1. 简介
BLEU(Bilingual Evaluation Understudy),相信大家对这个评价指标的概念已经很熟悉,随便百度谷歌就有相关介绍。原论文为BLEU: a Method for Automatic Evaluation of Machine Translation,IBM出品。
本文通过一个例子详细介绍BLEU是如何计算以及NLTKnltk.align.bleu_score模块的源码。
首先祭出公式:
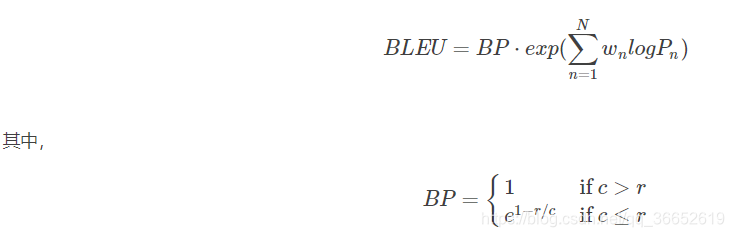
注意这里的BLEU值是针对一条翻译(一个样本)来说的。
NLTKnltk.align.bleu_score模块实现了这里的公式,主要包括三个函数,两个私有函数分别计算P和BP,一个函数整合计算BLEU值。
# 计算BLEU值
def bleu(candidate, references, weights)
# (1)私有函数,计算修正的n元精确率(Modified n-gram Precision)
def _modified_precision(candidate, references, n)
# (2)私有函数,计算BP惩罚因子
def _brevity_penalty(candidate, references)例子:
候选译文(Predicted):
It is a guide to action which ensures that the military always obeys the commands of the party
参考译文(Gold Standard)
1:It is a guide to action that ensures that the military will forever heed Party commands
2:It is the guiding principle which guarantees the military forces always being under the command of the Party
3:It is the practical guide for the army always to heed the directions of the party
2. Modified n-gram Precision计算(也即是PnPn)
def _modified_precision(candidate, references, n):
counts = Counter(ngrams(candidate, n))
if not counts:
return 0
max_counts = {}
for reference in references:
reference_counts = Counter(ngrams(reference, n))
for ngram in counts:
max_counts[ngram] = max(max_counts.get(ngram, 0), reference_counts[ngram])
clipped_counts = dict((ngram, min(count, max_counts[ngram])) for ngram, count in counts.items())
return sum(clipped_counts.values()) / sum(counts.values())我们这里n取值为4,也就是从1-gram计算到4-gram。
Modified 1-gram precision:
首先统计候选译文里每个词出现的次数,然后统计每个词在参考译文中出现的次数,Max表示3个参考译文中的最大值,Min表示候选译文和Max两个的最小值。

然后将每个词的Min值相加,将候选译文每个词出现的次数相加,然后两值相除即得
P1=(3+0+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1)/(3+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1)=0.95
类似可得:
Modified 2-gram precision:

P2=10/17=0.588235294 P2=10/17=0.588235294
Modified 3-gram precision:

![]()


def _brevity_penalty(candidate, references):
c = len(candidate)
ref_lens = (len(reference) for reference in references)
#这里有个知识点是Python中元组是可以比较的,如(0,1)>(1,0)返回False,这里利用元组比较实现了选取参考翻译中长度最接近候选翻译的句子,当最接近的参考翻译有多个时,选取最短的。例如候选翻译长度是10,两个参考翻译长度分别为9和11,则r=9.
