XrayGLM据说是首个会看胸部X光片的中文多模态医学大模型,我最近也是因为关注这个所以就找时间学习了一下,顺便把学习资料对应记录分享一下。
官方提供了开源的项目,地址在这里,如下所示:
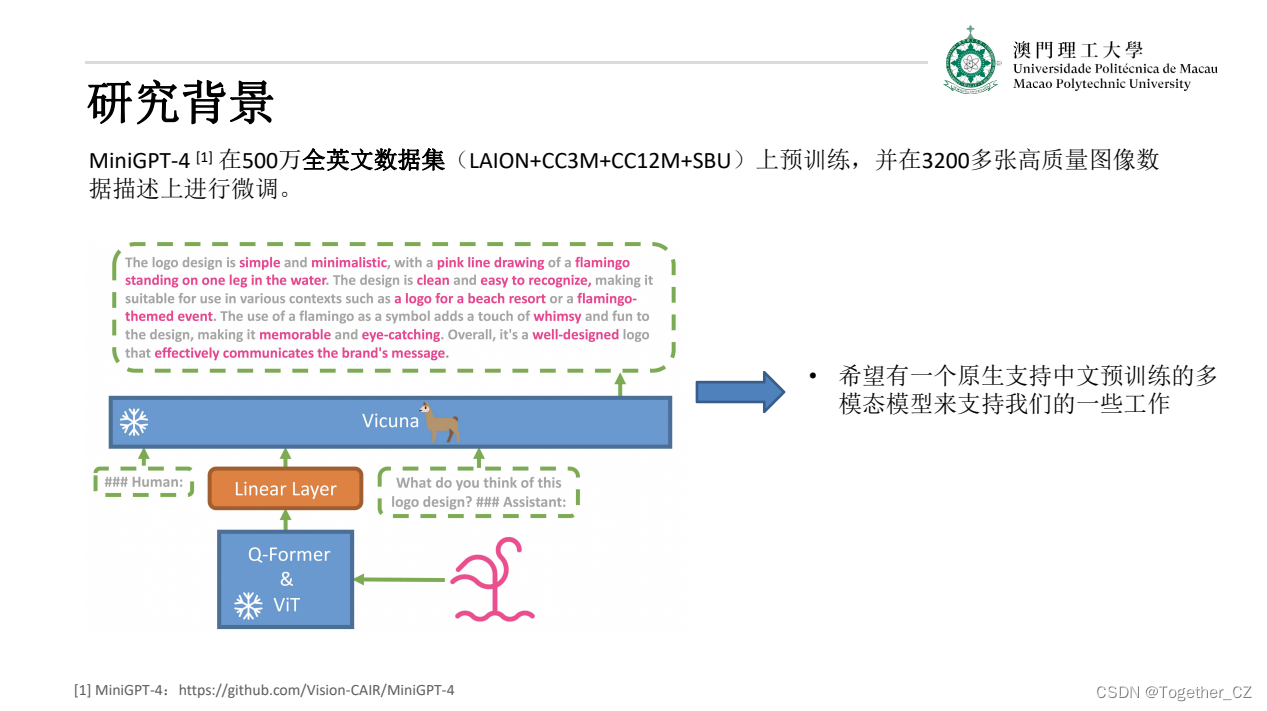
最近,通用领域的大语言模型 (LLM),例如 ChatGPT,在遵循指令和产生类似人类响应方面取得了显著的成功,这种成功间接促进了多模态大模型的研究和发展,如通用领域的多模态大模型MiniGPT-4、mPLUG-Owl、Multimodal-GPT和LLaVA ,然而,此类多模态大模型却很少出现在医学领域的研究中,阻碍了相关研究发展。visual-med-alpaca虽然在医学多模态大模型方面做出了一些很有成效的工作,然而其数据为英文诊断报告,不利于促进中文领域医学多模态大模型的研究发展。为此,我们开发了XrayGLM以解决上述问题。XrayGLM在医学影像诊断和多轮交互对话上显示出了非凡的潜力。
为了帮助大家上手学习掌握,官方也提供了对应的视频讲解,地址在这里,如下所示:
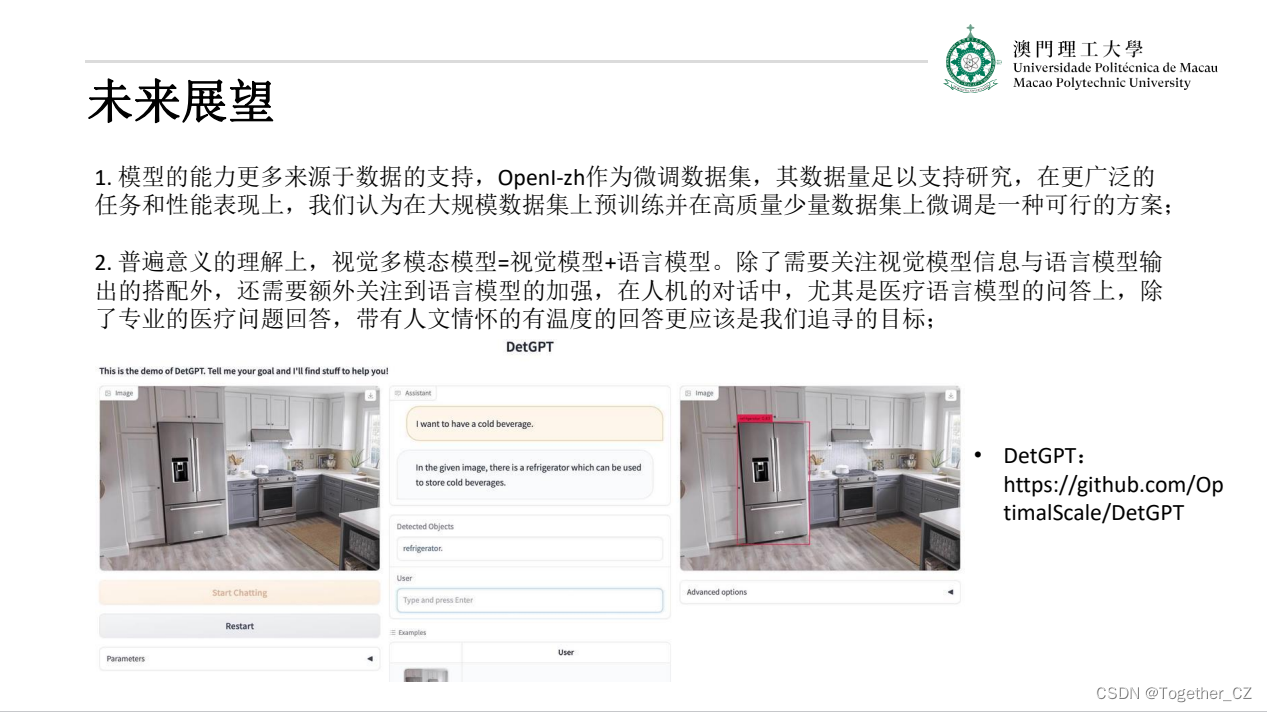
