GET请求
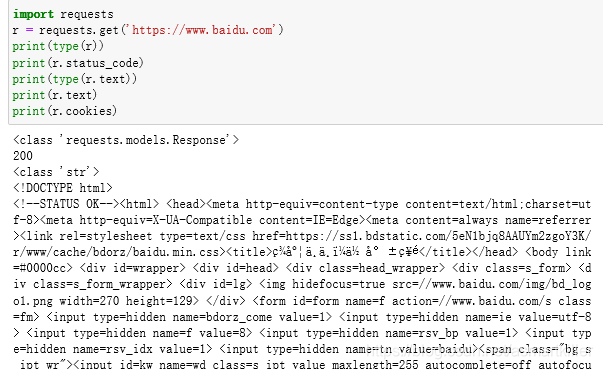
使用get方法成功实现一个GET请求,返回类型是requests .models.Response ,响应体的类型是字符串str,Cookies的类型是RequestsCookieJar 。
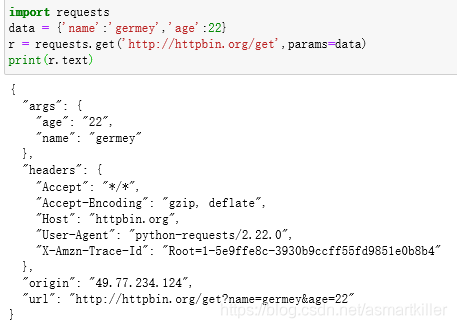
给GET请求添加参数

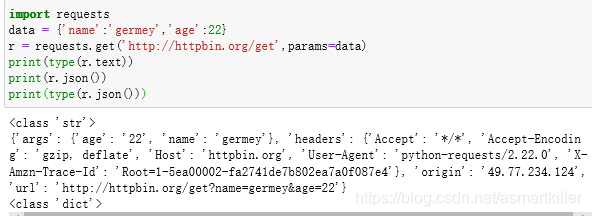
网页的返回类型实际上是str类型,但是它很特殊,是JSON格式的。所以,如果想直接解析返回结果,得到一个字典格式的话,可以直接调用json方法,返回结果是JSON 格式的字符串转化为字典。
抓取网页 上面的请求链接返回的是JSON形式的字符串, 那么如果请求普通的网页,则肯定能获得相应的内容了。
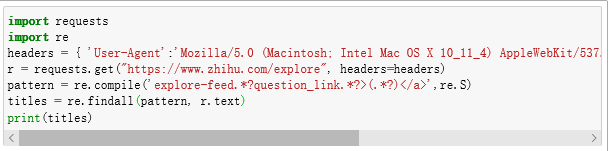
抓取二进制数据 图片、音频、视频这些文件本质上都是由二进制码组成的,由于有特定的保存格式和对应的解析方式, 我们才可以看到这些形形色色的多媒体。所以,想要抓取它们,就要拿到它们的二进制码。
添加headers
POST请求
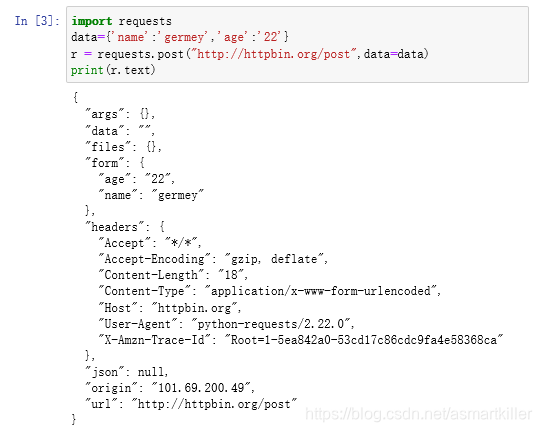
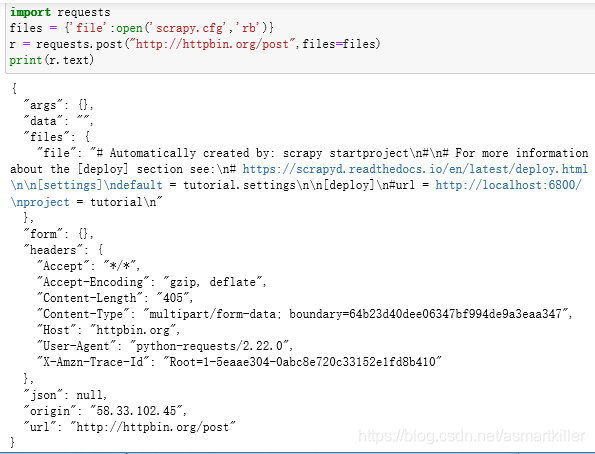
其中form部分就是提交的数据,这就证明POST 请求成功发送了
响应
使用text 和content 获取了响应的内容。此外,还有很多属性和方法可以用来获取其他信息,比如状态码、响应头、Cookies 等。
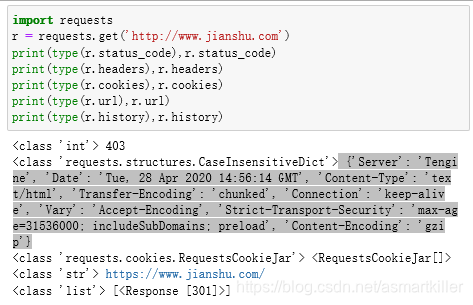
状态码常用来判断请求是否成功,而requests还提供了一个内置的状态码查询对象requests.codes

