目录
一:前言
OpenPose是一个基于深度学习的人体姿势估计库,它可以从图像或视频中准确地检测和估计人体的关键点和姿势信息。OpenPose的目标是将人体姿势估计变成一个实时、多人、准确的任务。它的原理部分已经在上一篇非常详细的讲解了——本节介绍训练部分
二:导入数据,定义参数
因为是基于coco数据集来做的,所有导入的都是coco的api来处理数据,所以很多操作可以使用api进行简化
# DATA_DIR = 'D:\\eclipse-workspace\\PyTorch\\coco-data'
DATA_DIR = 'C:\\python\\code\\tangyudi\\yolo\\PyTorch-YOLOv3\\data\\coco'
ANNOTATIONS_TRAIN = [os.path.join(DATA_DIR, 'annotations', item) for item in ['person_keypoints_train2014.json']]
ANNOTATIONS_VAL = os.path.join(DATA_DIR, 'annotations', 'person_keypoints_val2014.json')
IMAGE_DIR_TRAIN = os.path.join(DATA_DIR, 'images\\train2014')
IMAGE_DIR_VAL = os.path.join(DATA_DIR, 'images\\val2014')在使用GPU进行深度学习训练或推断时,数据通常需要从主机内存传输到GPU内存,这涉及到内存之间的数据拷贝操作。这些数据拷贝操作可能会引入一定的开销,降低数据传输效率。
通过将数据固定在主机内存中,可以避免每次传输数据时的拷贝操作,从而减少数据传输的开销。这对于大规模的数据传输、高频率的数据传输或需要实时性能的任务非常有用。
def cli():
parser = argparse.ArgumentParser(
description=__doc__,
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
)
# train_cli(parser)是cli()函数的一部分,它负责添加训练相关的命令行参数。
train_cli(parser)
parser.add_argument('-o', '--output', default=None,
help='output file')
parser.add_argument('--stride-apply', default=1, type=int,
help='apply and reset gradients every n batches')
parser.add_argument('--epochs', default=75, type=int,
help='number of epochs to train')
parser.add_argument('--freeze-base', default=0, type=int,
help='number of epochs to train with frozen base')
parser.add_argument('--pre-lr', type=float, default=1e-4,
help='pre learning rate')
parser.add_argument('--update-batchnorm-runningstatistics',
default=False, action='store_true',
help='update batch norm running statistics')
parser.add_argument('--square-edge', default=368, type=int,
help='square edge of input images')
parser.add_argument('--ema', default=1e-3, type=float,
help='ema decay constant')
parser.add_argument('--debug-without-plots', default=False, action='store_true',
help='enable debug but dont plot')
parser.add_argument('--disable-cuda', action='store_true',
help='disable CUDA')
parser.add_argument('--model_path', default='./network/weight/', type=str, metavar='DIR',
help='path to where the model saved')
args = parser.parse_args()
# add args.device
args.device = torch.device('cpu')#设置设备
args.pin_memory = False #内存固定
if not args.disable_cuda and torch.cuda.is_available():
args.device = torch.device('cuda')
args.pin_memory = True
return args三:初始化加载数据成类的属性,打包成dataloder
def train_factory(args, preprocess, target_transforms):
train_datas = [datasets.CocoKeypoints(
root=args.train_image_dir,
annFile=item,
preprocess=preprocess,
image_transform=transforms.image_transform_train,
target_transforms=target_transforms,
n_images=args.n_images,
) for item in args.train_annotations]
train_data = torch.utils.data.ConcatDataset(train_datas)
# 初始化完后打包成dataloder
train_loader = torch.utils.data.DataLoader(
train_data, batch_size=args.batch_size, shuffle=True,
pin_memory=args.pin_memory, num_workers=args.loader_workers, drop_last=True)
val_data = datasets.CocoKeypoints(
root=args.val_image_dir,
annFile=args.val_annotations,
preprocess=preprocess,
image_transform=transforms.image_transform_train,
target_transforms=target_transforms,
n_images=args.n_images,
) # 初始化完后打包成dataloder
val_loader = torch.utils.data.DataLoader(
val_data, batch_size=args.batch_size, shuffle=False,
pin_memory=args.pin_memory, num_workers=args.loader_workers, drop_last=True)
return train_loader, val_loader, train_data, val_data进入__getitem__函数
这是实际取数据的函数__getitem__,index是随机取的,而且每一行图片都要进行很多预处理操作
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
tuple: Tuple (image, target). target is the object returned by ``coco.loadAnns``.