r = min(ref_lens, key=lambda ref_len: (abs(ref_len - c), ref_len))
print 'r:',r
if c > r:
return 1
else:
return math.exp(1 - r / c)下面计算BP(Brevity Penalty),翻译过来就是“过短惩罚”。由BP的公式可知取值范围是(0,1],候选句子越短,越接近0。
候选翻译句子长度为18,参考翻译分别为:16,18,16。
所以c=18,r=18(参考翻译中选取长度最接近候选翻译的作为rr)
所以![]()
4. 整合
最终![]()
BLEU的取值范围是[0,1],0最差,1最好。
通过计算过程,我们可以看到,BLEU值其实也就是“改进版的n-gram”加上“过短惩罚因子”。
浅谈用 Python 计算文本 BLEU 分数
BLEU, 全称为 Bilingual Evaluation Understudy(双语评估替换), 是一个比较候选文本翻译与其他一个或多个参考翻译的评价分数
尽管 BLEU 一开始是为翻译工作而开发, 但它也可以被用于评估文本的质量, 这种文本是为一套自然语言处理任务而生成的
通过本教程, 你将探索 BLEU 评分, 并使用 Python 中的 NLTK 库对候选文本进行评估和评分
完成本教程后, 你将收获:
BLEU 评分的简单入门介绍, 并直观地感受到到底是什么正在被计算
如何使用 Python 中的 NLTK 库来计算句子和文章的 BLEU 分数
如何用一系列的小例子来直观地感受候选文本和参考文本之间的差异是如何影响最终的 BLEU 分数
让我们开始吧
浅谈用 Python 计算文本 BLEU 分数
照片由 Bernard Spragg. NZ 提供, 保留所有权
教程概述
本教程分为 4 个部分; 他们分别是:
双语评估替换评分介绍
计算 BLEU 分数
累加和单独的 BLEU 分数
运行示例
双语评估替换评分
双语评估替换分数 (简称 BLEU) 是一种对生成语句进行评估的指标
完美匹配的得分为 1.0, 而完全不匹配则得分为 0.0
这种评分标准是为了评估自动机器翻译系统的预测结果而开发的尽管它还没做到尽善尽美, 但还是具备了 5 个引人注目的优点:
计算速度快, 计算成本低
容易理解
与具体语言无关
和人类给的评估高度相关
已被广泛采用
BLEU 评分是由 Kishore Papineni 等人在他们 2002 年的论文 BLEU: a Method for Automatic Evaluation of Machine Translation 中提出的
这种评测方法通过对候选翻译与参考文本中的相匹配的 n 元组进行计数, 其中一元组 (称为 1-gram 或 unigram) 比较的是每一个单词, 而二元组 (bigram) 比较的将是每个单词对这种比较是不管单词顺序的
BLEU 编程实现的主要任务是对候选翻译和参考翻译的 n 元组进行比较, 并计算相匹配的个数匹配个数与单词的位置无关匹配个数越多, 表明候选翻译的质量就越好
摘自论文 BLEU: a Method for Automatic Evaluation of Machine Translation,2002 年发表
n 元组匹配的计数结果会被修改, 以确保将参考文本中的单词都考虑在内, 而不会对产生大量合理词汇的候选翻译进行加分在 BLEU 论文中这被称之为修正的 n 元组精度
糟糕的是, 机器翻译系统可能会生成过多的合理单词, 从而导致翻译结果不恰当, 尽管其精度高... 从直观上这个问题是明显的: 在识别出匹配的候选单词之后, 相应的参考单词应该被视为用过了我们将这种直觉定义为修正的单元组精度
摘自论文 BLEU: a Method for Automatic Evaluation of Machine Translation,2002 年发表
BLEU 评分是用来比较语句的, 但是又提出了一个能更好地对语句块进行评分的修订版本, 这个修订版根据 n 元组出现的次数来使 n 元组评分正常化
我们首先逐句计算 n 元组匹配数目接下来, 我们为所有候选句子加上修剪过的 n 元组计数, 并除以测试语料库中的候选 n 元组个数, 以计算整个测试语料库修正后的精度分数 pn
摘自论文 BLEU: a Method for Automatic Evaluation of Machine Translation,2002 年发表
实际上, 一个完美的分数是不可能存在的, 因为这意味着翻译必须完全符合参考甚至连人类翻译家都不能做到这点对计算 BLEU 分数的参考文本的数量和质量的水平要求意味着在不同数据集之间的比较 BLEU 分数可能会很麻烦
BLEU 评分的范围是从 0 到 1 很少有翻译得分为 1, 除非它们与参考翻译完全相同因此, 即使是一个人类翻译, 也不一定会在一个大约 500 个句子 (也就是 40 个普通新闻报道的长度) 的测试语料上得 1 分, 一个人类翻译在四个参考翻译下的得分为 0.3468, 在两个参考翻译下的得分为 0.2571
摘自论文 BLEU: a Method for Automatic Evaluation of Machine Translation,2002 年发表
除了翻译之外, 我们还可以将 BLEU 评分用于其他的语言生成问题, 通过使用深度学习方法, 例如:
语言生成
图片标题生成
文本摘要
语音识别
以及更多
计算 BLEU 分数
Python 自然语言工具包库 (NLTK) 提供了 BLEU 评分的实现, 你可以使用它来评估生成的文本, 通过与参考文本对比
