《数据挖掘》系列文章目录
第一章 概述
第二章 数据
第三章 数据预处理
第四章 数据仓库和OLAP
第五章 回归分析
第六章 频繁模式
第七章 分类
第八章 聚类
第九章 离群点检测
第一章 概述
单选题
- 下列属于数据挖掘任务的是( )
A 根据性别划分公司的顾客
B 计算公司的总销售额
C 预测一对骰子的结果
D 利用历史记录预测公司的未来股价 - 下述四种方法哪一种不是常见的分类方法( )
A 决策树
B 支持向量
C K-Means
D 朴素贝叶斯分类 - 将原始数据进行集成、变换、维度规约、数值规约是哪个步骤的任务( )
A 频繁模式挖掘
B 分类和预测
C 数据预处理
D 数据流挖掘 - KDD是( )
A 数据挖掘与知识发现
B 领域知识发现
C 文档知识发现
D 动态知识发现 - 下列有关离群点的分析错误的是( )
A 一般情况下离群点会被当作噪声而丢弃
B 离群点即是噪声数据
C 在某些特殊应用中离群点有特殊的意义
D 信用卡在不常消费地区突然消费大量金额的现象属于离群点分析范畴 - 可以在不同维度合并数据,从而形成数据立方体的是( )
A 数据库
B 数据源
C 数据仓库
D 数据库系统 - 目的是缩小数据的取值范围,使其更适合于数据挖掘算法的需要,并且能够得到和原始数据相同的分析结果的是( )
A 数据清洗
B 数据集成
C 数据变换
D 数据归约 - 下列任务中,属于数据挖掘技术在商务智能方面应用的是( )
A 欺诈检测
B 垃圾邮件识别
C 根据因特网的搜索引擎查找特定的Web页面
D 定向营销 - 异常检测的应用包括( )
A 网络攻击
B 预测某股票的未来价格
C 计算公司的总销售额
D 根据性别划分公司顾客 - 下列关于模式识别的相关说法中错误的是( )
A 模式识别的本质是抽象出不同事物中的模式并由此对事物进行分类
B 医疗诊断属于模式识别的研究内容之一
C 手机的指纹解锁技术不属于模式识别的应用
D 自然语言理解也包含模式识别问题" - 目前数据分析和数据挖掘面临的挑战性问题不包括( )
A 数据类型的多样化
B 高维度数据
C 离群点数据
D 分析与挖掘结果可视化
判断题
- 无监督学习可以在没有标记的数据集上进行学习。✓
- 聚类就是把一些对象划分为多个组或者聚簇,从而使同组内对象间比较相似而不同组对象间差异较大。✓
- 事务数据库的每个记录代表一个事务。✓
- 数据仓库和数据库其实是相同的,都是数据或信息的存储系统。✗
- 离群点因偏离一般水平而不需要考虑和研究。✗
- 数据挖掘的主要任务是从数据中发现潜在的规则,从而能更好的完成描述数据、预测数据等任务。✓
- 数据仓库一般存储在线交易数据,数据库存储的一般是历史数据。✗
- 数据库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。✗
- 常见的机器学习方法有监督学习、无监督学习、和半监督学习。✓
- 频繁模式是指在数据集中频繁出现的模式。✓
- 离群点是指全局或局部范围内偏离一般水平的观测对象。✓
- 回归是通过建立模型预测离散的标签,而分类则是通过建立连续值模型推断新的数据的某个数值型属性。✗
- 数据库是面向主题的设计,数据仓库是面向事务设计的。✗
- 区分是将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比较。✓
- 聚类过程的输入对象有与之关联的目标信息。✗
- 数据挖掘的目标不在于数据采集策略,而在于对于已经存在的数据进行模式的发掘。✓
- 数据分析是指采用适当的统计分析方法对收集到的数据进行分析、概括和总结,对数据进行恰当的描述,并提取出有用的信息的过程。✓
- 数据分析的定义:数据分析就是对数据进行分析。专业的说法,数据分析是指根据分析目的,用适当的统计分析方法及工具,对收集来的数据进行处理与分析,提取有价值的信息,发挥数据的作用。✓
- 从大规模的数据中抽取或挖掘出感兴趣的知识或模式的过程或方法叫做数据挖掘。✓
- 数据挖掘主要侧重解决四类问题:分类、聚类、关联和预测。✓
- 数据分析是指采用适当的统计分析方法对收集到的数据进行分析、概括和总结。✓
- 数据仓库系统的主要应用是联机分析处理。✓
解析
判断12
回归是通过建立模型预测离散的标签,而分类则是通过建立连续值模型推断新的数据的某个数值型属性。✗
分类是通过建立模型预测离散的标签,回归是通过建立连续值模型推断新的数据的某个数值型属性。
思考总结
关于数据分析和数据挖掘——认识
- 谈谈你对数据分析和数据挖掘简要的认识?
