8.1 个体与集成
集成学习就是把多个学习器结合起来。一般这种结合比单一学习器泛化性能更优良。
不是说集成一定比单一的好,如果想获得好的集成,个体学习器应“好而不同”。
假设基学习器的误差独立,则可推出集成的错误随着分类器数目增大而指数级下降。(现实中不可能)
准确性和多样性是矛盾的。
集成学习分类:
序列化方法:个体学习器强依赖关系,串行生成。Boosting
并行化方法:不存在强依赖,同时生成。Bagging和“随机森林”
8.2 Boosting
Boosting族算法代表:AdaBoost。
AdaBoost算法流程:

简单解释:


AdaBoost使用指数损失函数:
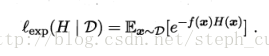
其中H是集成后学习器,f是真实函数。
可以证明:指数损失函数是分类任务原本0/1损失函数的一致的替代损失函数。
注意:每轮训练都会给每个训练样本重新赋权重,这叫“重赋权法”。也可以采用重采样法。重采样法可以获得“重启动”机会以避免训练过程过早结束。
Boosting主要关注降低偏差,因此基于泛化性能很弱的学习器构建很强的集成。
8.3 Bagging与随机森林
核心是每轮训练数据尽量不一样,以满足“集成的个体学习器尽可能独立”的要求。具体做法是采用互相有交叠的采样子集。
并行集成学习代表:Bagging。采用了前面提过的自助采样法。(初始训练集中约有63.2%的样本有出现在采样集中)。
对预测输出结合是,分类任务简单投票;回归任务采用简单平均。
Bagging算法流程:
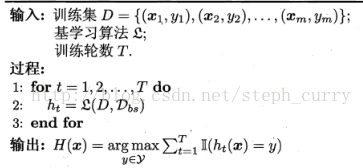
Bagging集成的训练与用基学习算法训练一个学习器的复杂度同阶。且可用于多分类、回归(AdaBoost只能二分类)
(此外,由于自助采样法还有36.8%的数据没用训练,则可以拿来当验证集,“包外估计”)
Bagging主要关注降低方差,因此在不剪枝决策树、神经网络等易受样本扰动的学习器上效用更明显。
随机森林(RF):
是Bagging一个变体(以决策树为基学习器)。核心是决策树训练过程中引入随机属性选择。回想前面决策树算法中国,选择划分属性是在当前结点的属性集合中选择最优属性,
但是在RF中,是先从该结点的属性集合中随机选择一个包含k个属性的子集,再从子集中选择最优属性。k控制了随机性引入程度。一般

可以看到,RF中的随机性来自两部分:样本扰动和属性扰动。
与Bagging相比,RF起始性较差,但最终收敛更低的泛化误差。
8.4结合策略
学习器结合有三大好处:
统计方面;计算方面;表示方面
常见结合策略:
平均法:简单平均法、加权平均法;
投票法:绝对多数投票法、相对所属投票法、加权投票法
学习法:通过学习另一个学习器来结合。Stacking是典型代表。
把个体学习器叫“初级学习器”,用于结合的学习器叫“次级学习器”。
Stacking 算法流程如下:

简单解释:先从初始数据集训练处初级学习器,再生成一个新数据集来训练次级学习器。这个新的数据集这样构成:初级学习器的输出当做样例输入特征,而初始样本的标记仍当做样例标记。
注意,并不是直接用初级学习器的训练集来产生次级训练集,这样过拟合风险大。采用交叉验证或留一法,用初级学习器未使用的样本来产生次级学习器。
8.5 多样性
可以证明这个式子:

其中:
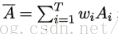
这个式子证明:个体学习器准确率越高,多样性越大,则集成越好。(E是集成的泛化误差)
多样性度量:
两个分类器hi和hj预测结果列联表:

常见多样性度量:
不合度量:
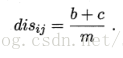
相关系数:

范围是[-1,1]。若二者无关,值为0,正相关为正数……
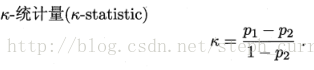
完全一致,k=1。偶然达成一致,k=0.越大多样性越低。
最后总结多样性增强方法:
数据样本扰动;
输入属性扰动;
输出表示扰动;
算法参数扰动