强化学习(四):基于表格型动态规划算法的强化学习

夏栀的博客——王嘉宁的个人网站 正式上线,欢迎访问和关注:http://www.wjn1996.cn
在有限马尔可夫决策过程中,智能体在某个状态进行决策的过程中,始终满足价值函数和动作函数的贝尔曼方程,事实上,这就是一种动态规划的思想。动态规划即是一种递推表达式,例如对于状态价值的贝尔曼方程,其衡量的是当前状态与所有的下一个可能的状态价值的关系,同理,动作价值的贝尔曼方程则是衡量当前状态动作二元组的价值与对应所有可能转移的下一个状态基础上执行所有可能动作的价值的关系。
回想一下在强化学习(一)中,我们介绍了强化学习的相关概念,其中给出了有模型与无模型的概念。基于动态规划的强化学习则是一种基于有模型的方法,具体的讲,只有已知环境中所有的状态以及对应的策略分布、状态转移概率分布,才能应用动态规划。
动态规划的目标是得到当前状态
的价值函数以及当前可采取的最优策略。因为我们已知策略分布
、状态转移
,则可以将所有可能转移的下一个状态
对应的状态价值
一同通过贝尔曼方程更新到
,这既是动态规划的思想。事实上不管是动态规划,还是蒙特卡洛采样,都是这种逆推回溯的思想。
1、策略评估与策略控制
几乎所有的基于表格型的强化学习算法都可以分为策略评估与策略改进两个部分。策略评估是指根据后续的状态价值来更新当前时刻的状态价值,因此不严谨的讲,策略评估即是对状态价值的一种估计,或者说是一种预测。而对于策略控制,则是根据当前评估的结果,贪心的选择认为最好的策略。如下图所示:
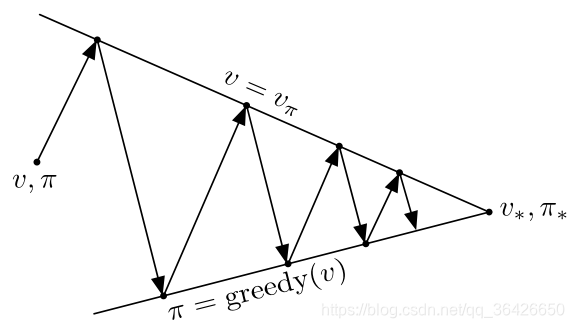
策略评估与策略改进是一对相互约束又相互促进的两个“进程”,策略评估的目的是使得价值函数与当前的策略保持一致,策略控制则是根据当前价值函数贪心地选择策略。这一流程也被称为广义策略迭代(GPI)。
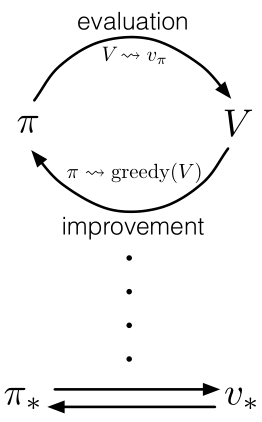
策略总是基于特定的价值函数进行改进,价值函数也始终会向对应特定策略的真实价值函数进行收敛。两者不断轮回直到收敛到一个稳定值。下面以动态规划为主,讲解其策略评估与策略改进。
1.1 策略评估用于估计状态价值
这里需要说明的一点是,策略评估目标预测状态价值。事实上,动态规划自身因为是一种有模型的算法,其已经保存当前时刻所有状态以及所有可能采取的动作,因此通过当前已知的这些信息来预估每个状态最终的价值,也就是说,这些状态价值是一个唯一的值。只是我们并不知道具体是多少,而动态规划的目的就是去找到这个值。后面的证明事实也说明这样的值一定是唯一的且是全局最优的。
给定时刻
的状态
,已知策略分布
、状态转移概率分布
,局部收益
和折扣系数
,回报为
。根据状态价值贝尔曼公式的定义:
则可以推出:
因此如果根据策略 ,则可以依赖贝尔曼方程不断地对每一个状态的价值函数进行迭代,即:
我们仔细分析一下上面这个公式, 表示 时刻状态 的价值函数的第 次迭代值, 则表示 时刻状态 第 次迭代的值。因此动态规划是在贝尔曼方程的基础上,不断地迭代来寻求最优值的过程。策略评估算法如图所示:

首先输入一个确定的策略 ,初始化状态价值函数 。对于所有状态,开始不断地迭代计算。当相邻两次迭代之间值的差小于一个预设的阈值时,迭代结束。
1.2 策略控制用于估计动作价值
策略控制也叫做策略更新、策略改进,其目标即是根据当前的状态结果,贪心的选择认为最优的动作策略:
分析一下可知,当前时刻状态 的最好策略,即是在所有可能的动作中,挑选使得下一个时刻状态价值最大的对应的动作,因此事实上,策略控制就是一次择优过程。
1.3 策略迭代过程
策略迭代就是策略评估与策略控制相互交替的过程,如图所示:
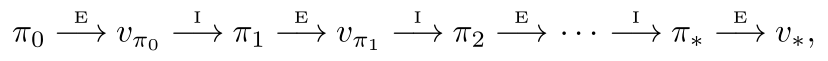
首先初始化一个策略分布,并根据这个策略来迭代所有状态,试图找到该策略下各个状态价值的最好结果,其次从所有可取的动作中,挑选最优动作,作为新的策略,如此循环下去。下面给出动态规划的策略迭代算法:

1、2部分与策略评估一样,第3部分为策略控制,即从当前所有可取的动作中,选择动作价值最大的作为新的策略,当且仅当相邻的两次策略控制得到的最优策略(old-action和 )完全一致时,迭代终止。
需要说明的是,在策略迭代过程中,首先进行的是策略评估,当前仅当策略评估收敛时,才进行策略控制。不过很快我们会发现问题,如果始终等待策略评估收敛后,才能进行策略控制,这一过程会消耗很多时间和计算资源,因此我们比较常用价值迭代来实现动态规划
2、价值迭代与异步动态规划
价值迭代即是将策略评估与策略控制相结合,即在每一次迭代是,直接选择最优的动作来更新当前的状态价值,这样就能保证每个状态都能够保存最好的策略。价值迭代的算法如图所示:

分析一下算法流程,首先是初始化,其次不断迭代,对于每一个状态 ,其直接选择最优策略对应的价值来更新当前状态的价值,即公式 ,其与策略控制公式一样,只是策略控制是选择最大对应的动作,而此处则是将最大值更到 ,这样就一步到位。
事实上,这是一种异步的思想,简单地来说,在每次迭代时,并不在意是否所有的动作都全部完成一次策略评估,而是就地的直接更新。我们可以细想一下策略迭代,其先进行一次策略评估,而这一过程是需要将所有的状态全部遍历一遍,且达到收敛为止,而价值迭代,则不管当前状态是否都遍历完,逢遇到一个状态就就地的将最好的策略对应的价值更新上去。这样的好处自然就是节省内存和时间。