项目主要完成了两个贡献:
- 借助ChatGPT以及公开的数据集,我们构造了一个
X光影像-诊断报告对的医学多模态数据集; - 我们将构建的中文胸部X光片诊断数据集在VisualGLM-6B进行微调训练,并开放了部分训练权重用于学术研究;
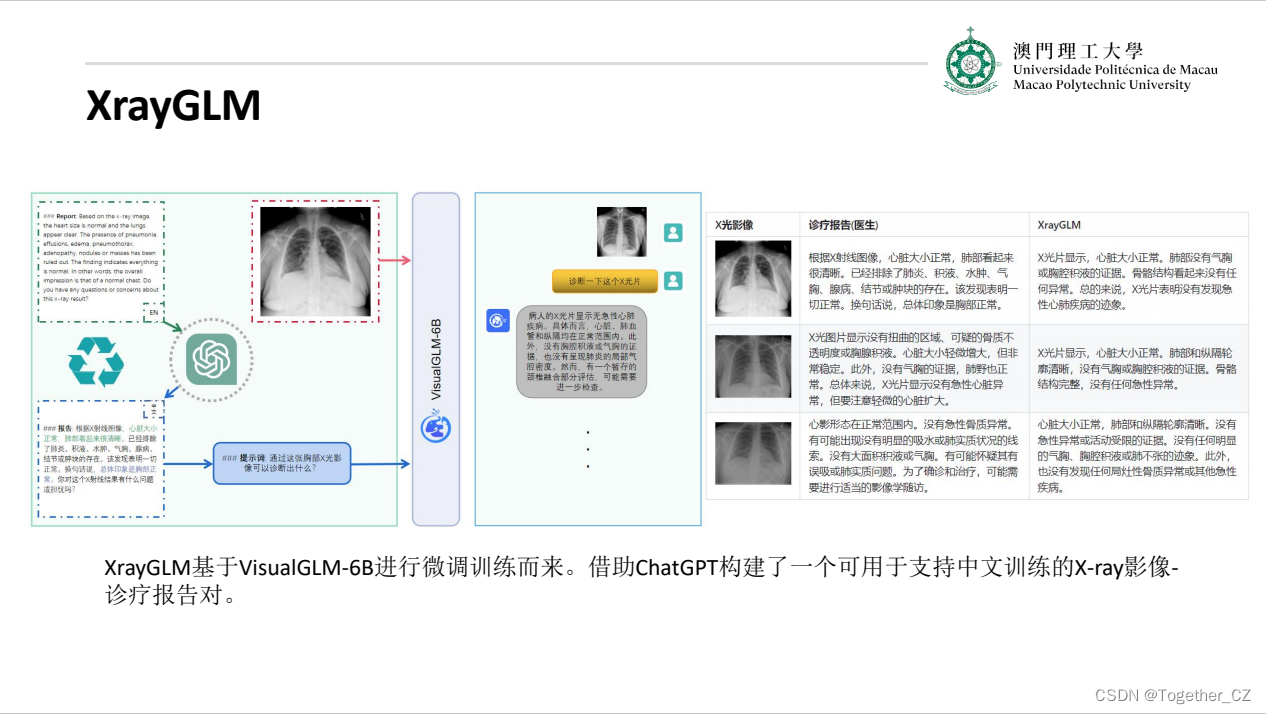
下面是报告内容详情:









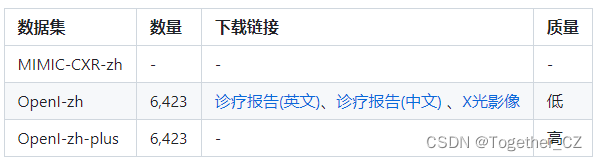
官方项目使用的数据集是开源的数据如下:
- MIMIC-CXR是一个公开可用的胸部X光片数据集,包括377,110张图像和227,827个相关报告。
- OpenI是一个来自印第安纳大学医院的胸部X光片数据集,包括6,459张图像和3,955个报告。
在上述工作中,报告信息都为非结构化的,不利于科学研究。为了生成合理的医学报告,我们对两个数据集进行了预处理,并最终得到了可以用于训练的英文报告。除此之外,为了更好的支持中文社区发展,借助ChatGPT的能力,我们将英文报告进行了中文翻译,并最终形成了可用于训练的数据集。
