scrapy工作原理
| engine | 引擎,类似于一个中间件,负责控制数据流在系统中的所有组件之间流动,可以理解为“传话者” |
| spider | 爬虫,负责解析response和提取Item |
| downloader | 下载器,负责下载网页数据给引擎 |
| scheduler | 调度器,负责将url入队列,默认去掉重复的url |
| item pipelines | 管道,负责处理被spider提取出来的Item数据 |

1、从spider中获取到初始url给引擎,告诉引擎帮我给调度器;
2、引擎将初始url给调度器,调度器安排入队列;
3、调度器告诉引擎已经安排好,并把url给引擎,告诉引擎,给下载器进行下载;
4、引擎将url给下载器,下载器下载页面源码;
5、下载器告诉引擎已经下载好了,并把页面源码response给到引擎;
6、引擎拿着response给到spider,spider解析数据、提取数据;
7、spider将提取到的数据给到引擎,告诉引擎,帮我把新的url给到调度器入队列,把信息给到Item Pipelines进行保存;
8、Item Pipelines将提取到的数据保存,保存好后告诉引擎,可以进行下一个url的提取了;
9、循环3-8步,直到调度器中没有url,关闭网站(若url下载失败了,会返回重新下载)。
使用场景:
在需要爬取的数据量极大的情况下,建议使用scrapy框架。性能好。
一、创建项目
创建一个爬虫项目test_spider。cmd,cd到将要存放项目的目录中。
scrapy startproject test_spider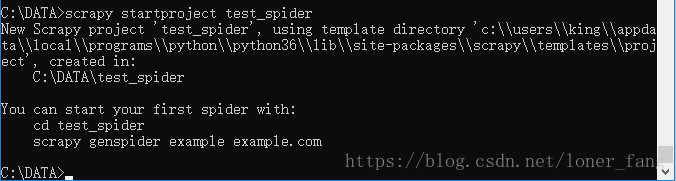


| __init__.py | c初始化文件 |
| items.py | 存放的是要爬取的字段。Item是保存爬取到的数据的容器。 |
| middlewares.py | 中间件 |
| pipeines.py | 管道文件,负责处理被spider提取出来的Item,例如数据持久化(将爬取的结果保存到文件/数据库中) |
| settings.py | 配置文件 |
| spiders | spider核心代码的目录 |
二、创建爬虫
创建爬虫spider文件。
scrapy genspider 爬虫名称 允许爬取的域
scrapy genspider test_spider example.com三、思路及各文件内容
1、先确定要爬的网站和需要提取的信息(如标题、url、作者、日期等)
2、查看源码和element中的代码是否一致。爬虫返回的response是源码。因此如果element中的代码和源码不一致的话,就不能直接看element中的代码,需要查看网页源代码。
3、查看分页规律,看能否直接提取下一页的url。
4、观察信息所在的代码结构,定位元素、提取信息。
5、以上思路全部搞清楚后,写码,先item.py。
以爬取51testing论坛的【测试用例设计】专栏下的帖子为例。
明确目标:item.py
明确想要抓取的目标,定义需要爬取的信息(字段)
import scrapy
class Spider51TestingItem(scrapy.Item):
# 类型
style = scrapy.Field()
# 标题
title = scrapy.Field()
# 链接
link = scrapy.Field()
# 作者
author = scrapy.Field()
# 日期
date = scrapy.Field()
# 回复
response = scrapy.Field()
# 查看
look = scrapy.Field()制作爬虫:test_spider.py
解析数据,并提取信息和新的url。
# -*- coding: utf-8 -*-
import scrapy
from spider_51testing.items import Spider51TestingItem
class TestingSpiderSpider(scrapy.Spider):
name = 'testing_spider' # 定义爬虫的名称,用于区别spider,该名称必须是唯一的,不可为不同的spider设置相同的名字
allowed_domains = ['bbs.51testing.com'] # 定义允许爬取的域,若不是该列表内的域名则放弃抓取
base_url = 'http://bbs.51testing.com/forum.php?mod=forumdisplay&fid=19&page='
page = 1
start_urls = [base_url+str(page)] # spider在启动时爬取的入口url列表,后续的url从初始的url抓取到的数据中提取
base_link = 'http://bbs.51testing.com/'
def parse(self, response): # 定义回调函数,每个初始url完成下载后生成的response对象会作为唯一参数传递给parse()函数。负责解析数据、提取数据(生成Item)、以及生成需要进一步处理的url
node_list = response.xpath('//tbody[@id ="separatorline"]/following-sibling::tbody')
totalpage = response.xpath('//a[@class="bm_h"]/@totalpage').extract()[0]
for node in node_list:
item = Spider51TestingItem() # 类型是list
item['style'] = node.xpath('.//th[@class="common"]/em/a/text()').extract()[0] \
if len(node.xpath('.//th[@class="common"]/em/a/text()')) else None
item['title'] = node.xpath('.//th/em/following-sibling::a[1]/text()').extract()[0] \
if len(node.xpath('.//th/em/following-sibling::a[1]/text()')) else None
item['link'] = self.base_link + node.xpath('.//th/em/following-sibling::a[1]/@href').extract()[0] \
if len(node.xpath('.//th/em/following-sibling::a[1]/@href')) else None
item['author'] = node.xpath('.//td[@class="by"]//cite/a/text()').extract()[0] \
if len(node.xpath('.//td[@class="by"]//cite/a/text()')) else None
item['date'] = node.xpath('.//td[@class="by"]//em/span/text()').extract()[0]\
if len(node.xpath('.//td[@class="by"]//em/span/text()')) else None
item['response'] = node.xpath('.//td[@class="num"]//a/text()').extract()[0] \
if len(node.xpath('.//td[@class="num"]//a/text()')) else None
item['look'] = node.xpath('.//td[@class="num"]//em/text()').extract()[0] \
if len(node.xpath('.//td[@class="num"]//em/text()')) else None
yield item # 返回item(列表),return会直接退出程序,这里是有yield
if self.page < int(totalpage):
self.page += 1
yield scrapy.Request(self.base_url+str(self.page), callback=self.parse) # 返回请求,请求回调parse,此处也是是有yield存储内容:pipelines.py
设计管道存储内容。当spider收集好Item后,会将Item(由字典组成的列表)传递到Item Pipeline,这些Item Pipeline组件按定义的顺序处理Item。
import json
class Spider51TestingPipeline(object):
def __init__(self):
self.f = open('testing.json','wb')
def process_item(self, item, spider):
if item['title'] != None: # 过滤掉移动类的帖子
data = json.dumps(dict(item), ensure_ascii=False, indent=4) + ','
self.f.write(data.encode('utf-8'))
return item # 返回item,告诉引擎,我已经处理好了,你可以进行下一个item数据的提取了
def close_spider(self,spider):
self.f.close()相关配置:settings.py
为了启动Item Pipelines组件,必须将类添加到settings.py的ITEM_PIPELINES中,此处只有一个pipeline类,因此找到ITEM_PIPELINES,打开代码。
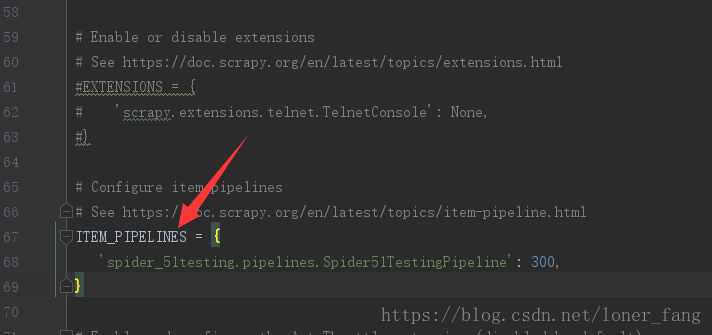
如果有多个item pipelines的话(多种保存方式),需要在ITEM_PIPELINES中配置类,后面的“300”随意设置。
分配给每个类的整型值,确定了它们的运行顺序。数值越低,组件的优先级越高,运行顺序越靠前。
四、启动spider
进入项目根目录,运行如下代码启动spider。
scrapy crawl testing_spider运行spider使用 scrapy crawl name
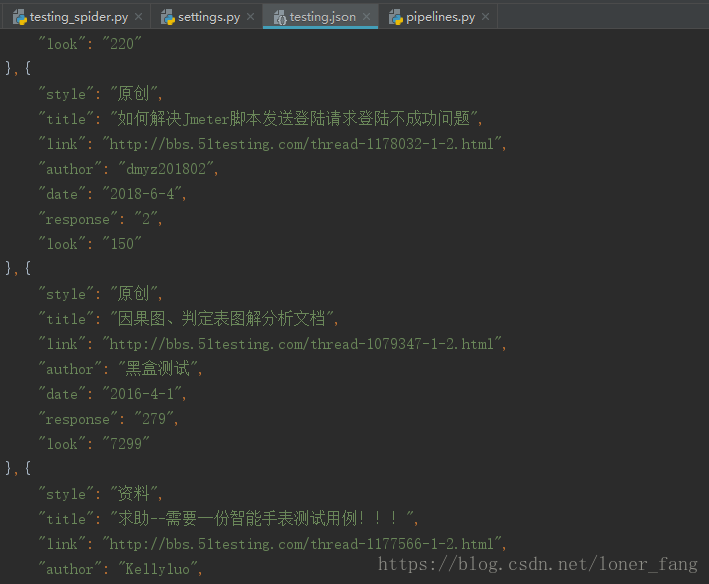
生成testing.json文件,结果如下:
如果报UnicodeEncodeError: 'ascii' codec can't encode characters错误,在test_spider.py文件上添加下面代码指定编码格式:
import sys
reload(sys)
sys.setdefaultencoding('utf-8')五、未解决的问题
初始url的type字段全部未保存到json文件中,获取的时候是获取到第一页的type数据的,就是没有保存到json文件中,还未找到原因。