读笔记(LRCNs) |
||
| 简介 |
题目 |
Long-term Recurrent Convolutional Networks for Visual Recognition and Description |
| 作者 |
Jeff Donahue, Lisa Anne Hendricks, Marcus Rohrbach, Subhashini Venugopalan, Sergio Guadarrama, Kate Saenko, Trevor Darrell, CVPR, 2015. |
|
| 原文链接 |
||
| 关键词 |
||
| 研究问题 |
理想情况下,一个视频模型应该允许处理可变长度的输入序列,并提供可变长度的输出,包括生成超出传统的一对一预测任务的完整句子描述。 |
|
| 研究方法 |
 Image caption: 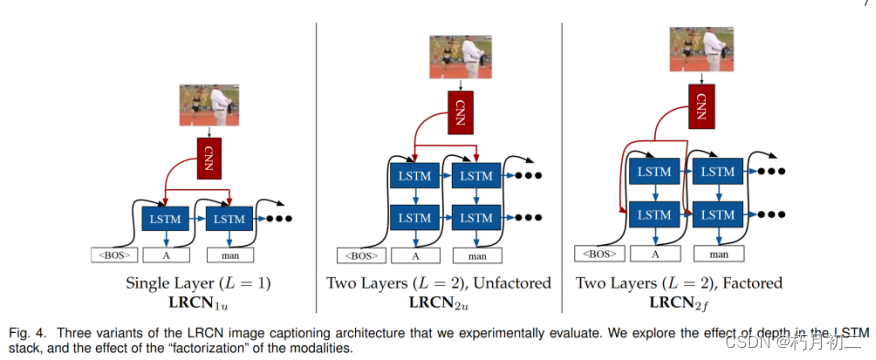 在两个任务和所有指标下,两层、无事实根据的变体(LRCN2u)的性能都比其他两种变体差。LRCN1u 优于 LRCN2u 的事实表明,单独堆叠额外的 LSTM 层对这项任务并无益处。其他两个变体(LRCN2f 和 LRCN1u)的整体表现类似,在大多数指标下,LRCN2f 在从图像到标题的任务中似乎略胜一筹,但在从标题到图像的检索中却恰恰相反。 对 CNN 进行微调和使用功能更强大的 CNN(VGGNet而不是 CaffeNet)都能大幅改善各方面的结果。 Video description:
对于每种架构,我们都假定已经根据完整的视频输入,通过 CRF 预测了视频中的活动、工具、物体和位置。这样,我们就能在每个时间步长观察到整个视频,而不是逐帧增量观察。
(1) LSTM 优于基于 SMT 的视频描述方法;(2) 更简单的解码器架构 (b) 和 (c) 比 (a) 取得了更好的性能,这可能是因为输入不需要记忆; |
|
| 研究结论 |
证明 LSTM 类型的模型可以提高传统视频活动挑战的识别率,并实现从图像像素到句子级自然语言描述的新颖端到端优化映射 |
|
| 创新不足 |
||
| 额外知识 |
简单的 RNN 模型在时间上严格整合状态信息,其一个显著的局限性就是所谓的 "梯度消失 "效应:在实践中,通过长距离时间间隔反向传播误差信号的能力变得越来越困难。 长短期记忆(LSTM)单元最早是在文献[7]中提出的,它是一种能够实现长距离学习的递归模块。LSTM 单元的隐藏状态使用非线性机制进行增强,允许状态在不修改的情况下传播、更新或重置,使用的是简单的学习门控函数。 |
|

| (59.)45.文献阅读笔记 |
||
| 简介 |
题目 |
Translating Videos to Natural Language Using Deep Recurrent Neural Networks |
| 作者 |
Subhashini Venugopalan, Huijuan Xu, Jeff Donahue, Marcus Rohrbach, Raymond Mooney, Kate Saenko, NAACL-HLT, 2015. |
