快速安装scrapy
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy
安装完成之后在cmd里面输入scrapy

如果出现以上的情况,说明已经安装成功了
新建scrapy项目,我们不能直接在pycharm里面新建,我们要在cmd新建
scrapy startproject +名字 ## 前提进入该文件夹

下面的这个代表我的项目文件夹,然后我们再进去

下面这个文件夹代表了scrapy的框架

接着我们找要爬取的网站,按f12

然后我们开始写代码
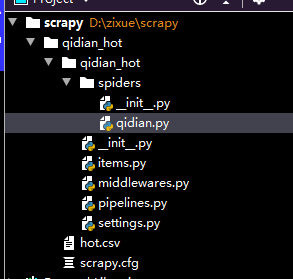
目录如下
#-*-coding:utf-8-*-
from scrapy import Request
from scrapy.spiders import Spider
class HotSalesSpider(Spider):
#定义爬虫名称
name = 'hot'
#起始的URL列表
start_urls = ["https://www.qidian.com/rank/hotsales?style=1"]
#解析函数
def parse(self, response):
#使用xpath定位到小说内容的div元素
list_selector = response.xpath("//div[@class='book-mid-info']")
#依次读取每部小说的元素,从中获取名称、作者、类型和形式
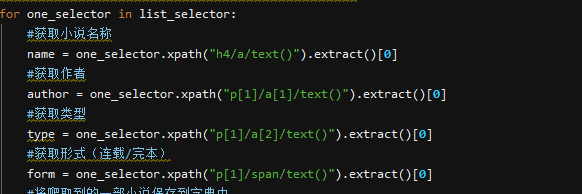
for one_selector in list_selector:
#获取小说名称
name = one_selector.xpath("h4/a/text()").extract()[0]
#获取作者
author = one_selector.xpath("p[1]/a[1]/text()").extract()[0]
#获取类型
type = one_selector.xpath("p[1]/a[2]/text()").extract()[0]
#获取形式(连载/完本)
form = one_selector.xpath("p[1]/span/text()").extract()[0]
#将爬取到的一部小说保存到字典中
hot_dict = {"name":name, #小说名称
"author":author, #作者
"type":type, #类型
"form":form} #形式
#使用yield返回字典
yield hot_dict
写完之后保存,我们用cmd进入scrapy文件夹

输入以下命令
scrapy crawl hot -o hot.csv
为什么会有hot那,因为我们定义了一个hot的爬虫名字

运行结束会出现下面的结果

然后我们打开scrapy文件夹,里面会多出来一个csv文件,我们用文本编辑器打开

name,author,type,form,就是我们刚刚所写的对应的代码