目录
开发环境
作者:嘟粥yyds
时间:2023年7月9日
集成开发工具:PyCharm Professional 2021.1
集成开发环境:Python 3.10.6
第三方库:random、time、timeit、functools和heapq
概念
贪心算法(Greedy algorithm)是一种常用的算法策略,用于在求解最优化问题时做出局部最优选择。贪心算法的基本思想是每次都选择当前最优的解决方案,而不考虑整体的最优解。虽然贪心算法不能保证对所有问题都能找到全局最优解,但它在许多问题上表现良好,并且具有高效的计算速度。
基本步骤
贪心算法的一般步骤如下:
1. 确定问题的最优解性质:首先,需要确定问题的最优子结构性质。这意味着通过局部最优解可以推导出全局最优解。这是贪心算法的基础,因为贪心策略的核心是每一步都选择当前最优解。
2. 构建贪心选择:在每一步中,根据某种准则选择当前最优解。这个选择是局部最优的,即在当前状态下看起来是最好的。
3. 解决子问题:经过选择后,将原问题转化为一个更小的子问题。通常,这个子问题是原问题的约束条件限制下的一个子集。
4. 迭代步骤 2 和步骤 3:重复执行步骤 2 和步骤 3,直到得到问题的完整解。
虽然贪心算法可以在某些问题上找到最优解,但是它并不适用于所有问题。在某些情况下,贪心算法会产生次优解甚至不可行的解。因此,在使用贪心算法时,需要经过仔细分析问题的特点,确保贪心选择的可行性和最优性。
选择策略
贪心算法的原理是通过局部最优来达到全局最优,采用的是逐步构造最优解的方法。在每个阶段,都做出一个看上去最优的,决策一旦做出,就不再更改。
要选出最优解可不是一件容易的事,要证明局部最优为全局最优,要进行数学证明,否则就不能说明为全局最优。而改证明往往是及其复杂的,故本文在证明方面并无篇幅。
贪心算法是一个广泛应用的算法策略,它在许多问题上具有简单、高效和近似最优的特点。但需要注意的是,贪心算法并不适用于所有问题,并且对问题的分析和理解至关重要,以确保贪心选择的有效性和正确性。
实际应用
本文所有例题(N皇后问题除外)均采用对数器对贪心算法的结果进行验证选取的贪心策略是否正确,并对比了贪心算法求解和暴力排列求解的运行时间。
1. 会议安排
问题描述:一些项目要占用一个会议室宣讲,会议室不能同时容纳两个项目的宣讲。给你每一个项目开始的时间和结束的时间(给你一个数组,里面是一个个具体的项目),你来安排宣讲的日程,要求会议室进行的宣讲的场次最多。返回这个最多的宣讲场次。 贪心策略:根据结束时间进行排序,依次安排宣讲场次。
代码实现
import random
import timeit
def schedule_meetings(projects):
"""
对于问题:一些项目要占用一个会议室宣讲,会议室不能同时容纳两个项目的宣讲。给你每一个项目开始的时间和结束的时间
(给你一个数组,里面是一个个具体的项目),你来安排宣讲的日程,要求会议室进行的宣讲的场次最多。返回这个最多的宣讲场次。
贪心策略:根据结束时间进行排序,依次安排宣讲场次。
:type projects: List[List[int]]
"""
if not projects:
return []
sorted_projects = sorted(projects, key=lambda x: x[1])
count = 1
curr_end_time = sorted_projects[0][1]
result = [sorted_projects[0]]
for i in range(1, len(sorted_projects)):
start_time, end_time = sorted_projects[i]
if start_time >= curr_end_time:
count += 1
curr_end_time = end_time
result.append(sorted_projects[i])
return result
def schedule_meetings_brute_force(projects):
"""
暴力求解,用于对数器验证贪心算法的正确性
"""
if not projects:
return []
max_count = 0
max_result = []
def backtrack(curr_result, curr_index):
nonlocal max_count, max_result
# 当前结果的项目数量大于最大数量时更新最大数量和最大结果
if len(curr_result) > max_count:
max_count = len(curr_result)
max_result = curr_result[:]
# 从当前索引开始尝试添加项目
for i in range(curr_index, len(projects)):
curr_project = projects[i]
can_add = True
# 检查当前项目与已安排的项目是否有时间冲突
for scheduled_project in curr_result:
if curr_project[0] < scheduled_project[1] and curr_project[1] > scheduled_project[0]:
can_add = False
break
# 如果没有时间冲突,将当前项目添加到结果中,并继续向下回溯
if can_add:
curr_result.append(curr_project)
backtrack(curr_result, i + 1)
curr_result.pop()
backtrack([], 0)
return max_result
def generate_test_input():
# 生成随机测试输入
n = random.randint(5, 10) # 项目数量
projects = []
for _ in range(n):
start_time = random.randint(1, 10)
end_time = random.randint(start_time + 1, 15)
projects.append((start_time, end_time))
return projects
def run_test():
projects = generate_test_input()