|
| 原文链接 |
||
| 关键词 |
视频翻译 |
|
| 研究问题 |
将视频直接翻译成句子.描述的视频数据集稀缺,现有的大多数方法已被应用于可能词汇量较小的玩具领域。人们已经提出了针对具有一小部分已知动作和对象的狭窄领域的解决方案. |
|
| 研究方法 |
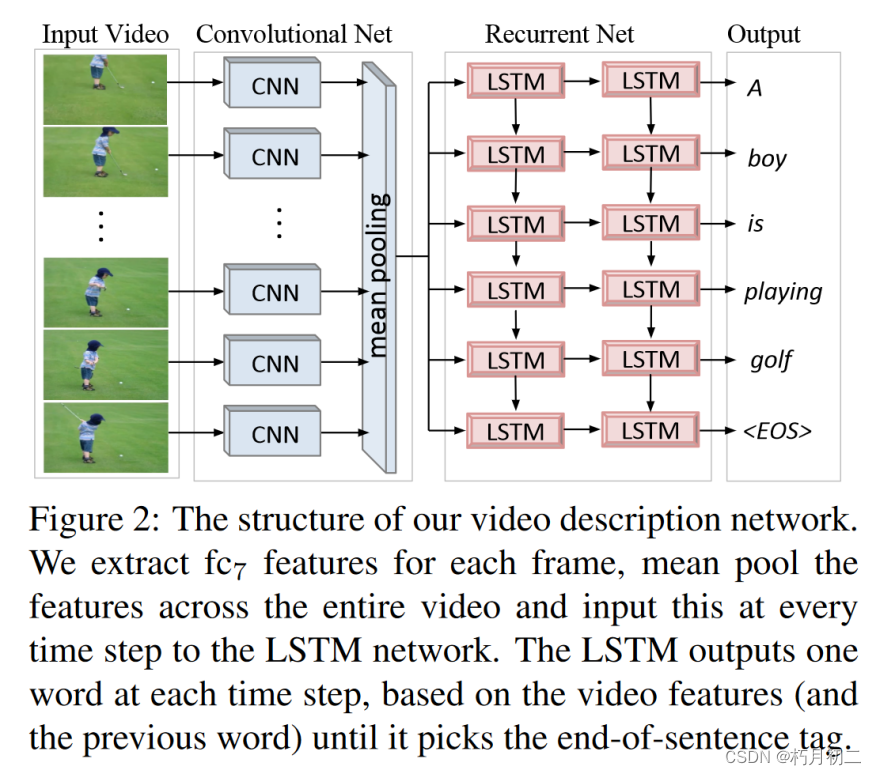 同时具有卷积和循环结构的统一深度神经网络将视频直接翻译成句子。 该网络在 120 多万张带有类别标签的图像上进行了预先训练. 他们将其模型的一个版本应用于视频到文本的生成,但没有提出端到端的单一网络,而是使用了中间角色表示。 利用长短期记忆(LSTM)递归神经网络来建立序列动态模型,但将其直接连接到深度卷积神经网络来处理传入的视频帧,从而完全避免了监督中间表征。 |
|
| 研究结论 |
提出了一种用于视频描述的模型,该模型使用神经网络从像素到句子的整个流水线,并且可以潜在地允许整个网络的训练和调整。在一个广泛的实验评估中,我们表明我们的方法比相关的方法生成更好的句子。我们还表明,与仅依赖视频描述数据相比,利用图像描述数据可以提高性能。然而,我们的方法在更好地利用视频中的时间信息方面存在不足 |
|
| 创新不足 |
每帧都进行卷积处理,运算量太大. 58证明一层lstm会更好 |
|
| 额外知识 |
||
| 60.文献阅读笔记 |
||
| 简介 |
题目 |
Joint Modeling Embedding and Translation to Bridge Video and Language |
| 作者 |
Yingwei Pan, Tao Mei, Ting Yao, Houqiang Li, Yong Rui |
|
| 原文链接 |
arXiv:1505.01861 |
|
| 关键词 |
||
| 研究问题 |
生成的描述语言语境正确但是语义不正确。 |
|
| 研究方法 |
a novel unified framework, named Long Short-Term Memory with visual-semantic Embedding (LSTM-E),可以同时探索LSTM和视觉-语义嵌入的学习。 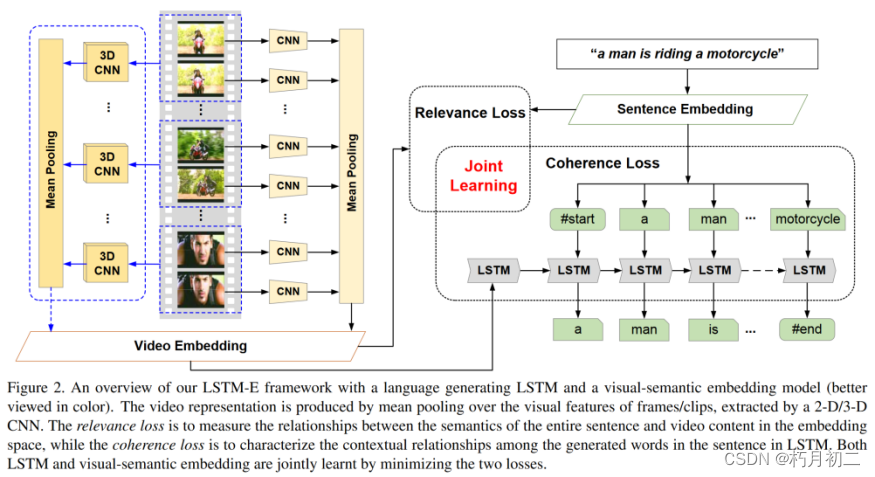 视频表示是通过对由2 - D / 3-D CNN提取的帧/片段的视觉特征进行平均池化产生的。相关性损失是在嵌入空间中度量整个句子的语义与视频内容之间的关系,而相干性损失是在LSTM中刻画句子中生成词之间的上下文关系。LSTM和视觉-语义嵌入都是通过最小化这两个损失来联合学习的。 |
|
| 研究结论 |
通过引入一种新颖的 LSTM-E 模型结构,为视频描述问题提出了一种解决方案。特别是在 LSTM 学习中加入了视觉语义嵌入空间。这样,在 LSTM 学习中,除了每一步的单词与前一步的单词之间的局部上下文关系外,还能同时测量视频内容与句子语义之间的全局关系。在一个流行的视频描述数据集上,我们的实验结果证明了我们的方法是成功的,在 SVO 预测和句子生成方面,我们都以显著的优势超越了目前最先进的模型。 |
