参考文章:https://arxiv.org/abs/2210.00379
1. 概述
神经辐射场(NeRF)模型是一种新视图合成方法,它使用体积网格渲染,通过MLP进行隐式神经场景表达,以学习3D场景的几何和照明。
应用:照片编辑、3D表明提取、人体建模、3D表达和视图合成等。
特点:模型自监督。对于一个场景,只需要多视图图像及其姿态,而无需3D或深度监督。
2. NeRF模型
NeRF模型将3D场景表达为用神经网络表示的辐射场。辐射场描述了各点在各视角下的颜色和密度。即 F ( x , θ , ϕ ) → ( c , σ ) F(x,\theta,\phi)\rightarrow(c,\sigma) F(x,θ,ϕ)→(c,σ)其中 x x x为点的3D坐标, ( θ , ϕ ) (\theta,\phi) (θ,ϕ)为视线的水平角与俯仰角, c c c表示颜色, σ \sigma σ表示体积网格密度。该函数使用MLP(记为 F Θ F_\Theta FΘ)进行近似。 ( θ , ϕ ) (\theta,\phi) (θ,ϕ)也可表达为3维的单位方向向量 d d d。
该表达需要满足多视图一致性,即 σ \sigma σ(场景的内容)与视角无关,而 c c c与坐标和视角均相关。通常来说,会设计两个MLP,第一个MLP输入 x x x,输出 σ \sigma σ与高维特征向量 h h h: σ , h = σ-MLP ( x ) \sigma,h=\text{σ-MLP}(x) σ,h=σ-MLP(x)高维特征向量 h h h与视线方向 d d d拼接后输入第二个MLP得到 c c c: c = c-MLP ( [ h ; d ] ) c=\text{c-MLP}([h;d]) c=c-MLP([h;d])由于密度和颜色都完全被MLP表达,因此这种方法被称为隐式场景表达。
3. 新视图合成
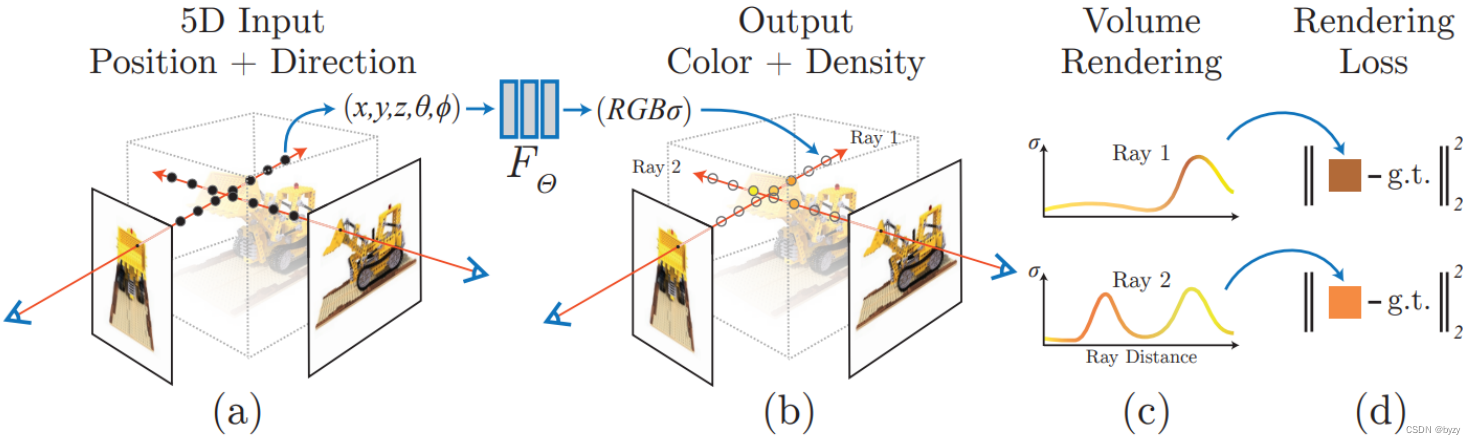
- 对于待合成图像的每个像素,使用相机射线穿过场景并生成采样点(上图(a))。
- 对每个采样点,使用射线方向和采样位置,输入NeRF MLP计算局部颜色与密度(上图(a)与(b)之间的连接处)。
- 使用体积网格渲染,从采样点的色彩和密度生成图像。
4. 体积网格渲染
设相机射线为 r ( t ) = o + t d r(t)=o+td r(t)=o+td,其中 o o o为相机位置, d d d为射线方向。则可按下式得到色彩 C ( r ) C(r) C(r): C ( r ) = ∫ t 1 t 2 T ( t ) ⋅ σ ( r ( t ) ) ⋅ c ( r ( t ) , d ) ⋅ d t C(r)=\int_{t_1}^{t_2}T(t)\cdot\sigma(r(t))\cdot c(r(t),d)\cdot dt C(r)=∫t1t2T(t)⋅σ(r(t))⋅c(r(t),d)⋅dt其中 σ ( r ( t ) ) \sigma(r(t)) σ(r(t))和 c ( r ( t ) , d ) c(r(t),d) c(r(t),d)为射线 r ( t ) r(t) r(t)处的体积网格密度和颜色。