print("测试输入:", projects)
# 计算算法1的执行时间,number是执行次数
time1 = timeit.timeit(lambda: schedule_meetings(projects), number=1)
# 计算算法2的执行时间
time2 = timeit.timeit(lambda: schedule_meetings_brute_force(projects), number=1)
result1 = schedule_meetings(projects)
result2 = schedule_meetings_brute_force(projects)
if len(result1) == len(result2):
print("算法输出结果一致:", result1)
# 输出算法执行时间
print("贪心算法执行时间:", time1, "秒")
print("暴力求解算法执行时间:", time2, "秒")
else:
print("算法输出结果不一致:")
print("算法1输出结果:", result1)
print("算法2输出结果:", result2)
# 运行对数器测试
run_test()
运行结果
测试输入: [(10, 11), (3, 11), (10, 15), (5, 13), (9, 14), (1, 8), (9, 14), (6, 12), (8, 14)]
算法输出结果一致: [(1, 8), (10, 11)]
贪心算法执行时间: 5.500005499925464e-06 秒
暴力求解算法执行时间: 1.9899998733308166e-05 秒2. 构造字典序最小的字符串
问题描述:给定若干个字符串,将字符串进行拼接,要求拼接后的字符串字典序最小。例如字符串s1='b'和字符串s2='ba'拼接后的最小字典序字符串为s3='bab'。
贪心策略:定义比较规则,当s1+s2 < s2+s1时,s1放在s2前面,否则s2放在s1前。
代码实现
import timeit
import random
from functools import cmp_to_key
def smallest_concatenation(strings):
"""
对于问题:拼接字符串,要求拼接后的字符串字典序最小
贪心策略:定义比较规则,当s1+s2 < s2+s1时,s1放在s2前面,否则s2放在s1前
"""
# 比较函数,用于确定字符串在排序时的顺序
def compare(s1, s2):
if s1 + s2 < s2 + s1:
return -1
elif s1 + s2 > s2 + s1:
return 1
else:
return 0
# 将字符串列表按照 compare 函数进行排序
sorted_strings = sorted(strings, key=cmp_to_key(compare))
# 拼接排序后的字符串
result = ''.join(sorted_strings)
return result
def smallest_concatenation_brute_force(strings):
"""
暴力排列求解法,用于验证贪心算法的正确性
"""
def permute(nums, curr_permutation, visited, all_permutations):
if len(curr_permutation) == len(nums):
all_permutations.append(''.join(curr_permutation))
return
for i in range(len(nums)):
if not visited[i]:
visited[i] = True
curr_permutation.append(nums[i])
permute(nums, curr_permutation, visited, all_permutations)
curr_permutation.pop()
visited[i] = False
all_permutations = []
visited = [False] * len(strings)
permute(strings, [], visited, all_permutations)
min_concatenation = min(all_permutations)
return min_concatenation
def generate_test_input():
n = random.randint(5, 10) # 字符串数量
strings = []
for _ in range(n):
string_length = random.randint(1, 5)
string = ''.join(random.choices('abcdefghijklmnopqrstuvwxyz', k=string_length))
strings.append(string)
return strings
def run_test():
strings = generate_test_input()
print("测试输入:", strings)
# 计算算法1的执行时间,number是执行次数
time1 = timeit.timeit(lambda: smallest_concatenation(strings), number=1)
# 计算算法2的执行时间
time2 = timeit.timeit(lambda: smallest_concatenation_brute_force(strings), number=1)
result_greedy = smallest_concatenation(strings)
result_brute_force = smallest_concatenation_brute_force(strings)
print("贪心算法拼接结果:", result_greedy)
print("暴力排列算法拼接结果:", result_brute_force)
if result_greedy == result_brute_force:
print("贪心算法和暴力排列算法的结果一致")
else:
print("贪心算法和暴力排列算法的结果不一致")
