一、Scrapy框架使用
1. 创建scrapy项目(不能有汉字,不能数字开头)
scrapy startproject Baidu
2. 创建爬虫文件
1. cd Baidu
2. scrapy genspider wenda www.baidu.com

注意: parse()是执行了start_url之后要执行的方法,方法中的response就是返回的对象。相当于response = requests.get或requests.post
3. 运行爬虫代码
scrapy crawl wenda
在parse()函数打印一句话,运行后发现没有打印结果,原因是被一个叫robots.txt的文件给阻止了。

解决:大平台的君子协议,只需在settings里将ROBOTSTXT_OBEY = True注释掉即可。

再次运行
 4. scrapy文档
4. scrapy文档
scrapy官网:https://scrapy.org/ scrapy文档:https://doc.scrapy.org/en/latest/intro/tutorial.html scrapy日志:https://docs.scrapy.org/en/latest/news.html
二、scrapy项目的结构

四、response的属性和方法
- response.text 获取响应的字符串(源码)
- response.body 获取响应的二进制数据(二进制源码)
- response.xpath 直接通过xpath解析response中的内容
- response.extract() 提取selector对象的data所有属性值
- response.extract_first() 提取selector列表的第一个数据
- response.get() : 得到第一条数据
- response.getall() :取出所有的数据,以列表的方式呈现
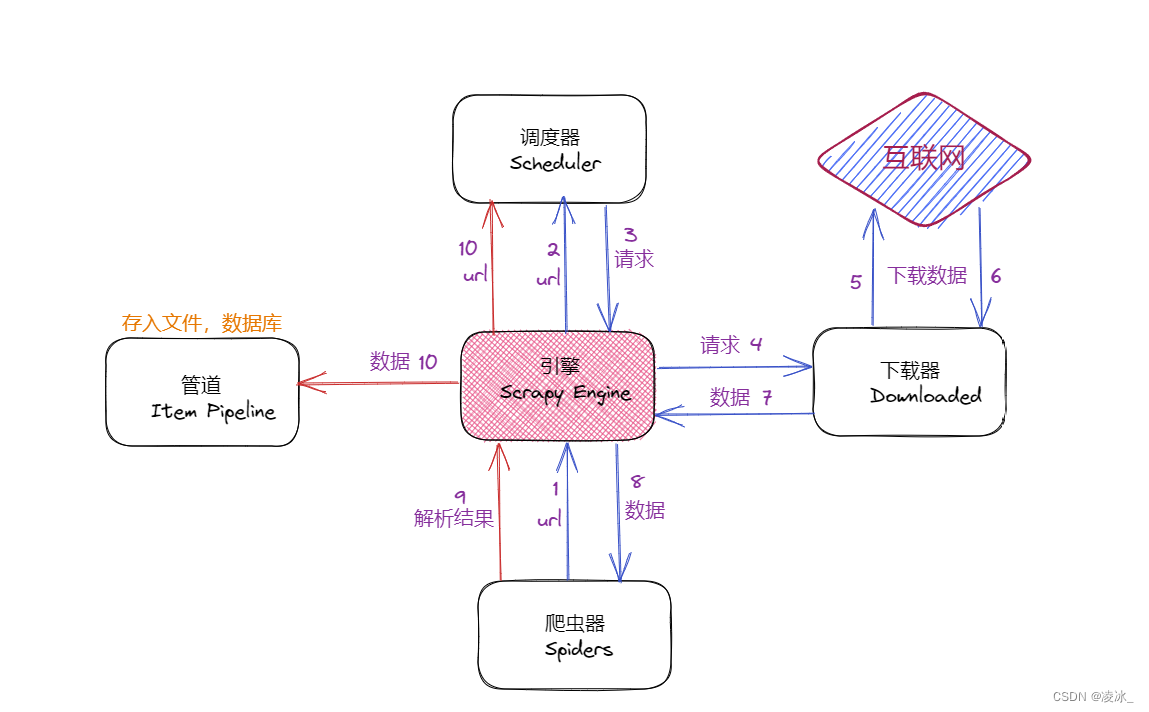
五、scrapy工作原理
- 引擎向spiders要url
- 引擎将要爬取的url给调度器
- 调度器会将url生成请求对象放入到指定的队列中
- 从队列中出队一个请求
- 引擎将请求交给下载器处理
- 下载器发送请求获取互联网数据
- 下载器将数据返回给引擎
- 引擎将数据再次给spiders
- spiders通过xpath解析该数据,得到数据或url
- spiders将数据或url给到引擎
- 引擎判断是数据还是url,若是数据,交给管道处理;若是url,交给调度器处理