本文不赘述神经网络的原理,只是简单介绍如何用python3.0 |tensorflow2.0框架搭建一个简单的神经网络,进行简单的图像识别。
本文分为三个部分,第一部分先po出总体代码,第二部分分段详解每段代码,第三部分总结。
参考:
2Fashion-MNIST:替代MNIST手写数字集的图像数据集 - 知乎 (zhihu.com)
3 model.evaluate检验_kitanoli的博客-CSDN博客_model.evaluate
目录
总体代码
import tensorflow as tf
from tensorflow import keras
#导入数据集
fashion_mnist = keras.datasets.fashion_mnist
#devide the data into training and test:train 60000 and test 10000
(train_images, train_lables),(test_images, test_lables) = fashion_mnist.load_data()
# 定义一个三层结构,输入层,隐藏层,输出层
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28,28)), #图片为28 28格式
keras.layers.Dense(128, activation= tf.nn.relu), #隐藏层有128个神经元,这个数字是自己定的
keras.layers.Dense(10, activation = tf.nn.softmax) #10指的输出有10个类别,10个神经元
])
# train and evaluate the module
train_images_scaled = train_images/255 #将输入的数据归一化,训练效果更好
model.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics=['accuracy'])
model.fit(train_images_scaled, train_lables, epochs=5)
test_images_scaled = test_images/255
model.evaluate(test_images_scaled, test_lables)
#module to predict
print(model.predict(test_images/255)[0])代码细节介绍
1 导入数据集
from tensorflow import keras
fashion_mnist = keras.datasets.fashion_mnist
#devide the data into training and test:train 60000 and test 10000
(train_images, train_lables),(test_images, test_lables) = fashion_mnist.load_data()- 这段代码是导入mnist图像数据集,涵盖了10种类别的共7万个不同商品的正面图片以及对应的标签,每张图片都是28×18的灰度图。训练集/测试集划分为60000/10000,即这里的trian_images有60000张,test_images有10000张。
- 可以利用以下代码,查看训练集的数据形状。
print(train_images.shape) #可以查看训练集的数据形状
print(train_images[0]) #可以查看训练集种具体一张图片的像素
plt.imshow(train_images[0]) #可以查看图片样式,关于imshow函数使用可以查看上一篇博文可以看到对应的形状为(60000,28,28),即60000张28×28的灰度图片。
其他补充:
1 keras介绍
tf.keras 是 TensorFlow 对 Keras API 规范的实现。这是一个用于构建和训练模型的高阶 API,包含对 TensorFlow 特定功能(例如 Eager Execution、tf.data 管道和 Estimator)的顶级支持。 tf.keras 使 TensorFlow 更易于使用,并且不会牺牲灵活性和性能。
2 搭建网络模型
# 定义一个三层结构,输入层,隐藏层,输出层
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28,28)), #图片为28 28格式
keras.layers.Dense(128, activation= tf.nn.relu), #隐藏层有128个神经元,这个数字是自己定的
keras.layers.Dense(10, activation = tf.nn.softmax) #10指的输出有10个类别,10个神经元
])
- 这里定义了一个三层的网络结构,输入层,隐藏层,输出层。输入层为展平的28×28的图像像素输入,隐藏层有128个神经元,激活层有10个神经元。
keras.Sequential函数,个人理解是:按照顺序分别 建立神经网络的第一层,第二层,第三层。sequetial的意思为顺序的,例如这里keras.layers.Flatten函数建立了神经网络的第一层,keras.layers.Dense建立了神经网络的第二层。
keras.layers.Flatten函数,负责将输入层数据压缩成一维数据,也就是28×28=784。通常用作全连接层,因为全连接层只能接收一维数据,而卷积层可以处理二维数据。
keras.layers.Dense 建立全连接层:
keras.layers.Dense(units, activation=None, use_bias=True, kernel....)
- 这里的units是神经元的个数,正整数
- activation 是选择激活函数,若不指定,则默不使用激活函数。
感兴趣可以自己查查每个激活函数的用法,这里不赘叙。
3 训练网络模型
# train the module
train_images_scaled = train_images/255 #将输入的数据归一化,训练效果更好
model.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics=['accuracy'])
model.fit(train_images_scaled, train_lables, epochs=5)由于像素值在0-255,将其压缩到0-1之间训练效果会更好。
- model.compile 用于在配置训练时,告知训练时用的优化器、损失函数和准确率的评测标准。
- model.fit 用于执行模型的训练过程。
model.fit(训练集的输入特征X,
训练集的标签Y,
batch_size,#每一个batch的大小,这里未设置
epochs,迭代的次数)
4 评价模型,如何看训练效果
test_images_scaled = test_images/255 #因为训练集归一化了,这里也归一化
model.evaluate(test_images_scaled, test_lables) #评价模型效果model.evaluate 输入数据及对应的真实标签,然后将预测结果与真实标准相比较,得到两者误差并输出。
下图为对应的5轮训练对应的损失和准确率: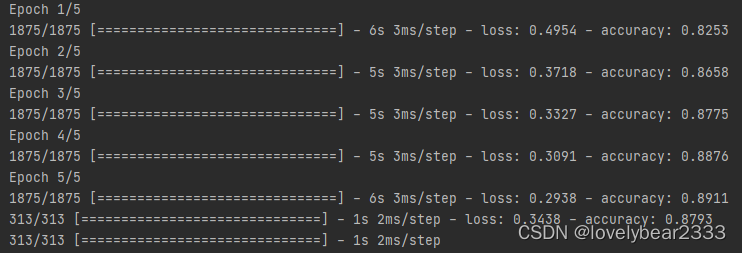
可以看到loss越来越小,精度accuracy越来越高。最下面时evaluate的输出,对应的误差及准确率,可以看到这个比训练结果的0.2938,及0.8911效果要差,为正常现象。
5 模型进行预测
#module to predict
print(model.predict(test_images/255)[0]) #输入测试集中的第一张图片,进行预测model.predict 输入一张新图片,输出预测结果。
这里输出的是10个概率值,对应这张图属于10种类别的概率值,最大概率值则对应的模型的预测结果。

这里对应的9.5131058e-01最大,则该模型预测这张图片属于第10种类别
可以利用 “print(test_lables[0]”检测测试集的第0张图片的标签是什么。

输出为9(索引值从0开始),所以模型预测正确。
总结
本代码创建了一个三层神经网络,对mnist图像数据集进行训练和检验。
网络整体结构如下所示:

可以利用model.summary()检查网络形状
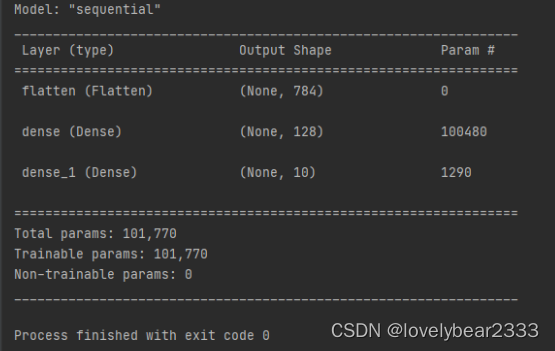
100480是输入层到隐藏层之间的突触个数
100480 : 784个像素 × 128个神经元=100352,但是因为每一层都有一个bias (自动加上去的),输入层加一个,中间层加一个,所以是(784+1)×128
1290是隐藏层到输出层之间的突触个数
1290:输出层是10个神经元,输入是128+1个,就是bias。所以是(128+1)×10=1290.