点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
报告题目
面向文本和视觉线索联合推断的多模态上下文推理方法
内容简介
联合文本和视觉线索条件推理任务是一项复杂多模态推理任务,其中,文本线索提供与视觉内容互补的先验假设或者外部知识,对推断正确选项至关重要。虽然先前使用预训练视觉语言模型(VLM)的方法取得了令人印象深刻的表现,但这些方法存在多模态上下文推理能力的不足,尤其是在文本模态信息上,上下文推断能力较弱。为了解决这个问题,我们提出了一种名为ModCR的多模态上下文推理方法。与通过跨模态语义对齐进行推理的VLMs相比,ModCR将给定的文本抽象语义和客观图像信息视为前置上下文信息,输入到语言模型中进行上下文推理。不同于近期在自然语言处理中使用的视觉辅助语言模型 (vision-assistant language model ),ModCR通过在预训练语言模型中引入图像文本间对齐前缀 (alignment prefix embedding),成功融合了语言和视觉之间的多层次语义对齐信息。这种情形下的语言模型十分适合于联合文本和视觉线索的多模态推理场景。我们在两个相应数据集上进行了大量实验,实验结果显示与先前的模型相比,推理性能显著提高。
论文地址:https://arxiv.org/abs/2305.04530
代码地址:https://github.com/YunxinLi/Multimodal-Context-Reasoning
01
背景
