本地部署 VisualGLM-6B
1. 什么是 VisualGLM-6B
VisualGLM-6B 是一个开源的,支持图像、中文和英文的多模态对话语言模型,语言模型基于 VisualGLM-6B,具有 62 亿参数;图像部分通过训练 BLIP2-Qformer 构建起视觉模型与语言模型的桥梁,整体模型共78亿参数。
VisualGLM-6B 依靠来自于 CogView 数据集的30M高质量中文图文对,与300M经过筛选的英文图文对进行预训练,中英文权重相同。该训练方式较好地将视觉信息对齐到VisualGLM的语义空间;之后的微调阶段,模型在长视觉问答数据上训练,以生成符合人类偏好的答案。
VisualGLM-6B 由 SwissArmyTransformer(简称sat) 库训练,这是一个支持Transformer灵活修改、训练的工具库,支持Lora、P-tuning等参数高效微调方法。本项目提供了符合用户习惯的huggingface接口,也提供了基于sat的接口。
不过,由于 VisualGLM-6B 仍处于v1版本,目前已知其具有相当多的局限性,如图像描述事实性/模型幻觉问题,图像细节信息捕捉不足,以及一些来自语言模型的局限性。请大家在使用前了解这些问题,评估可能存在的风险。在VisualGLM之后的版本中,将会着力对此类问题进行优化。
结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4量化级别下最低只需8.7G显存)。
2. Github 地址
https://github.com/THUDM/VisualGLM-6B
3. 安装 Miniconda3
下载 Conda 安装脚本,
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
运行安装脚本,
bash Miniconda3-latest-Linux-x86_64.sh
按提示操作。当提示是否初始化 Conda 时,输入 “yes”,
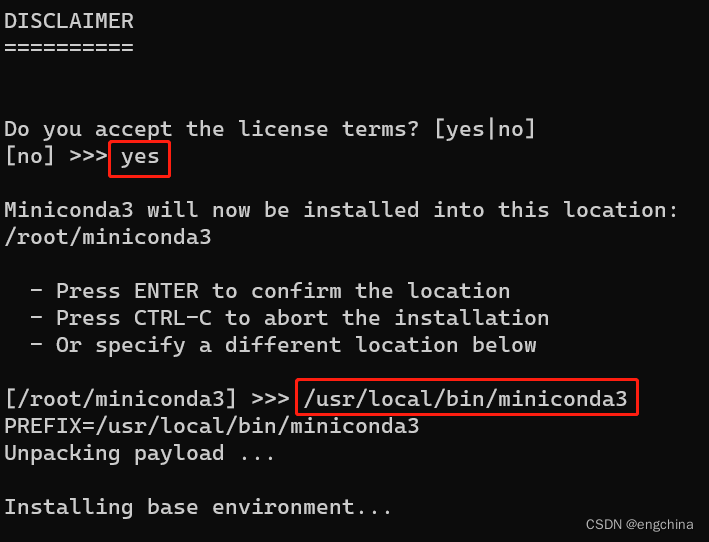
安装完成后,关闭当前终端并打开新终端,这将激活 Conda,
sudo su - root
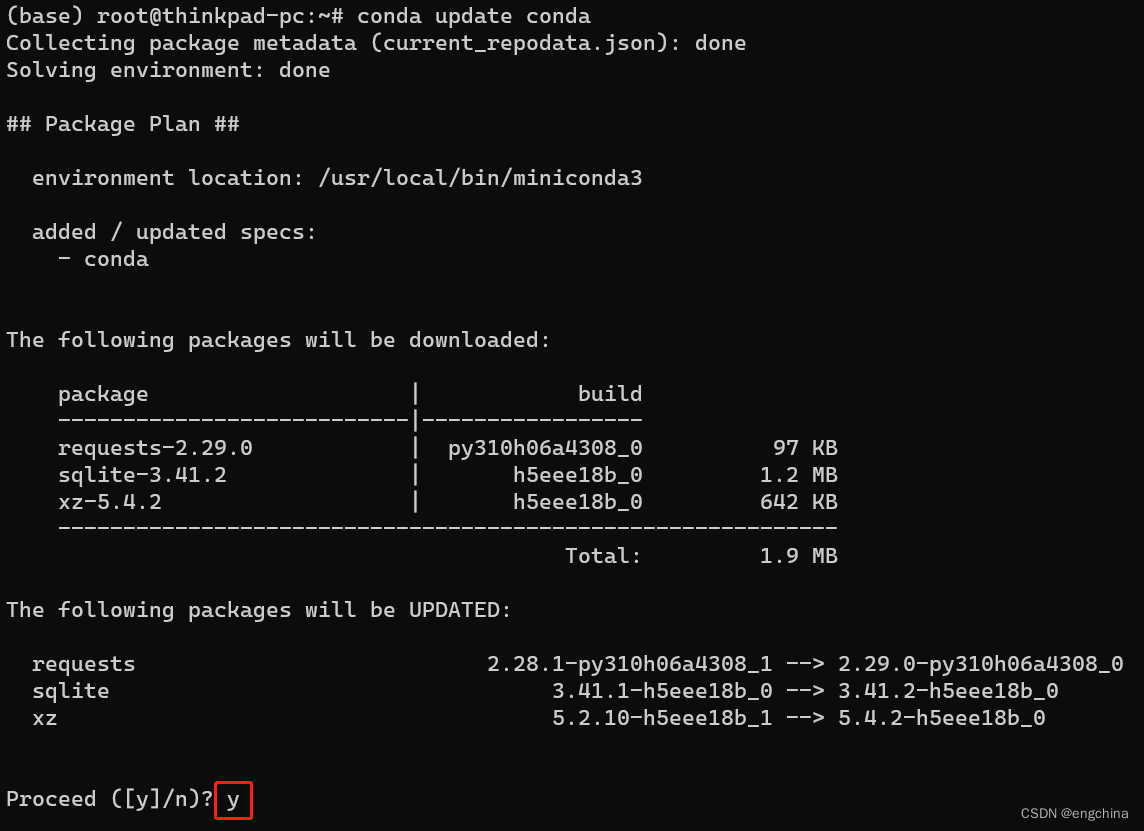
更新 Conda 至最新版本,
conda update conda

(可选)Conda 配置 aliyun 源
