目录
1.1 机器人规划的配置空间 Configuration Space
1 图搜索基础
1.1 机器人规划的配置空间 Configuration Space
一个机器人的配置表示对机器人上面所有的点的位置的一种描述。
• 机器人自由度(DOF):
表示机器人配置所需的最小实值坐标数量 n
• 机器人配置空间:
包含所有可能的机器人配置的 n 维空间,表示为 C-空间
• 每个机器人位姿是 C-空间中的一个点解释一下这些抽象概念:
机器人配置涉及描述机器人整体结构中各个点的位置。机器人的自由度(DOF)是指用于准确描述机器人配置所需的最小实值坐标数量。这个数值 n 可以理解为机器人在空间中可以独立移动的方向或自由度的数量。
机器人配置空间是一个抽象的概念,表示包含了机器人所有可能配置的 n 维空间,我们通常将其称为 C-空间。在这个空间中,每个不同的机器人姿势都对应着这个空间中的一个唯一点。这样,我们可以通过在 C-空间中的点来表示和理解机器人的各种姿势和位置。这种抽象的概念使得我们能够更方便地处理和分析机器人的运动和配置。
在配置空间如何表示障碍物用于我们的路径规划呢?
在进行运动规划之前,需要在配置空间中表示障碍物,这被称为配置空间障碍物或C-障碍物。这一步骤是一次性的工作,有助于确保在规划机器人运动时考虑和避免这些障碍物,从而使机器人能够找到可行的路径。
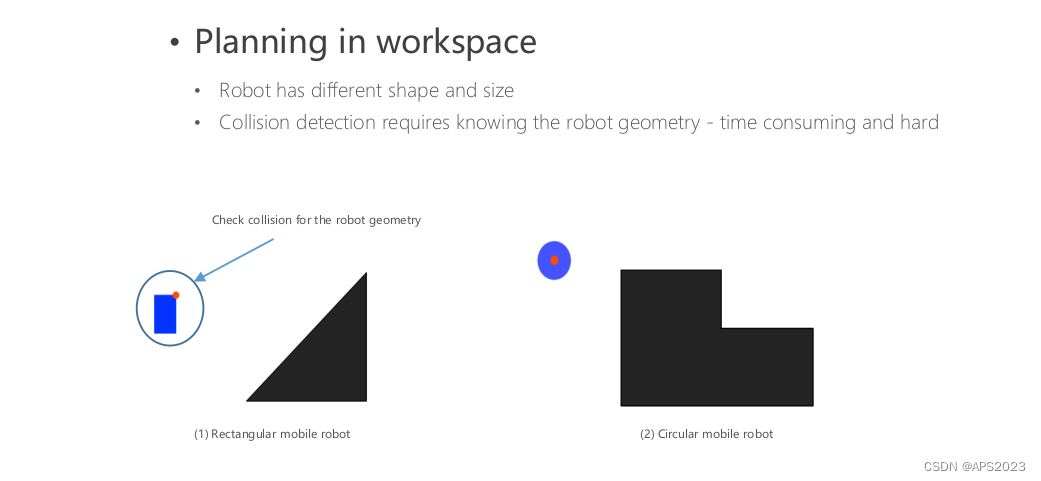
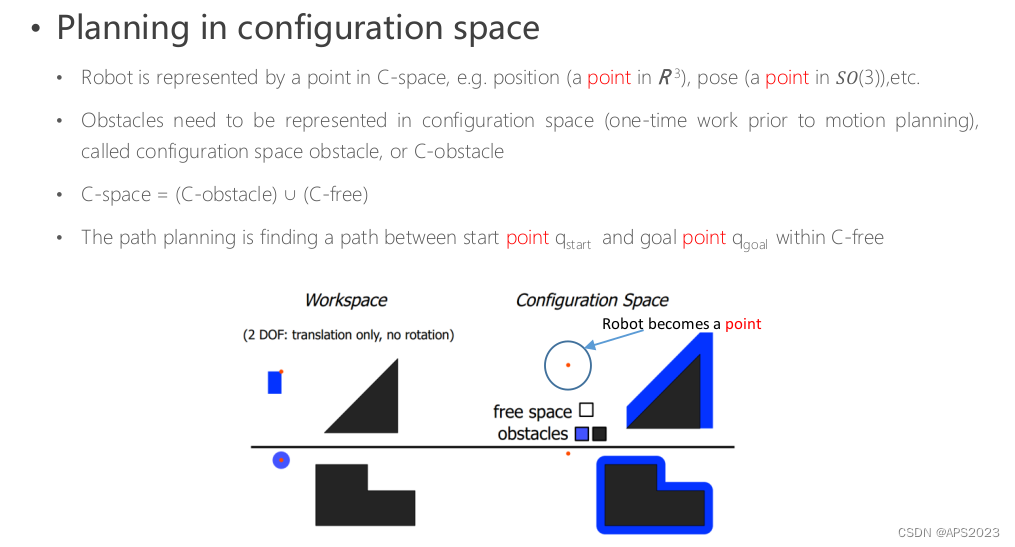
我们从工作空间向配置空间抽象,我们将机器人比作一个点,那么障碍物也需要进行抽象(工作空间的障碍物转换为配置空间的障碍物)
也就是说:
在工作空间中,机器人有尺寸有形状有大小。
在配置空间中,机器人变成了一个点,障碍物经过膨胀。在C-空间中表示障碍物可能会变得非常复杂,因此在实践中通常使用近似但更保守的表示方法。这有助于简化处理,同时确保更加可行的运动规划,尽管是一种近似的处理方式。

1.2 图搜索算法的基本概念
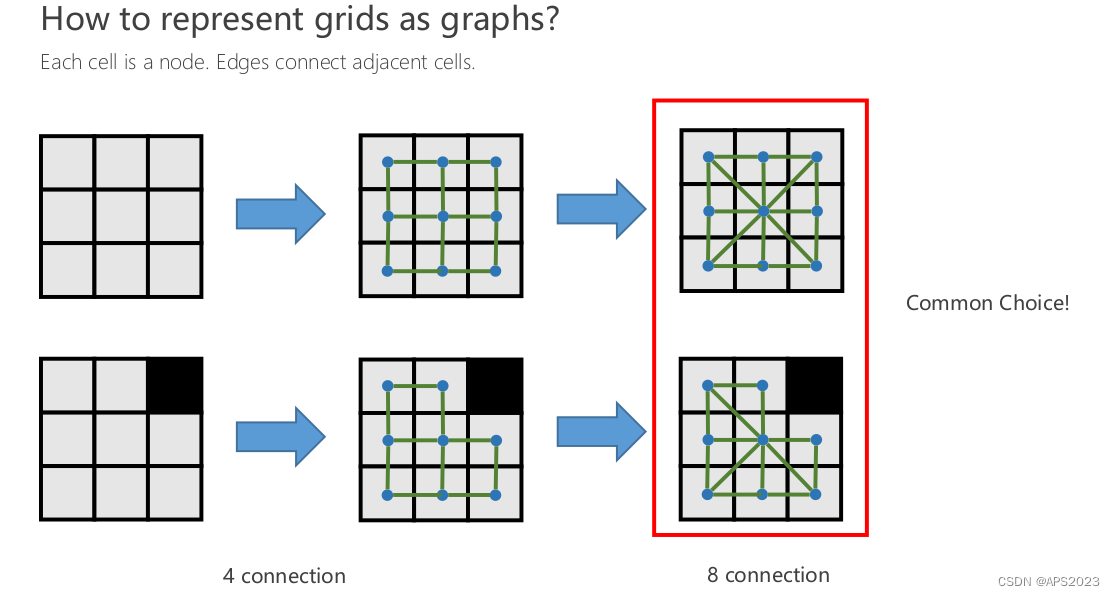
图由节点和边表达,边可以是无向的,有向的。边也可以是有权重、无权重的:
我们对于任何的搜索算法,我们都要构造搜索用的图:
状态空间图是搜索算法的一种数学表示方式,用于描述问题的各个状态以及它们之间的关系。对于每个搜索问题,都可以建立一个相应的状态空间图。在这个图中,每个状态被表示为一个节点,而节点之间的连接则由有向或无向的边来表示。
节点之间的连接通常表示状态之间的转移或可达性。有向边表示一个状态可以直接转移到另一个状态,而无向边可能表示状态之间存在某种关联,但没有特定的方向。
这种图的构建和分析有助于搜索算法理解问题的结构,从而更有效地找到问题的解决方案。
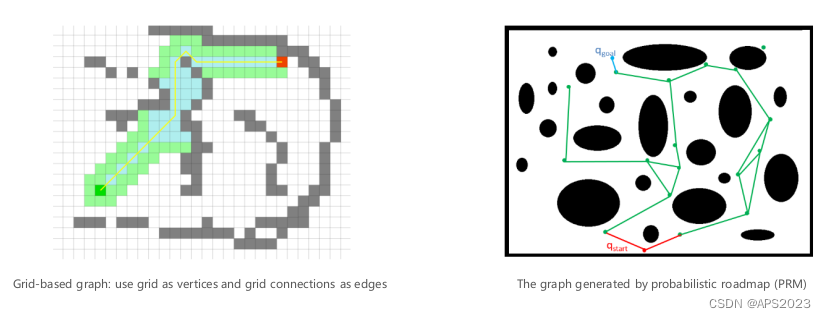
如上图,如果是栅格地图上的路径规划问题。栅格地图上的每个节点天然的与邻居节点存在邻接关系,本身就是图了。如果是基于采样的路径规划,右图,图中只有障碍物的信息,没有天然的连接关系,因此我们需要构建一个图。(由节点和边构成的图)。
S->G搜索。对于图搜索,我们需要构建搜索树。
• 搜索始终从起始状态 XS 开始
