本次为大家带来一期基于ICEEMDAN-GWO-LSSVM的轴承诊断方法。
简介
①对官方下载的西储大学数据进行处理
②采用ICEEMDAN对数据进行分解,得到若干个IMF分量,计算前n个IMF分量的排列熵,从而构造特征向量,本期内容选用前8个
③将特征向量归一化处理后,划分训练集和测试集,送入LSSVM进行诊断
④采用GWO灰狼算法对LSSVM的两个关键参数(σ2(sig2)和γ (gam)参数)进行优化,提升轴承诊断的准确率
内容详解
一,对官方下载的西储大学数据进行处理,步骤如下:
一共加载10种数据,然后取每个数据的DE_time(%DE是驱动端数据 FE是风扇端数据 BA是加速度数据 选择其中一个就行)
2.设置滑动窗口w,每个数据的故障样本点个数s,每个故障类型的样本量m
将所有的数据滑窗完毕之后,综合到一个data变量中
有关西储大学数据的处理之前有文章也讲过,大家可以看这篇文章:西储大学轴承诊断数据处理,matlab免费代码获取
最后得到的数据是一个1200*2048的矩阵,其中1200是样本量,2048是特征。1200又等于120*10,10是指10种故障状态,120是指每种状态有120个样本。在代码中是data_total_1797.mat
二,采用ICEEMDAN对西储大学数据进行分解处理
ICEEMDAN分解图:
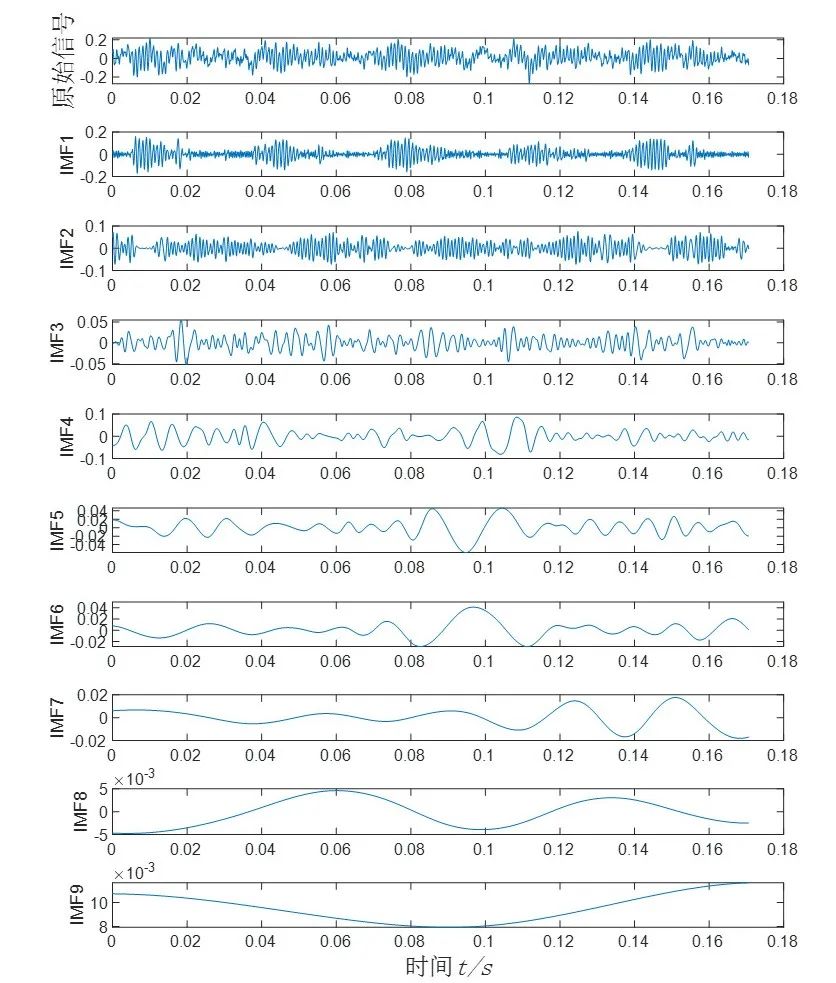
由ICEEMDAN分解图可知,轴承的主要信息包含在前几个IMF分量,本期内容取的是前8个IMF分量。分别求取前8个IMF分量的排列熵来构建特征向量。