"""
# 获取图片的id,因为是基于coco数据集来做的,所有导入的都是coco的api来处理数据,所以很多操作可以使用api进行简化
image_id = self.ids[index]
# 根据id获取标注的信息
ann_ids = self.coco.getAnnIds(imgIds=image_id, catIds=self.cat_ids)
# 加载与之前步骤中获得的ann_ids对应的注释。它根据提供的ID从COCO数据集中获取注释信息。
anns = self.coco.loadAnns(ann_ids)
anns = copy.deepcopy(anns)
# 直接利用api加载coco的图片,路径,图片名字,大小等等很多。 单单取[0]就这么多信息了。。。
image_info = self.coco.loadImgs(image_id)[0]
# 记录(通常是打印)图像信息
self.log.debug(image_info)
with open(os.path.join(self.root, image_info['file_name']), 'rb') as f:
image = Image.open(f).convert('RGB')
meta_init = {
'dataset_index': index,
'image_id': image_id,
'file_name': image_info['file_name'],
}
# 元数据(Metadata)是描述数据的数据,它提供关于数据的特征、属性和其他相关信息的描述。元数据可以帮助理解和管理数据,包括数据的来源、
# 格式、结构、内容、时间戳、创建者、修改历史、使用许可等。
# 注释(anns)它是与图像关联的对象的标注信息。注释可以包括多个对象的标注,每个对象可能有不同的属性和标记。
# self.preprocess方法用于对图像和注释进行预处理操作,可能包括缩放、裁剪、标准化等操作。并返回处理后的图像、注释和其他元数据。
image, anns, meta = self.preprocess(image, anns, None)
if isinstance(image, list):
# 检查image是否为列表类型。如果image是列表,则表示有多张图像需要处理。
return self.multi_image_processing(image, anns, meta, meta_init)
# 进行单图像处理。,,meta_init表示元数据的初始值。
# 只希望拿到anns的keypoints,坐标的含有是:(x,y,keypoints)keypoints(0,1,2)0是该点未被标记,1是标了但是被遮挡了,2是标了而且没被遮挡
# 一般1和2有用到,0没用,因为没标注
return self.single_image_processing(image, anns, meta, meta_init)获得有效区域
def single_image_processing(self, image, anns, meta, meta_init):
# meta_init中的键值对更新到meta字典中。如果meta中已经存在相同的键,则会被meta_init中的值覆盖。
meta.update(meta_init)
# transform image
original_size = image.size
# 将图像进行变换操作,可能包括缩放、裁剪、标准化等操作,用于将图像转换为模型输入所需的格式。
image = self.image_transform(image)
# 确保图像变换过程中没有出现尺寸错误。
assert image.size(2) == original_size[0]
assert image.size(1) == original_size[1]