• 对图进行搜索产生一棵搜索树
• 在搜索树中回溯一个节点会给我们从起始状态到达该节点的路径
• 对于许多问题,我们实际上无法构建整个树,因为太大或效率低下 — 我们只想尽快到达目标节点。
流程如下:
• 维护一个容器以存储所有待访问的节点
• 该容器以起始状态 XS 进行初始化
• 循环
• 根据预定义的评分函数从容器中移除一个节点
• 访问一个节点
• 展开:获取该节点的所有邻居
• 发现并存储所有邻居
• 将它们(邻居)推入容器
• 结束循环当你启动搜索时,首先要维护一个容器,可以想象成一个存放待访问节点的集合。这个容器最初会被初始化,包含了起始状态XS。
接下来,进入一个循环,该循环是搜索算法的主要操作。在每次循环中,按照预定义的评分函数从容器中选择一个节点。这个评分函数可以是根据节点的启发式估计、代价等因素来确定节点的优先级。
选中的节点被标记为已访问,并进行节点的扩展操作。扩展节点意味着获取该节点的所有邻居。这一步通常包括发现并存储所有邻居,以及将这些邻居推入容器中,以便在后续迭代中进行处理。
整个过程持续进行循环,直到满足某个终止条件,比如找到目标节点或容器为空。这样,搜索算法通过不断选择、访问、扩展节点来探索问题空间,逐步朝着目标前进。这个方法的优势在于在整个搜索过程中只保持了一部分节点,从而提高了搜索的效率。
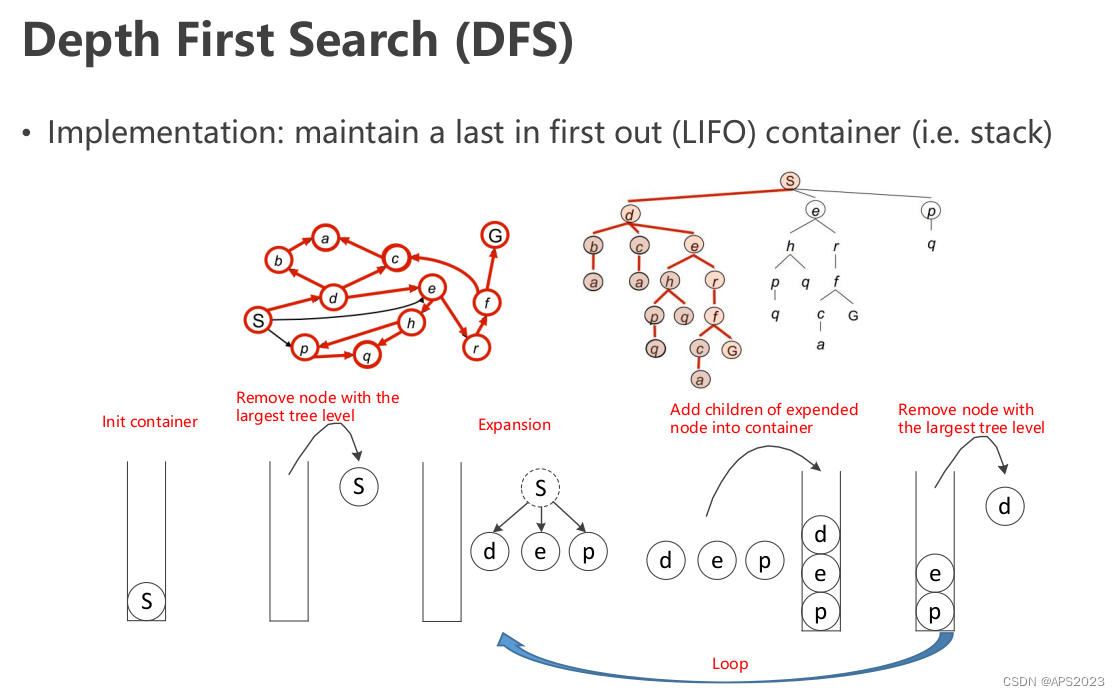
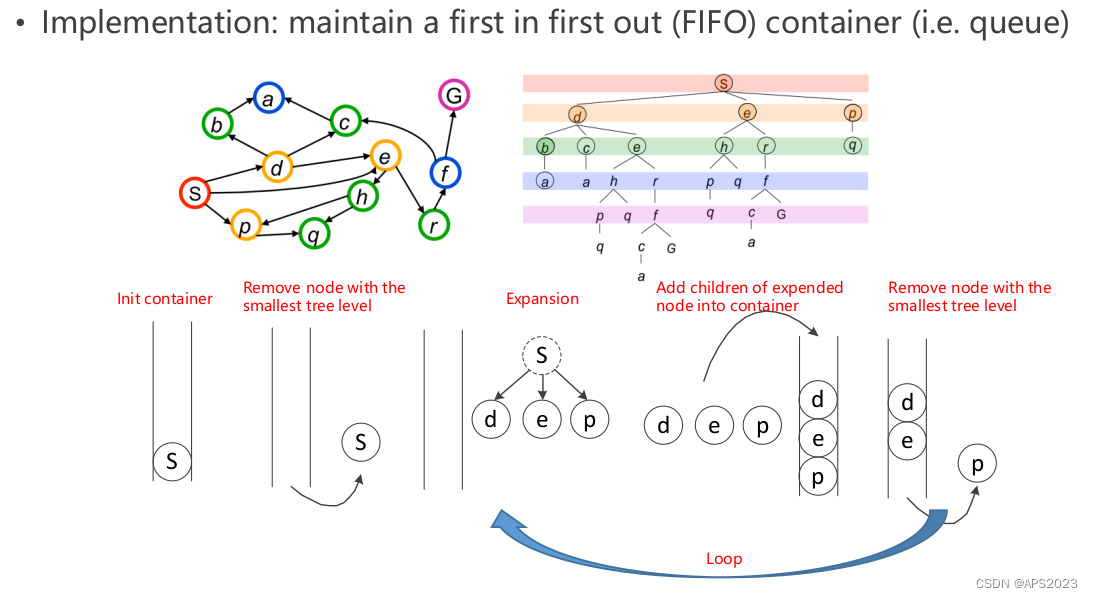
最简单的图搜索算法就是广度优先搜索和深度优先搜索,考研的时候大家肯定考过,这里不过多介绍:
我们指定一个点,搜索到另一个点,可以发现BFS是可以搜索到最优路径的,因为DFS是一条路走到黑。BFS是一层一层进行搜索的。







1.3 启发式的搜索算法 Heuristic search
广度优先搜索(BFS)和深度优先搜索(DFS)是基于“先进先出”或“后进先出”原则从frontiers(边界节点集合)中选择下一个节点的算法。
• 贪心最佳优先搜索则根据一定规则(称为启发式)选择“最佳”节点。启发式是对节点离目标的估计,其通过一种猜测来判断节点的优先级。在BFS中,下一个节点是frontiers队列中最早加入的节点,而在DFS中,下一个节点是frontiers队列中最晚加入的节点。而贪婪最佳优先搜索则通过启发式规则,选择当前被认为最有可能接近目标的节点。
总的来说,这些算法都是在搜索问题空间时选择下一个节点的不同策略,BFS和DFS是基于先进先出或后进先出的原则,而贪婪最佳优先搜索则通过启发式规则选择最有希望接近目标的节点。
启发式函数应该有两个原则:
启发式能指引你朝着正确的方向前进;启发式应该易于计算。
对比一下贪心策略和正常策略:
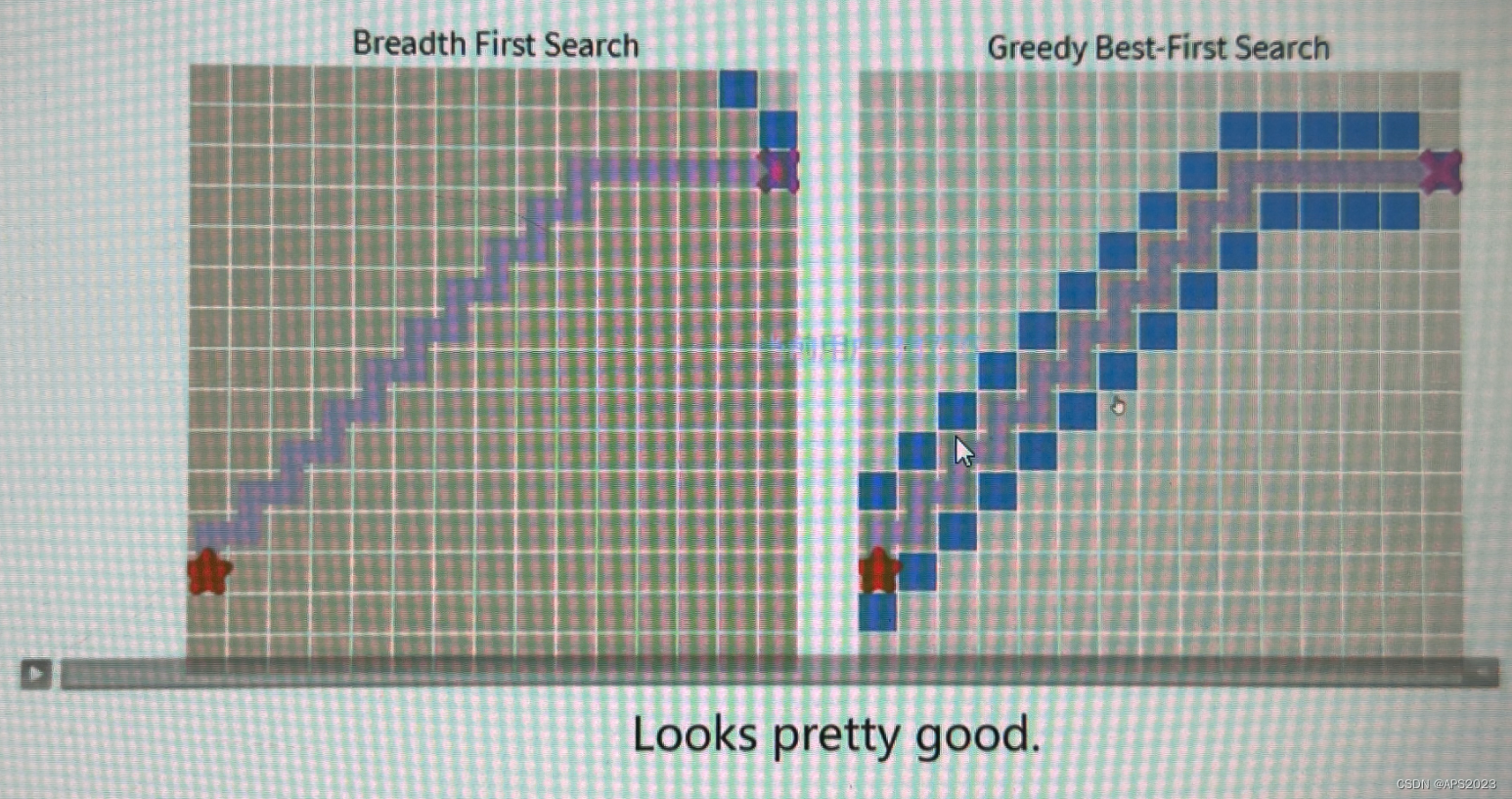
速度上是优于广度优先搜索遍历的。效果是一样的曲率最优的。
在没有障碍物的场景下是优于广度搜索的。
但如果在障碍物的环境中,贪心算法会陷入局部最优的场景:
一个实际的搜索问题存在着从一个节点到其相邻节点的成本“C”。
• 成本可以是长度、时间、能量等等。
• 当所有权重都为1时,BFS可以找到最优解。
• 对于一般情况,如何尽快找到最小成本路径呢?
