深度学习解决的核心问题之一就是自动地将简单的特征组合成更加复杂的特征,一旦解决了数据表达和特征提取,很多人工智能任务也就解决了90%。
TensorFlow计算框架可以很好地支持深度学习的各种算法,但它的应用不限于深度学习。
一、TensorFlow的主要依赖包
- Protocol Buffer
将结构化的数据(不同于大数据中的机构化数据,这里的结构化数据指的是拥有多种属性的数据)序列化,并从序列化之后的数据流中还原出原来的结构化数据。
三种常见的结构化数据处理工具对比:
1. Protocol Buffer:
name: 张三
id: 12345
email: [email protected]2. XML:
<user>
<name>张三</name>
<id>12345</id>
<email>[email protected]</email>
</user>3. JSON:
{
"name": "张三",
"id": "12345",
"email": "[email protected]",
}相比较另外两种工具,使用Protocol Buffer时需要先定义数据的格式,Protocol Buffer序列化出来的数据要比XML格式的数据小3到10倍,解析时间要快20到100倍。以下代码给出了上述用户信息样例的数据格式定义文件(存放在 .proto 文件中):
message user{
optional string name = 1; # 可以为空
required int32 id = 2; # 必须有
repeated string email =3; # 取值可以为一个列表
}- Bazel
谷歌开源的自动化构建工具,TensorFlow本身以及谷歌给出的很多官方样例都是通过Bazel来编译的。
项目空间是Bazel的一个基本概念,项目空间(workspace)包含了编译一个软件所需要的源代码以及输出编译结果的symbolic link地址,一个项目的根目录需要有一个WORKSPACE文件,此文件定义了对外部资源的依赖关系。
Bazel对Python支持的编译方式只有三种:py_binary(将Python程序编译为可执行文件)、py_library(将Python程序编译成库函数供其他调用)和py_test(编译Python测试程序)
二、TensorFlow计算模型
TensorFlow程序一般可以分为两个阶段:在第一个阶段定义计算图中所有的计算,第二个阶段执行计算。
1. 计算图
TensorFlow是一个通过计算图的形式来表达计算的编程系统,每一个计算都是计算图上的一个节点,节点之间的边描述了计算之间的依赖关系。

import tensorflow as tf
a = tf.constant([1.0,2.0],name='a')
print(a.graph is tf.get_default_graph())a.graph获得张量a所属的计算图,tf.get_default_graph函数可以获取当前线程默认的计算图,所以输出结果如下:
True
tf.Graph.device可以指定运行计算的设备:
g = tf.Graph()
# 指定计算运行的设备
with g.device('/gpu:0'):
result = a + b通过tf.Graph函数生成新的计算图,不同计算图上的张量和运算不会共享:
import tensorflow as tf
# 在计算图g1中定义变量“v”,并设置初值为0
g1 = tf.Graph()
with g1.as_default():
v = tf.get_variable("v", initializer=tf.zeros_initializer()(shape = [1]))
# 在计算图g2中定义变量“v”,并设置初值为1
g2 = tf.Graph()
with g2.as_default():
v = tf.get_variable("v", initializer=tf.ones_initializer()(shape = [1]))
# 在计算图g1中读取变量“v”的取值
with tf.Session(graph=g1) as sess:
tf.global_variables_initializer().run()
with tf.variable_scope("", reuse=True):
print(sess.run(tf.get_variable("v")))