print("贪心算法执行时间:", time1, "秒")
print("暴力排列算法执行时间:", time2, "秒")
# 运行对数器测试
run_test()运行结果
测试输入: ['tuh', 'xmvqb', 'fk', 'go', 'paga', 'hkrcx']
贪心算法拼接结果: fkgohkrcxpagatuhxmvqb
暴力排列算法拼接结果: fkgohkrcxpagatuhxmvqb
贪心算法和暴力排列算法的结果一致
贪心算法执行时间: 7.099995855242014e-06 秒
暴力排列算法执行时间: 0.00093120000383351 秒3. 分金条(哈夫曼编码)
问题描述:一块金条切成两半,是需要花费和长度数值一样的铜板的。比如长度为20的金条,不管切成长度多大的两半,都要花费20个铜板。 一群人想整分整块金条,怎么分最省铜板? 例如,给定数组{10,20,30},代表一共三个人,整块金条长度为10+20+30=60。金条要分成10,20,30三个部分。如果先把长度60的金条分成10和50,花费60;再把长度50的金条分成20和30,花费50;一共花费110铜板。 但是如果先把长度60的金条分成30和30,花费60;再把长度30金条分成10和20,花费30;一共花费90铜板。 输入一个数组,返回分割的最小代价。
贪心策略:每次选择代价最小的两块金条进行合并,直到最终只剩下一块金条。
代码实现
import random
import time
def min_cost_split(gold_lengths):
total_cost = 0
while len(gold_lengths) > 1:
# 找到长度最小的两块金条
min1_idx = gold_lengths.index(min(gold_lengths))
min1 = gold_lengths.pop(min1_idx)
min2_idx = gold_lengths.index(min(gold_lengths))
min2 = gold_lengths.pop(min2_idx)
# 合并两块金条的长度,并计算代价
merged_length = min1 + min2
total_cost += merged_length
# 将合并后的金条长度加入列表中
gold_lengths.append(merged_length)
return total_cost
def brute_force_min_cost_split(gold_lengths):
def split_gold(lengths, total_cost):
if len(lengths) == 1:
return total_cost
min_cost = float('inf')
for i in range(len(lengths) - 1):
for j in range(i + 1, len(lengths)):
new_lengths = lengths[:i] + [lengths[i] + lengths[j]] + lengths[i + 1:j] + lengths[j + 1:]
cost = split_gold(new_lengths, total_cost + lengths[i] + lengths[j])
min_cost = min(min_cost, cost)
return min_cost
return split_gold(gold_lengths, 0)
def generate_test_input():
n = random.randint(3, 8) # 金条数量
gold_lengths = [random.randint(10, 80) for _ in range(n)]
return gold_lengths
def run_test():
gold_lengths = generate_test_input()
gold_lengths1 = gold_lengths.copy()
print("测试输入:", gold_lengths)
start_time = time.perf_counter()
result_greedy = min_cost_split(gold_lengths)
end_time = time.perf_counter()
time_greedy = end_time - start_time
start_time = time.perf_counter()
result_brute_force = brute_force_min_cost_split(gold_lengths1)
end_time = time.perf_counter()
time_brute_force = end_time - start_time
print("贪心算法最小代价:", result_greedy)
print("暴力排列算法最小代价:", result_brute_force)
if result_greedy == result_brute_force:
print("贪心算法和暴力排列算法的结果一致")
else:
print("贪心算法和暴力排列算法的结果不一致")
print("贪心算法执行时间:", time_greedy, "秒")
print("暴力排列算法执行时间:", time_brute_force, "秒")
# 运行对数器测试
run_test()运行结果
测试输入: [14, 15, 15, 46, 17, 52, 37, 80]
贪心算法最小代价: 757
暴力排列算法最小代价: 757
贪心算法和暴力排列算法的结果一致
贪心算法执行时间: 8.39999847812578e-06 秒
暴力排列算法执行时间: 3.426389200001722 秒4. 背包问题
问题描述:在启动资金为m、一次最多能同时做k个项目的情况下,求最大的收益.。其中,每做完一个项目,马上就能获得收益并支持你去做下一个项目。
贪心策略:对项目按照利润进行降序排序,然后依次选择利润最大的项目进行执行
代码实现
import random
import timeit
def max_profit(costs, profits, k, m):
"""
问题描述:在启动资金为m的,一次最多能同时做k个项目的情况下,求最大的收益.
