
浙大和微软亚洲研究院开源的HuggingGPT,又名JARVIS,它可以根据用户的自然语言描述的需求就可以自动分析需要哪些AI模型,然后去Huggingface上直接调用对应的模型,最终给出用户的解决方案。
一、HuggingGPT的工作流程
它的工作流程包括四个阶段:
-
任务规划:ChatGPT将用户的需求解析为任务列表,并确定任务之间的执行顺序和资源依赖关系;
-
模型选择:ChatGPT根据HuggingFace上托管的各专家模型的描述,为任务分配合适的模型;
-
任务执行:混合端点(包括本地推理和HuggingFace推理)上被选定的专家模型根据任务顺序和依赖关系执行分配的任务,并将执行信息和结果给到ChatGPT;
-
响应生成:最后,由ChatGPT总结各模型的执行过程日志和推理结果,给出最终的输出。

下表展示了HuggingGPT的具体细节:

不同任务的任务规划评估,如下表所示:

任务规划的格式是: [{"task": task, "id", task_id, "dep": dependency_task_ids, "args": {"text": text, "image": URL, "audio": URL, "video": URL}}],参数的详细解释,如下表所示:

二、HuggingGPT的示例
假设我们有如下请求,来看一下HuggingGPT的完整流程:
请求:请生成一个女孩正在看书的图片,她的姿势与example.jpg中的男孩相同。然后请用你的声音描述新图片。

可以看到HuggingGPT是如何将它拆解为6个子任务,并分别选定模型执行得到最终结果的。
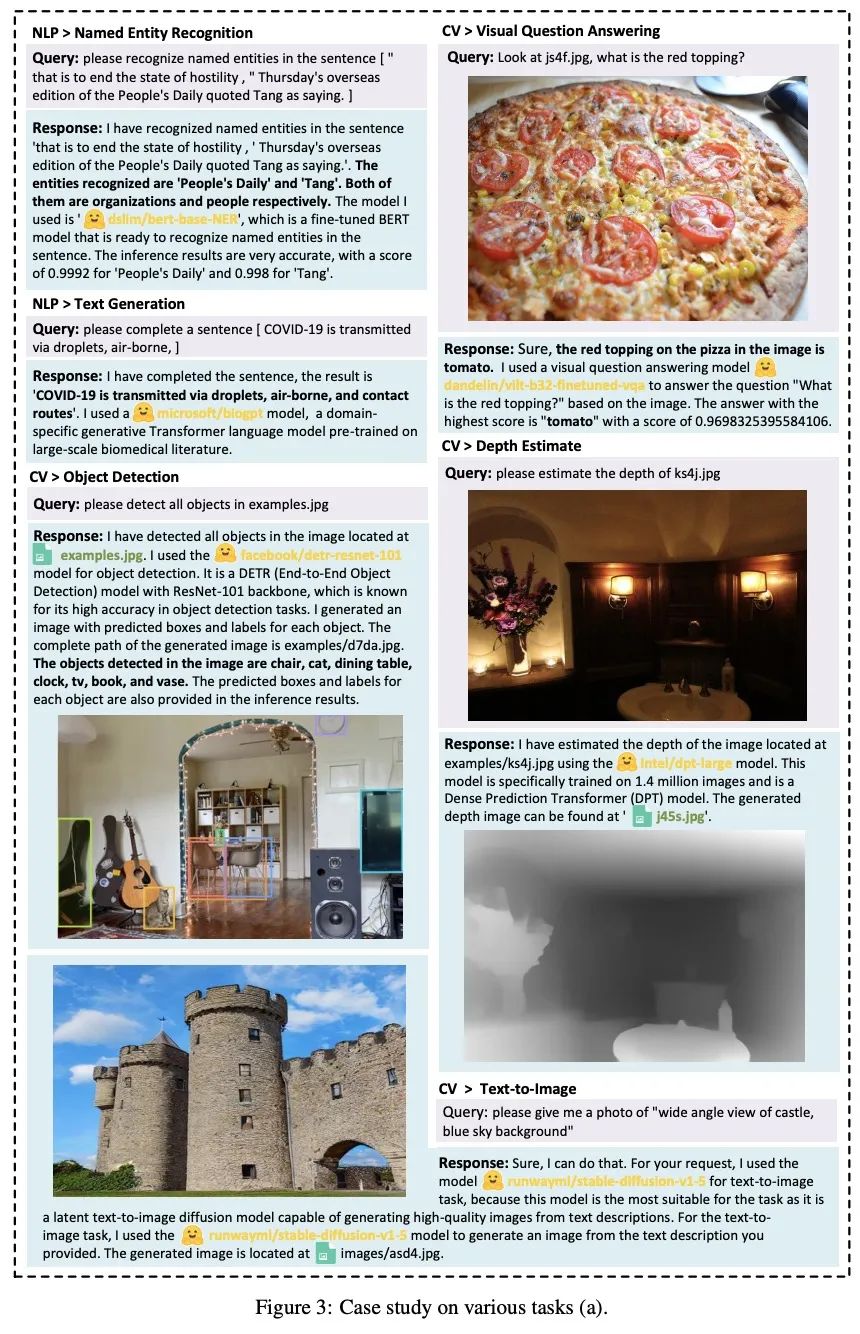
三、HuggingGPT不同任务的实验效果







参考文献:
[1] https://github.com/microsoft/JARVIS
[2] https://huggingface.co/spaces/microsoft/HuggingGPT
[3] https://arxiv.org/abs/2303.17580
[4] https://twitter.com/DrJimFan/status/1642563455298473986