算法概述
可行性,有穷性,确定性(输入,输出)
设计要求:
正确性,可读性,健壮性,高效率与低储存
频度:代码重复执行的次数
一般计算最坏时间复杂度,也可以计算平均次数
线性表
tyoedef struct
{
elemtype *elem;
int len;
int listsize;
}sxlist;
int initlist(sxlist &l)
{
l.elem = new int;
if(!l.elem)
exet(overflow);
l.lenth = 0;
l.listsize = sizeof(int);
}注意错误判断
对于长度为n的顺序表,
在第i个位置插入数据,需要移动n-i+1个元素。实际主要花费在移动元素上。
若在任何位置插入的可能相等,p = 1/n+1
期望:E = n/2,O(n)
删除时,删除第i个位置的元素需要移动n-i个元素
E = (n-1)/2,O(n)

线性(单)链表


linklist deletitem(linklist &L,int i,Elemtype &e)
{
p = L;int j = 0;
while(!(p->next==null)&&j<i-1)
{p = p->next;j++;};
linlist *t = p->next;
e = t->data;
p->next =p->next->next;
free(p);
return ok;
}头插法建立链表
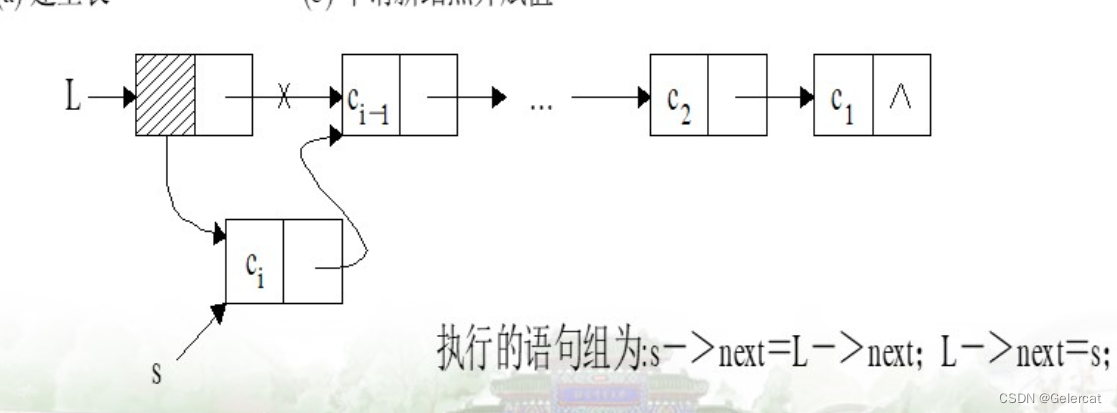
尾插法建立链表
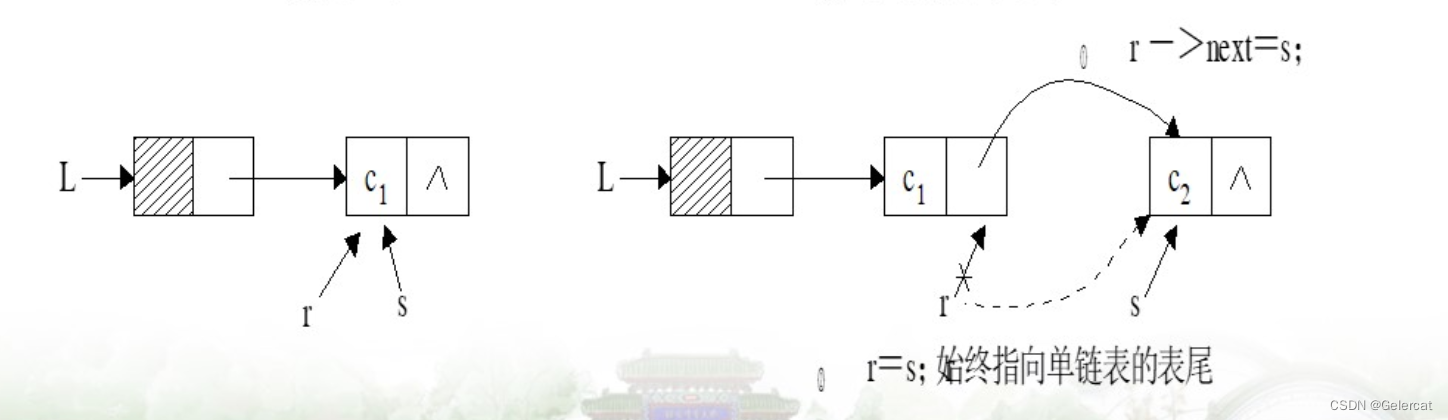
单循环链表
设置头指针或尾指针,尾指针rear会更好
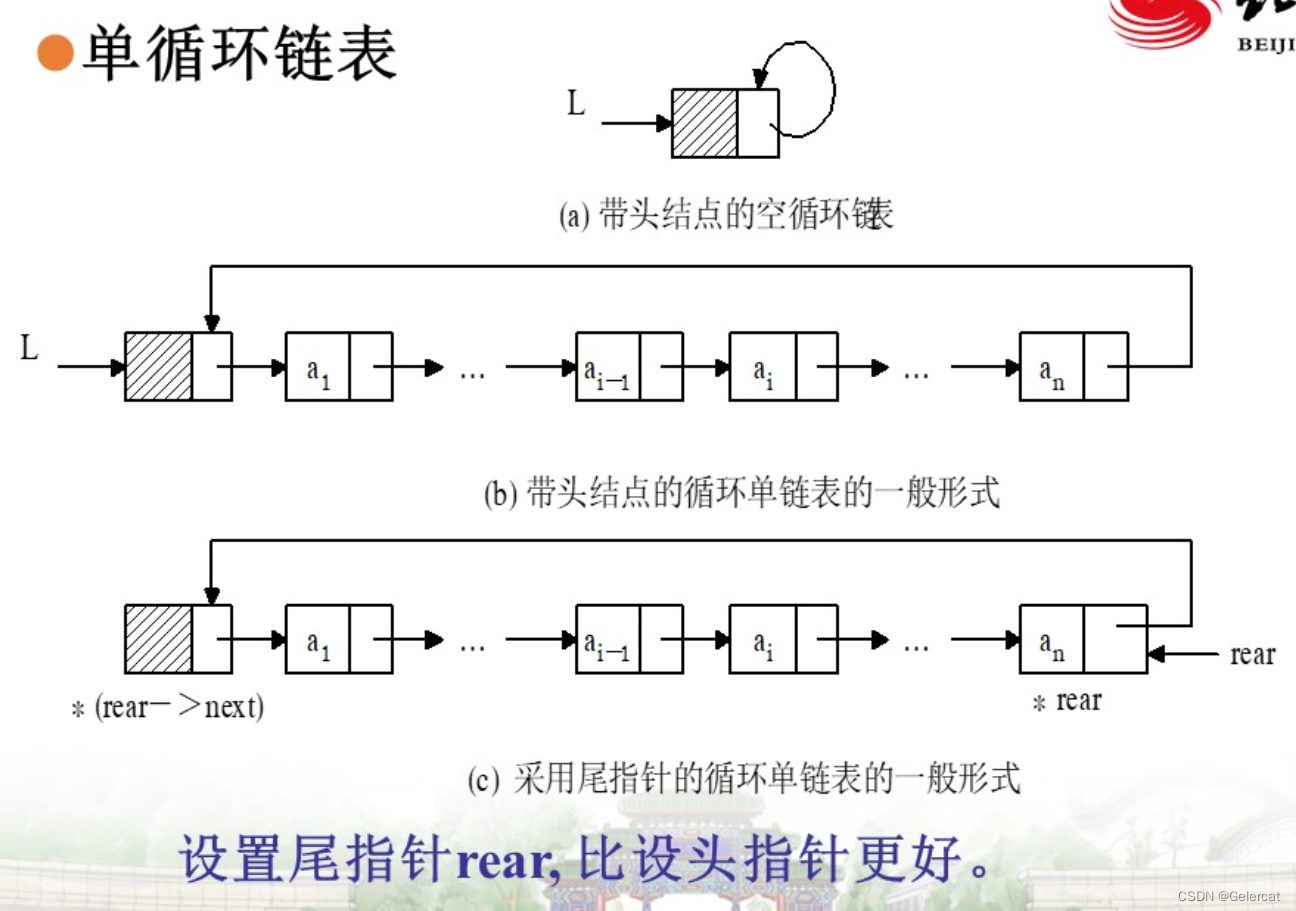
连接只需将后面的头节点抛弃
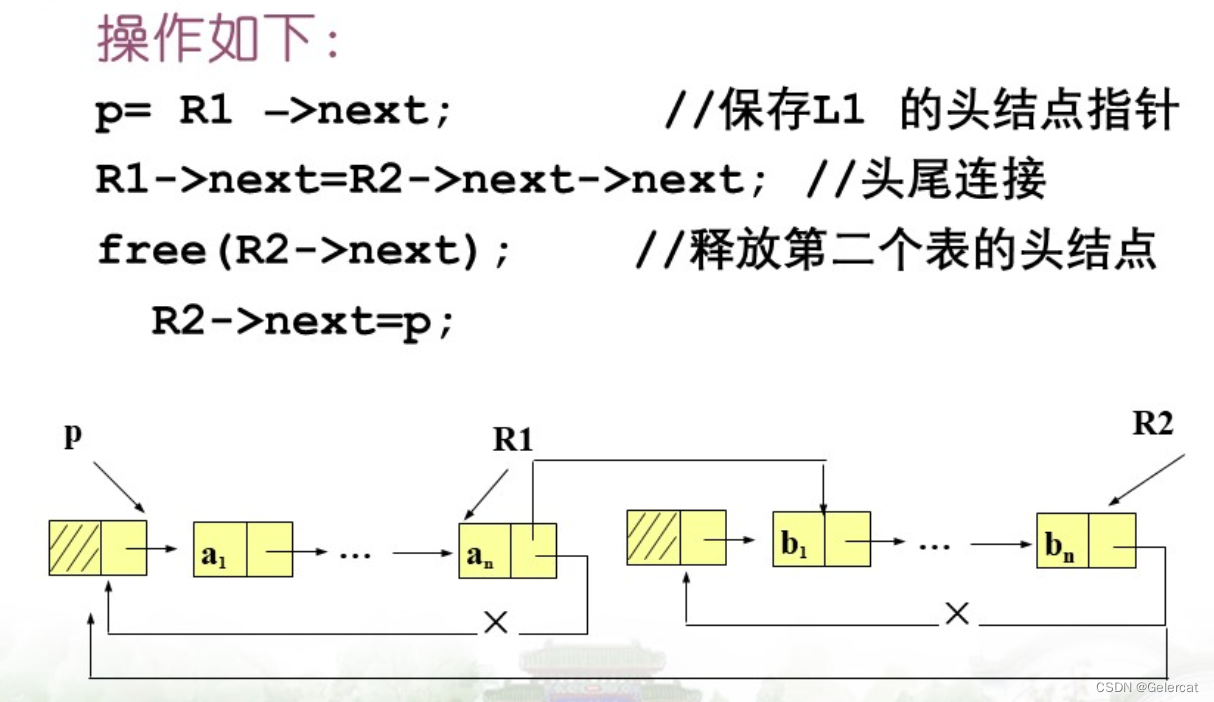
遍历结束的标志:p == L
双链表