跨模态推理任务是自然语言处理和计算机视觉两个领域的一个研究热点,而包括VQA,Visual Entailment在内的多数跨模态推理任务都侧重主要依赖图像信息的视觉推理场景。在这些任务中,给定的文本都与图像高度相关而缺乏外部补充信息。而在另一种更加符合实际的跨模态推理场景中,文本模态通常提供了对源图像的互补信息或先验假设,如下图中的前提所示。我们工作主要关注联合文本和视觉线索的条件推理任务,具体的任务形式则是根据给定的文本前提和图像从候选集中选择正确的选项。
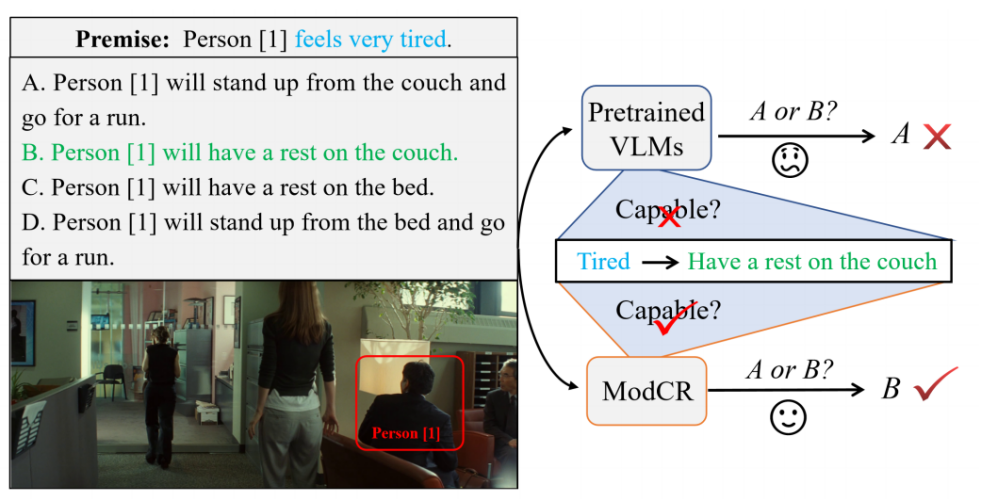
先前的方法通常将文本前提、图像和候选答案的拼接序列输入到VLM中,并使用特定任务的分类器来根据从VLM获得的联合表示来推断结果。虽然这些任务在主要基于视觉线索的推理任务中表现良好,但存在一个主要的缺点:推理过程没有充分利用给定前提文本的抽象语义信息来进行上下文推理。这是因为VLM在预训练过程中主要将不同的模态表示映射到一个统一的空间中,而忽视了基于给定的语言和视觉的多模态语义的上下文学习。然而,包括BERT, Roberta在内的预训练语言模型(PLM)具有强大的上下文学习能力,能够根据给定的抽象文本信息推断下一步的意图。
我们提出了一个名为ModCR的简单有效的多模态上下文推理方法,充分发挥了VLM和PLM的优势。具体而言,ModCR使用一个配备视觉映射网络的预训练视觉编码器来获取图像表示并将其转换为可学习的视觉前缀。视觉前缀和文本前提被视为两种类型的前文信息,输入到语言模型中以推理正确答案。考虑到在语言模型中视觉前缀和文本之间不同模态信息表示语义的差距,我们提出利用多粒度视觉语言语义对齐器来获取图像和文本之间的多视图对齐表示。随后,设计了一个对齐映射网络,以捕捉关键的对齐信息并将其转换为可学习的跨模态对齐前缀。最后,我们将这两个前缀、前提和答案馈送到语言模型中,并以指令模板槽位填充的方法执行跨模态推理。
02
方法介绍