最后得到一个1200×8的矩阵,该矩阵即为特征向量!在代码中是
feature_vector.mat
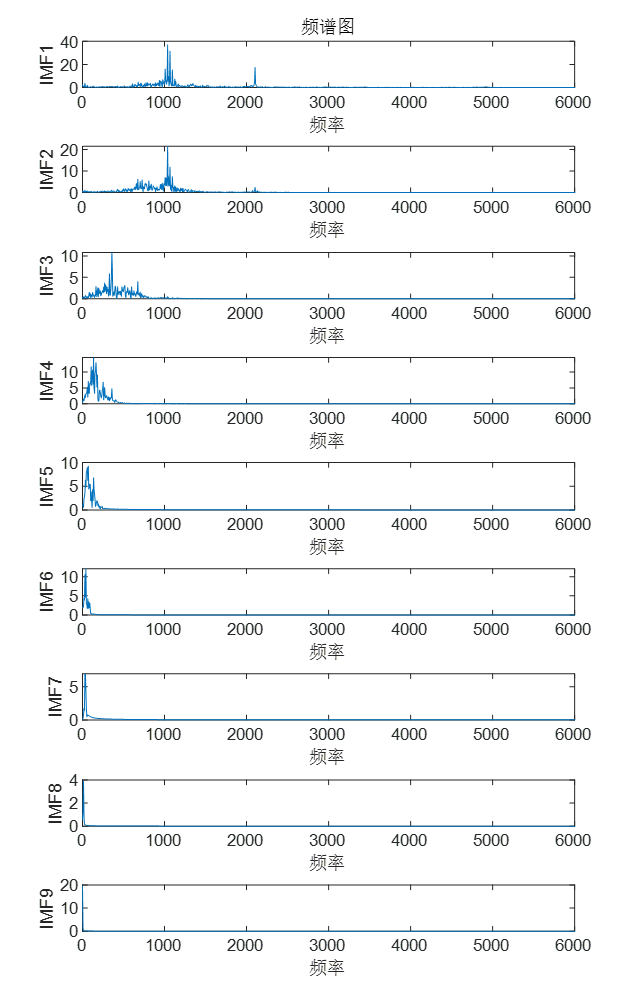
另外附上,ICEEMDAN包络谱图:

ICEEMDAN频谱图:
三,将构建好的特征向量送入LSSVM进行训练
特征向量进行归一化处理,将每种状态的前80组用于训练,后40组用于测试。得到的结果如下:
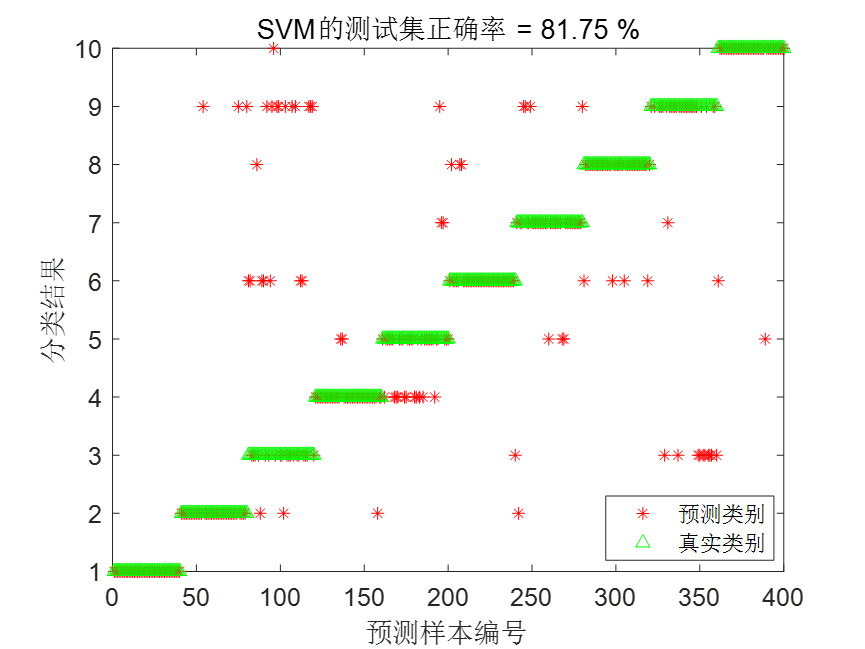
四,采用GWO优化LSSVM
将LSSVM的两个关键参数(σ2(sig2)和γ (gam)参数)上下限设置为:
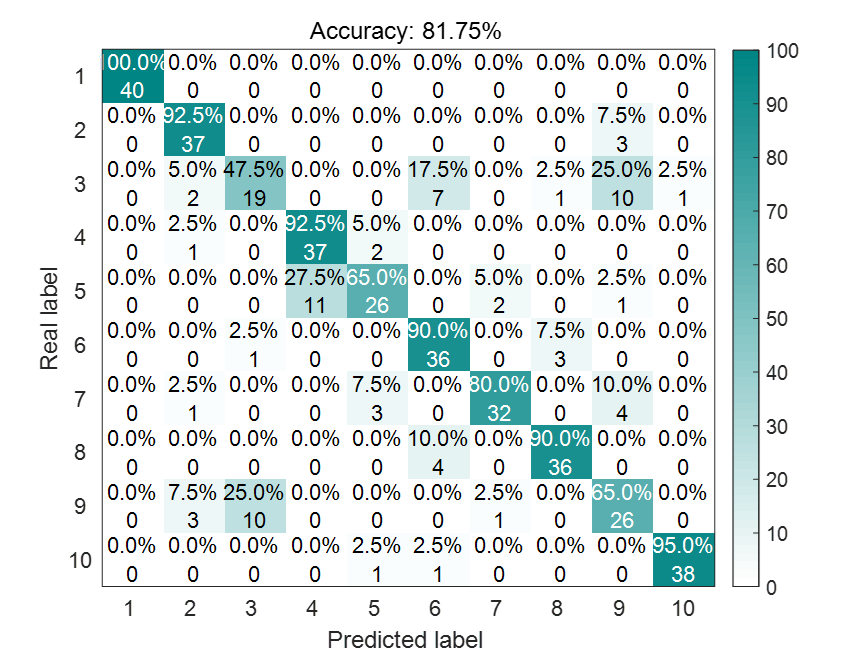
[10^-8,10^8]。灰狼个数设置为15,迭代次数设置为30。经过优化后,GWO-LSSVM的诊断结果为:
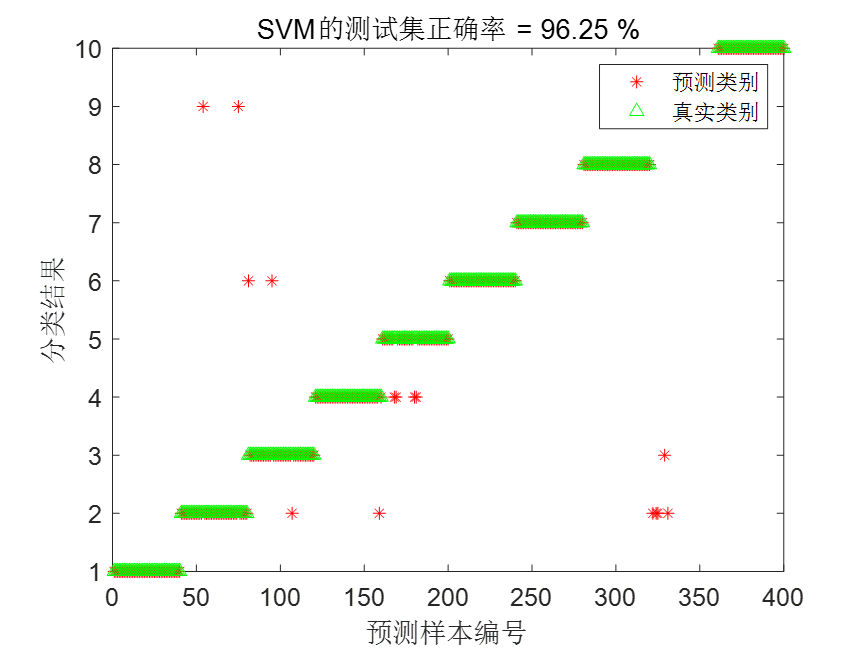
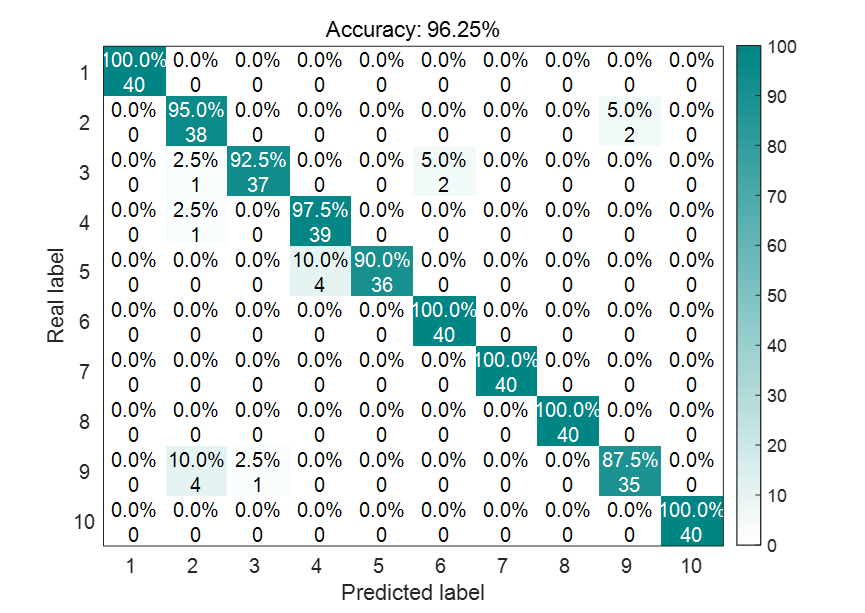
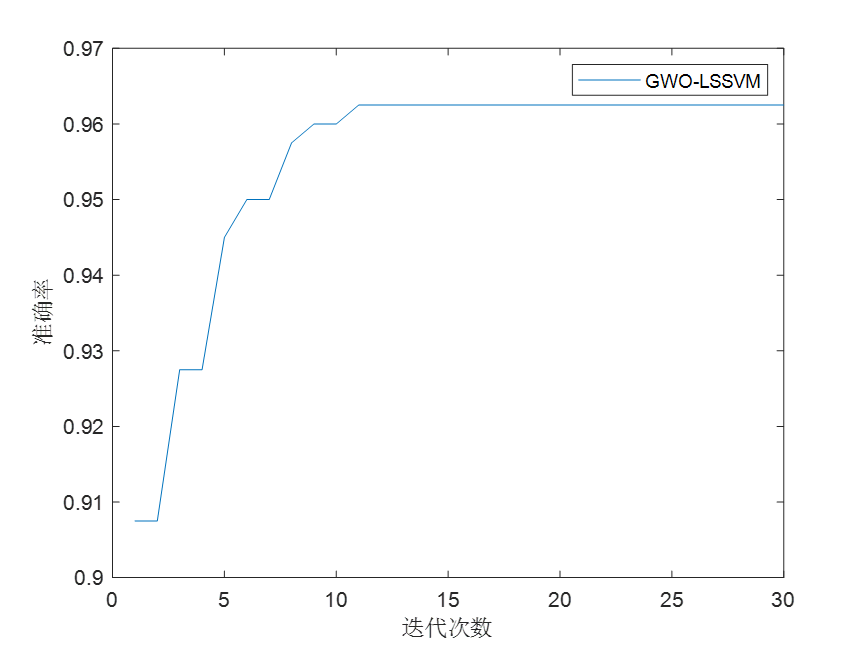
可以看到,相比于未优化的LSSVM,GWO-LSSVM的诊断精度有了极大的提升。
部分代码
数据处理代码:
clc;
clear;
addpath(genpath(pwd));
%DE是驱动端数据 FE是风扇端数据 BA是加速度数据 选择其中一个就行
load 97.mat %正常