栈
顺序栈
#define SElemtype int
#define MAXSIZE 100
typedef struct
{
SElemtype *base;
SElemtype *top;
int stacksize;
}myStack;
typedef struct
{
SElemtype data[MAXSIZE];
int top;
};
动态分配:
栈空:S.base == top;
不存在栈:S.base == Null;
栈满:S.top - S.base>=S.stacksize;
#top 指向的是栈顶元素的顶上一个#
静态分配:
栈空:top = 0;
不存在栈:data = Null;
栈满:top == MAXSIZE;
链栈
只初始化一个栈顶结点指针
#define SElemtype int
#define MAXSIZE 100
typedef struct STNode
{
SElemtype data;
struct STnode *next;
}STNode, *linkStack;与单链表的定义方式一模一样,区别在于操作。并且链表有空数据的头结点,但栈没有,有的只有栈顶结点指针,且存数据。
入栈
typedef struct STNode
{
SElemtype data;
struct STnode *next;
}STNode, *linkStack;出栈
void Pop(linkStack &S,SElemtype &e)
{
linkStack P = S;
e = P->data;
S = P->next;
delete P;
}应用


队列

链队列
一个头指针,一个尾指针,一堆储存单元以链表形式存在
#include <iostream>
typedef int QElemtype;
//定义
typedef struct QNode
{
QElemtype data;
struct QNode *next;
}QNode,*QueuePrt;
typedef struct
{
QueuePrt front;
QueuePrt rear;
}LinkQueue;
//初始化队列
void initQueue(LinkQueue &Q)
{
Q.front = Q.rear = new QNode;
if(!Q.front)exit(0);
Q.front->next = NULL;
};
//进队列
void InQueue(LinkQueue &Q,QElemtype e)
{
QueuePrt p = new QNode;
p->data = e;
p->next = NULL;
Q.rear->next = p;
Q.rear = p;
};
//出队列
void OutQueue(LinkQueue &Q,QElemtype &e)
{
if(Q.front==Q.rear)std::cout<<"队已空"<<std::endl;return;
QueuePrt p = Q.front->next;
e = p->data;
Q.front->next = p->next;
if(Q.rear==p)Q.rear = Q.front;
delete p;
return ;
}队空标志
有头节点:Q.front = Q.rear;
无头节点:Q.front = NULL
循环队列
typedef struct
{
QElemtype *base;
int front;
int rear;
}SqQueue;
空队列:Q.front = Q.rear;
入队列:Q.rear++;
出队列:Q.front++;
非空队列,front指针始终指向队头元素
rear指针始终指向队尾元素的下一位置