ModCR模型中,我们首先使用视觉编码器获得图像表示,然后通过映射网络将其投影到视觉前缀中以提供客观环境信息。考虑到语言模型执行上下文学习时,前缀与文本之间的语义差距,我们设计了一个基于多粒度视觉语言语义对齐器的映射网络。最后,我们通过指令学习的方式将两种类型的前缀、前提文本和答案输入到语言模型当中。
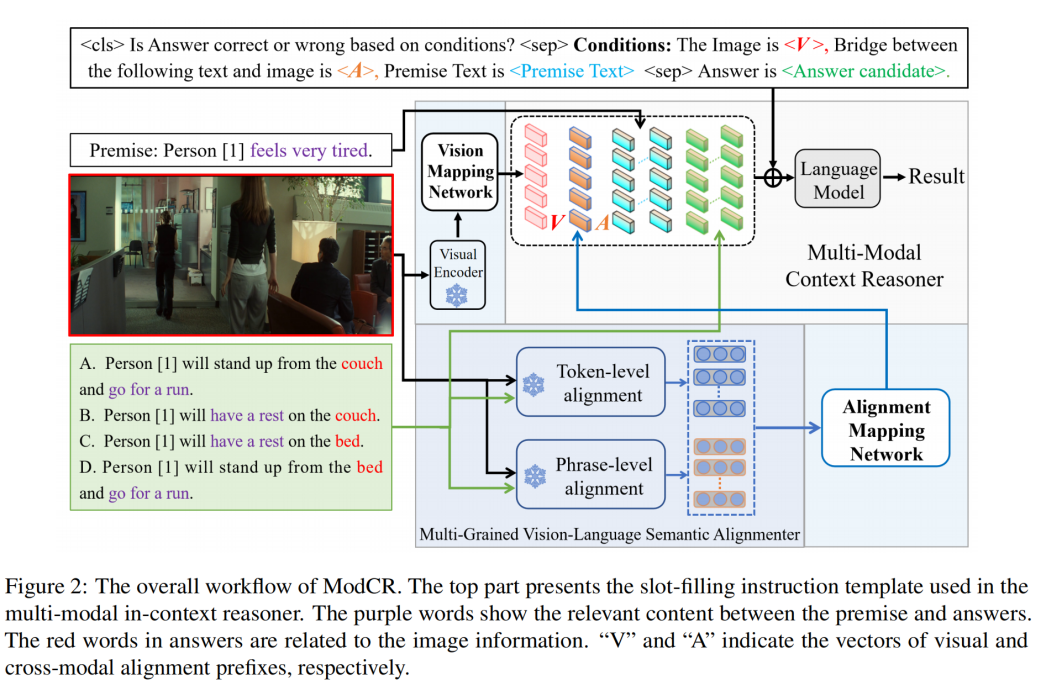
基础模型. 我们使用了预训练的单流双向编码器Oscar作为视觉编码器和多粒度视觉语言语义对齐器的基础框架。此时,图像特征首先由Faster-RCNN提取,然后输入到视觉编码器和对齐器当中。原始的Oscar模型主要实现文本和图像之间的Token级别对齐。同时我们在Flickr30k Entities上预训练了基于Oscar的块感知编码器,用于实现文本和图像之间的短语(Phrase)级别对齐。
视觉映射网络VMN. 对于视觉映射网络,我们采用了一个带有ReLU激活函数的两层感知器。它可以在大规模图像文本对上进行预训练,进而将视觉特征投影到与语言模型中的词嵌入具有相同空间分布的视觉前缀中。
对齐映射网络AWN. 对于对齐映射网络,我们首先应用一个两层的Transformer来捕获和,其中和分别表示答案文本中第i个token的token级别和phrase级别的对齐表示。第一层的计算公式如下
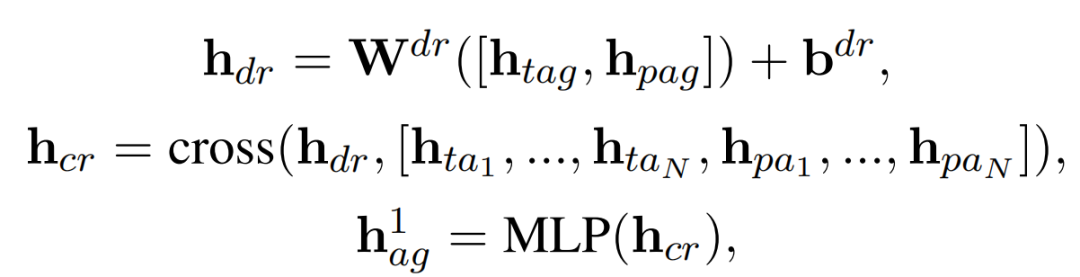
其中和为可学习参数,表示交叉注意力计算。在进行相同的两层计算后,我们得到了关键的对齐表示之后,我们通过与视觉映射网络中类似的计算过程将其投影到跨模态对齐前缀当中。