load 107.mat %直径0.007英寸,转速为1750时的 内圈故障
load 120.mat %直径0.007,转速为1750时的 滚动体故障
load 132.mat %直径0.007,转速为1750时的 外圈故障
load 171.mat %直径0.014英寸,转速为1750时的 内圈故障
load 187.mat %直径0.014英寸,转速为1750时的 滚动体故障
load 199.mat %直径0.014英寸,转速为1750时的 外圈故障
load 211.mat %直径0.021英寸,转速为1750时的 内圈故障
load 224.mat %直径0.021英寸,转速为1750时的 滚动体故障
load 236.mat %直径0.021英寸,转速为1750时的 外圈故障
w=1000; % w是滑动窗口的大小1000
s=2048; % 每个故障表示有2048个故障点
m = 10; %每种故障有120个样本
D0=[];
for i =1:m
D0 = [D0,X097_DE_time(1+w*(i-1):w*(i-1)+s)];
end
D0 = D0';ICEEMDAN画图的代码:
clc
clear
close all
load data_total_1797.mat
fs=12000;%采样频率
Ts=1/fs;%采样周期
L=2048;%采样点数
t=(0:L-1)*Ts;%时间序列
%ICEEMDAN的相关参数设置
Nstd = 0.1; %信噪比,作用为了抑制混叠效应。噪声权重(范围:0-inf,一般选择0-1)