|
| 创新不足 |
||
| 额外知识 |
||
| 61.文献阅读笔记 |
||
| 简介 |
题目 |
Sequence to Sequence--Video to Text |
| 作者 |
Subhashini Venugopalan, Marcus Rohrbach, Jeff Donahue, Raymond Mooney, Trevor Darrell, Kate Saenko |
|
| 原文链接 |
arXiv:1505.00487 |
|
| 关键词 |
视频描述 |
|
| 研究问题 |
视频描述 |
|
| 研究方法 |
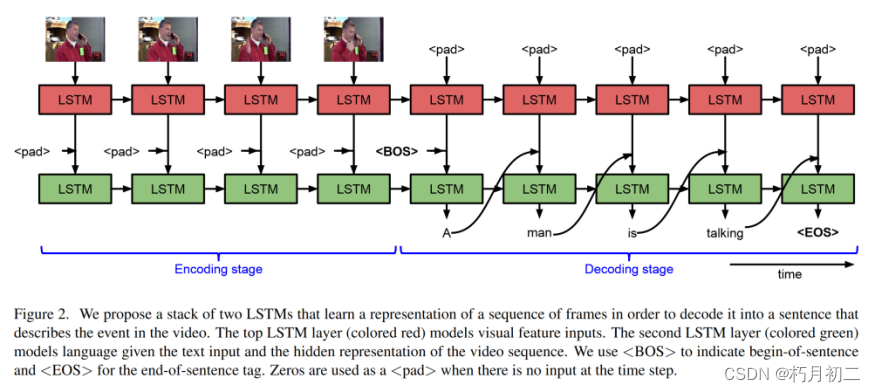
图2。我们提出了一个由两个LSTM组成的堆栈,学习一个帧序列的表示,以便将其解码为一个描述视频中事件的句子。顶层LSTM层(彩色红色)对视觉特征输入进行建模。第二层LSTM层(彩色绿色)模型语言给出了文本输入和视频序列的隐藏表示。我们用来表示句子的开头,用来表示句子的结尾。当时间步没有输入时,零被用作a。 |
|
| 研究结论 |
使用序列到序列模型来构建描述,其中首先顺序读取帧,然后顺序生成单词。这使得我们可以同时处理变长的输入和输出,同时对时间结构进行建模。我们的模型在MSVD数据集上取得了最先进的性能,并且在两个大型且具有挑战性的电影描述数据集上超过了相关工作。 |
|
| 创新不足 |
||
| 额外知识 |
Rgb图像提取objrct;光流法提取动作。 |
|

| 62.文献阅读笔记 |
||
| 简介 |
题目 |
Describing Videos by Exploiting Temporal Structure |
| 作者 |
Li Yao, Atousa Torabi, Kyunghyun Cho, Nicolas Ballas, Christopher Pal, Hugo Larochelle, Aaron Courville |
|
| 原文链接 |
arXiv:1502.08029 |
|
| 关键词 |
natural language descriptions of videos |
|
| 研究问题 |
natural language descriptions of videos |
|
| 研究方法 |
  结合了视频的局部时间动态(也就是说,在几个帧的块内)模型,以及它们的全局时间结构。使用3 - D CNN的时间特征图对局部结构进行建模,同时使用时间注意力机制来组合整个视频的信息。 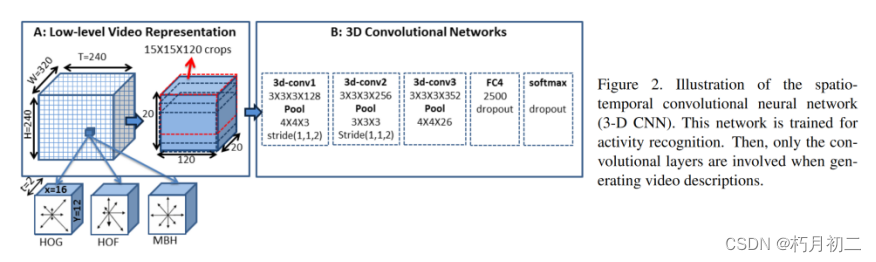 |
|
| 研究结论 |
发现并强调了除了帧外观信息外,捕捉局部和全局时间结构的重要性。为此,我们提出了一种新颖的三维卷积神经网络,旨在捕捉连续帧的局部细粒度运动信息。为了捕捉全局时间结构,我们建议使用一种时间注意力机制,学习聚焦于帧子集的能力。最后,我们提出的这两种方法自然地结合到了编码器-解码器神经视频字幕生成器中。我们在 Youtube2Text 和 DVS 数据集上根据四个标准评估指标对每种方法进行了实证验证。实验表明,使用这两种方法的模型都比基线模型有所改进。此外,将这两种方法结合在一起可以获得最佳性能。 |