多模态上下文推理器. 在获取了两种类型的前缀之后,我们将其输入多模态上下文推理器中进行跨模态推理,我们选用了预训练的语言模型RoBERTa作为上下文推理器,同时利用指令学习的方法来进行上下文编码信息的融合。具体而言,我们将视觉前缀、对齐前缀、前提和答案候选项填充到预定义的指令模板中,模板如图中所示。通过这种方式,我们可以利用预训练语言模型的上下文学习能力来解决多模态推理问题。我们通过在RoBERTA的顶层cls隐藏层输出上应用具有ReLU函数的两层感知器来获取每个答案候选项的推断结果。
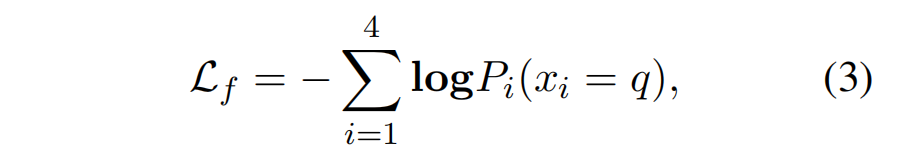
03
实验结果
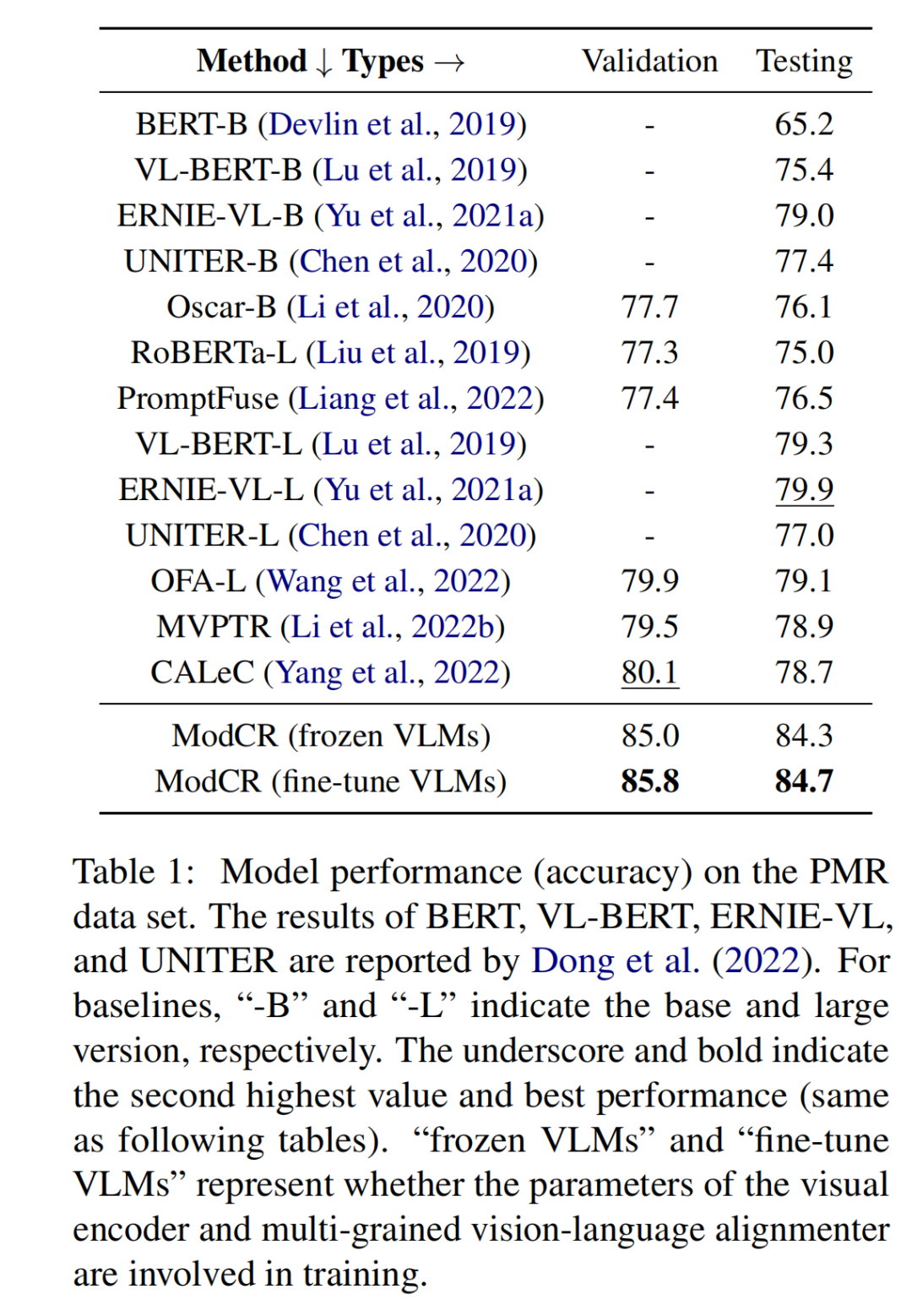
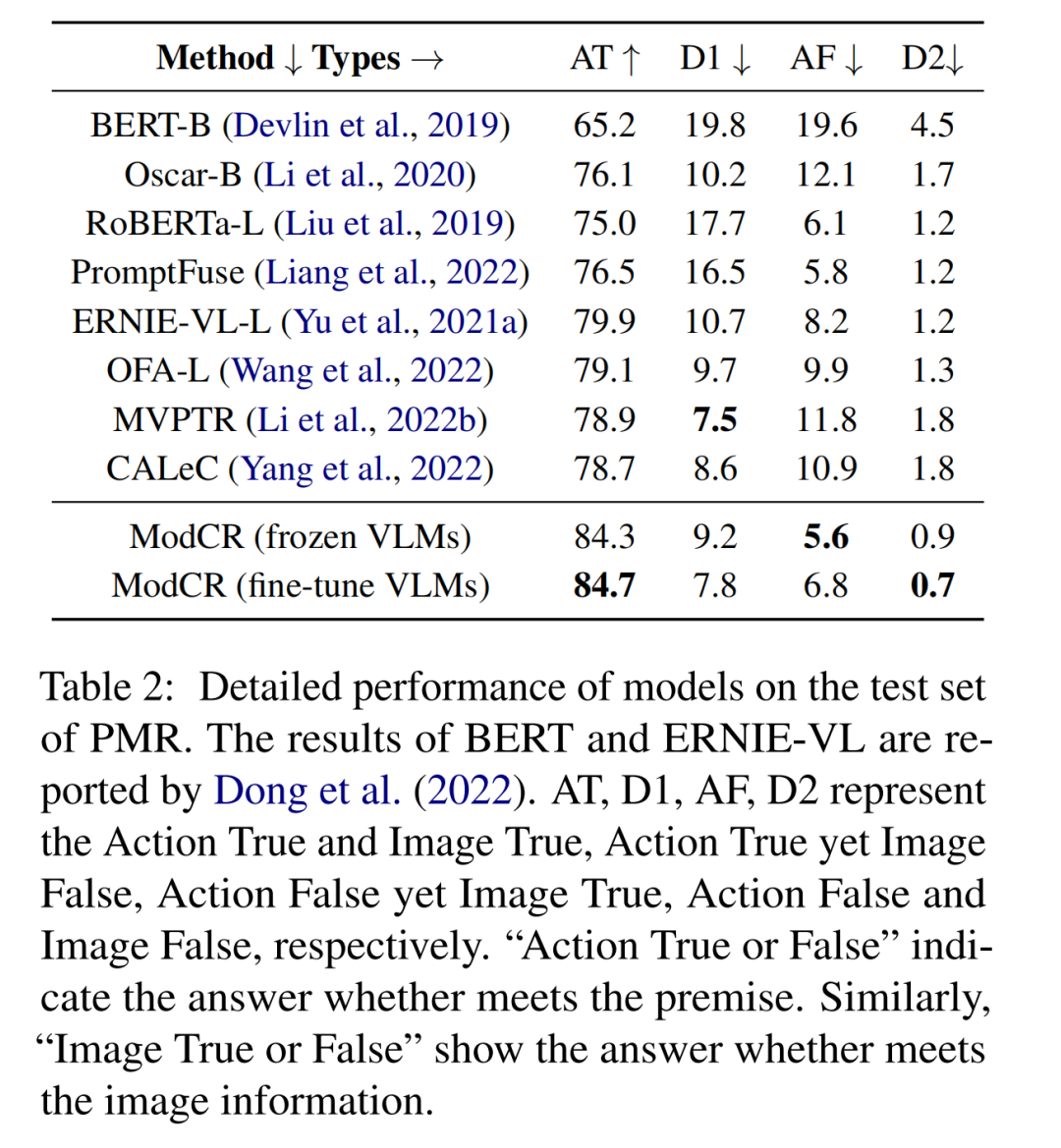
如下作图所示,模型在PMR数据集上的实验结果可表明ModCR相比其他的基准模型表现出更优异的性能。而如下右图则是ModCR模型在PMR数据集上的更加细粒度的评估,可以发现ModCR模型在利用抽象语义进行推理能力上的优异。
下图是ModCR模型在VCR数据集上的实验结果,ModCR模型相比其他基准模型在性能上同样优异。该实验结果表明,在利用外部知识方面,ModCR比直接将知识拼接到语言模型输入序列中,效果要更好一些。

同时,为了验证ModCR的有效性,我们选用PMR数据集进行了消融实验。从下左图中,我们通过比较ModCR LA=0和ModCR LA=1版本的实验结果,我们可以证明对齐映射网络的有效性;通过对比选用不同长度的视觉前缀和对齐前缀的ModCR模型,我们可以发现当两个前缀长度均为5时,ModCR模型性能最好。而下右图中,我们对比了不同训练策略对ModCR模型的影响。对比”冻结VLM”和”微调VLM”在两个数据集上的实验结果,我们可以发现微调VLM能给ModCR模型带来更好的性能。