# mask valid
# valid_area可能表示一个矩形区域或是一个二值掩码(mask),用于指示图像中哪些像素属于有效区域。矩形区域可以由左上角和右下角坐标表示,
# 或者可以使用二值掩码标记有效区域内的像素。meta['valid_area'] = [ 0. 20. 368. 327.]也就是整个人的图像框
# 从meta字典中获取名为valid_area的键对应的值。valid_area翻译过来就是:可能表示图像中的有效区域,也就是整个人的图像框。
valid_area = meta['valid_area']#valid_area
# 将图像中的非有效区域(根据valid_area进行定义)进行掩码处理,可能是将非有效区域的像素置为特定值或进行其他处理。
# 相当于有效区域的置为1,无效置为0, 但是没有返回值?
utils.mask_valid_area(image, valid_area)#传入图片和有效的区域核心部分:生成热图和pafs
最核心的部分:利用标注好的信息anns 来生成热图(heatmaps)和部件关联图(pafs)的真值信息。
vgg-19是3次下采样,假设输入的是368,那么采样后就是368/8=46
多了一个脖子外加一个背景
按照先后顺序来的,x和y来给你个方向,得到38个,[[1, 8], [8, 9], [9, 10], [1, 11], [11, 12], [12, 13], [1, 2], [2, 3], [3, 4], [2, 14], [1, 5], [5, 6], [6, 7], [5, 15], [1, 0], [0, 14], [0, 15], [14, 16], [15, 17]]
ef get_ground_truth(self, anns):
#vgg-19是3次下采样,假设输入的是368,那么采样后就是368/8=46
grid_y = int(self.input_y / self.stride)
grid_x = int(self.input_x / self.stride)
channels_heat = (self.HEATMAP_COUNT + 1)#19 HEATMAP_COUNT中coco给了17个,但是我们多了一个脖子所以18个,+1是背景所以是19
channels_paf = 2 * len(self.LIMB_IDS)#按照先后顺序来的,x和y来给你个方向,得到38个,[[1, 8], [8, 9], [9, 10], [1, 11], [11, 12], [12, 13], [1, 2], [2, 3], [3, 4], [2, 14], [1, 5], [5, 6], [6, 7], [5, 15], [1, 0], [0, 14], [0, 15], [14, 16], [15, 17]]
heatmaps = np.zeros((int(grid_y), int(grid_x), channels_heat))
pafs = np.zeros((int(grid_y), int(grid_x), channels_paf))#对于躯干来说,没有躯干的位置,向量为0,有躯干的地方为1
keypoints = []
# anns有多少list,就说明有多少个人,anns里面的num_keypoints表示每个人体部位关键点有被标注的个数,有些可能没标有些可能标了但是被遮挡了(也就是1)
# 第一个注释的"num_keypoints"为0,表示该注释中没有标记的关键点。第二个注释的"num_keypoints"为14,表示该注释中标记了14个关键点,等等等等
for ann in anns:
# 17种部位,3列(x,y,keypoint)
single_keypoints = np.array(ann['keypoints']).reshape(17, 3)
# 在这里添加个脖子,先找到左肩膀和右肩膀求平均,就是脖子的位置了
single_keypoints = self.add_neck(single_keypoints)
keypoints.append(single_keypoints)
keypoints = np.array(keypoints)
# 去除不合法的关节。具体而言,这个方法可能会处理一些关节坐标异常或无效的情况,例如超出图像范围、无效的坐标值等。
keypoints = self.remove_illegal_joint(keypoints)生成高斯热图
从0遍历到18,每个部位都遍历
# 有了标注点后就开始生成高斯热图,在ppt的第9页
# confidance maps for body parts
# 从0遍历到18,每个部位都遍历
for i in range(self.HEATMAP_COUNT):
# print(keypoints)
joints = [jo[i] for jo in keypoints] # 每次遍历所有人的同一种关键点,多少人就多少个
# print(joints)
# 每次遍历每个人的同一种部位的关键点生成热图(例如肩膀),然后是0的话就是没有标注的,所以判断是否大于0.5
for joint in joints:
# 1是标注被遮挡 2是标注且没被遮挡
if joint[2] > 0.5:
center = joint[:2] # 点坐标
# 每次gaussian_map都要赋值,因为要在这基础上生成高斯热图。需要一直累加生成高斯图
gaussian_map = heatmaps[:, :, i]
# 对这个点坐标center 生成高斯热图,#7.0是sigma
heatmaps[:, :, i] = putGaussianMaps(
center, gaussian_map,
7.0, grid_y, grid_x, self.stride)生成pafs
开始一个人(同一个人)中所有部位的,一个人一个人来遍历pafs向量 self.LIMB_IDS是规定的连接规则:在第十四行开始[[1, 8], [8, 9], [9, 10], [1, 11], [11, 12], [12, 13], # [1, 2], [2, 3], [3, 4], [2, 14], [1, 5], [5, 6], [6, 7], [5, 15], [1, 0], [0, 14], [0, 15], [14, 16], [15, 17]]
putVecMaps函数: 必须有标注的,否则没法算向量
for i, (k1, k2) in enumerate(self.LIMB_IDS):
# limb
# 表示该位置是否被计算了多次(计算的数量)
count = np.zeros((int(grid_y), int(grid_x)), dtype=np.uint32)
for joint in keypoints:
# 必须有标注的,否则没法算向量
if joint[k1, 2] > 0.5 and joint[k2, 2] > 0.5:
#k1,k2是self.LIMB_IDS是规定的连接规则
centerA = joint[k1, :2]# [283. 280.]