在一般情况下,可以使用 Dijkstra's 算法或 A* 算法来找到最小成本路径。Dijkstra's 算法适用于所有边权重都为非负的图,它以贪婪的方式选择当前最小成本的节点来扩展搜索。A* 算法结合了启发式函数和实际成本来在搜索过程中更加高效地选择节点,它常用于带有启发式函数的图搜索,可以更快地找到最小成本路径。 这个语句不通顺

2 A* Dijkstra算法
2.1 Dijkstra算法
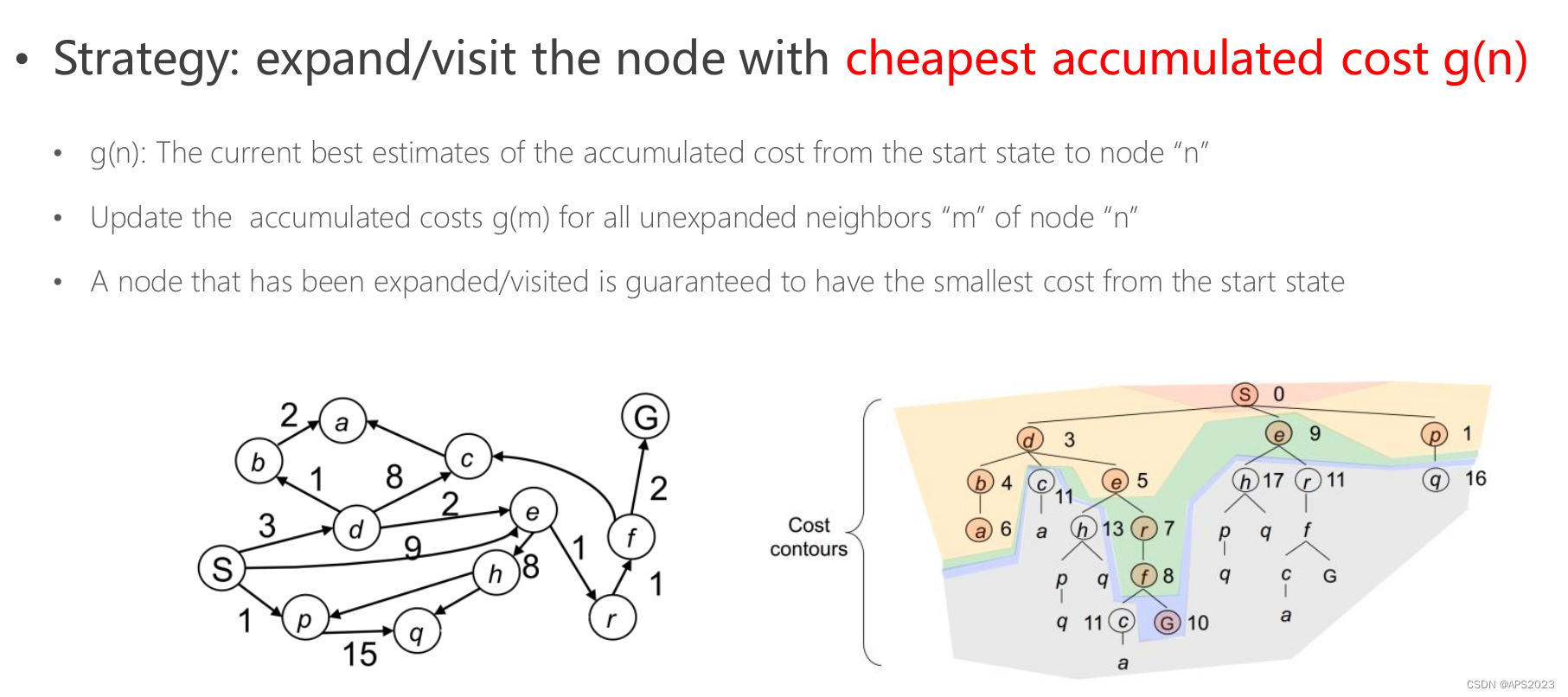
和BFS弹出的规则不同,对于BFS来说是弹出在搜索树中的距离最浅的一个节点。而 Dijkstra算法的原则是弹出的节点包含最小的函数值g(n),它表示从起点到n节点这条路径累计的代价总和最小的特点。
这个策略是这样的:它会优先考虑那些累计成本最低的节点来进行扩展或访问。
• 这里的“累计成本”(g(n))指的是从起始状态到达节点“n”所需的当前最佳估计成本。
• 算法会更新所有未被探索的邻居节点“m”的累计成本(g(m)),确保它们都被考虑到。 • 任何一个被扩展或访问过的节点都可以确保它从起始状态到达的成本是最小的。
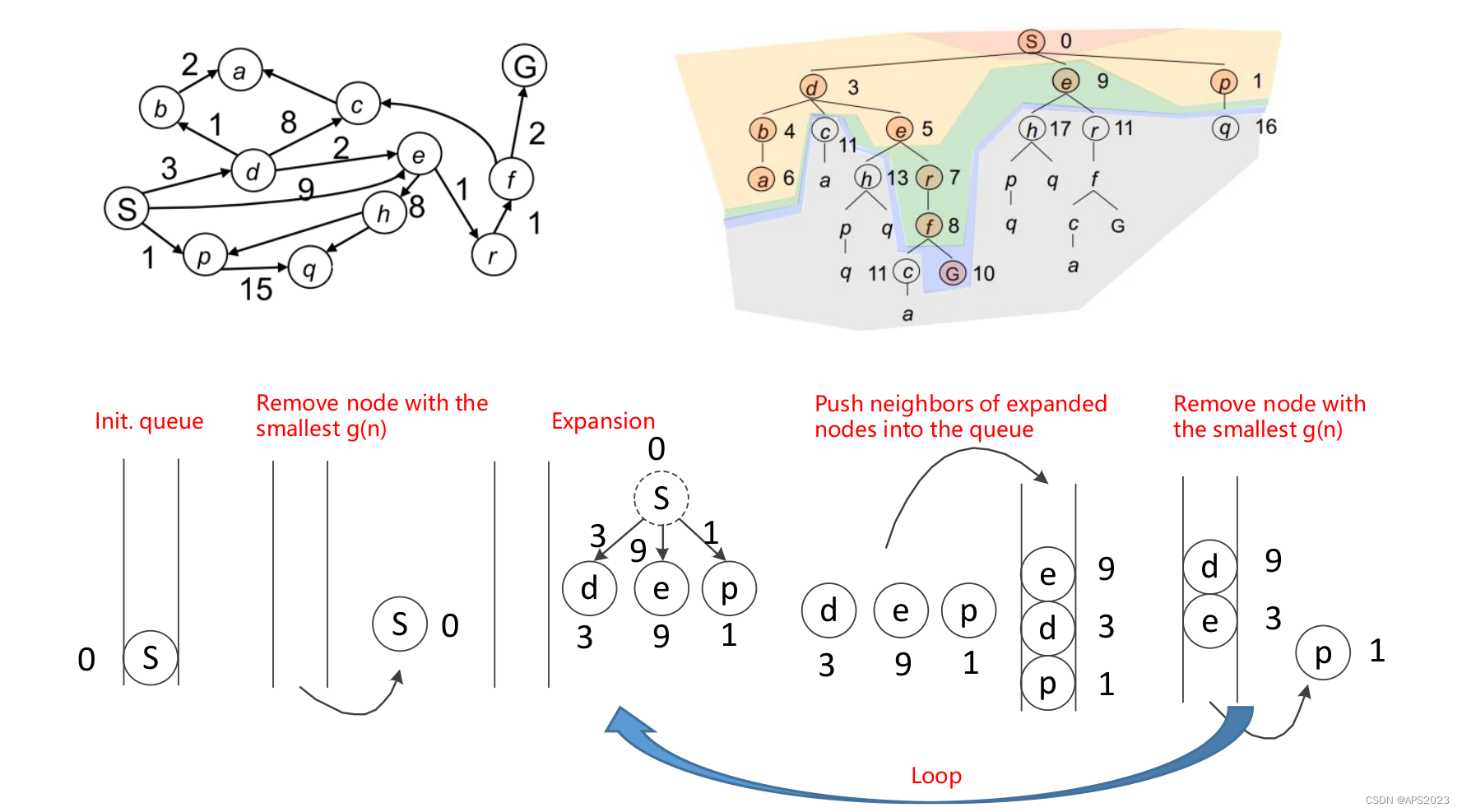
看一下伪代码流程:
1. **维护一个优先队列**:用于存储所有待扩展的节点。
2. **初始化优先队列**:将起始节点X S放入优先队列中。
3. **设定初始成本值**:为起始节点X S 设定 g(X S )=0,而对于图中的其他节点,设定 g(n)=无穷大(表示尚未探索)。
4. **循环开始**:
- 如果队列为空,表示没有可探索的节点,返回FALSE并终止循环。
- 从优先队列中取出具有最小 g(n) 的节点“n”。
- 将节点“n”标记为已扩展。
- 如果节点“n”是目标状态,表示找到了目标,返回TRUE并终止循环。
- 对于节点“n”的所有未被探索的邻居节点“m”:
- 如果 g(m) = 无穷大:
- 计算新的 g(m) = g(n) + Cnm,其中 Cnm 是从节点“n”到节点“m”的成本。
- 将节点“m”放入优先队列中。
- 如果 g(m) > g(n) + C nm:
- 更新 g(m) = g(n) + C nm。
- 结束对邻居节点的循环。
5. **结束循环**。这个算法的主要步骤是不断从优先队列中取出具有最小 g(n) 的节点进行扩展,并更新其邻居节点的成本估计值。通过迭代这个过程,直到找到目标状态或者确定没有更多可探索的节点为止。这种方法通常用于寻找最优路径或解决问题空间中的最小成本路径问题。
我们看一下具体的例子:
如何评价Dijkstra算法:
Good:完备的、最优的
Bad:只能观察到到目前为止累积的成本,也就是说,只知道当前状态到其他状态的代价,但没有有关目标位置的信息。因此,在搜索时会沿着每个可能的方向继续探索下一个状态,但并不知道哪个方向是最终目标所在的位置。