T ( t ) T(t) T(t)为累积透明度,表示射线从 t 1 t_1 t1到 t t t不被拦截的概率: T ( t ) = exp ( − ∫ t 1 t σ ( r ( u ) ) ⋅ d u ) T(t)=\exp\left(-\int_{t_1}^t\sigma(r(u))\cdot du\right) T(t)=exp(−∫t1tσ(r(u))⋅du) 通过追踪待合成图像的像素对应的相机射线,可计算积分。但是通常会通过分层抽样法来计算其近似值。具体来说,射线会被分为等长的 N N N段,然后在各段内均匀抽样一个点,并用求和近似上面的积分: C ^ ( r ) = ∑ i = 1 N α i T i c i , 其中 T i = exp ( − ∑ j = 1 i − 1 σ j δ j ) \hat{C}(r)=\sum_{i=1}^N\alpha_iT_ic_i,其中T_i=\exp\left(-\sum_{j=1}^{i-1}\sigma_j\delta_j\right) C^(r)=i=1∑NαiTici,其中Ti=exp(−j=1∑i−1σjδj)其中 δ i \delta_i δi为采样点 i i i与 i + 1 i+1 i+1的距离; ( σ i , c i ) (\sigma_i,c_i) (σi,ci)为射线上采样点 i i i的密度和颜色(使用NeRF MLP计算)。 α i \alpha_i αi为采样点 i i i处alpha合成的透明度/不透明度: α i = 1 − exp ( σ i δ i ) \alpha_i=1-\exp(\sigma_i\delta_i) αi=1−exp(σiδi)
5. 期望深度计算
期望的深度可使用积累透明度沿射线计算: d ( r ) = ∫ t 1 t 2 T ( t ) ⋅ σ ( r ( t ) ) ⋅ t ⋅ d t d(r)=\int_{t_1}^{t_2}T(t)\cdot\sigma(r(t))\cdot t\cdot dt d(r)=∫t1t2T(t)⋅σ(r(t))⋅t⋅dt上式同样可使用求和近似: D ^ ( r ) = ∑ i = 1 N α i t i T i \hat{D}(r)=\sum_{i=1}^N\alpha_it_iT_i D^(r)=i=1∑NαitiTi某些深度正则化方法会使用期望深度将密度限制为类似(在场景表面取峰值的)delta函数的形式,或是保证深度的平滑性。
6. 损失函数
对每个像素,考虑其平方误差光度损失,以优化MLP参数。总损失为: L = ∑ r ∈ R ∥ C ^ ( r ) − C g t ( r ) ∥ 2 2 L=\sum_{r\in R}\|\hat{C}(r)-C_{gt}(r)\|_2^2 L=r∈R∑∥C^(r)−Cgt(r)∥22其中 C g t ( r ) C_{gt}(r) Cgt(r)是与射线 r r r关联像素的真实颜色, R R R是待合成图像的相机射线集合。
7. 位置编码
NeRF模型通常会使用位置编码,因其有利于渲染图像的细节重建。原始的位置编码 γ \gamma γ是在点 x x x的坐标(归一化到 [ − 1 , 1 ] [-1,1] [−1,1])以及射线单位方向向量 d d d的每个分量 v v v上进行的: γ ( v ) = ( sin ( 2 0 π v ) , cos ( 2 0 π v ) , sin ( 2 1 π v ) , cos ( 2 1 π v ) , ⋯ , sin ( 2 N − 1 π v ) , cos ( 2 N − 1 π v ) ) \gamma(v)=(\sin(2^0\pi v),\cos(2^0\pi v),\sin(2^1\pi v),\cos(2^1\pi v),\cdots,\sin(2^{N-1}\pi v),\cos(2^{N-1}\pi v)) γ(v)=(sin(20πv),cos(20πv),sin(21πv),cos(21πv),⋯,sin(2N−1πv),cos(2N−1πv))其中 N N N为用户定义的维度参数。