centerB = joint[k2, :2]# [292.34824 294.96875]
# 拿到向量的结果。每次都取出两个通道? 每一个躯干位置,选择x和y两个方向0-2,2-4,4-6
vec_map = pafs[:, :, 2 * i:2 * (i + 1)]
# 使用putVecMaps 来真正的构建向量
pafs[:, :, 2 * i:2 * (i + 1)], count = putVecMaps(
centerA=centerA,
centerB=centerB,
accumulate_vec_map=vec_map,
count=count, grid_y=grid_y, grid_x=grid_x, stride=self.stride
)
# background
heatmaps[:, :, -1] = np.maximum(
1 - np.max(heatmaps[:, :, :self.HEATMAP_COUNT], axis=2),
0.
)
return heatmaps, pafs使用putVecMaps 来真正的构建向量
计算向量
b-a算出来向量a到b的向量,它表示从 centerA 指向 centerB 的向量
范数是为了获取向量的长度或大小。范数可以衡量向量的大小或大小关系,它代表了向量从原点到达该点的距离。
计算向量叉乘根据阈值选择赋值区域,任何向量与单位向量的叉乘即为四边形的面积,
不管在不在躯干上都要计算一下平行四边形的所有点到a点的距离
在大胳膊区域里面的 被算过的点 要+1,该区域计算次数都+1,为了下面取平均
现在不是躯干上的置为1。没有被计算过的地方还是本身,任何书除以1还是等于自身
def putVecMaps(centerA, centerB, accumulate_vec_map, count, grid_y, grid_x, stride):
centerA = centerA.astype(float)
centerB = centerB.astype(float)
# limb width # 做一个假设:假设都是正常人标准的人,特别高特别胖长得奇奇怪怪的先不考虑
thre = 1
centerB = centerB / stride # 映射到特征图中
centerA = centerA / stride
# b-a算出来向量a到b的向量,它表示从 centerA 指向 centerB 的向量。p19那一节,大胳膊向量,
limb_vec = centerB - centerA
# 范数是为了获取向量的长度或大小。范数可以衡量向量的大小或大小关系,它代表了向量从原点到达该点的距离。
# 求范数 这里求出来的是向量长度,为了进行归一化
norm = np.linalg.norm(limb_vec)
if (norm == 0.0):