思考?是不是如果没有权重的话和广度优先搜索遍历是一样的,因此它是盲目的...。
如果我们加入贪心算法:
这是关于启发式搜索的一些重要点:
• **回顾贪心最佳优先搜索中的启发式方法**:在贪心最佳优先搜索中,启发式方法用于指导搜索,根据某种规则选择下一个节点,通常是基于节点到目标的估计距离。
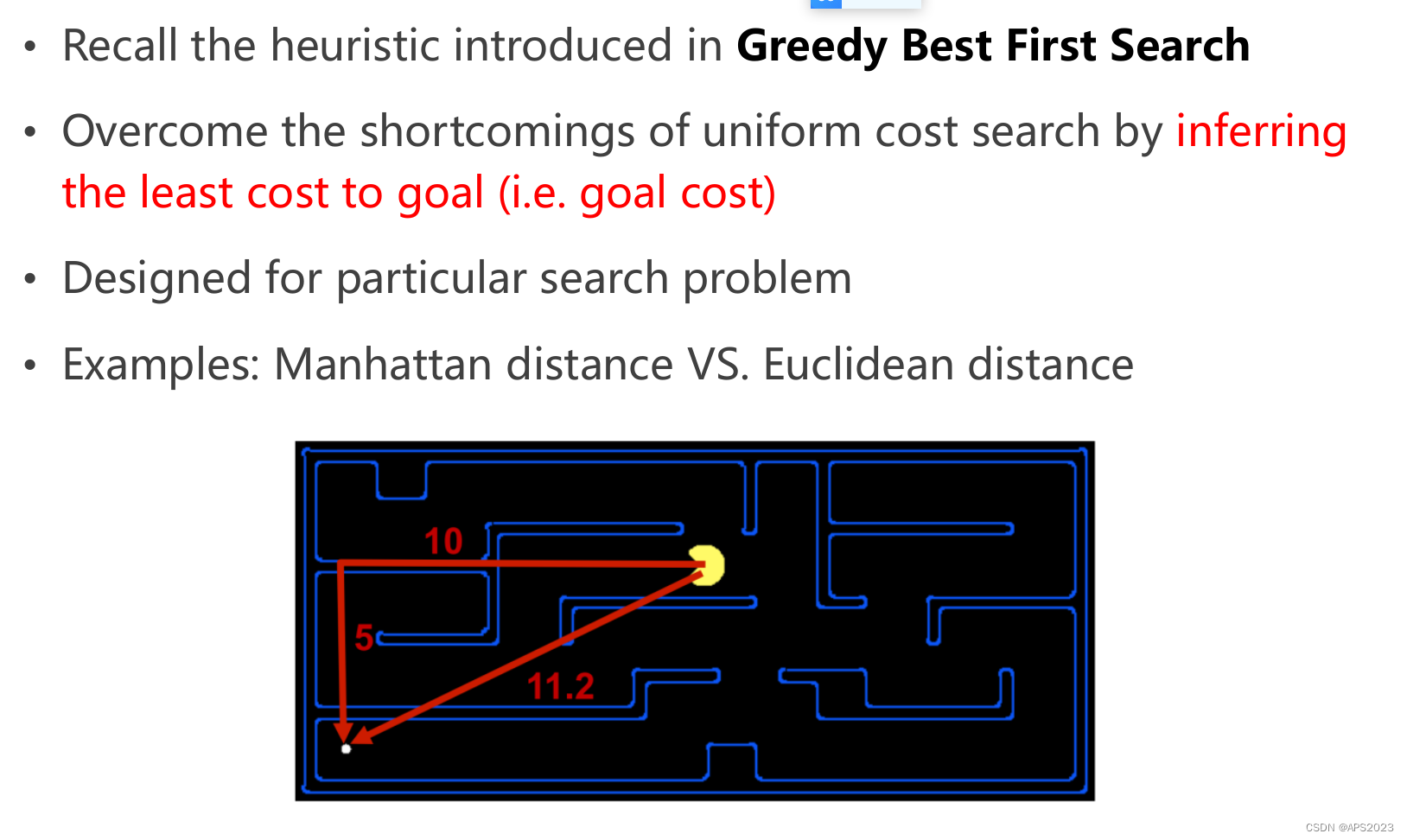
• **克服均匀成本搜索的缺点**:均匀成本搜索只考虑到目前为止的累积成本,没有关于目标位置的信息。为了弥补这个缺陷,启发式搜索会推断出到目标的最小成本(即目标成本),这样就能更有效地引导搜索朝着目标位置前进。
• **为特定搜索问题设计**:启发式搜索方法通常是为了解决特定问题而设计的。例如,对于不同的问题,可能会选择不同的启发式函数来更好地估计到目标的距离。
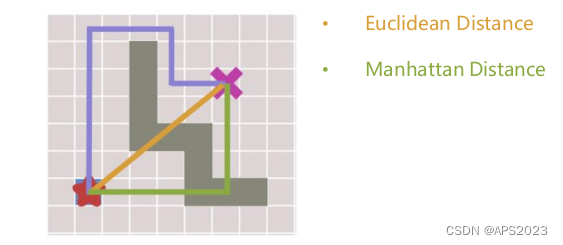
• **举例:曼哈顿距离与欧几里得距离**:这两种距离是在启发式搜索中常用的启发式函数。曼哈顿距离用于网格型问题,它是节点在水平和垂直方向上的距离总和。而欧几里得距离则用于连续空间中的问题,它是节点之间的直线距离。选择合适的启发式函数可以帮助算法更好地估计节点到目标的距离,从而更有效地指导搜索方向。
下面我们介绍A*算法


2.2 A*&&Weighted A*算法
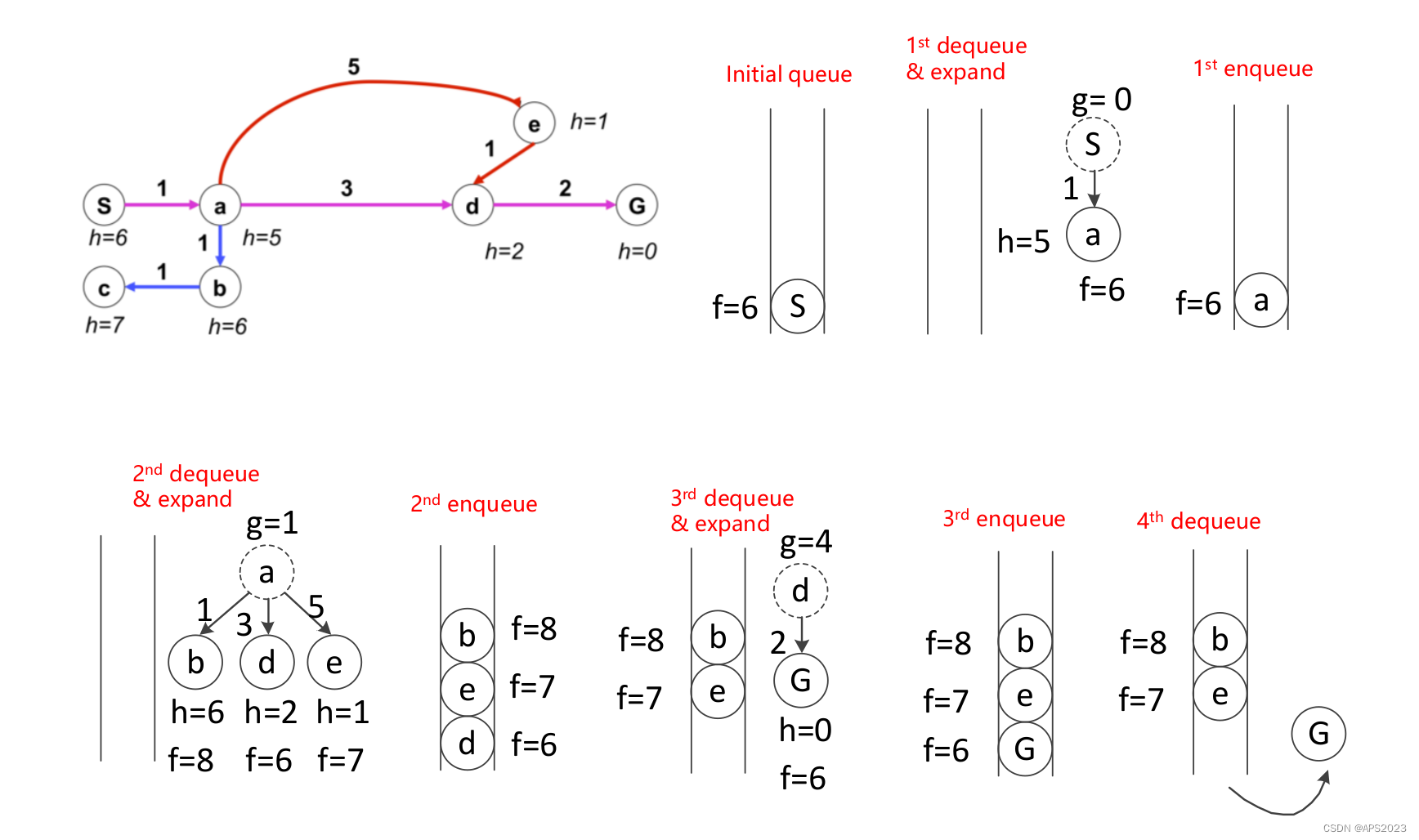
A*算法的关键如下:
• **累积成本 (g(n))**:这是从起始状态到达节点“n”所需的当前最佳估计成本。它代表了到达该节点的路径所累积的实际代价。
• **启发式 (h(n))**:这是从节点“n”到目标状态的估计最小成本。它是根据某些信息或规则得出的,帮助指导搜索朝着目标的最优方向。
• **f(n) = g(n) + h(n)**:这表示通过节点“n”到达目标状态的最小估计成本。在启发式搜索中,这个值是一个关键的指标,用来评估下一个扩展节点的优先级。
• **策略**:选择具有最小 f(n) = g(n) + h(n) 的节点来扩展。这个策略能够在搜索过程中朝着总体最小成本的路径前进。
• **更新累积成本 g(m)**:对于节点“n”的所有未被扩展的邻居“m”,需要更新其累积成本 g(m)。这样做能够确保获得更准确的路径成本估计。
• **已扩展节点的保证**:任何一个被扩展的节点都保证具有从起始状态到达的最小成本。这是因为启发式搜索通过每次选择最小 f(n) 的节点来确保路径的最小成本。
看一下A*的伪代码,和Dijkstra其实就加了一个启发函数:
举个例子:
那么A*的结果是最优的吗?我们来看这个例子:
可能不是最优!!启发式函数的估计如果不合理的话会影响我们最终的结果。
那么如何设计启发式函数呢?