每做完一个项目,马上就能获得收益并支持你去做下一个项目
:param costs[i]:花费
:param profits[i]:利润
:return:
"""
# 创建项目列表 [(花费, 利润)]
projects = list(zip(costs, profits))
# 根据利润从大到小排序
projects.sort(key=lambda x: -x[1])
# 执行贪心算法
for _ in range(k):
affordable_projects = []
# 找出所有花费在当前资金范围内的项目
for c, p in projects:
if c <= m:
affordable_projects.append((c, p))
if not affordable_projects:
break
# 选择利润最大的项目,更新资金和项目列表
max_profit_project = max(affordable_projects, key=lambda x: x[1])
m += max_profit_project[1]
projects.remove(max_profit_project)
return m
def brute_force_max_profit(costs, profits, k, m):
def backtrack(curr_profit, curr_index, curr_funds):
nonlocal max_profit
if curr_index == len(costs) or curr_profit == k:
max_profit = max(max_profit, curr_funds)
return
# 不选择当前项目
backtrack(curr_profit, curr_index + 1, curr_funds)
# 选择当前项目,更新当前利润和资金
if curr_funds >= costs[curr_index]:
backtrack(curr_profit + 1, curr_index + 1, curr_funds + profits[curr_index])
max_profit = 0
backtrack(0, 0, m)
return max_profit
def generate_test_input():
n = random.randint(5, 10) # 项目数量
k = random.randint(2, 4) # 最多做的项目数
m = random.randint(50, 100) # 初始资金
costs = [random.randint(10, 20) for _ in range(n)] # 花费列表
profits = [random.randint(30, 50) for _ in range(n)] # 利润列表
return costs, profits, k, m
def run_test():
costs, profits, k, m = generate_test_input()
print("测试输入:")
print("costs:", costs)
print("profits:", profits)
print("k:", k)
print("m:", m)
# 计算算法1的执行时间,number是执行次数
time_greedy = timeit.timeit(lambda: max_profit(costs, profits, k, m), number=1)
# 计算算法2的执行时间
time_brute_force = timeit.timeit(lambda: brute_force_max_profit(costs, profits, k, m), number=1)
result_greedy = max_profit(costs, profits, k, m)
result_brute_force = brute_force_max_profit(costs, profits, k, m)
print("贪心算法最大收益:", result_greedy)
print("贪心算法执行时长:", time_greedy, "秒")
print("暴力排列算法最大收益:", result_brute_force)
print("暴力排列算法执行时长:", time_brute_force, "秒")
# 运行对数器测试
run_test()运行结果
测试输入:
costs: [12, 10, 12, 12, 10, 14, 13, 11, 15]
profits: [49, 32, 40, 41, 47, 44, 30, 46, 49]
k: 2
m: 57
贪心算法最大收益: 155
贪心算法执行时长: 1.189999602502212e-05 秒
暴力排列算法最大收益: 155
暴力排列算法执行时长: 2.2799998987466097e-05 秒5. 中位数获取
问题描述:在输入流中能随时获得中位数。
贪心策略:使用两个堆来解决这个问题:一个最大堆和一个最小堆。最大堆用于存储较小的一半元素,最小堆用于存储较大的一半元素。
代码实现
import heapq
class MedianFinder:
def __init__(self):
self.max_heap = [] # 最大堆,存储较小的一半元素
self.min_heap = [] # 最小堆,存储较大的一半元素
def addNum(self, num):
heapq.heappush(self.max_heap, -num) # 最大堆使用相反数存储(因为 Python 的 heapq 模块只提供最小堆的实现)
heapq.heappush(self.min_heap, -heapq.heappop(self.max_heap)) # 平衡两个堆
if len(self.min_heap) > len(self.max_heap):
heapq.heappush(self.max_heap, -heapq.heappop(self.min_heap))
def findMedian(self):
if len(self.max_heap) == len(self.min_heap):
return (-self.max_heap[0] + self.min_heap[0]) / 2
else:
return -self.max_heap[0]
# 测试
medianFinder = MedianFinder()
# stream = [2, 4, 1, 5, 3] # 输入流
stream = [5, 4, 3, 2, 1] # 输入流
for num in stream:
medianFinder.addNum(num)
print("当前中位数:", medianFinder.findMedian(), "\t大根堆为:", medianFinder.max_heap, "\t小根堆为:", medianFinder.min_heap)运行结果
当前中位数: 5 大根堆为: [-5] 小根堆为: []
当前中位数: 4.5 大根堆为: [-4] 小根堆为: [5]
当前中位数: 4 大根堆为: [-4, -3] 小根堆为: [5]
当前中位数: 3.5 大根堆为: [-3, -2] 小根堆为: [4, 5]
当前中位数: 3 大根堆为: [-3, -1, -2] 小根堆为: [4, 5]6. N皇后问题
问题描述:按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。
n 皇后问题 研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
给你一个整数 n ,返回所有不同的 n 皇后问题 的解决方案。
每一种解法包含一个不同的 n 皇后问题 的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
示例:
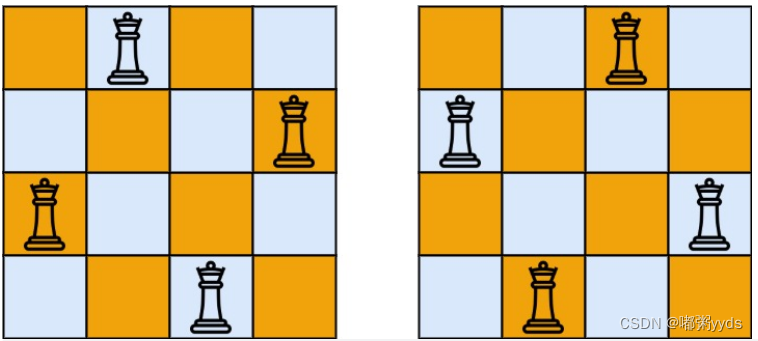
输入:n = 4
输出:[[".Q..","...Q","Q...","..Q."],["..Q.","Q...","...Q",".Q.."]]