|
| 创新不足 |
||
| 额外知识 |
||
| 63.文献阅读笔记 |
||
| 简介 |
题目 |
The Long-Short Story of Movie Description |
| 作者 |
Anna Rohrbach, Marcus Rohrbach, Bernt Schiele |
|
| 原文链接 |
arXiv:1506.01698 |
|
| 关键词 |
视频描述 |
|
| 研究问题 |
视频描述 |
|
| 研究方法 |
 两步视频描述方法。第一步进行视觉识别,第二步生成文本描述。对于视觉识别,我们提出使用根据标签的语义和"可视性"训练的视觉分类器。对于语言生成,我们依赖一个已经成功用于图像和视频描述的LSTM网络。 初始标签集合 标签对应不同的语义组。在这项工作中,考虑了三个最重要的语义组:动词(动作)、物体和地点,因为它们通常是可视的。还可以考虑心情或情绪等组,这些组自然更难进行视觉识别。我们建议独立处理每个标签组。首先,我们对每个语义组采用不同的表示方法,针对特定组进行识别。 舍弃所有不属于我们所关注的三组中任何一组的标签,因为我们认为这些标签很可能不是可视的,因此很难识别。 要求分类器具有最小的 ROC 曲线(Receiver Operating Characteristic)下面积 |
|
| 研究结论 |
在 MPII-MD 数据集上获得了最高的性能,所有自动评估指标和广泛的人工评估都表明了这一点。有助于获得更高绩效的因素包括:频繁出现的词语、句子的长度和简洁性,以及 "视觉 "动词(如 "点头"、"走路"、"坐下"、"微笑")的出现。句子/片段的文字和视觉难度与所有方法的性能密切相关。我们观察到,数据中人类作为主语和类似于 "看 "的动词的偏差很大。未来的工作必须侧重于处理频率较低的词语和视觉描述。这可能需要考虑外部文本语料库、视频以外的其他模式(如音频和对话),以及对多个句子进行研究。这样就可以利用长短语境,从而理解和描述电影故事。 |
|
| 创新不足 |
||
| 额外知识 |
||
| 64.文献阅读笔记 |
||
| 简介 |
题目 |
Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books |
| 作者 |
Yukun Zhu, Ryan Kiros, Richard Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, Sanja Fidler |
|
| 原文链接 |
arXiv:1506.06724 |
|
| 关键词 |
将书籍与他们的电影版本进行对齐 |
|
| 研究问题 |
 以便为视觉内容提供丰富的描述性解释,这些内容在语义上远远超出了当前数据集中可用的字幕。 |
|
| 研究方法 |