当谈到启发式时,有几个关键概念:
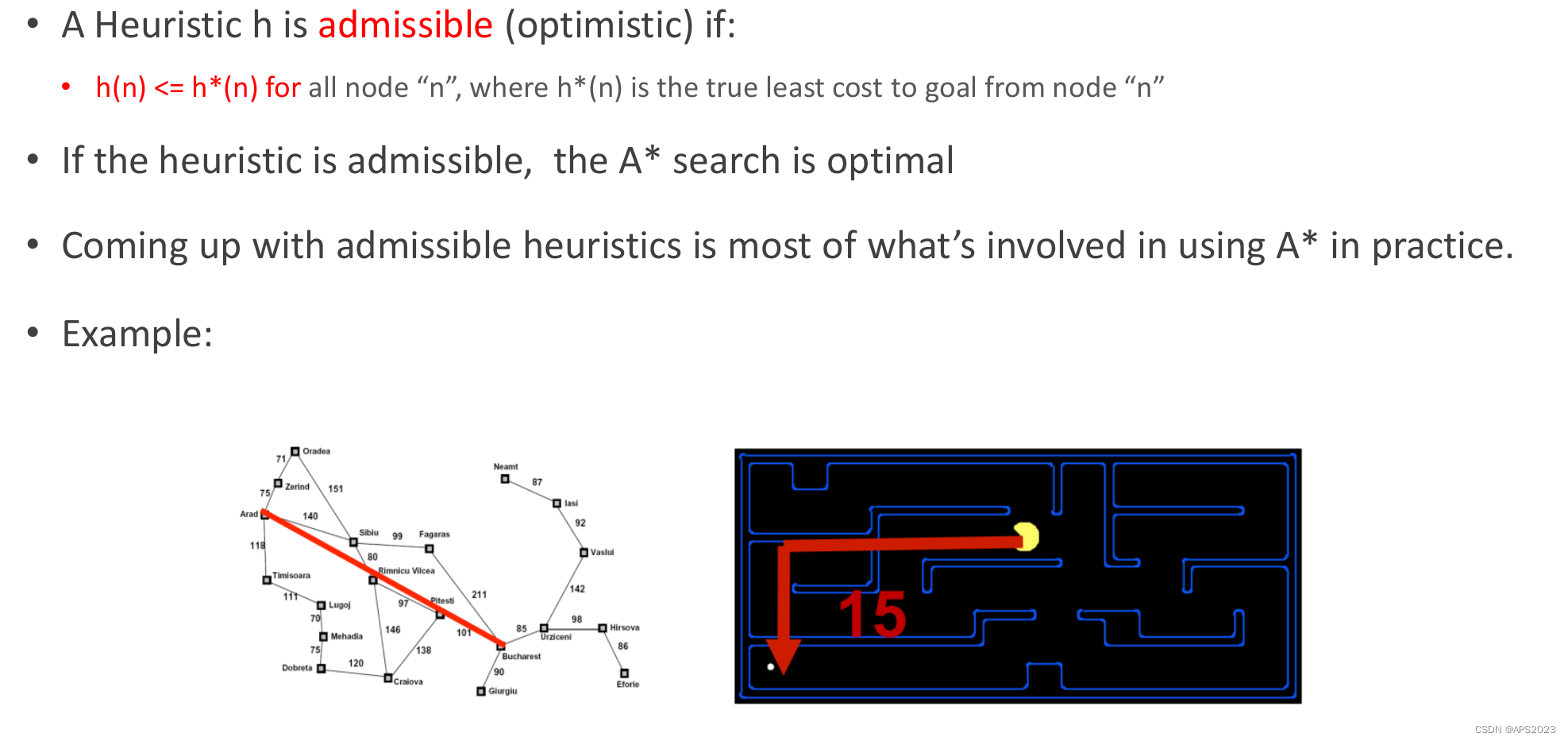
• 可接受的启发式(乐观估计):如果对于所有节点“n”,启发式 h(n) 都满足 h(n) <= h*(n),其中 h*(n) 是从节点“n”到目标的实际最小成本,那么这个启发式就是可接受的。它是一种乐观的估计,不会高估到目标的距离或成本。
• A 搜索的最优性*:如果启发式是可接受的,那么 A* 搜索算法就是最优的。这意味着它能够以最优的方式找到起始状态到目标状态的最小成本路径。
• 确定可接受启发式:在实际应用中,大部分工作涉及到找到可接受的启发式。这种启发式对于 A* 算法至关重要,因为它直接影响着搜索的效率和最终的最优路径。
在 A* 搜索中,一个关键目标就是找到一个既能够引导搜索,又不会高估成本的启发式。这样的启发式可以帮助 A* 算法更快地找到最优解,同时确保找到的解是最优的。
我们可以用以下的启发式函数:
当谈到启发式函数时,有几个关键点需要注意:
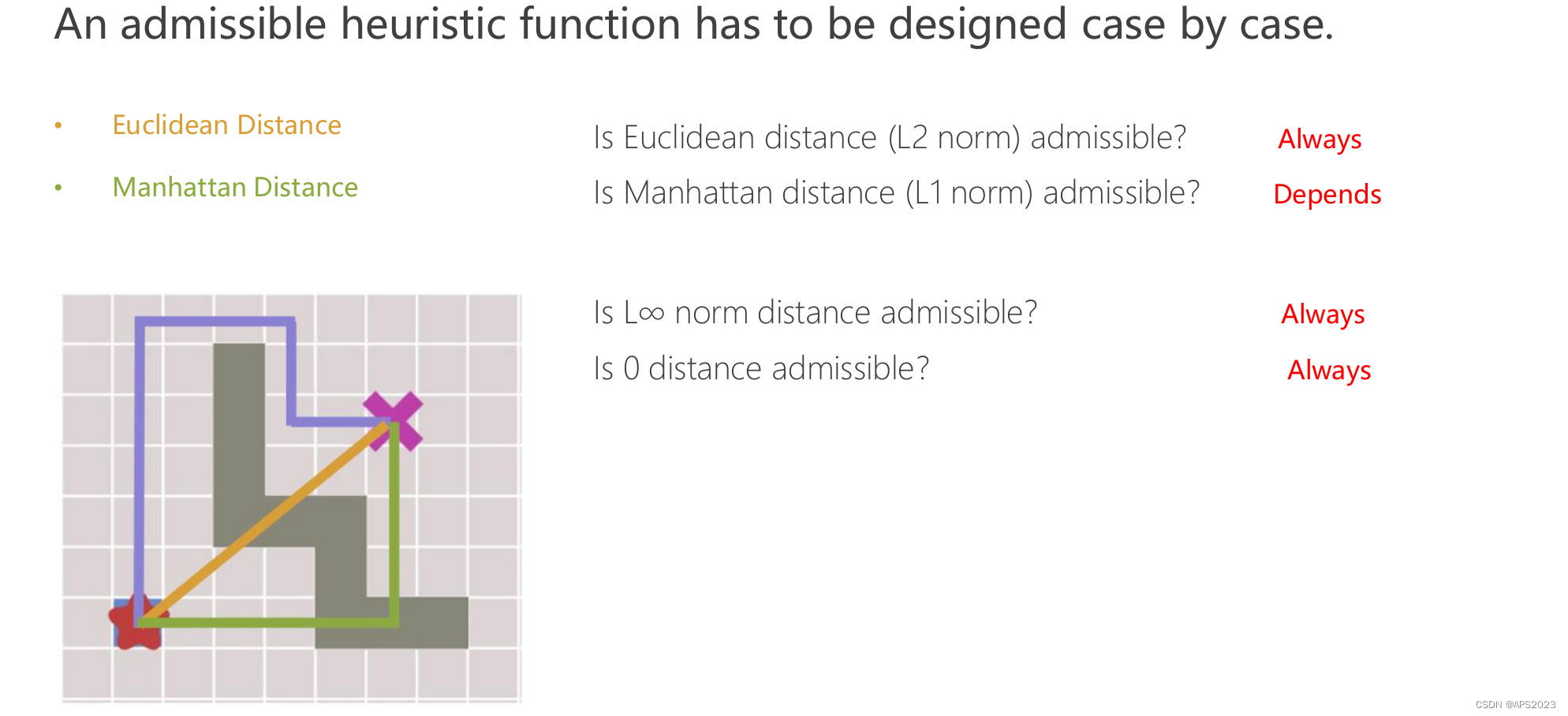
• **可接受启发式函数需因情况而定**:设计可接受的启发式函数需要根据具体情况。这意味着针对不同的问题,可能需要不同的启发式函数。
• **欧几里得距离**:欧几里得距离(L2范数)总是可接受的。这意味着欧几里得距离是一种保守估计,不会高估到达目标的成本。
• **曼哈顿距离**:曼哈顿距离(L1范数)是否可接受则取决于具体情况。在某些问题中,曼哈顿距离可能是保守估计,但在其他情况下可能会高估到达目标的成本。
• **L∞范数距离**:L∞范数距离总是可接受的。这种距离是一种非常保守的估计,因为它考虑了所有维度中的最大差异。
• **零距离**:零距离总是可接受的。这意味着如果启发式函数始终返回零作为估计值,它仍然是可接受的,尽管这种情况下效率不高,但是搜索会保证找到最短路径。
总的来说,一些距离函数如欧几里得距离和L∞范数距离总是可接受的,而曼哈顿距离取决于具体情况。零距离虽然总是可接受,但在实践中效率可能不高。选择合适的启发式函数取决于问题的特性和需要平衡的搜索效率。
我们看下曼哈顿距离:如果我们机器人允许对角线运动,曼哈顿距离为h=右走上走为2,但是机器人实际运动距离为h*=根号2,h*<h,不满足。
我们对比下Dijkstra算法和A*算法:
Dijkstra算法会从起始节点开始,逐步探索图中的所有方向或路径,以达到每个可达节点。它不考虑特定的方向性或目标节点;相反,它根据从起始节点到当前节点的累积成本,系统地检查每个节点。
这个算法的工作原理是从初始节点开始,在每一步中选择未访问节点中具有最低当前成本的节点。然后从该节点扩展到其相邻节点,并更新到达这些邻居节点的累积成本。这个过程一直持续到它访问了从起始节点可达的每个节点,或者直到达到目标节点(如果指定了目标节点)为止。
不同于一些其他算法可能会优先考虑特定的目标或方向,Dijkstra算法专注于找到从起始节点到所有其他可达节点的最短路径。
A*算法主要朝着目标方向扩展搜索,但并不是以确保最优性为目标进行搜索的算法。
A*算法我们可以让其搜索更快,但是不是一个最优解!!工程上就是这样:这个算法称为Weighted A*,我们乘以一个
值让其更快的收敛:
它是用最优性换取了速度!付出的代价就是找出的结果是此优的,cost(solution) <= εcost (optimal solution)。
我们看下具体的路径。






2.3 A* 算法的工程实践中的应用
如何把栅格地图转化为图?
需要定义节点连接方法。
在工程中我们经常建立稠密的栅格地图:
如何在A*搜索中使用最好的启发式函数?
那要如何解决呢?
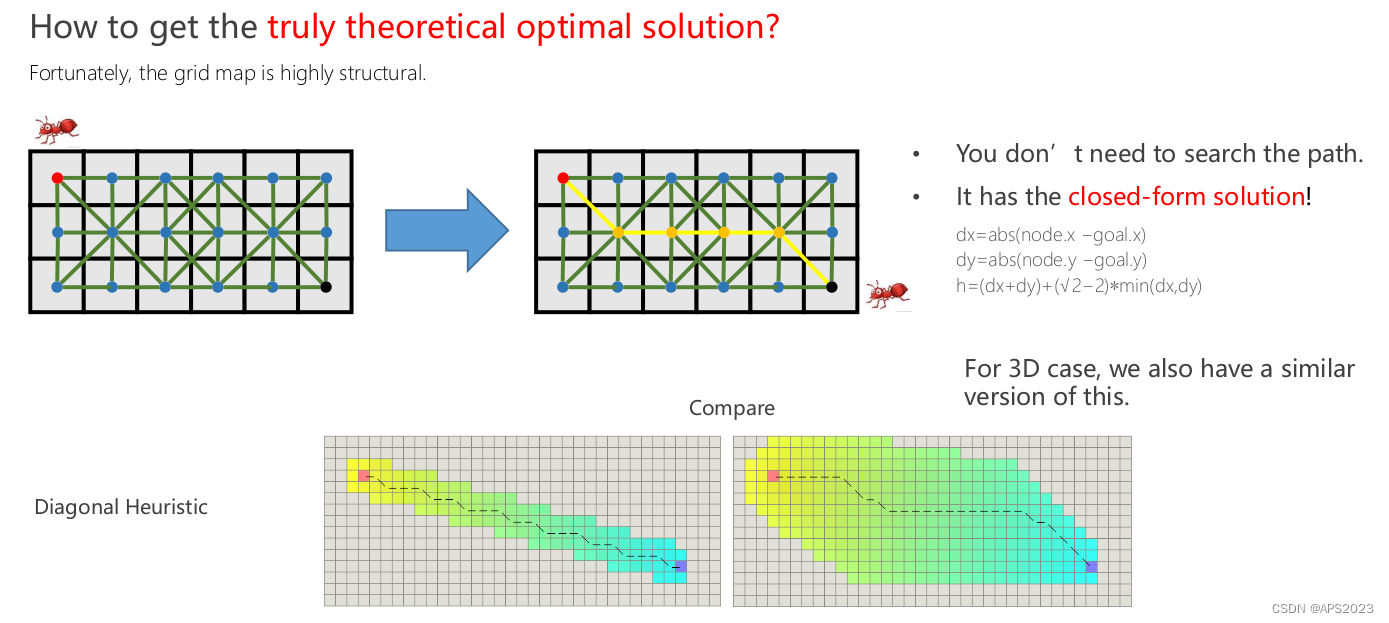
栅格地图具有高度的结构性。你不需要搜索路径。!它有闭式解!我们可以求出一个h*=h的路径。基于此我们可以设计算法。
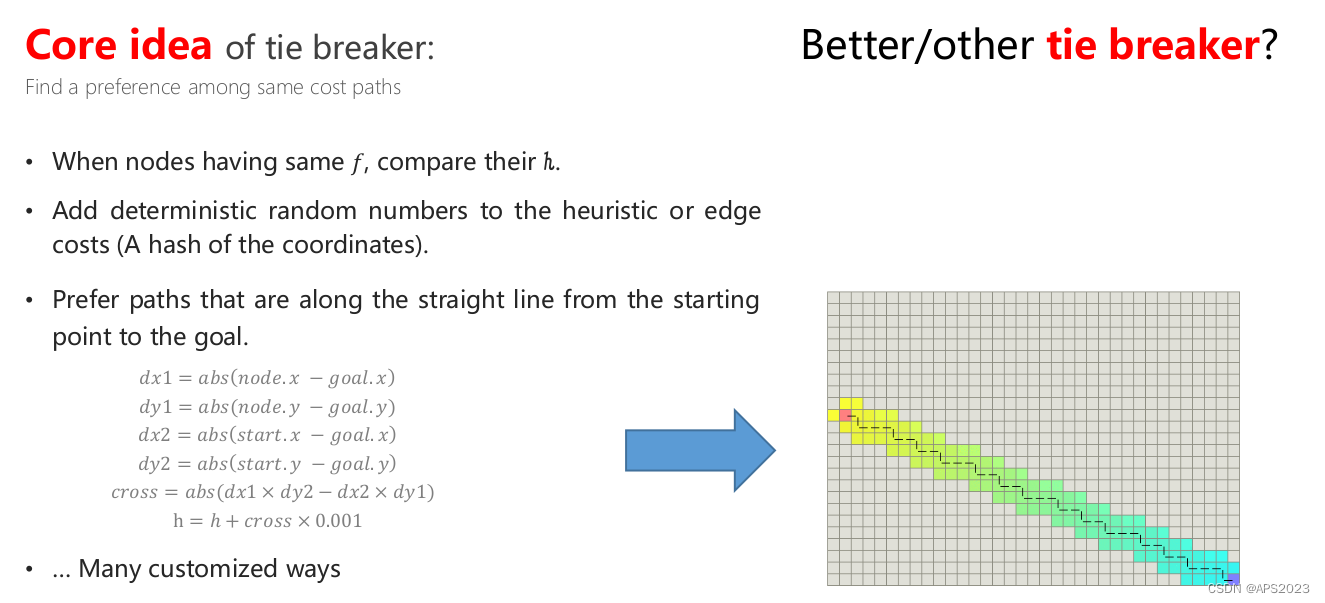
打破对称性!