# 在计算图g1中,变量“v”的取值应该为0,所以上面这行会输出[0.]
# 在计算图g2中读取变量“v”的取值
with tf.Session(graph=g2) as sess:
tf.global_variables_initializer().run()
with tf.variable_scope("", reuse=True):
print(sess.run(tf.get_variable("v")))
# 在计算图g2中,变量“v”的取值应该为0,所以上面这行会输出[1.]张量
张量可以简单地理解为多维数组,在张量中并没有真正保存数字,它保存的是如何得到这些数字的计算过程,TensorFlow计算的结果不是一个具体的数字,而是一个张量的结构,一个张量中主要保存了三个属性:名字(name)、维度(shape)和类型(type)
import tensorflow as tf
# tf.constant是一个计算,这个计算的结果是一个张量,保存在变量a中
a = tf.constant([1, 2], name='a', dtype=tf.float32)
b = tf.constant([2.0, 3.0], name='b')
print(a)
result = tf.add(a,b, name='add')
print(result)上述程序的运行结果为:
Tensor(“a:0”, shape=(2,), dtype=float32)
Tensor(“add:0”, shape=(2,), dtype=float32)
张量的使用:
- 对中间计算结果的引用
- 获得计算结果
通过集合(collection)来管理不同类别的资源:
通过tf.add_to_collection可以将资源加入一个或多个集合中,通过tf.get_collection获取一个集合里面的所有资源,下表给出了常用的几个自动维护的集合:
| 集合名称 | 集合内容 | 使用场景 |
|---|---|---|
| tf.GraphKeys.VARIABLES | 所有变量 | 持久化TensorFlow模型 |
| tf.GraphKeys.TRAINABLE_VARIABLES | 可学习的变量(一般指神经网络中的参数) | 模型训练、生成模型可视化内容 |
| tf.GraphKeys.SUMMARIES | 日志生成相关的张量 | TensorFlow计算可视化 |
| tf.GraphKeys.QUEUE_RUNNERS | 处理输入的QueueRunner | 输入处理 |
| tf.GraphKeys.MOVING_AVERAGE_VARIABLES | 所有计算了滑动平均值的变量 | 计算变量的滑动平均值 |
2. 会话
1.会话拥有并管理TensorFlow程序运行时的所有资源,所有计算完成之后需要关闭会话来帮助系统回收资源,TensorFlow中使用会话的模式一般有两种:
sess = tf.Session()
sess.run(xxx)
sess.close()with tf.Session as sess:
sess.run(xxx)
# 不需要再调用Session.close()来关闭会话,当上下文退出时会话关闭和资源释放也自动完成了2. TensorFlow会自动生成一个默认的计算图,但是不会自动生成默认的会话,需要手动指定,当默认的会话被指定之后可以通过tf.xxxTensor.eval函数来计算一个张量的取值(与 print(sess.run(result)) 结果相同):
sess = tf.Session()
with sess.as_default():
print(result.eval())sess = tf.Session()
print(result.eval(session = sess))3. 使用tf.InteractiveSession会自动将生成的会话注册为默认会话
sess = tf.InteractiveSession()
print(result.eval())
sess.close()4. 通过ConfigProto可以配置类似并行的线程数、GPU分配策略、运算超时时间等参数,经常用到的参数有下面这两个:
config = tf.ConfigProto(allow_soft_placement = True, log_device_placement = True)
sess1 = tf.InteractiveSession(config = config)
sess2 = tf.Session(config = config)(1) 其中allow_soft_placement为True时,以下任意一个条件成立时,GPU上的运算可以放到CPU上运行(一般是为了增强代码的可移植性):
- 运算无法在GPU上运行
- 没有GPU资源(在GPU只有一个的情况下运算被指定在第二个GPU上运行)
- 运算输入包含对CPU计算结果的引用
(2) log_device_placement为True时日志中将会记录每个节点被安排在哪个设备上以方便调试,设为False可以减少日志量
三、TensorFlow实现神经网络
真实问题中,一般会从实体中抽取很多特征,每一个特征为一个维度,一个实体便被映射为高维空间中的一个点。
结合TensorFlow_PlayGround示例,我们可以发现使用神经网络解决分类问题主要可以分为以下4个步骤:
- 提取问题中实体的特征向量作为神经网络的输入
- 定义神经网络结构,并定义如何从神经网路的输入得到输出
- 通过训练数据来调整神经网络中参数的值
- 使用神经网络来预测未知的数据
全连接网络:
全连接网络: 相邻两层之间任意两个节点之间都有连接
前向传播:
前向传播:可以简单地理解为一个线性模型,这个过程主要用到的函数是tf.matmul(),其功能为实现矩阵乘法
- 在TensorFlow中,变量(tf.Variable)的作用就是保存和更新神经网络中的参数,一般使用随机数来进行变量初始化:
weights = tf.Variable(tf.random_normal([2,3],stddev=2))TensorFlow随机数生成函数:
| 函数名 | 随机数分布 | 主要参数 |
|---|---|---|
| tf.random_normal | 正态分布 | tf.random_normal(shape,mean=0.0,stddev=1.0,dtype=tf.float32) |
| tf.truncated_normal | 偏离均值不超过两个标准差的正态分布 | 同上 |
| tf.random_uniform | 均匀分布 | tf.random_uniform(shape,minval=0,maxval=None,dtype=tf.float32) |
| tf.random_gamma | Gamma分布 | tf.random_gamma(shape,alpha,beta=0,,dtype=tf.float32) |
2. 在神经网络中,偏置项(bias)通常会使用常数来设置初值:
biases = tf.Variable(tf.zeros([3]))或通过其他变量的初试值来初始化新的变量:
w2 = tf.Variable(weights.initialized_value())
w3 = tf.Variable(weights.initialized_value() * 2.0)TensorFlow常数生成函数:
| 函数名 | 样例 | 结果 |
|---|---|---|
| tf.zeros | tf.zeros([2,3],int32) | [[0,0,0],[0,0,0]] |
| tf.ones | tf.zeros([2,3],int32) | [[1,1,1],[1,1,1]] |
| tf.fill | tf.fill([2,3],9) | [[9,9,9],[9,9,9]] |
| tf.constant | tf.constant([1,2,3]) | [1,2,3] |
在TensorFlow中,一个变量的值在被使用之前,这个变量的初始化过程需要被明确地调用,变量是特殊的张量:
import tensorflow as tf
# 设定随机种子,保证每次运行得到的结果一样
w1 = tf.Variable(tf.random_normal((2,3),stddev=1,seed=1))
w2 = tf.Variable(tf.random_normal((3,1),stddev=1,seed=1))
x = tf.constant([0.7,0.9])
# 通过前向传播算法获得神经网络的输出
a = tf.matmul(x,w1)
y = tf.matmul(a,w2)
sess = tf.Session()
# 这里不能直接通过sess.run(y)来获取y的取值,因为w1和w2都还没有运行初始化过程
# 以下两行分别初始化了w1和w2两个变量
# sess.run(w1.initializer)
# sess.run(w1.initializer)
# 当变量变多的时候上面的初始化过程就比较麻烦了,通常用下面这种调用方式
init_op = tf.global_variables_initializer()
sess.run(init_op)
print(sess.run(y))
sess.close()所有的变量都会被自动地加入到GraphKeys.VARIABLES这个集合中,通过tf.global_variables()函数可以拿到当前计算图上所有的变量,在构建机器学习模型时,可以通过变量声明函数中的trainable参数来区分需要优化的参数(比如神经网络中的参数)和其他参数(比如迭代的轮数),当trainable为True时,这个变量将会被将入到GraphKeys.TRAINABLE_VARIABLES集合,可以通过tf.trainable_variables函数得到所有需要优化的参数。
维度(shape)和类型(type)是变量最重要的两个属性,变量的类型在构建之后不能改变,但是维度可以(和reshape的更改不同):
程序示例:
import tensorflow as tf
w1 = tf.Variable(tf.random_normal([2,3],stddev=1),name="w1")
w2 = tf.Variable(tf.random_normal([2,2],stddev=1),name="w2")
# 会报错维度不匹配
tf.assign(w1,w2)
# 成功执行
tf.assign(w1,w2,validate_shape=False)四、TensorFlow训练神经网络
神经网络优化流程图如下所示:
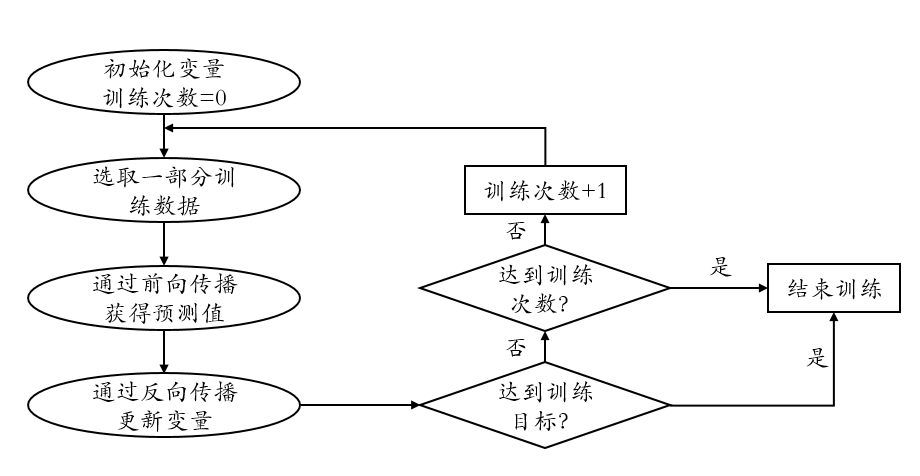
其中反向传播(back propagation)算法是神经网络优化算法中最常用的算法:
TensorFlow实现反向传播算法的第一步是使用TensorFlow表达一个batch的数据,但如果每轮迭代中选取的数据都要通过常量来表示,那么TensorFlow的计算图会非常大,为了避免这个问题,TensorFlow提供了placeholder机制用于提供输入数据,placeholder相当于定义了一个位置,这个位置中的数据在程序运行时再指定,在placeholder定义时,数据类型是需要被指定的,维度可以根据提供的数据推导得出:
import tensorflow as tf