如果想判断结果是不是404 状态,可以用requests.codes . not_found 来比对



文件上传
requests 可以模拟提交一些数据

Cookies
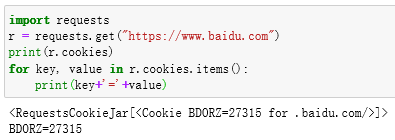
首先调用cookies属性即可成功得到Cookies , 可以发现它是RequestCookieJar类型。然后用items方法将其转化为元组组成的列表, 遍历输出每一个Cookie 的名称和值, 实现Cookie的遍历解析。
可以直接用Cookie来维持登录状态, 下面以知乎为例来说明。首先登录知乎,将Headers 中的Cookie内容复制下来,
可以替换成你自己的Cookie , 将其设置到Headers里面,然后发送请求
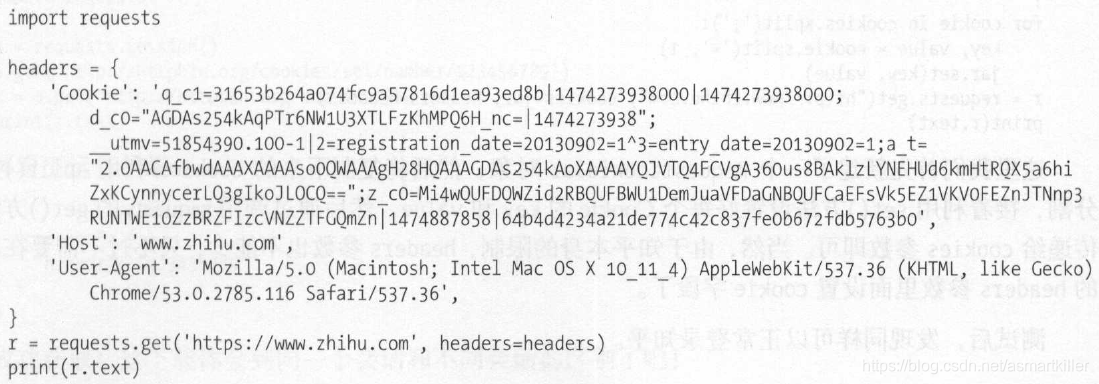
你也可以通过cookies 参数来设置,不过这样就需要构造RequestsCookieJar 对象,而且需要分割一下cookies。

首先新建了一个RequestCookieJar对象,然后将复制下来的cookies 利用split方法分割,接着利用set方法设置好每个Cookie 的key 和value ,然后通过调用requests 的get方法并传递给cookies 参数即可。当然,由于知乎本身的限制, headers参数也不能少,只不过不需要在原来的headers 参数里面设置cookie字段了。
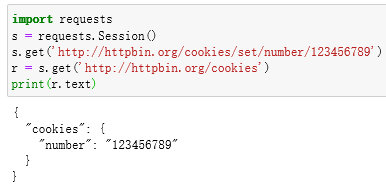
会话维持
在requests中,如果直接利用get或post等方法的确可以做到模拟网页的请求,但是这实际上是相当于不同的会话,也就是说相当于你用了两个浏览器打开了不同的页面。设想这样一个场景,第一个请求利用post方法登录了某个网站,第二次想获取成功登录后的自己的个人信息,你又用了一次get方法去请求个人信息页面。实际上,这相当于打开了两个浏览器, ·四
是两个完全不相关的会话,能成功获取个人信息吗?那当然不能。有小伙伴可能说了,我在两次请求时设置一样的cookies 不就行了?可以,但这样做起来显得很烦琐, 我们有更简单的解决方法。其实解决这个问题的主要方法就是维持同一个会话, 也就是相当于打开一个新的浏览器选项卡而不是新开一个浏览器。但是我又不想每次设置cook ies ,那该怎么办呢?这时候就有了新的利器一Session 对象。