1.在A*中,加入的节点有很多cost值是相等的。我们可以修改启发式函数,如果对于相邻的两个节点有相同的f,将某一个节点的h作为一个简单的修改(非常小的方法)。
2.如果f相同,谁的h小放在前面或者直接丢弃h大的!!或者加上一个倾向性!
当然,我们采取这种方法找到的Path也会趋向于一条直线,如下图:



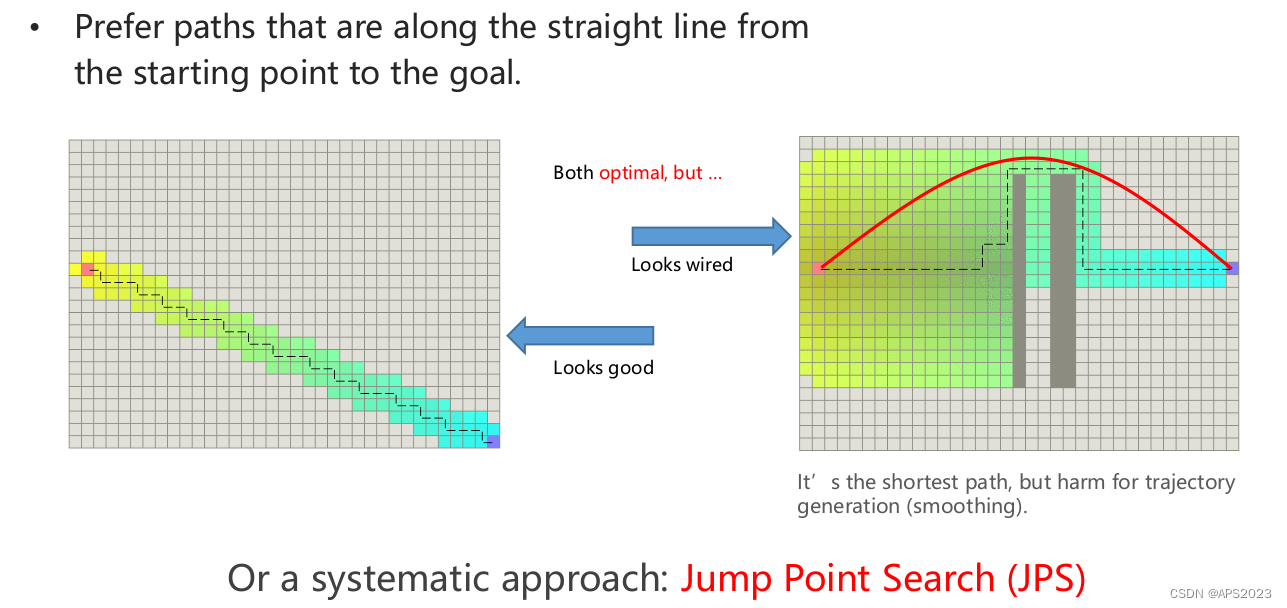
3 JPS
可以彻底性消灭tie breaker的方法!
JPS算法的核心就是找到搜索图的对称性并打破它!
JPS是怎么工作的呢?
1.Look Ahead Rule
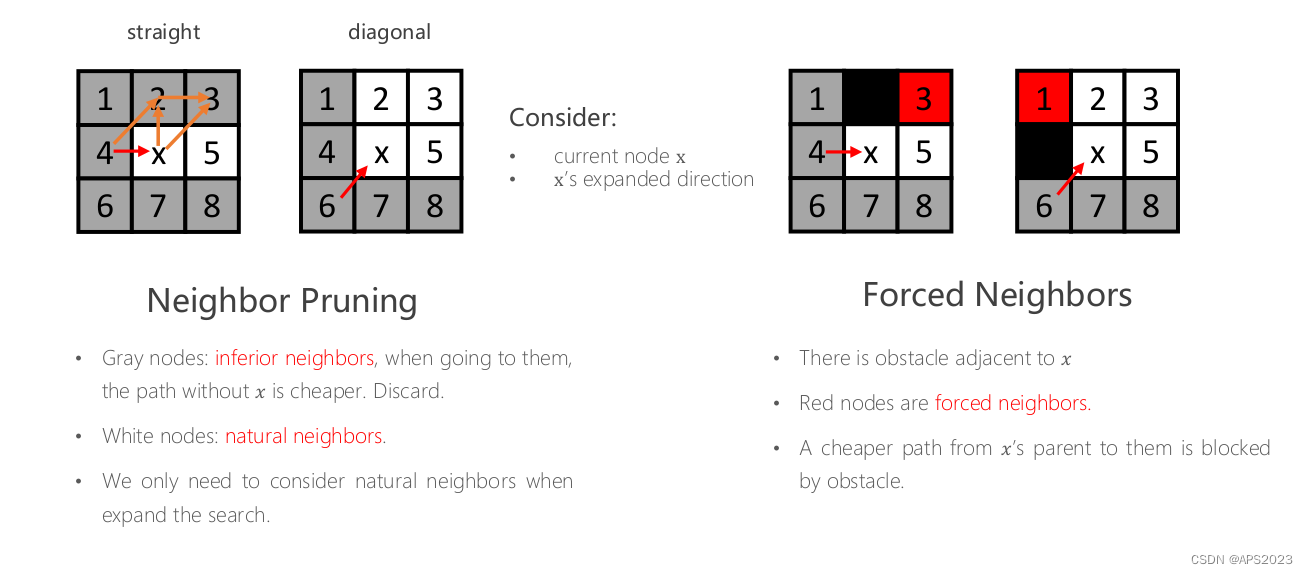
它扩展每一步的时候可以根据当前节点的父亲拓展过来的方向以及周围是否有障碍物以及障碍物在哪个位置的信息来智能的选择哪些节点是需要扩展的哪些节点是不需要扩展的。
准则1就是如果其他节点可以经过x的父亲直接到达并获得路径的path小于等于经过x再过去,那么这个节点没有必要从x到达。
比如说1号节点:4->1代价为1,4->x->1代价为根号2+1,没必要。2号也是 1?根号2。3号 423 根号2+1 4x3 根号2+1没必要。
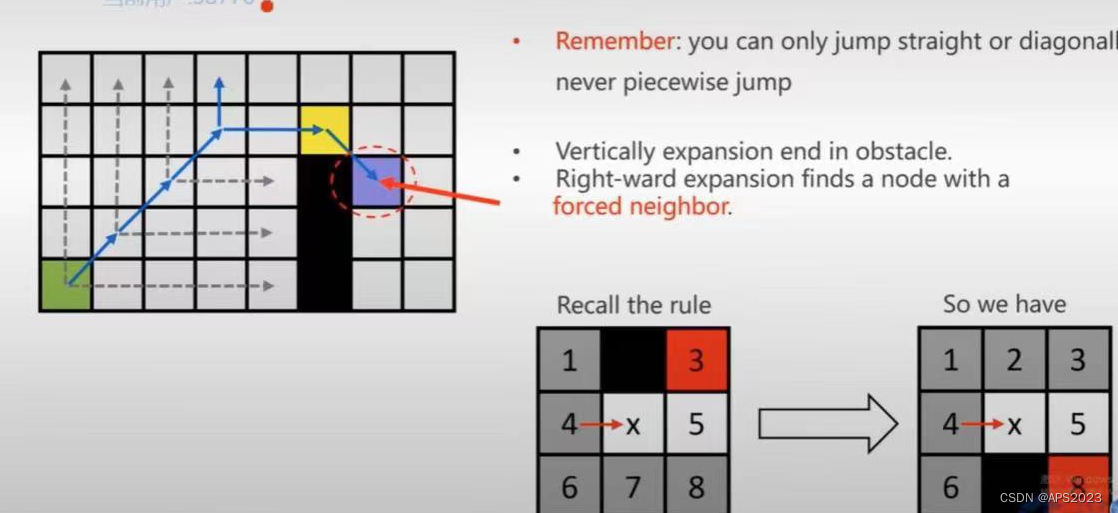
如果x旁边有障碍物呢?右图,红色的是需要考虑的。
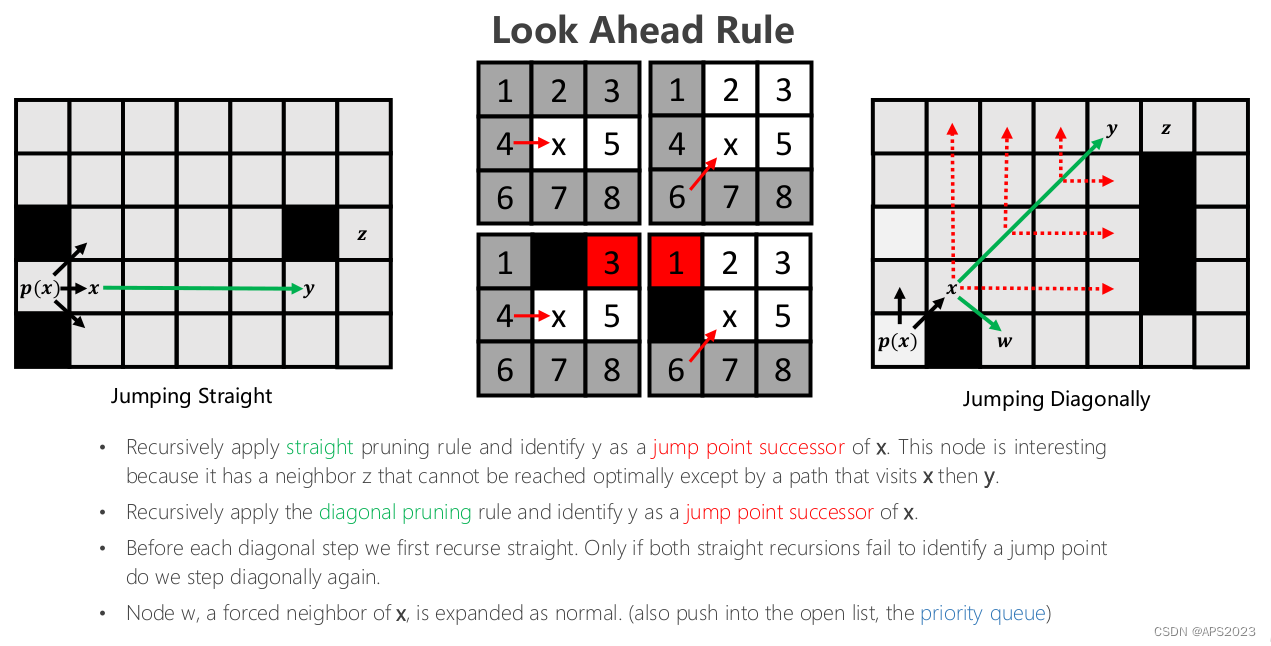
2.Jumping Rules
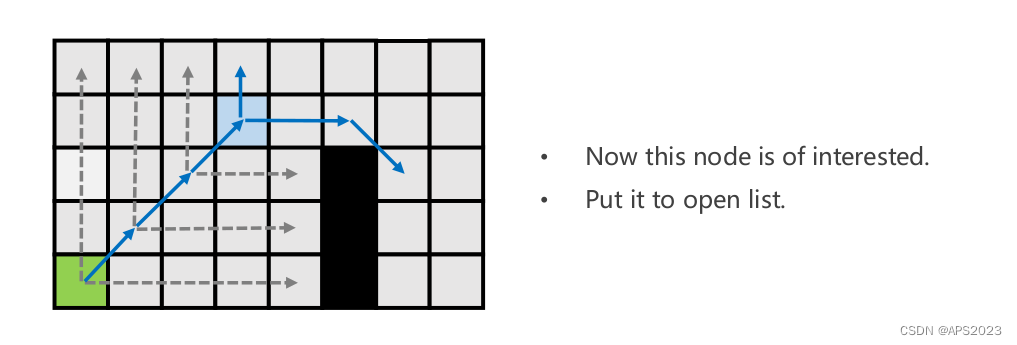