语句 BLEU 分数
NLTK 提供了 sentence_bleu()函数, 用于根据一个或多个参考语句来评估候选语句
参考语句必须作为语句列表来提供, 其中每个语句是一个记号列表候选语句作为一个记号列表被提供例如:
from nltk.translate.bleu_score import sentence_bleu
reference = [['this', 'is', 'a', 'test'], ['this', 'is' 'test']]
candidate = ['this', 'is', 'a', 'test']
score = sentence_bleu(reference, candidate)
print(score)运行这个例子, 会输出一个满分, 因为候选语句完全匹配其中一个参考语句
1.0
语料库 BLEU 分数
NLTK 还提供了一个称为 corpus_bleu()的函数来计算多个句子 (如段落或文档) 的 BLEU 分数
参考文本必须被指定为文档列表, 其中每个文档是一个参考语句列表, 并且每个可替换的参考语句也是记号列表, 也就是说文档列表是记号列表的列表的列表候选文档必须被指定为列表, 其中每个文件是一个记号列表, 也就是说候选文档是记号列表的列表
这听起来有点令人困惑; 以下是一个文档的两个参考文档的例子
# two references for one document
from nltk.translate.bleu_score import corpus_bleu
references = [[['this', 'is', 'a', 'test'], ['this', 'is' 'test']]]
candidates = [['this', 'is', 'a', 'test']]
score = corpus_bleu(references, candidates)
print(score)运行这个例子就像之前一样输出满分
1.0
累加和单独的 BLEU 分数
NLTK 中提供的 BLEU 评分方法允许你在计算 BLEU 分数时为不同的 n 元组指定权重
这使你可以灵活地计算不同类型的 BLEU 分数, 如单独和累加的 n-gram 分数
让我们来看一下
单独的 N-Gram 分数
单独的 N-gram 分数是对特定顺序的匹配 n 元组的评分, 例如单个单词 (称为 1-gram) 或单词对(称为 2-gram 或 bigram)
权重被指定为一个数组, 其中每个索引对应相应次序的 n 元组仅要计算 1-gram 匹配的 BLEU 分数, 你可以指定 1-gram 权重为 1, 对于 2 元, 3 元和 4 元指定权重为 0, 也就是权重为 (1,0,0,0) 例如:
# 1-gram individual BLEU
from nltk.translate.bleu_score import sentence_bleu
reference = [['this', 'is', 'small', 'test']]
candidate = ['this', 'is', 'a', 'test']
score = sentence_bleu(reference, candidate, weights=(1, 0, 0, 0))
print(score)运行此例将输出得分为 0.5
0.75
我们可以重复这个例子, 对于从 1 元到 4 元的各个 n-gram 运行语句如下所示:
# n-gram individual BLEU
from nltk.translate.bleu_score import sentence_bleu
reference = [['this', 'is', 'a', 'test']]
candidate = ['this', 'is', 'a', 'test']
print('Individual 1-gram: %f' % sentence_bleu(reference, candidate, weights=(1, 0, 0, 0)))
print('Individual 2-gram: %f' % sentence_bleu(reference, candidate, weights=(0, 1, 0, 0)))
print('Individual 3-gram: %f' % sentence_bleu(reference, candidate, weights=(0, 0, 1, 0)))
print('Individual 4-gram: %f' % sentence_bleu(reference, candidate, weights=(0, 0, 0, 1))运行该示例, 结果如下所示:
Individual 1-gram: 1.000000
Individual 2-gram: 1.000000
Individual 3-gram: 1.000000
Individual 4-gram: 1.000000虽然我们可以计算出单独的 BLEU 分数, 但这并不是使用这个方法的初衷, 而且得出的分数也没有过多的含义, 或者看起来具有说明性
累加的 N-Gram 分数
累加分数是指对从 1 到 n 的所有单独 n-gram 分数的计算, 通过计算加权几何平均值来对它们进行加权计算
默认情况下, sentence_bleu()和 corpus_bleu()分数计算累加的 4 元组 BLEU 分数, 也称为 BLEU-4 分数
BLEU-4 对 1 元组, 2 元组, 3 元组和 4 元组分数的权重为 1/4(25%)或 0.25 例如:
# 4-gram cumulative BLEU
from nltk.translate.bleu_score import sentence_bleu
reference = [['this', 'is', 'small', 'test']]
candidate = ['this', 'is', 'a', 'test']
score = sentence_bleu(reference, candidate, weights=(0.25, 0.25, 0.25, 0.25))
print(score)运行这个例子, 输出下面的分数:
0.707106781187
累加的和单独的 1 元组 BLEU 使用相同的权重, 也就是 (1,0,0,0) 计算累加的 2 元组 BLEU 分数为 1 元组和 2 元组分别赋 50%的权重, 计算累加的 3 元组 BLEU 为 1 元组, 2 元组和 3 元组分别为赋 33%的权重
让我们通过计算 BLEU-1,BLEU-2,BLEU-3 和 BLEU-4 的累加得分来具体说明:
# cumulative BLEU scores
from nltk.translate.bleu_score import sentence_bleu
reference = [['this', 'is', 'small', 'test']]
candidate = ['this', 'is', 'a', 'test']
print('Cumulative 1-gram: %f' % sentence_bleu(reference, candidate, weights=(1, 0, 0, 0)))
print('Cumulative 2-gram: %f' % sentence_bleu(reference, candidate, weights=(0.5, 0.5, 0, 0)))
print('Cumulative 3-gram: %f' % sentence_bleu(reference, candidate, weights=(0.33, 0.33, 0.33, 0)))
print('Cumulative 4-gram: %f' % sentence_bleu(reference, candidate, weights=(0.25, 0.25, 0.25, 0.25)))运行该示例输出下面的分数结果的差别很大, 比单独的 n-gram 分数更具有表达性
Cumulative 1-gram: 0.750000
Cumulative 2-gram: 0.500000
Cumulative 3-gram: 0.632878
Cumulative 4-gram: 0.707107在描述文本生成系统的性能时, 通常会报告从 BLEU-1 到 BLEU-4 的累加分数
运行示例
在这一节中, 我们试图通过一些例子来进一步获取对 BLEU 评分的直觉
我们在语句层次上通过用下面的一条参考句子来说明:
the quick brown fox jumped over the lazy dog
首先, 我们来看一个完美的分数
# prefect match
from nltk.translate.bleu_score import sentence_bleu
reference = [['the', 'quick', 'brown', 'fox', 'jumped', 'over', 'the', 'lazy', 'dog']]
candidate = ['the', 'quick', 'brown', 'fox', 'jumped', 'over', 'the', 'lazy', 'dog']
score = sentence_bleu(reference, candidate)
print(score)运行例子输出一个完美匹配的分数
1.0
接下来, 让我们改变一个词, 把 quick 改成 fast
# one word different
from nltk.translate.bleu_score import sentence_bleu
reference = [['the', 'quick', 'brown', 'fox', 'jumped', 'over', 'the', 'lazy', 'dog']]
candidate = ['the', 'fast', 'brown', 'fox', 'jumped', 'over', 'the', 'lazy', 'dog']
score = sentence_bleu(reference, candidate)
print(score)结果是分数略有下降
0.7506238537503395
尝试改变两个词, 把 quick 改成 fast , 把 lazy 改成 sleepy
# two words different
from nltk.translate.bleu_score import sentence_bleu
reference = [['the', 'quick', 'brown', 'fox', 'jumped', 'over', 'the', 'lazy', 'dog']]
candidate = ['the', 'fast', 'brown', 'fox', 'jumped', 'over', 'the', 'sleepy', 'dog']
score = sentence_bleu(reference, candidate)
print(score)运行这个例子, 我们可以看到得分线性下降
0.4854917717073234
如果候选语句的所有单词与参考语句的都不一样呢?