SSL 证书验证
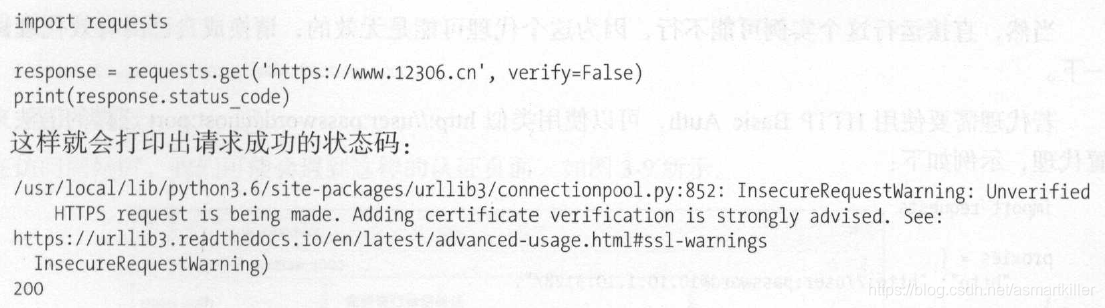
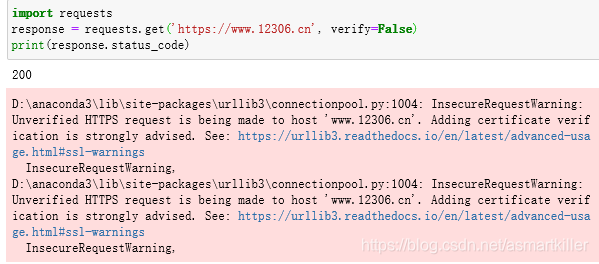
requests还提供了证书验证的功能。当发送HTTP请求的时候,它会检查SSL证书,我们可以使用verify参数控制是否检查此证书。其实如果不加verify 参数的话,默认是True ,会向动验证。
12306 的证书没有被官方CA 机构信任,会出现证书验证错误的结果。

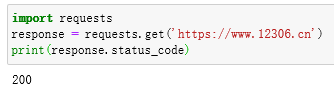
提示一个错误SSL Error ,表示证书验证错误。所以,如果请求一个HTTPS站点,但是证书验证错误的页面时,就会报这样的错误,那么如何避免这个错误呢?很简单,把verify 参数设置为False 即可。
发现报了一个警告它建议我们给它指定证书。我们可以通过设置忽略警告的方式来屏蔽这个警告:

也可以指定一个本地证书用作客户端证书,这可以是单个文件(包含密钥和证书)或一个包含两个文件路径的元组:


代理设置
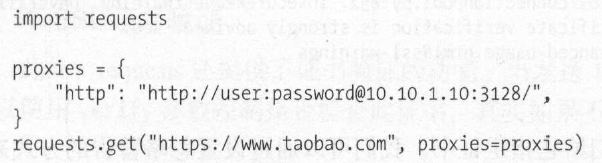
对于某些网站,在测试的时候请求几次, 能正常获取内容。但是一旦开始大规模爬取,对于大规模且频繁的请求,网站可能会弹出验证码,或者跳转到登录认证页面, 更甚者可能会直接封禁客户端的IP ,导致一定时间段内无法访问。那么,为了防止这种情况发生,我们需要设置代理来解决这个问题,这就需要用到proxies参数。可以用这样的方式设置:

若代理需要使用HTTP Basic Auth ,可以使用类似http://user: password@host: port 这样的语法来设置代理
requests 还支持SOCKS 协议的代理

超时设置
在本机网络状况不好或者服务器网络响应太慢甚至无响应时,我们可能会等待特别久的时间才可能收到响应,甚至到最后收不到响应而报错。为了防止服务器不能及时响应,应该设置一个超时时间,即超过了这个时间还没有得到响应,那就报错。这需要用到timeout 参数。这个时间的计算是发出请求到服务器返回响应的时间。