以左图为例子,不断迭代执行直线的(往前推进一格子Look Ahead Rule),如左一图,执行到y的时候z节点是它的first neigbor(我们称y节点为关键节点因为它有一个first neigbor)。这是直线跳跃的规则。对角线跳跃的规则就是图3。我们先考虑直线跳跃红虚线撞到障碍物表示失败了整条路线上就没有我们关心的节点了。y节点水平跳跃发现有first neighbor,返回到发现它的y节点,把y加入优先队列openlist中。w也是first neibor。这样x的扩展结束。
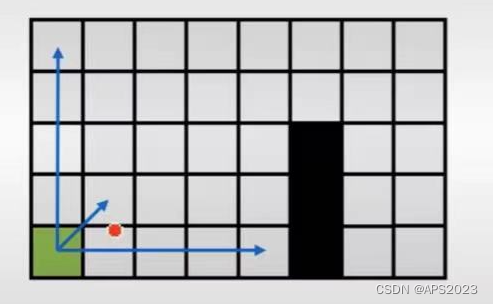
我们看一个例子:
先水平方向扩展(失败)对角线移动一步。
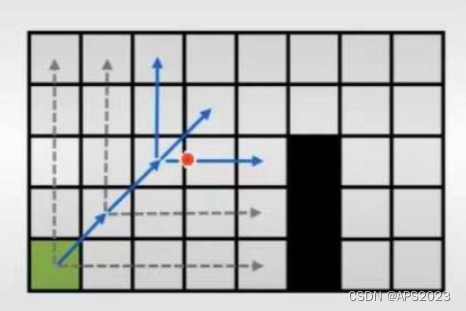
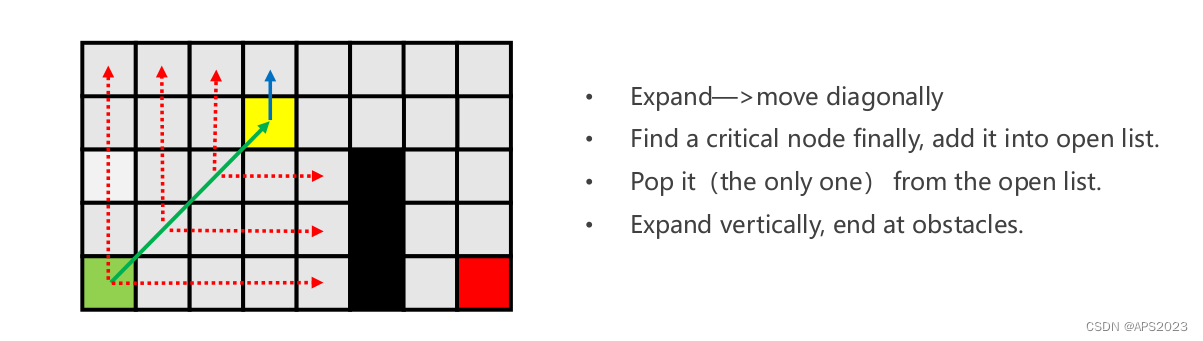
水平失败 再移动一步
水平失败 再移动一步
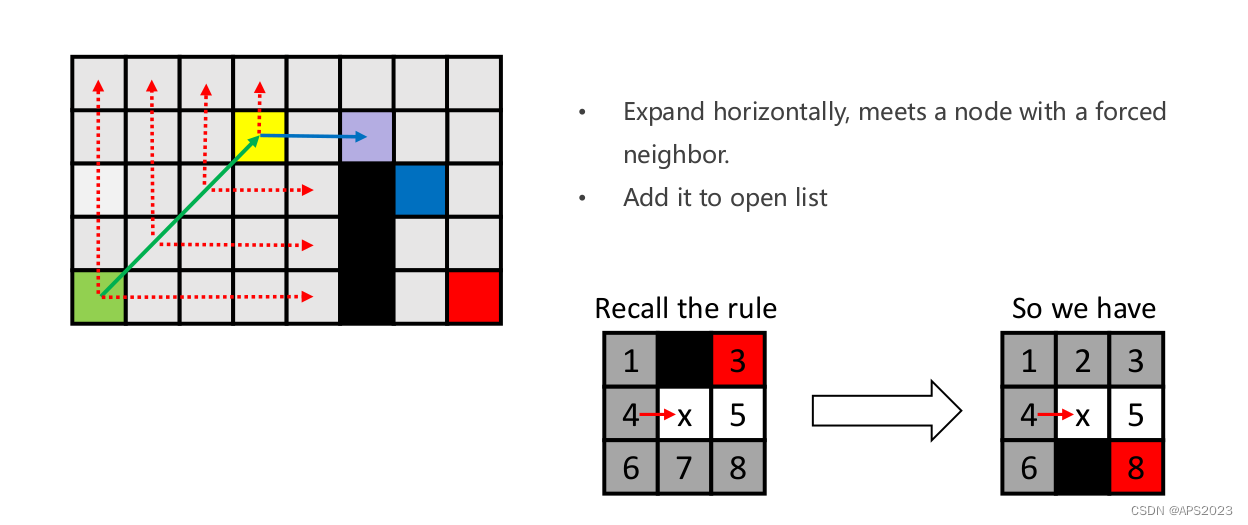
水平移动,发现有first neigbor。因此找到了黄色的关键点,跳跃到黄色点。把黄色节点加入openlist,退出历史舞台。
看一下算法流程图:
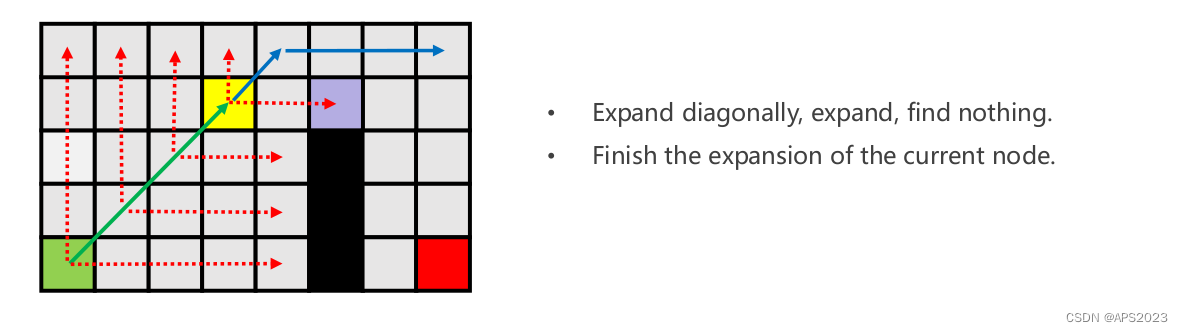
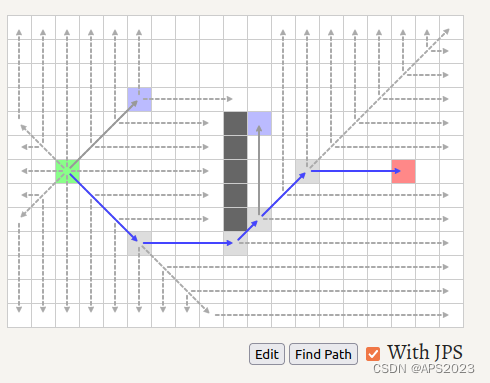
再来看一个例子巩固一下吧:
从起点横向纵向跳跃,撞墙...斜着走:
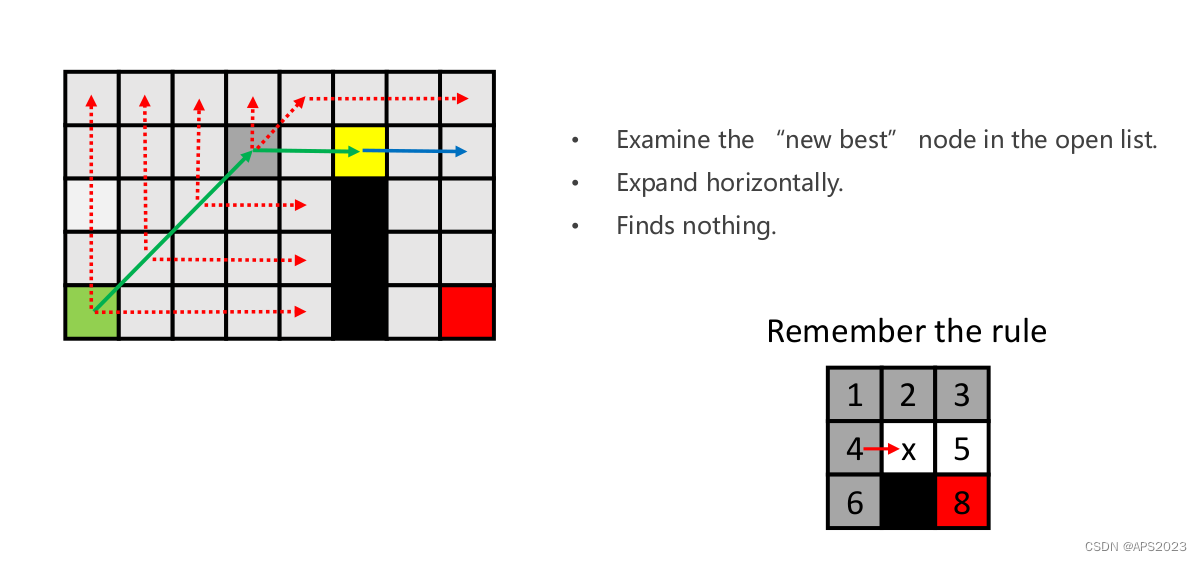
黄色点向右的话会找到first neighbor。因此加入openlist。绿色节点从openlist弹出,现在openlist只有黄色点。
纵向不行,横向发现了刚才的点(紫色点),加入openlist