# print 'limb is too short, ignore it...'
return accumulate_vec_map, count
# 那既然limb_vec = centerB - centerA能计算出来大小方向了,为什么还需要转换为单位向量????????
# 这是因为单位向量具有相同的方向,但长度为1,可以用来表示方向信息而不考虑其具体长度。在某些情况下,只关注向量的方向而不关注其具体的长度是有意义的,比如计算角度、方向差异等。
# limb_vec_unit计算得出单位向量
limb_vec_unit = limb_vec / norm
# print 'limb unit vector: {}'.format(limb_vec_unit)
#寻找满足我这个大胳膊区域里面的所有点
# To make sure not beyond the border of this two points
min_x = max(int(round(min(centerA[0], centerB[0]) - thre)), 0)# 得到所有可能区域
max_x = min(int(round(max(centerA[0], centerB[0]) + thre)), grid_x)
min_y = max(int(round(min(centerA[1], centerB[1]) - thre)), 0)
max_y = min(int(round(max(centerA[1], centerB[1]) + thre)), grid_y)
# 找到大胳膊区域的矩形的上下左右四个点后,可以生成的只包围大胳膊的矩形框(的x范围和y的范围)
range_x = list(range(int(min_x), int(max_x), 1))
range_y = list(range(int(min_y), int(max_y), 1))
# 生成一个网格(grid)来表示一个矩形区域,它们包含了矩形区域内所有的 x 坐标和 y 坐标。
xx, yy = np.meshgrid(range_x, range_y)
# 因为上面生成了gird,xx和yy是所有矩形的坐标,现在计算矩形中的所有点到a的距离(x和y的距离都算),# 不管在不在躯干上都要计算一下平行四边形的所有点到a点的距离
ba_x = xx - centerA[0]
ba_y = yy - centerA[1]
# 计算完所有点的ba_x和ba_y后。计算向量叉乘根据阈值选择赋值区域,任何向量与单位向量的叉乘即为四边形的面积,
# 画出图来就会明白,在胳膊上的点与a形成的四边形面积肯定小于在胳膊外面与a形成的面积要小
limb_width = np.abs(ba_x * limb_vec_unit[1] - ba_y * limb_vec_unit[0])
# mask is 2D # 小于阈值的表示在该区域上
mask = limb_width < thre
# 创建一个空的数组,以便在接下来的代码中进行填充和操作,都是对mask进行操作
vec_map = np.copy(accumulate_vec_map) * 0.0
# 之前计算得到的mask(表示大胳膊区域)用于存储大胳膊的(ture还是faslse)。
# 通过索引 yy 和 xx,将 mask 中为真的区域对应的位置的值设置为 1,其他位置的值保持为 0。这样就得到了一个与大胳膊区域对应的二维数数组
vec_map[yy, xx] = np.repeat(mask[:, :, np.newaxis], 2, axis=2)
# 0*limb_vec_unit表示不是大胳膊区域的,1*limb_vec_unit是区域里的,而且还是是单位向量limb_vec_unit
vec_map[yy, xx] *= limb_vec_unit[np.newaxis, np.newaxis, :]
#筛选:最后得到46*46的矩阵,大于0的为True 都是躯干(也就是单位向量),小于0的是false,本身mask不是的,
# 终于懂了为什么现在是还原到特征图去了,因为上面只是大胳膊的矩阵,现在要对特征图操作了,所以还原到特征图去
mask = np.logical_or.reduce((np.abs(vec_map[:, :, 0]) > 0, np.abs(vec_map[:, :, 1]) > 0))
#先算类加值?一会再平均?先算出重叠的总值
# 对accumulate_vec_map数组与count数组进行逐元素的乘法运算。
# count 使用了 count[:, :, np.newaxis],它在最后添加了一个新的维度,形状变为 (height, width, 1)。
accumulate_vec_map = np.multiply(accumulate_vec_map, count[:, :, np.newaxis])
# 加上当前关键点位置形成的向量
accumulate_vec_map = accumulate_vec_map + vec_map
# 在大胳膊区域里面的 被算过的点 要+1,该区域计算次数都+1,为了下面取平均
count[mask == True] = count[mask == True] + 1