将超时时间设置为1 秒,如果1秒内没有响应,那就抛出异常。
上面设置的timeout 将用作连接和读取这二者的timeout 总和。如果要分别指定,就可以传入一个元组:r = requests.get (’ https : //www .taobao.com ’, timeout=(S,11, 30))
如果想永久等待,可以直接将timeout 设置为None ,或者不设置直接留空,因为默认是None 。这样的话,如果服务器还在运行,但是响应特别慢,那就慢慢等吧,它永远不会返回超时错误的。其用法如下:r = requests. get(' https: I /www. taobao. com ’, timeout=None)或r = requests.get (’ https://www.taobao . com ’)
身份认证
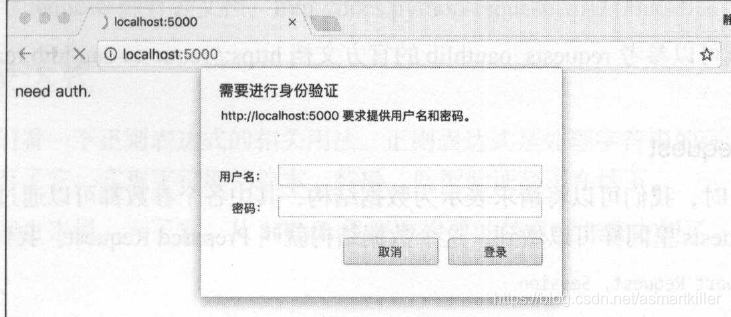
可以使用requests 自带的身份认证功能,如果用户名和密码正确的话,请求时就会自动认证成功,会返回200 状态码;如果认证失败, 则返回401 状态码。

如果参数都传一个HTTPBasicAuth 类,就显得有点烦琐了,所以requests 提供了一个更简单的写法,可以直接传一个元组,它会默认使用HTTPBasicAuth 这个类来认证

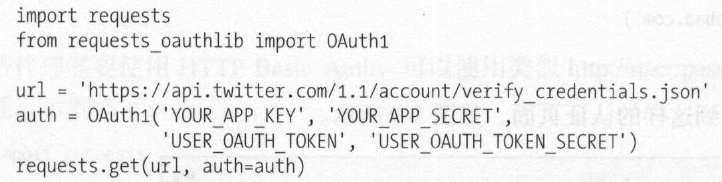
requests 还提供了其他认证方式,如OAuth认证, 不过此时需要安装oauth 包:pip3 install requests_oauthlib
Prepared Request 结构化请求数据
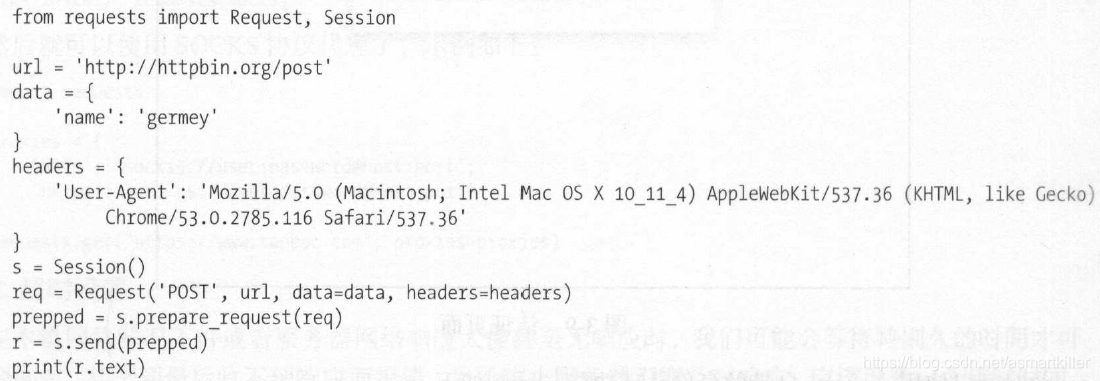
引入Request,然后用url、data和headers参数构造一个Request对象,这时需要再调用Session的prepare_request方法将其转换为一个Prepared Request对象,然后调用send方法发送即可。有了Request 这个对象,就可以将请求当作独立的对象来看待,这样在进行队列调度时会非常方便。