,但是黄色节点的扩展还没有结束,考察对角线方向,没有路径:
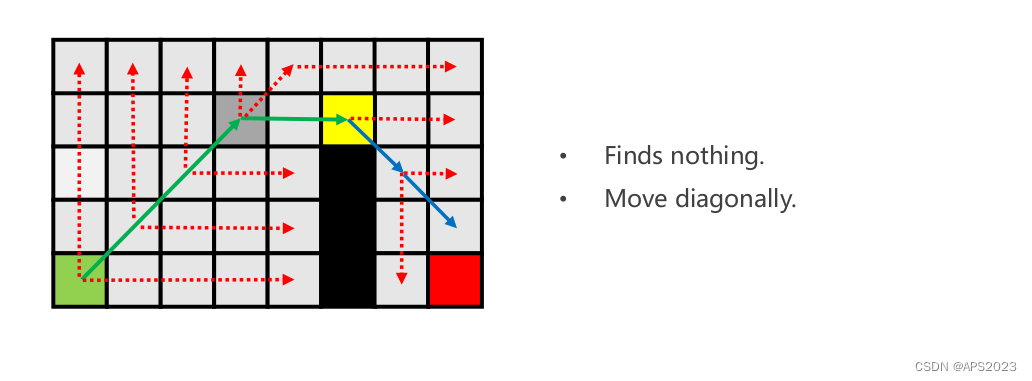
因此,黄色节点完全扩展完毕,加入close list,openlist节点只剩下紫色节点。
水平扩展无,对角线节点存在,加入openlist。
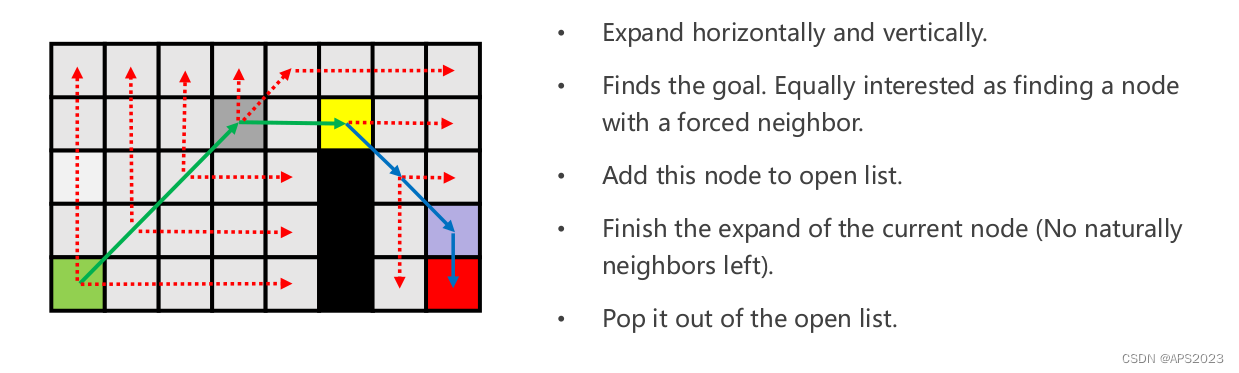
水平垂直没有任何,考虑对角线方向。
特殊规则出现,探索方向出现终点。break。回溯路径。
因此,它是若干关键节点组成的。
如果加入启发式函数,随着终点位置不同,路径的偏移不同。
demo
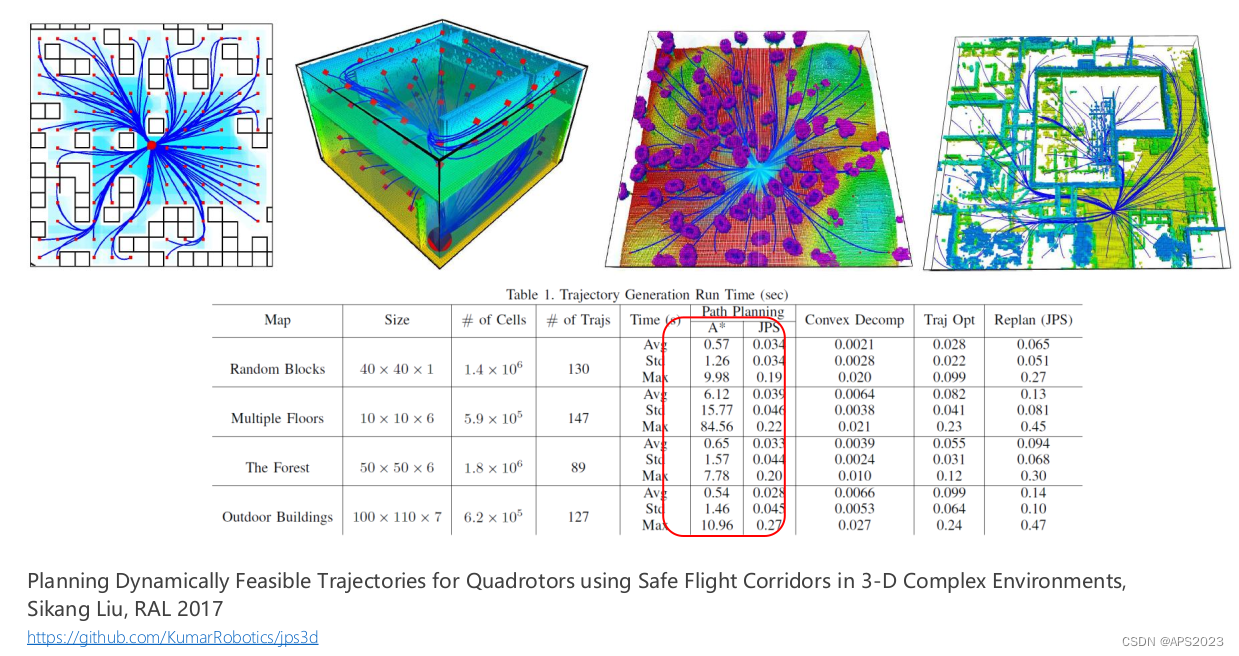
https://zerowidth.com/2013/a-visual-explanation-of-jump-point-search.html 在三维中,也适用于3D。
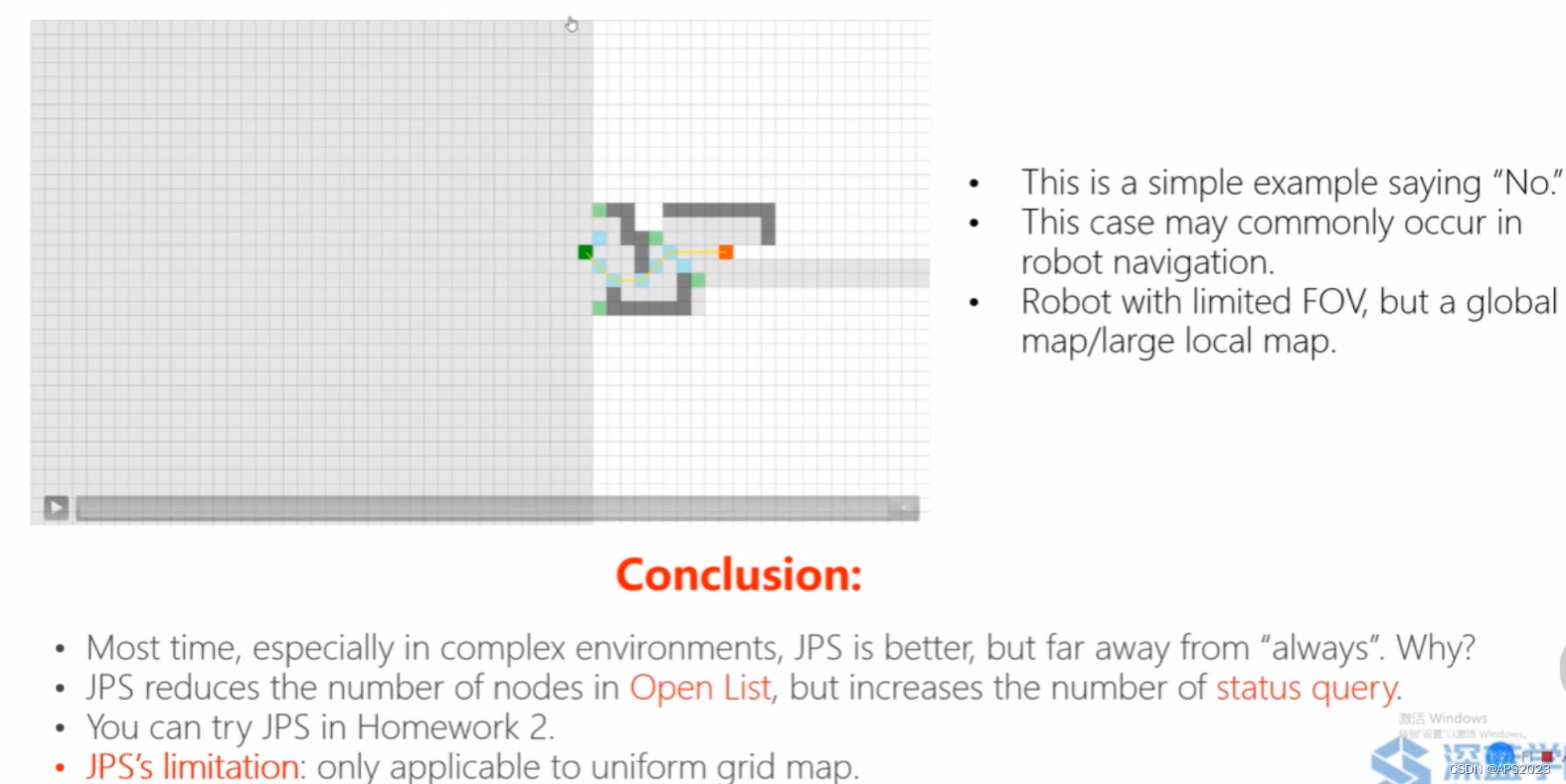
JPS永远比A*好吗?不一定?
机器人视野有限的。
通常情况下,特别是在复杂环境中,JPS算法表现更好,因为它能够减少在搜索过程中处理的节点数量,从而提高搜索效率。但并非在所有情况下都表现得很好,因为它也有一些局限性。
JPS算法通过跳跃式搜索路径,从而减少了在搜索过程中开放列表中节点的数量。这样做可以降低计算开销,但却增加了需要进行状态查询的次数。在某些情况下,这种增加的查询次数可能会导致算法效率降低,特别是在特定类型的地图或路径情况下。
最后,指出了JPS算法的一个重要限制:它仅适用于均匀网格地图。这意味着对于非均匀的或者特殊类型的地图结构,JPS算法可能不适用,需要考虑其他的路径规划方法。