# all words different
from nltk.translate.bleu_score import sentence_bleu
reference = [['the', 'quick', 'brown', 'fox', 'jumped', 'over', 'the', 'lazy', 'dog']]
candidate = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i']
score = sentence_bleu(reference, candidate)
print(score)我们得到了一个更糟糕的分数
0.0
现在, 让我们尝试一个比参考语句的词汇更少 (例如, 放弃最后两个词) 的候选语句, 但这些单词都是正确的
# shorter candidate
from nltk.translate.bleu_score import sentence_bleu
reference = [['the', 'quick', 'brown', 'fox', 'jumped', 'over', 'the', 'lazy', 'dog']]
candidate = ['the', 'quick', 'brown', 'fox', 'jumped', 'over', 'the']
score = sentence_bleu(reference, candidate)
print(score)结果和之前的有两个单词错误的情况很相似
0.7514772930752859
如果我们把候选语句调整为比参考语句多两个单词, 那又会怎么样?
# longer candidate
from nltk.translate.bleu_score import sentence_bleu
reference = [['the', 'quick', 'brown', 'fox', 'jumped', 'over', 'the', 'lazy', 'dog']]
candidate = ['the', 'quick', 'brown', 'fox', 'jumped', 'over', 'the', 'lazy', 'dog', 'from', 'space']
score = sentence_bleu(reference, candidate)
print(score)再一次, 我们可以看到, 我们的直觉是成立的, 得分还是有点像 有两个错字 的情况
0.7860753021519787
最后, 我们来比较一个很短的候选语句: 只有两个单词的长度
# very short
from nltk.translate.bleu_score import sentence_bleu
reference = [['the', 'quick', 'brown', 'fox', 'jumped', 'over', 'the', 'lazy', 'dog']]
candidate = ['the', 'quick']
score = sentence_bleu(reference, candidate)
print(score)运行此示例首先会打印一条警告消息, 指出不能执行评估 3 元组及以上部分 (直到 4 元组) 这是合乎情理的, 因为在候选语句中我们最多只能用 2 元组来运行
UserWarning:
Corpus/Sentence contains 0 counts of 3-gram overlaps.
BLEU scores might be undesirable; use SmoothingFunction().
warnings.warn(_msg)接下来, 我们会得到一个非常低的分数
0.0301973834223185
你可以继续用这些例子来进行其他试验
BLEU 包含的数学知识非常简单, 我也鼓励你阅读这篇论文, 并在自己电子表格程序中探索计算语句评估分数的方法
进一步阅读
如果你要深入研究, 本节将提供更多有关该主题的资源
BLEU 在维基百科的主页
BLEU: a Method for Automatic Evaluation of Machine Translation,2002 年发表
nltk.translate.bleu_score 的源码
nltk.translate 包的 API 文档
总结
在本教程中, 你探索了 BLEU 评分, 根据在机器翻译和其他语言生成任务中的参考文本对候选文本进行评估和评分
具体来说, 你学到了:
BLEU 评分的简单入门介绍, 并直观地感受到到底是什么正在被计算
如何使用 Python 中的 NLTK 库来计算语句和文章的 BLEU 分数
如何使用一系列的小例子来直观地感受候选文本和参考文本的差异是如何影响最终的 BLEU 分数
参考:
https://blog.csdn.net/guolindonggld/article/details/56966200