环境安装部署如下:
安装环境
# 安装依赖
pip install -r requirements.txt
# 国内换源安装依赖
pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements.txt
此时默认会安装deepspeed库(支持sat库训练),此库对于模型推理并非必要,同时部分Windows环境安装此库时会遇到问题。 如果想绕过deepspeed安装,我们可以将命令改为:
# 安装依赖
pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements_wo_ds.txt
# 安装SwissArmyTransformer
pip install -i https://mirrors.aliyun.com/pypi/simple/ --no-deps "SwissArmyTransformer>=0.3.6"checkpoints-XrayGLM-300模型权重地址在这里,如下所示:
checkpoints-XrayGLM-3000模型权重地址在这里,如下所示:


可以看到:模型体积将近16GB。
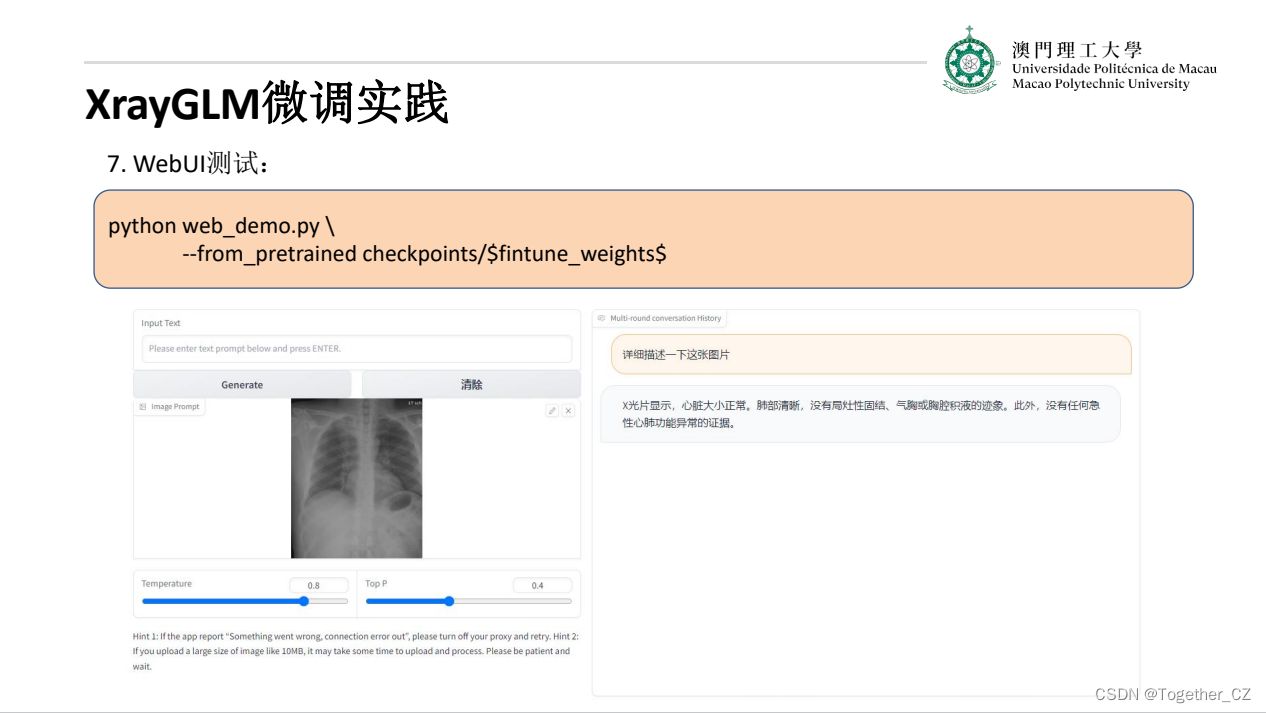
运行启动只需要终端执行下面的命令即可:
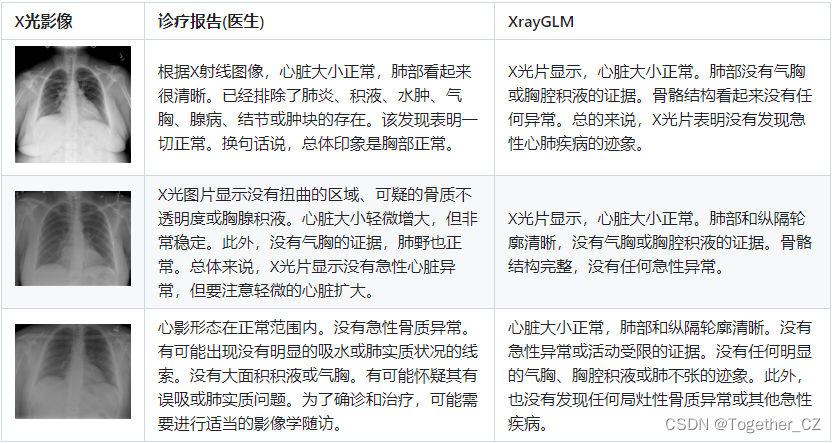
python web_demo.py --from_pretrained checkpoints/checkpoints-XrayGLM-3000实例影像诊断效果如下所示:
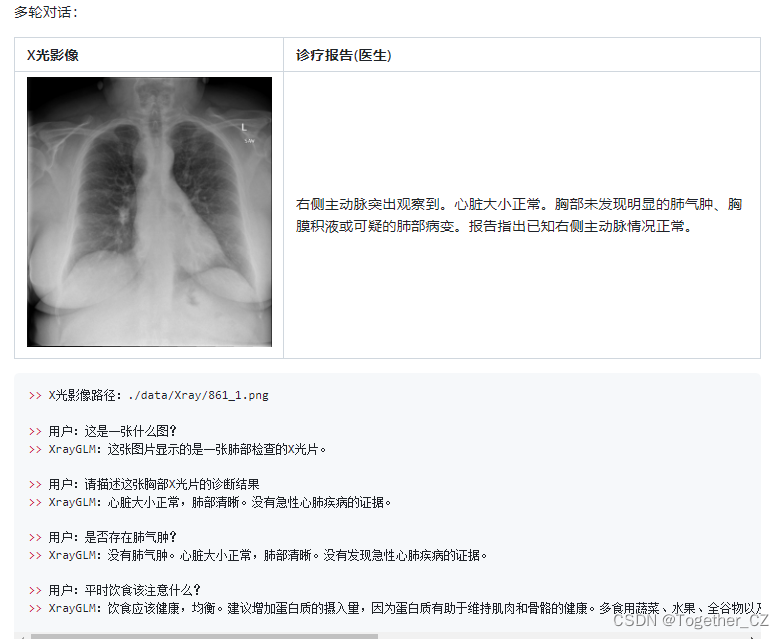
多轮对话实例:
感兴趣的话都是可以自己训练实验体验一下的:
硬件资源
* 实验在A100 (4X, 80GB)上进行
(1)准备诊疗报告(中文)和X光影像在data/Xray文件夹下;
(2)开始训练:
# 设置CUDA变量,主要是为了解决有时候直接训练而出现无法正确加载到显卡问题
export CUDA_VISIBLE_DEVICES=0,1,2,3
# 开始训练
bash finetune_XrayGLM.sh
这里的复现过程非常简单,主要是很多过程我们都为大家准备好了,大家可以随时复现一个自己的XrayGLM。