前面讲过的几种排序算法,选择排序,冒泡排序,插入排序,希尔排序,这些排序可以归为一类(算法实现请移步这里).
因为他们是逐个元素依次比较和交换,其中插入排序对于有序元素有一定的优势,希尔排序是制造比较优势.这些排序算法都是内外循环的方式,一直到数据结束.
而归并排序使用递归的方式,将数组分成无数个小的子数组,对子数组进行排序,然后依次将他们归并起来,从而达到对整个数组排序的目的.
将两个有序的数组归并起来,从而组成更大的有序数组.从这个概念衍生出来的递归排序思想:归并排序.要将一个数组排序,可以递归的将这个数组的分成两半,直道他们在最小单位内变成有序时(通常最小单位为1),将数组合并起来.
总体的流程可以用下面的图来理解 地址:

- 先将左半边数组进行排序,
- 再将右半边元素进行排序,
- 最后将左边和右边的有序数组进行合并结果
看上面的图,我们很容易的想到,我们需要三个数组,左半边有序数组,右半边有序数组,然后将左右两半数组合并到一个更大的有序数组中去,但上面的图只是显示了一个抽象的流程.实际中我们需要很多次归并,所以需要更多的数组,这显然会创建大量的数组,为了避免这种情况,我们可以一次性的分配和原数组大小相等的另外一个辅助数组.在合并的时候,先把原数组拷贝到辅助数组,然后利用辅助数组进行合并. 合并的方法为
merge(int[] a, int low, int mid, int height)
通过merge 方法,有效的将a[low]...a[mid]之间的元素和 a[mid+1]...a[height]归并成一个有序数组,并存放在a[low]...a[height]中,其中归并的过程中,会将原数组拷贝到辅助数组中,然后利用辅助数组,进行排序后,将结果归并到原数组:
private static void merge(int[] a, int low, int mid, int height) {
int i = low;
int j = mid + 1;
//copy the a to auxiliary
for (int k = low; k <= height; k++) {
auxiliary[k] = a[k];
}
//merge left and right
for (int k = low; k <= height; k++) {
if (i > mid) {
a[k] = auxiliary[j++];
} else if (j > height) {
a[k] = auxiliary[i++];
} else if (a[i] >= a[j]) {
a[k] = auxiliary[j++];
} else {
a[k] = auxiliary[i++];
}
}
}
这个方法的简单描述为:
先将原数组元素从low...height范围拷贝到auxiliary(auxiliary是一次性分配的),然后利用下面四个规则将左右两边的数组元素进行重新排序:
如果左半边元素用尽(i>mid),则使用右半边的元素.
如果有右半边的元素用尽(j>height),则使用左半边的元素.
如果左半边的当前元素比右半边的当前元素小,则使用左半边的当前元素.
如果右半边的当前元素比坐半边的当前元素小,则使用右半边的当前元素.
而且每次选定了元素,不管是左边(i++)还是右边(j++),索引都会增加,i,j分别代表两个数组中的元素的索引,大家可以仔细想象下,排序过程中,他们的位置依次增加,向后移动查找元素的模拟场景
为了加深理解理解,看看下面这幅图:
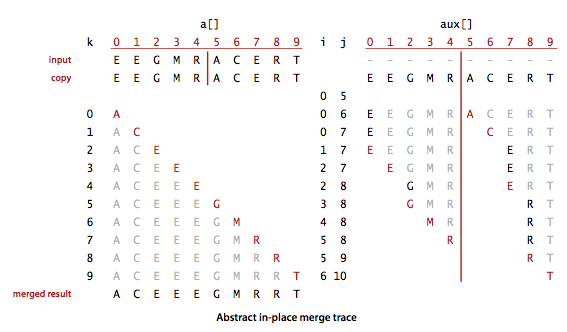
根据上面我描述的过程,可以看到,排序过程中不断的在aus[0]...a[4]和 a[5]...a[9]之间比较元素大小,总是将a[i](左半边数组)和a[j](右半边数组)之间的较小元素重新摆放在a[k]的位置上,直到数组结束
归并排序的思路就是,如果能将两个子数组排序,就能递归的将两个子数组排序归并成一个更大的有序数组.
现在给出递归排序算法的一个实现:
static int[] nums = new int[]{
1, 15, 3, 78,
34, 23, 46, 2,
8, 34, 57, 50,
200, 123, 66, 43,
33, 100, 356, 21};
static int[] auxiliary = new int[nums.length];
public static void main(String[] args) {
System.out.println("before Merge sort " + Arrays.toString(nums));
// topToBottomSort(nums, 0, nums.length - 1);
bottomToTopSort(nums);
System.out.println("after Merge sort " + Arrays.toString(nums));
}
public static void topToBottomSort(int[] nums, int low, int height) {
if (low >= height) return;
int mid = low + (height - low) / 2;
topToBottomSort(nums, low, mid);// sort left
topToBottomSort(nums, mid + 1, height);//sort right
merge(nums, low, mid, height); // merge left and right
}
看方法名称topToBottomSort,叫自顶向下排序,从方法实现上来看,排序时总是先将数组分成更小的数组排序,总是将a[low]....a[height]分成 a[low]....a[mid]和 a[mid+1].....a[height],递归地将他们进行排序,最后通过merge将他们归并成最终的结果
归并的过程为:


上面两幅图是归并排序的轨迹图,可以看出,
要将a[0]...a[15]排序,先要对a[0]...a[7]排序,
要对a[0]....a[7]排序,要先对a[0]...a[3]排序,
要对a[0]...a[3]排序,要先对a[0]...a[1]排序,
要对a[0]...a[1]排序,要先对a[0]和a[1]进行排序,这个时候,a[0],a[1]已经不能再分隔,作为单个元素来看,他们已经长度为1的有序数组,可以直接进行合并
a[0]和a[1]归并后,紧接着就是a[2]和a[3]合并,然后是a[4]...a[7]的排序,同理也是一样的排序流程,将他们递归的分割到只有一个元素的数组时,就可以开始归并排序,和上面的流程是一样的,依次类推,最后归并到a[0]...a[15]
这种递归排序方式化整为零,递归的将排序行为分成更小数组的排序行为,最后通过很多极小的数组的排序结果归并成更大数组,从而实现对整个数组的排序.这是"分治思想"在排序算法上的经典应用.我们将要解决的问题分成许多个小问题的解,然后将小问题的所有解组合起来,最终就构成这个问题的解.
还有另外一个排序思路,就是与上面的过程完全反过来,叫自底向上排序.
就是先向这个数组分成很多个极小的数组(长度为1),然后先两两合并,再四四合并,载八八合并.....直道数组结束.
排序的实现为:
public static void bottomToTopSort(int[] nums) {
final int N = nums.length;
for (int size = 1; size < N; size = size + size) {//the size is length of sub array
for (int low = 0; low < N - size; low += size + size) {
merge(nums, low, low + size - 1, Math.min(low + size + size - 1, N - 1));
}
}
}
private static void merge(int[] a, int low, int mid, int height) {
int i = low;
int j = mid + 1;
//copy the a to auxiliary
for (int k = low; k <= height; k++) {
auxiliary[k] = a[k];
}
//merge left and right
for (int k = low; k <= height; k++) {
if (i > mid) {
a[k] = auxiliary[j++];
} else if (j > height) {
a[k] = auxiliary[i++];
} else if (a[i] >= a[j]) {
a[k] = auxiliary[j++];
} else {
a[k] = auxiliary[i++];
}
}
}
用下面这幅图来加深排序过程的理解:

先分成长度为1的子数组,两两合并,然后将size 加倍,也就是四四合并,然后再加倍,八八合并,直到数组结束!
前面我们做过实际的 算法|算法性能实测(选择|插入|希尔) ,其中希尔排序是性能最好的,排序 100w随机数据的时间为193ms.
现在将数组规模再扩大16倍时(千万级别),16777216 (1<<24) 个时,排序的时间为: 4663ms,
而归并排序算法在这个数据规模上的排序时间为:1425ms,又快了2倍不止.
下一篇会接着介绍,快速排序,与归并排序的排序思想类似,也是"分治思想"的经典应用之一.
快速排序的排序性能某些时候比归并排序还要快,非常值得学习!
算法实现请移步这里
下一篇:快速排序