# 下面两步操作是:先拿出来不在躯干上的,然后当前mask为true的(为false的)赋值为1为了当除数,
# 没有被计算过的赋值给mask,现在的mask的ture是没有被计算过的
mask = count == 0
# 现在不是躯干上的置为1。没有被计算过的地方还是本身,任何书除以1还是等于自身
count[mask == True] = 1
# 算平均向量,令没有被计算过的地方还是本身(如果不赋值为1的话), 另外其他算过的就计算平均值
accumulate_vec_map = np.divide(accumulate_vec_map, count[:, :, np.newaxis])
# 现在不是躯干上的置为1,还原回去0
count[mask == True] = 0
#返回更新后的 累积向量场 和 计数。
return accumulate_vec_map, count四:model初始化:加载模型 和预训练模型
这样的设计可能是为了先让模型在新任务上进行一定的训练,以便自适应新任务的数据。然后在后续的训练中,通过释放冻结的权重参数,
整个模型可以进行更全面的调整和优化,以更好地适应新任务的数据。
class rtpose_model(nn.Module):
def __init__(self, model_dict):
super(rtpose_model, self).__init__()
self.model0 = model_dict['block0']
self.model1_1 = model_dict['block1_1']
self.model2_1 = model_dict['block2_1']
self.model3_1 = model_dict['block3_1']
self.model4_1 = model_dict['block4_1']
self.model5_1 = model_dict['block5_1']
self.model6_1 = model_dict['block6_1']
self.model1_2 = model_dict['block1_2']
self.model2_2 = model_dict['block2_2']
self.model3_2 = model_dict['block3_2']
self.model4_2 = model_dict['block4_2']
self.model5_2 = model_dict['block5_2']
self.model6_2 = model_dict['block6_2']
model = rtpose_model(models)
return model# model初始化:加载模型
model = get_model(trunk='vgg19') # 可以换网络, elif trunk == 'mobilenet':
model = torch.nn.DataParallel(model).cuda()
# load pretrained
use_vgg(model) # 加载预训练模型。url = 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth'# Fix the VGG weights first, and then the weights will be released
# 其中模型的某些层或参数不需要进行更新,以保持其先前训练好的权重或特征提取能力。
for i in range(20): # 前20个子模块不更新 ,VGG19模型包含了总共19个层,VGG19模型的前20个层(索引0到19)在第一个循环中不会被更新。
for param in model.module.model0[i].parameters():
param.requires_grad = False这个操作的目的是为了获取模型中需要计算梯度和进行优化的参数集合。在训练过程中,只有这些参数会被更新,
通过这个列表,你可以将它们传递给优化器,以便在训练过程中仅更新这些参数的值。
# 这个操作的目的是为了获取模型中需要计算梯度和进行优化的参数集合。在训练过程中,只有这些参数会被更新,
trainable_vars = [param for param in model.parameters() if param.requires_grad]
# 通过这个列表,你可以将它们传递给优化器,以便在训练过程中仅更新这些参数的值。
optimizer = torch.optim.SGD(trainable_vars, lr=args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay,
nesterov=args.nesterov)五:训练开始(包括训练和验证)
for epoch in range(5):
# train for one epoch 进入def __getitem__(self, index)函数
train_loss = train(train_loader, model, optimizer, epoch)