NR = 80; %噪声添加次数,进行60次的噪声添加,一般选择50-100
MaxIter = 8; %对emd 内部最大包络次数设定。分解出分量的最大个数(假设ceemdan本来分解出10个分量,你将该值设置为5:那么最终就会获得5个分量。如果你将该值设置为20:最终还是会获得10个分量)
%该值一般设置为inf或一个很大的数。如果你要求ICEEMDAN每次只获得一个分量,那么就可以将该参数设置为1。
X = data(1,:)'; %这里可以选取DE(驱动端加速度)、FE(风扇端加速度)、BA(基座加速度),直接更改变量名,挑选一种即可。
[u,its]=iceemdan(X,Nstd,NR,MaxIter,1);
K = size(u,1);
figure(1);
imfn=u;
n=size(imfn,1);
subplot(n+1,1,1);
plot(t,X); %故障信号
ylabel('原始信号','fontsize',12,'fontname','宋体');
for n1=1:n
subplot(n+1,1,n1+1);
plot(t,u(n1,:));%输出IMF分量,a(:,n)则表示矩阵a的第n列元素,u(n1,:)表示矩阵u的n1行元素
ylabel(['IMF' int2str(n1)]);%int2str(i)是将数值i四舍五入后转变成字符,y轴命名
end
xlabel('时间\itt/s','fontsize',12,'fontname','宋体');特征提取的代码:
clear
clc