vi ~/.condarc
输入如下内容,
channels:
- defaults
show_channel_urls: true
default_channels:
- http://mirrors.aliyun.com/anaconda/pkgs/main
- http://mirrors.aliyun.com/anaconda/pkgs/r
- http://mirrors.aliyun.com/anaconda/pkgs/msys2
custom_channels:
conda-forge: http://mirrors.aliyun.com/anaconda/cloud
msys2: http://mirrors.aliyun.com/anaconda/cloud
bioconda: http://mirrors.aliyun.com/anaconda/cloud
menpo: http://mirrors.aliyun.com/anaconda/cloud
pytorch: http://mirrors.aliyun.com/anaconda/cloud
simpleitk: http://mirrors.aliyun.com/anaconda/cloud
测试是否安装成功,
conda list
如果显示 Conda 及其内部包的列表,则说明安装成功。
4. 创建虚拟环境
conda create -n visualglm python==3.10.6
conda activate visualglm
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
5. 安装 VisualGLM-6B
git clone --recursive https://github.com/THUDM/VisualGLM-6B; cd VisualGLM-6B
# 下面命令 2 选 1
# (2 选 1 之 1)国内请使用aliyun镜像,TUNA等镜像同步最近出现问题,命令如下
pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements.txt
# (2 选 1 之 2)国外请使用pypi.org镜像,命令如下
pip install -i https://pypi.org/simple -r requirements.txt