下图中我们展示了两个样例来展示模型的性能。从图中可以看出,虽然预训练的VLM能够判断候选答案是否满足图像内容,但它们无法有效地利用前提文本信息进行推理。而ModCR模型能够利用双模态的语义信息来推理出正确答案。

04
结论
在本文中,我们提出了一种名为ModCR的多模态上下文推理方法,用于联合视觉和文本线索的条件推理场景。ModCR将给定的图像和文本视为两种不同的前缀,并且通过指令学习的方法输入到语言模型当中以进行多模态推理。两个数据集上的实验结果显示了ModCR的有效性。
未来,我们将继续探索两个研究方向:1.如何提高预训练视觉语言模型的上下文学习能力,多模态大模型应具备的能力。2.探索复杂视觉和文本线索的条件推理,其中包含多个模态的多个线索。
所提出的ModCR扔有一些局限性,如下:
1) 当前方法在文本线索和图像的跨模态场景中实现了强大的上下文推理性能,但在包含多个文本和视觉线索的场景中的上下文推理能力仍然需要进一步探讨。
2) 从实验结果中,我们观察到视觉前缀的长度极大地影响了融入视觉信息的语言模型的稳定性。因此,我们仍需要探索用于自然语言处理和多模态场景的有效且稳定的视觉辅助语言模型。
3) 我们还希望这项工作能够激发更多关于改进预训练视觉语言模型的长上下文推理能力的研究,即迈向大视觉语言模型。
提
醒
点击“阅读原文”跳转至00:41:05
可以查看回放哦!
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1300多位海内外讲者,举办了逾600场活动,超600万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!