Nstd = 0.1; %信噪比,作用为了抑制混叠效应。噪声权重(范围:0-inf,一般选择0-1)
NR = 80; %噪声添加次数,进行60次的噪声添加,一般选择50-100
MaxIter = 8; %对emd 内部最大包络次数设定。分解出分量的最大个数(假设ceemdan本来分解出10个分量,你将该值设置为5:那么最终就会获得5个分量。如果你将该值设置为20:最终还是会获得10个分量)
%该值一般设置为inf或一个很大的数。如果你要求ICEEMDAN每次只获得一个分量,那么就可以将该参数设置为1。
%特征提取时只对前8个IMF分量进行熵值计算,因此,这里 设置为8
load data_total_1797.mat
%排列熵参数设置
M = 3; % 嵌入维数
T = 1; % 延迟时间
feature_vector = []; %最终的特征向量
for i = 1:size(data,1)
i
[u,its]=iceemdan(data(i,:),Nstd,NR,MaxIter,1);
for j=1:8
[pe ,hist] = PermutationEntropy(u(j,:),M,T);
PE(1,j) = pe;
end
feature_vector = [feature_vector;PE];
end
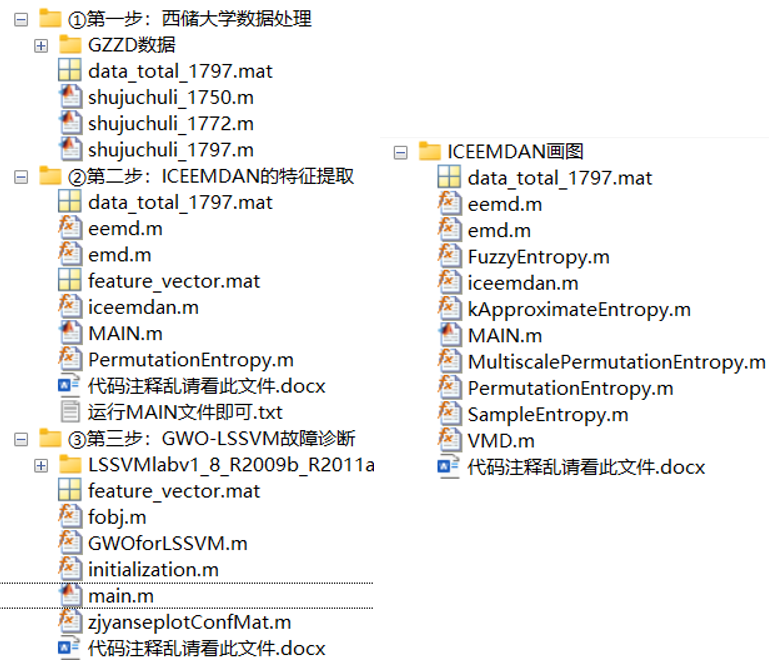
save feature_vector.mat feature_vector所有代码目录截图:
代码获取
完整代码获取,后台回复关键词:
LSSVM诊断