pip install gradio chardet cchardet fastapi uvicorn
6. 启动 VisualGLM-6B
我的环境使用 sat 模型会报错,所以实验全是使用的 Huggingface 模型,
# python web_demo.py
python web_demo_hf.py
7. 访问 VisualGLM-6B
使用浏览器打开 http://localhost:8080/,上次 1 张图片测试一下,
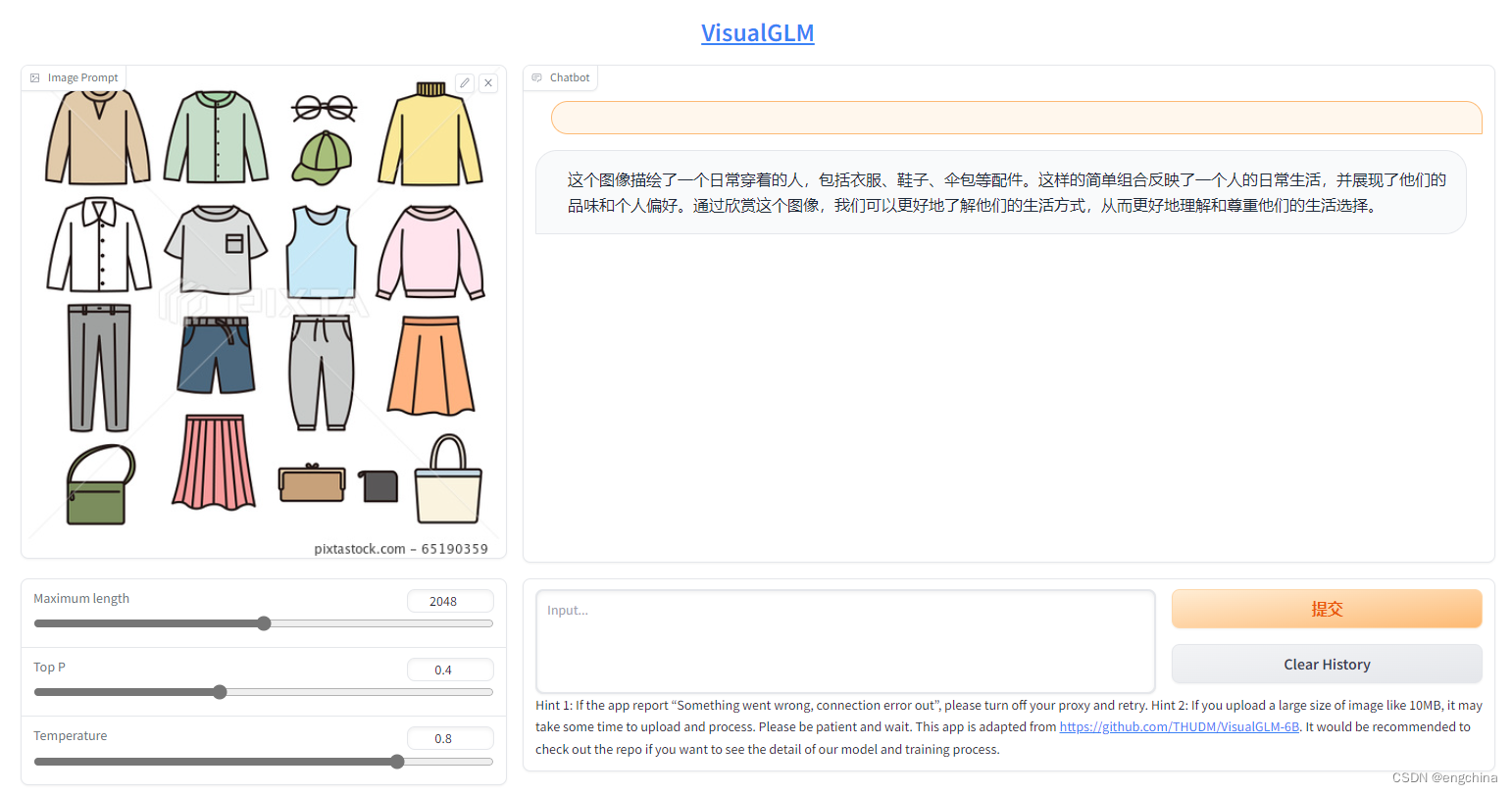
8. API部署
使用Huggingface模型的 api_hf.py,运行仓库中的 api_hf.py,
# python api.py
python api_hf.py
程序会自动下载 HuggingFace 模型,默认部署在本地的 8080 端口,通过 POST 方法进行调用。下面是用curl请求的例子,一般而言可以也可以使用代码方法进行POST。
echo "{\"image\":\"$(base64 /mnt/d//tmp/65190359.jpg)\",\"text\":\"描述这张图片\",\"history\":[]}" > temp.json
curl -X POST -H "Content-Type: application/json" -d @temp.json http://127.0.0.1:8080
得到的返回值为,
{
"result":"一件衬衫,一条裤子和一双鞋子。一个背包和一个手提包。一张卡片,一把雨伞和一些其他物品。这些物品组合在一起,形成了一套时尚的衣服。它们代表着现代生活的风格,展示了人们对自由、舒适和舒适的追求。这个图像展现了一种独特的风格,展示了人们在生活中穿着简单而富有时尚感的服饰。",
"history":[
],
"status":200,
"time":"2023-05-20 03:28:21"
}
9. 命令行部署
运行仓库中 cli_demo_hf.py,
# python cli_demo.py
python cli_demo_hf.py
程序会自动下载 HuggingFace 模型,并在命令行中进行交互式的对话,输入指示并回车即可生成回复,输入 clear 可以清空对话历史,输入 stop 终止程序。
效果展示如下,

大家可以访问 https://github.com/THUDM/VisualGLM-6B 了解更多详细信息。
完结!