插入元素:rear = (rear+1)%maxsize
删除元素:front = (front+1)%maxsize
但这样无法判断是队空还是队满,使用特殊的方法

初始化:Q.front = Q.rear = 0;
队空:front == rear;
队满:Q.front == (Q.rear+1)%maxsize
队列长度:L = (maxsize+rear-front)%maxsize
插入元素:base[rear]=x;
rear = (rear+1)%maxsize;
删除元素:front = (front+1)%maxsize;
串
堆:用户程序动态申请的地址空间
栈:保存函数参数和块内局部遍历的内存区
串:
下表以0为数组分量存放串的实际长度(a[0] = maxsize),因此定义储存数组时要maxsize+1
同时串的最后加入不计串长的结束标记字符。
储存密度=串值所占的存储位/实际分配的存储位
数组
一维数组中每个元素占用L个存储单元,任意一数据元素a的存储地址可以由下公式求出:
loc(ai) = loc(a0)+i*L;
二维数组
两者主序方式:
行:
列:
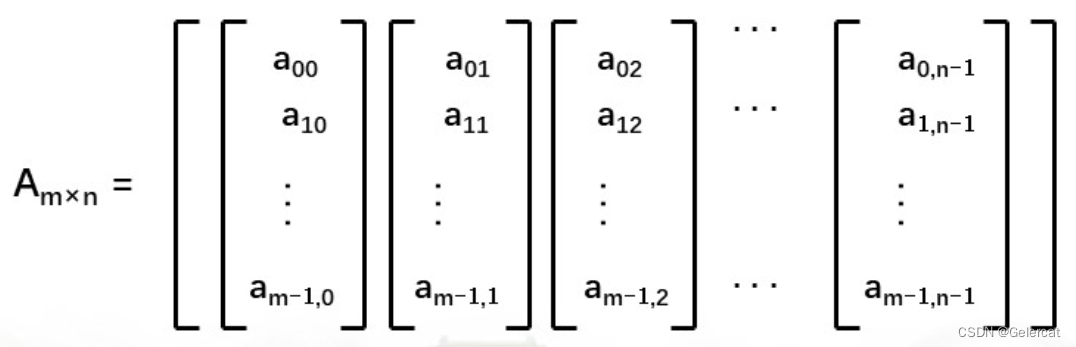
对于行主序:
二维数组:A(mxn)
aij的储存地址为:loc(aij) = loc(a00)+(n*i+j)*L
n维数组:下标:(j1,j2,j3,...,jn)
loc(j1,j2,...,jn) = loc(0,0,...,0)+(bn*...*b2*j1+bn*...b3*j2+...+bn*jn-1 +jn)*L
对于列主序:
二维数组:A(mxn)
aij的储存地址为:loc(aij) = loc(a00)+(j*m+i)*
矩阵的压缩储存
对称矩阵:只储存上三角或下三角的元素,将n^2个元素压缩到n*(n-1)/2个空间里,以一个一维数组作为存储结构
元素aij在该一维数组内的存储下标计算:
#算(i-1)时三角形里元素,再加上第i行的j个元素,下标从0开始所有减1
i>=j(下三角):k = i(i-1)/2+j-1
i<=j(上三角):k = j(j-1)/2+i-1
其实就是第aij是三角型的第k个元素的问题
对角矩阵:所有非0元素都集中在对焦现为中心得带状区域内,只有高对角线,对角线,低对角线三个对角线上的元素非0。同样以一个一维数组作为储存结构
共有3n-2个元素;
低对角线上元素:
k = 3(i-1)-1,i =j+1;
对角线上元素:
k = 3(i-1),i=j;
高对角线上元素:
k = 3(i-1)+1,i=j-1
稀疏矩阵:当非0元素个数t/(m*n)<=0.05时称为稀疏矩阵
用三元组顺序表(i,j,aij)
行逻辑链接得顺序表
十字链表
((1,2,19),(1,3,,9),(3,1,-3),(6,4,7))
广义表
是线性表得推广,是由0个或多个单元素或子表所组成的有限序列

广义表的长度:括号里的元素个数;
广义表的深度:子表全部展开后,( 的个数就是深度#注意同级的括号算一层
C = (a,C)长度为2,深度无限
表头(Head)
广义表非空时,第一个元素a1为广义表的表头(Head)
表尾(Tail)
其余元素组成的表(a2,a3,...,an)称为表尾
表头可能是原子,也可能是广义表,但表尾一定是广义表
tail取出来的一定是个表!!!没有()也要加上,有了再加一层,对于只有一个元素的广义表,取出来的就是()。