利用了一个从大量书籍语料中以无监督方式训练的神经句子嵌入,以及一个用于计算电影片段和书籍中句子之间相似性的视频-文本神经嵌入。我们提出了一种上下文感知的CNN来组合来自多个来源的信息。 提出了一个简单的成对条件随机场(CRF),通过鼓励对齐遵循线性时间轴来平滑视频和图书领域的对齐。  给定一个句子元组(si-1、si、si+1),我们的模型首先将句子 si 编码为一个固定向量,然后以该向量为条件,尝试重建句子 si-1 和 si+1 这种架构的灵感来源于分布假说:周围上下文相似的句子很可能在语义和句法上都相似。因此,语法和语义相似的两个句子很可能被编码成相似的向量。 一旦模型训练完成,我们就可以通过编码器映射任何句子,获得向量表示,然后通过内积对其相似性进行评分。该模型的学习信号取决于是否有连续的文本,即句子按顺序相继出现。因此,训练我们模型的天然语料库就是大量的书籍。鉴于书籍的规模和体裁的多样性,我们的 BookCorpus 可以让我们学习到非常通用的文本表征。 使用 GoogLeNet 架构和混合-CNN来提取帧特征 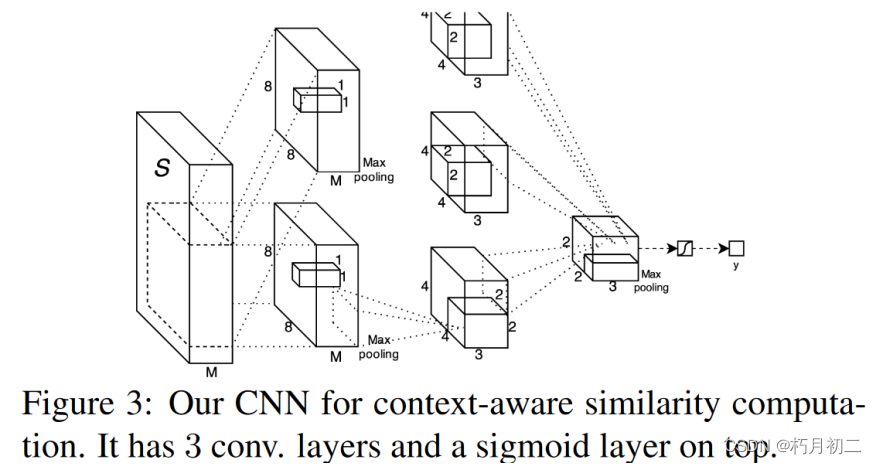 LSTM 架构 |
|
| 研究结论 |
||
| 创新不足 |
||
| 额外知识 |
||
| (55.)65.文献阅读笔记 |
||
| 简介 |
题目 |
Describing Multimedia Content using Attention-based Encoder-Decoder Networks |
| 作者 |
Kyunghyun Cho, Aaron Courville, Yoshua Bengio |
|
| 原文链接 |
arXiv:1507.01053 |
|
| 关键词 |
||
| 研究问题 |
||
| 研究方法 |
||
| 研究结论 |
||
| 创新不足 |
||
| 额外知识 |
||
| 66.文献阅读笔记 |
||
| 简介 |
题目 |
Temporal Tessellation for Video Annotation and Summarization(时空细分: 视频分析的统一方法) |
| 作者 |
Dotan Kaufman, Gil Levi, Tal Hassner, Lior Wolf |
|
| 原文链接 |
arXiv:1612.06950 |
|
| 关键词 |
||
| 研究问题 |
理解和分析视频的通用方法 |
|
| 研究方法 |
VGG-19 CNN+Lstm |
|
| 研究结论 |
我们的设计将每个片段的视频语义从参考、训练视频转移到新的测试视频。我们为这种转移提出了三种替代方法:不使用上下文的局部细分法、使用动态编程应用时间语义一致性的无监督细分法,以及使用 LSTM 预测未来语义的有监督细分法。我们的研究表明,这些方法与最新的视频表示技术相结合,可在三个截然不同的视频分析领域(视频注释、视频摘要和动作检测)提供最先进的结果,并在第四个应用领域(视频声音预测)提供接近最先进水平的结果。我们的方法是独一无二的,因为它是第一个在如此不同的视频理解任务中获得最先进结果的方法,其性能超过了为这些应用量身定制的方法。 |
|
| 创新不足 |
||
| 额外知识 |
||