w1= tf.Variable(tf.random_normal([2, 3], stddev=1))
w2= tf.Variable(tf.random_normal([3, 1], stddev=1))
# 定义placeholder作为存放输入数据的地方,这里维度不一定要定义
# 但是如果维度是实现确定的,这里给出维度可以降低出错概率
x = tf.placeholder(tf.float32, shape=(1, 2), name="input")
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
sess = tf.Session()
init_op = tf.global_variables_initializer()
sess.run(init_op)
# 需要提供feed_dict来指定x的值,feed_dict是一个字典
# 在字典中需要给出每个用到的placeholder的取值
print(sess.run(y, feed_dict={x: [[0.7,0.9]]}))接下来需要定义一个损失函数
这里用的是交叉熵函数 ,其中 表示真实标记的分布, 为训练后的模型的预测标记分布
来刻画当前的预测值和真实答案之间的差距,然后通过反向传播算法来调整神经网络参数的取值使得差距可以被缩小:
import tensorflow as tf
# 使用sigmoid函数将y转换为0~1之间的数值,转换后y代表预测是正样本的概率
# 1-y代表也测是负样本的概率
y = tf.sigmoid(y)
# 定义损失函数来刻画预测值与真实值的差距,y_为真实值
cross_entropy = -tf.reduce_mean(y_ * tf.log(y) + (1 - y_) * tf.log(1 - y))
# 定义学习速率
learning_rate = 0.001
# 定义反向传播算法来优化神经网络中的参数
# TensorFlow支持10种不同的优化器,比较常用的有:
# tf.train.AdamOptimizer / tf.train.GradientDescentOptimizer / tf.train.MomentumOptimizer
train_step = tf.train.AdamOptimizer(leraning_rate).minimize(cross_entropy)接下来给出一个完整的程序来训练神经网络解决二分类问题:
import tensorflow as tf
from numpy.random import RandomState
# 1.定义神经网络参数,输入和输出节点
batch_size = 8
w1= tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))
w2= tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))
# 在shape的一个维度上使用None可以方便使用不同的batch大小
x = tf.placeholder(tf.float32, shape=(None, 2), name="x-input")
y_= tf.placeholder(tf.float32, shape=(None, 1), name='y-input')
# 2.定义前向传播过程,损失函数及反向传播算法
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
y = tf.sigmoid(y)
# 定义损失函数和反向传播的算法
cross_entropy = -tf.reduce_mean(y_ * tf.log(y) + (1 - y_) * tf.log(1 - y))
train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
# 3.生成模拟数据集
# 数据集的样本是两个在0-1之间的实数,标签为0(当实数之和大于1)和1(当实数之和小于1)
rdm = RandomState(1)
dataset_size = 128
X = rdm.rand(dataset_size,2)
Y = [[int(x1+x2 < 1)] for (x1, x2) in X]
# 4.创建一个会话来运行TensorFlow程序
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
# 输出目前(未经训练)的参数取值
print(sess.run(w1))
print(sess.run(w2))
print("\n")
# 训练模型
STEPS = 5000
for i in range(STEPS):
start = (i * batch_size) % dataset_size
end = (i * batch_size) % dataset_size + batch_size
sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]})
# 每训练1000次计算交叉熵并输出
if i % 1000 == 0:
total_cross_entropy = sess.run(cross_entropy, feed_dict={x: X, y_: Y})
print("After %d training step(s), cross entropy on all data is %g" % (i, total_cross_entropy))
# 输出训练后的参数取值,与未经训练时的取值相比已经有了变化
print("\n")
print(sess.run(w1))
print(sess.run(w2))