# evaluate on validation set
val_loss = validate(val_loader, model, epoch)
train
根据给定的循环范围生成一系列带有特定格式的名称,并将它们保存在列表中供后续使用。在这个特定的例子中,生成的名称类似于 'loss_stage1_L1'、'loss_stage1_L2'、'loss_stage2_L1' 等。
def build_names():
names = []
for j in range(1, 7):
for k in range(1, 3):
names.append('loss_stage%d_L%d' % (j, k))
return namesAverageMeter 对象和 meter_dict 字典,训练函数可以在训练过程中实时跟踪和记录各种指标的平均值和当前值,以便后续分析和监控训练进展。
def train(train_loader, model, optimizer, epoch):
batch_time = AverageMeter() # 跟踪批处理时间的平均值和当前值
data_time = AverageMeter()
losses = AverageMeter()
meter_dict = {}
for name in build_names():
meter_dict[name] = AverageMeter()
meter_dict['max_ht'] = AverageMeter() # 'max_ht':用于跟踪最大关节点(身体关键点)的置信度值的指标。
meter_dict['min_ht'] = AverageMeter() # 'min_ht':用于跟踪最小关节点的置信度值的指标。
meter_dict['max_paf'] = AverageMeter() # 'max_paf':用于跟踪最大关节点之间部分关联场(Part Affinity Field)的置信度值的指标。
meter_dict['min_paf'] = AverageMeter() # min_paf':用于跟踪最小关节点之间部分关联场的置信度值的指标。损失
saved_for_loss是append后的,他有heatmap_target和paf_target这两个预测值
然后与heatmap_target, paf_target这两个真实值做损失,这个是标注得到数据
total_loss, saved_for_log = get_loss(saved_for_loss, heatmap_target, paf_target)完整训练过程
他有heatmap_target和paf_target这两个预测值,然后与heatmap_target, paf_target这两个真实值做损失,这个真实值在加载数据的时候生成的
def train(train_loader, model, optimizer, epoch):
batch_time = AverageMeter() # 跟踪批处理时间的平均值和当前值
data_time = AverageMeter()
losses = AverageMeter()
meter_dict = {}
for name in build_names():
meter_dict[name] = AverageMeter()
meter_dict['max_ht'] = AverageMeter() # 'max_ht':用于跟踪最大关节点(身体关键点)的置信度值的指标。
meter_dict['min_ht'] = AverageMeter() # 'min_ht':用于跟踪最小关节点的置信度值的指标。
meter_dict['max_paf'] = AverageMeter() # 'max_paf':用于跟踪最大关节点之间部分关联场(Part Affinity Field)的置信度值的指标。
meter_dict['min_paf'] = AverageMeter() # min_paf':用于跟踪最小关节点之间部分关联场的置信度值的指标。
# switch to train mode
model.train()
end = time.time()
for i, (img, heatmap_target, paf_target) in enumerate(train_loader):
# measure data loading time
# writer.add_text('Text', 'text logged at step:' + str(i), i)
# for name, param in model.named_parameters():
# writer.add_histogram(name, param.clone().cpu().data.numpy(),i)
data_time.update(time.time() - end)
img = img.cuda()
heatmap_target = heatmap_target.cuda()
paf_target = paf_target.cuda()
# compute output,获得喂给模型后的数据。任何计算损失
_, saved_for_loss = model(img)