解释:如上图所示,4 皇后问题存在两个不同的解法。
代码实现
import time
class Solution1:
def solveNQueens(self, n: int) -> list[list[str]]:
def backtrack(row, cols, diag1, diag2, path):
"""
:param row: 当前行数
:param cols: 存储已放置了皇后的列的索引 通过检查col not in cols确保不同列
:param diag1: 已放置了皇后的主对角线的差值 通过检查(row + col) not in diag1确保不同主对角线
:param diag2: 已放置了皇后的次对角线的差值 通过检查(row - col) not in diag2确保不同次对角线
"""
# 终止条件:当 row 等于 n 时,表示找到了一个有效的解决方案
if row == n:
result.append(path)
return
# 遍历当前行的每个位置
for col in range(n):
# 检查当前位置是否可以放置皇后
if col not in cols and (row + col) not in diag1 and (row - col) not in diag2:
# 更新 cols、diag1 和 diag2
cols.add(col)
diag1.add(row + col)
diag2.add(row - col)
# 递归调用 backtrack 处理下一行
backtrack(row + 1, cols, diag1, diag2, path + [col])
# 回溯:撤销对 cols、diag1 和 diag2 的更新
cols.remove(col)
diag1.remove(row + col)
diag2.remove(row - col)
result = []
backtrack(0, set(), set(), set(), [])
# 将结果转换为题目要求的输出格式
return [['.' * col + 'Q' + '.' * (n - col - 1) for col in path] for path in result]
class Solution2:
def solveNQueens(self, n: int) -> list[list[str]]:
def backtrack(row, cols, diag1, diag2, path):
if row == n:
result.append(path)
return
# 计算可放置皇后的位置,使用位运算
available_pos = ((1 << n) - 1) & (~(cols | diag1 | diag2))
while available_pos:
pos = available_pos & -available_pos # 获取最低位的 1
col = bin(pos - 1).count('1') # 获取该位置所在的列
cols |= pos
diag1 |= pos
diag2 |= pos
backtrack(row + 1, cols, diag1 << 1, diag2 >> 1, path + [col])
cols ^= pos
diag1 ^= pos
diag2 ^= pos
available_pos &= available_pos - 1 # 去除最低位的 1
result = []
backtrack(0, 0, 0, 0, [])
# 将结果转换为题目要求的输出格式
return [['.' * col + 'Q' + '.' * (n - col - 1) for col in path] for path in result]
start_time1 = time.time() * 1000 # 记录开始时间
n1 = Solution1().solveNQueens(14)
end_time1 = time.time() * 1000 # 记录结束时间
execution_time1 = end_time1 - start_time1 # 计算运行时间
print("优化前14皇后问题求解时间:", execution_time1, "毫秒")
print("优化前14皇后问题方案数:", len(n1))
start_time2 = time.time() * 1000 # 记录开始时间
n2 = Solution2().solveNQueens(14)
end_time2 = time.time() * 1000 # 记录结束时间
execution_time2 = end_time2 - start_time2 # 计算运行时间
print("优化后14皇后问题求解时间:", execution_time2, "毫秒")
print("优化后14皇后问题方案数:", len(n2))运行结果
优化前14皇后问题求解时间: 39064.458251953125 毫秒
优化前14皇后问题方案数: 365596
优化后14皇后问题求解时间: 24999.784912109375 毫秒
优化后14皇后问题方案数: 365596本例的优化仅使用位运算降低了常数级别的时间复杂度,若需进一步优化可在剪枝策略和启发式搜索方面完成,本文不做深入,读者若有兴趣可自行探索完成。