- 列举还有哪些数据分析和数据挖掘在实际生活和科研工作中的应用。
在我看来,数据挖掘与数据分析最大的不同有两点,第一个是数据挖掘比数据分析处理的数据量级要大,第二个数据挖掘在处理数据前没有明确的目的与需求,而数据分析是有的。综合起来,数据分析与数据挖掘的本质都是一样的,都是从数据里面发现有价值的信息,从而帮助人类做更好的决策,两个也都是现在大数据时代重要的工具,都需要重视。
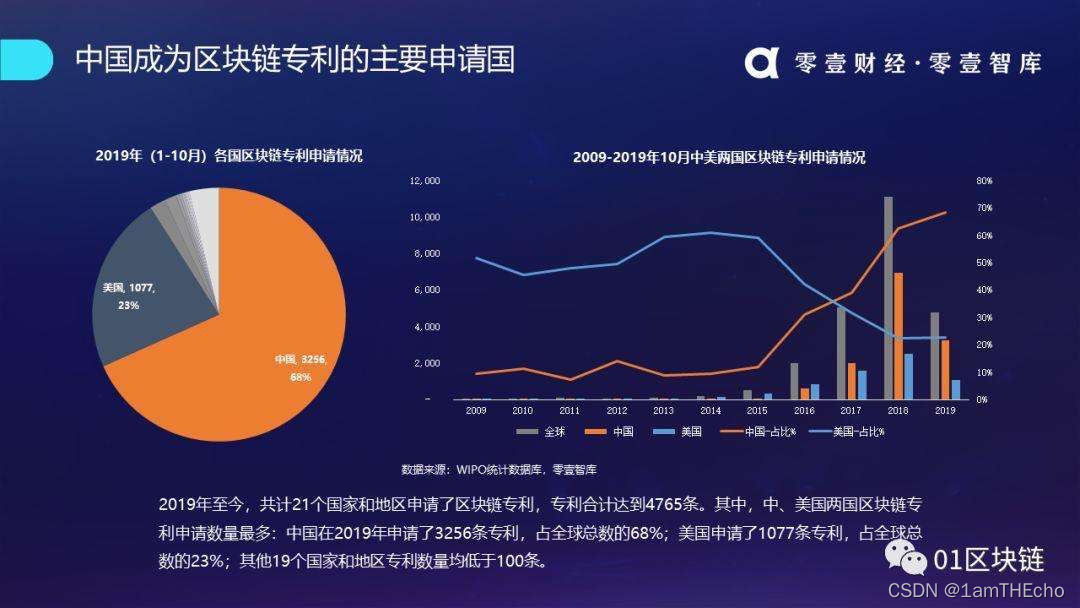
在实际生活中,数据分析给我们带来了很多规律,从而更好地规避风险。科研中,数据分析和数据挖掘更是我们摘取科研果实的不二手段。如图所示,我的研究方向——区块链正式应用了很多数据分析与数据挖掘的方法,才能对当前区块链的一些趋势进行信息统计。
关于数据分析和数据挖掘——技术
- 结合自己的科研经历,谈谈你对数据挖掘与数据分析中常用技术的理解?
- 数据挖掘中存在哪些具有挑战性的问题?对此你有什么看法?
我的科研方向是区块链,区块链和数据挖掘与数据分析相结合具有重要的社会价值和经济价值,也是区块链科学研究的重要领域。以BlockSci区块链数据分析框架为例,图中所示为使用BlockSci的区块链对象的[]操作符提取 比特币465100#区块内各交易的手续费率并进行相关分析,可能会用到分类,估值,预测,描述和可视化等技术。通过这些技术的分析,可以得知该区块内绝大多数交易的手续费率设置在500SAT/BYTE以内这个结果。

数据挖掘当前具有挑战性的问题我觉得是隐私保护。在解决实际问题时,难免会涉及隐私的数据,例如在研究信用卡和用户之间的关系时,数据中难免会有用户的个人信息;在研究宫颈癌(危险因素)与人的年龄、怀孕次数、伴侣数等关系时,会有部分隐私信息不便透漏外界。在进行数据挖掘过程中,不泄露用户的个人隐私问题,对数据进行脱敏处理,将成为人们研究数据挖掘的一个重要方面。
注:答案仅供参考,思考总结为01的个人想法。