# saved_for_loss是append后的,他有heatmap_target和paf_target这两个预测值,然后与heatmap_target, paf_target这两个真实值做损失
total_loss, saved_for_log = get_loss(saved_for_loss, heatmap_target, paf_target)
# 这段代码的主要目的是在迭代过程中更新和跟踪多个指标的值,包括损失函数和其他评估指标。这有助于监控模型的训练进展并进行性能评估。
for name, hyt in meter_dict.items():
"""
meter_dict.items():
{'loss_stage1_L1': < __main__.AverageMeterobjectat0x0000023397D1DF10 >,
'loss_stage1_L2': < __main__.AverageMeterobjectat0x000002338368CDC0 >,
'loss_stage2_L1': < __main__.AverageMeterobjectat0x000002338368CF10 >,
'loss_stage2_L2': < __main__.AverageMeterobjectat0x000002338368CF70 >,
'loss_stage3_L1': < __main__.AverageMeterobjectat0x000002338368CF40 >,
'loss_stage3_L2': < __main__.AverageMeterobjectat0x000002338368CE50 >,
'loss_stage4_L1': < __main__.AverageMeterobjectat0x000002338368CEB0 >,
'loss_stage4_L2': < __main__.AverageMeterobjectat0x000002338368CDF0 >,
'loss_stage5_L1': < __main__.AverageMetobjectat0x000002338368CD90 >,
'loss_stage5_L2': < __main__.AverageMeterobjectat0x000002338368CBB0 >,
'loss_stage6_L1': < __main__.AverageMeterobjectat0x000002338368CAC0 >,
'loss_stage6_L2': < __main__.AverageMeterobjectat0x000002338368CB50 >,
'max_ht': < __main__.AverageMeterobjectat0x0000023397D1DD00 >,
'min_ht': < __main__.AverageMeterobjectat0x0000023397D1DD90 >,
'max_paf': < __main__.AverageMeterobjectat0x000002338368CA00 >,
'min_paf': < __main__.AverageMeterobjectat0x000002338368CA60 >
"""
print('name是什么?', name)
print('hyt是什么?', hyt)
meter_dict[name].update(saved_for_log[name], img.size(0)) # 在每个步骤中更新指标的值,并在需要时计算平均值。这有助于跟踪指标的变化和趋势。
losses.update(total_loss, img.size(0))#img.size(0) 是当前批处理的图像数量
# compute gradient and do SGD step
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0: # 每20轮打印1次输出
print_string = 'Epoch: [{0}][{1}/{2}]\t'.format(epoch, i, len(train_loader))
print_string += 'Data time {data_time.val:.3f} ({data_time.avg:.3f})\t'.format(data_time=data_time)
print_string += 'Loss {loss.val:.4f} ({loss.avg:.4f})'.format(loss=losses)
for name, value in meter_dict.items():
print_string += '{name}: {loss.val:.4f} ({loss.avg:.4f})\t'.format(name=name, loss=value)
print(print_string)
return losses.avg效果演示:


视频效果

历史记录
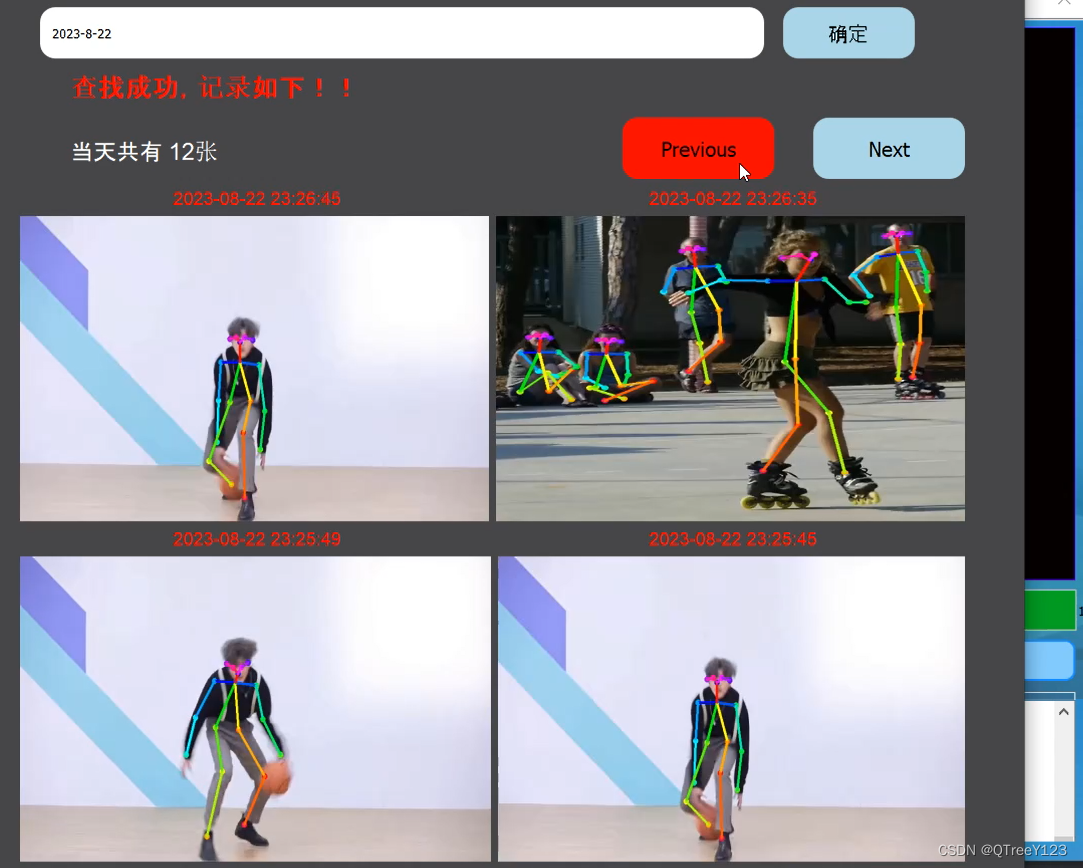
完整代码+UI界面
视频,笔记和代码,以及注释都已经上传网盘,放在主页置顶文章