目录
1. VisualGLM 效果展示
- VisualGLM 问答
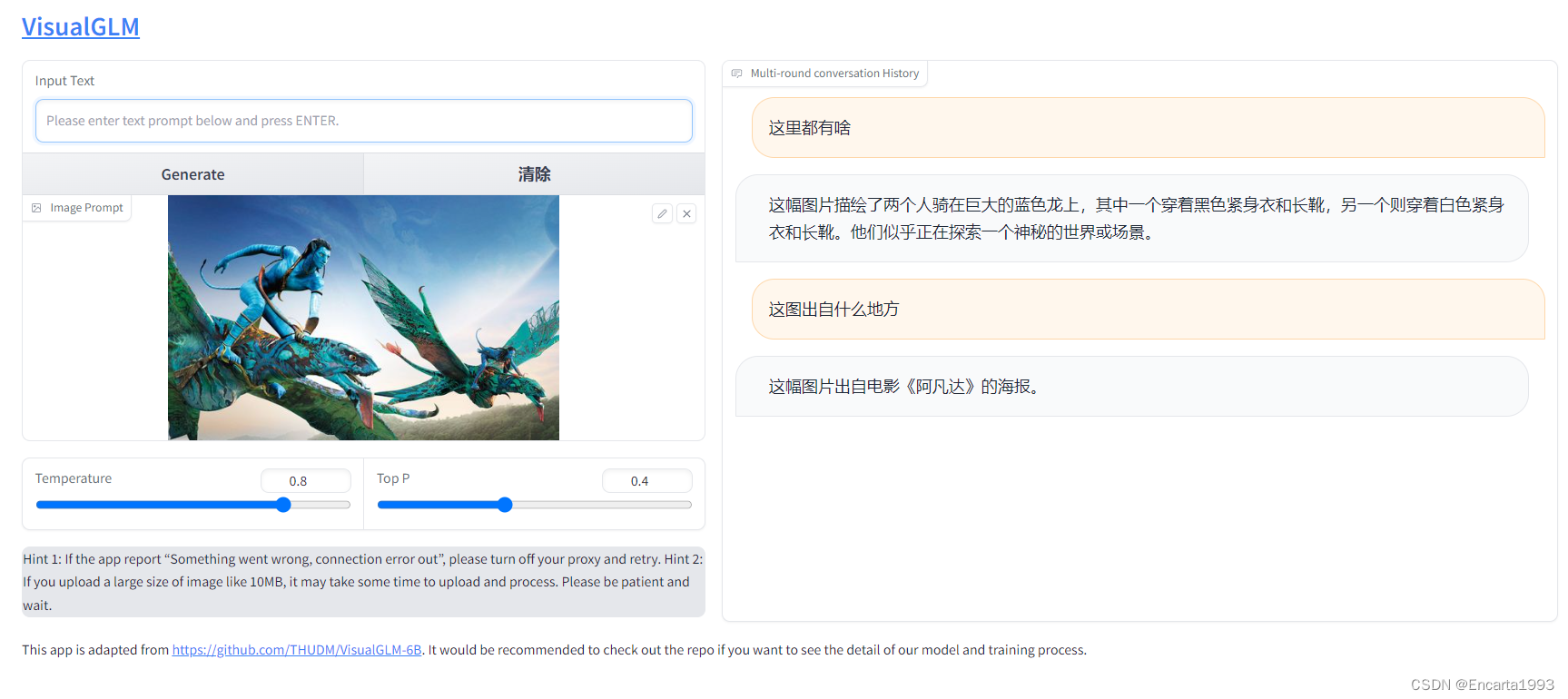
- 原始图片

2. VisualGLM 介绍
VisualGLM 主要做的是通过图像生成文字,而 Stable Diffusion 是通过文字生成图像。

一种方法是将图像当作一种特殊的语言进行预训练,还有一种是将图像特征对齐到预训练语言模型,可充分利用语言模型,并且无缝衔接多轮对话能力,但提取图像语义特征会损失底层信息。
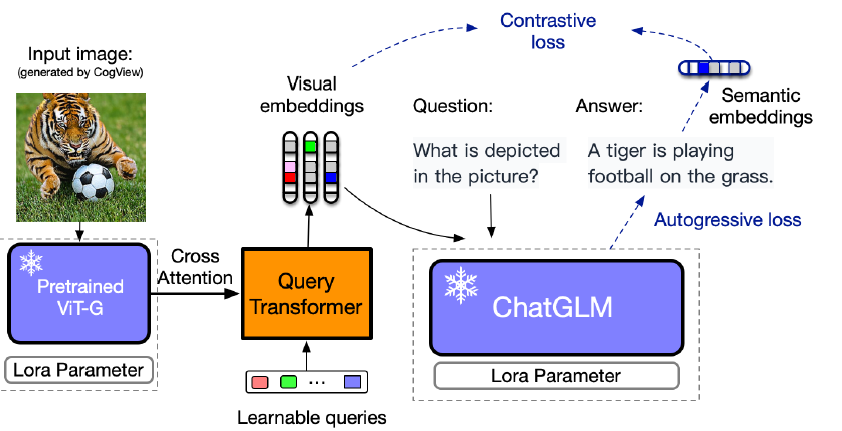
VisualGLM 模型架构是 ViT + QFormer + ChatGLM,在预训练阶段对 QFormer 和 ViT LoRA 进行训练,在微调阶段对 QFormer 和 ChatGLM LoRA 进行训练,训练目标是自回归损失(根据图像生成正确的文本)和对比损失(输入 ChatGLM 的视觉特征与对应文本的语义特征对齐)。
3. VisualGLM 部署
- ChatGLM 模型权重下载见
- VisualGLM 启动
# 源码下载
git clone https://github.com/THUDM/VisualGLM-6B.git
# 代码修改
# 可以把 ChatGLM-6B 改为本地加载
# web 端启动
cd VisualGLM-6B
pip install -r requirements.txt
pytohn web_deme.py