首页
移动开发
物联网
服务端
编程语言
企业开发
数据库
业界资讯
其他
搜索
《强化学习》 DP动态规划
其他
2018-06-22 05:15:55
阅读次数: 3
奖赏设计
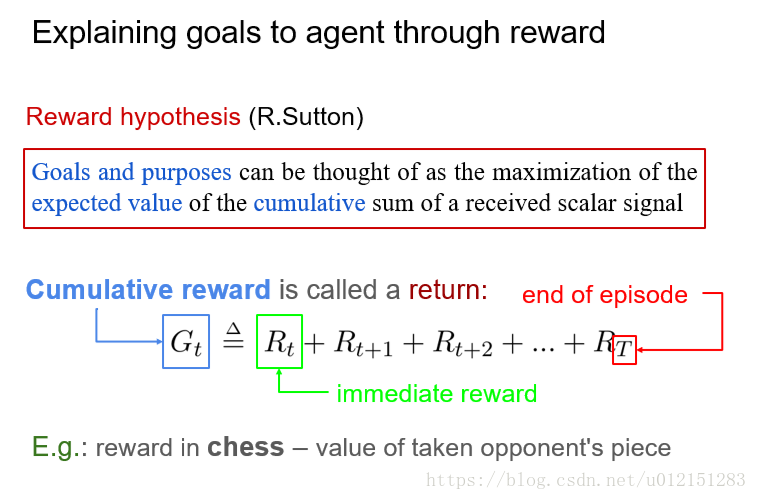
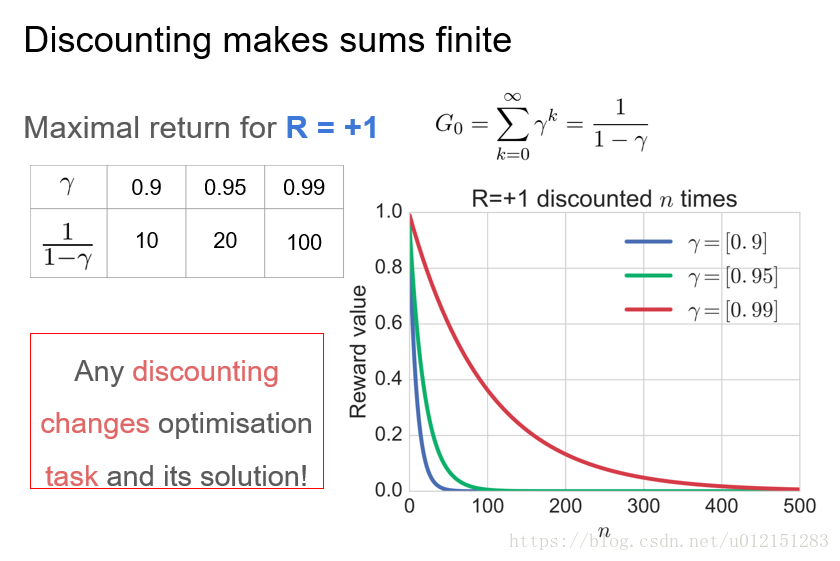
累计奖赏和折扣累计奖赏
数学上看,折扣奖赏机制可以将累计回报转化为递推的形式:
G
t
=
R
t
+
γ
(
R
t
+
1
+
γ
R
t
+
2
+
.
.
.
)
=
R
t
+
γ
G
t
+
1
G
t
=
R
t
+
γ
(
R
t
+
1
+
γ
R
t
+
2
+
.
.
.
)
=
R
t
+
γ
G
t
+
1
折扣是一种固定效应模型
奖赏设计:不要平移,奖励做什么而不是怎么做
奖赏设计:缩放,塑形
贝尔曼等式
状态值函数
值函数的贝尔曼期望等式
动作值函数
两者关系
动作值函数的贝尔曼期望等式
衡量策略优劣
贝尔曼最优等式
广义策略迭代GPI
策略评估
策略改进
GPI
策略迭代
值迭代
对比
猜你喜欢
转载自
blog.csdn.net/u012151283/article/details/80508413
强化学习:动态规划(DP)
《强化学习》 DP动态规划
强化学习(三)用动态规划(DP)求解
【转载】 强化学习(三)用动态规划(DP)求解
强化学习:DP
强化学习系列(四):动态规划
强化学习之动态规划
强化学习 4. 动态规划
强化学习:基于模型的动态规划
2、强化学习--动态规划
强化学习(四):基于表格型动态规划算法的强化学习
强化学习(四)用蒙特卡罗法(MC)求解 强化学习(三)用动态规划(DP)求解 强化学习(二)马尔科夫决策过程(MDP) 强化学习(一)模型基础
【强化学习笔记】3.1 基于模型的动态规划方法
《强化学习Sutton》读书笔记(三)——动态规划
重温强化学习之基于模型方法:动态规划
强化学习基础:基本概念和动态规划
强化学习(三)——动态规划解决MDP
强化学习&动态规划3 | 策略迭代 Policy Iteration
强化学习&动态规划2 | 策略完善 Policy Improvement
【深度强化学习】动态规划(Dynamic Programming)
强化学习系列14:动态规划求解法
强化学习笔记-04 动态规划Dynamic Programming
【强化学习理论】动态规划算法
强化学习笔记二 MDP & DP
强化学习笔记3—DP
强化学习(三):动态编程
【转载】 强化学习(四)用蒙特卡罗法(MC)求解 强化学习(三)用动态规划(DP)求解 强化学习(二)马尔科夫决策过程(MDP)
DP动态规划学习笔记
动态规划的学习-dp之旅
从逆向强化学习到动态规划:DeepMind在决策和规划方面的突破
今日推荐
开源日报 | Chrome内置Gemini的意义不在于Gemini;中国AI追随之路的五大误区;ECharts创始人“下海”养鱼;谷歌I/O开发者大会什么都有,只是没有惊喜
微软回应中国区AI团队“打包赴美”传闻
基于大语言模型的开源知识库问答系统 MaxKB GitHub Star 数量突破 5,000 个!
美国拟限制 AI 大模型出口中国和俄罗斯
苹果将与 OpenAI 达成协议,将 ChatGPT 应用于 iPhone
openKylin 社区生态委员会第六次会议圆满召开
阿里云正式发布通义千问 2.5
Python 3.13 发布首个 Beta:实验性自由线程模式和 JIT、改进交互式解释器
Stack Overflow 拿我的代码去训练 AI 大模型,还封了我的账号
Pop!_OS 的 COSMIC 桌面完成 App Store 上架工作
《2024 年一季度互联网投融资运行情况》研究报告
报告:Django 仍然是 74% 开发者的首选
周排行
返回指定时间格式
fopen函数中的mode参数
Java 单例模式探讨
Flex remoteobject工作原理探讨
寻找mplayer的便捷安装方法
30天了解30种技术系列---(26)MySQL自动化运维工具Inception
关于Jboss/Tomcat/Jetty的JNDI定义123
程序减肥,strip,eu-strip 及其符号表
AsyncTask、View.post(Runnable)、ViewTreeObserver三种方式总结frame animation自动启动
Json和Bean的互相转换
每日归档
更多
2024-05-15(24)
2024-05-14(0)
2024-05-13(18)
2024-05-12(0)
2024-05-11(38)
2024-05-10(38)
2024-05-09(35)
2024-05-08(42)
2024-05-07(14)
2024-05-06(40)