PageRank算法
PageRank算法总的来说就是预先给每个网页一个PR值(下面用PR值指代PageRank值),由于PR值物理意义上为一个网页被访问概率,所以一般是 ,其中N为网页总数。另外,一般情况下,所有网页的PR值的总和为1。如果不为1的话也不是不行,最后算出来的不同网页之间PR值的大小关系仍然是正确的,只是不能直接地反映概率了。
所以PageRank算法实际上就是预先给定PR值后,通过每个网页之间的链接关系不断迭代,直至达到平稳分布为止。
各个网页的PR值之间的关系一般情况下表示为如下的式子:
其中 是所有对 网页有出链的网页集合; 是网页的出链数目; 是网页总数; 是阻尼系数,即用户离开当前网页重新输入网址访问的概率,一般取0.85。
根据这一关系不断迭代,当算法收敛的时候,得到的PR值即使每个网页的PR排序值。
算法实现
digraph类
由于一个搜索引擎中的网页数不胜数,使用一个矩阵存储各个网页之间的链接关系是不可能的,这里采用有向图类来优化稀疏矩阵的存储。
- 类的方法一览表
| 名字 | 参数 | 说明 |
|---|---|---|
| init_nodes | self, nodes | 初始化向图图的节点 |
| init_edges | self, edges | 初始化向图图的边 |
| add_edge | self, edge | 增加向图图中的边 |
| neighbors | self, node | 返回参数节点的所有后继节点 |
| incidents | self, node | 返回参数节点的所有前驱节点 |
- digraph类源代码
class digraph:
def init_nodes(self, nodes):
self.nodes = nodes
self.edges = []
for node in nodes:
self.edges.append([node, [], []])
def init_edges(self, edges):
for edge in edges:
self.add_edge(edge)
def add_edge(self, edge):
for edgeTmp in self.edges:
if edgeTmp[0] == edge[0]:
edgeTmp[2].append(edge[1])
if edgeTmp[0] == edge[1]:
edgeTmp[1].append(edge[0])
def neighbors(self, node):
neighbors = []
for nodeTmp in self.edges:
if node == nodeTmp[0]:
neighbors = nodeTmp[2]
break
return neighbors
def incidents(self, node):
incidents = []
for nodeTmp in self.edges:
if node == nodeTmp[0]:
incidents = nodeTmp[1]
break
return incidentsPRIterator类
PRIterator类是用来迭代计算PR值的类,由一个有向图和一个阻尼系数构造,阻尼系数即公式中的α。默认的最大迭代次数是100,确定迭代是否结束,即PR值是否收敛的参数为0.00001,即ϵ。
只有一个方法——page_rank方法,来迭代计算PR值直至收敛。同时如果一个节点没有任何的后继节点,那么相当于所有的节点都是它的后继节点,即一个网页没有出链的情况下,下一秒访问任何网页的概率都是相等的。
- PRIterator类源代码
class PRIterator:
__doc__ = '''计算一张图中的PR值'''
def __init__(self, dg, damping_factor):
self.damping_factor = damping_factor # 阻尼系数,即α
self.max_iterations = 100 # 最大迭代次数
self.min_delta = 0.00001 # 确定迭代是否结束的参数,即ϵ
self.graph = dg
def page_rank(self):
# 先将图中没有出链的节点改为对所有节点都有出链
for node in self.graph.nodes:
if len(self.graph.neighbors(node)) == 0:
for node2 in self.graph.nodes:
self.graph.add_edge((node, node2))
nodes = self.graph.nodes
graph_size = len(nodes)
if graph_size == 0:
return {}
page_rank = dict.fromkeys(nodes, 1.0 / graph_size) # 给每个节点赋予初始的PR值
damping_value = (1.0 - self.damping_factor) / graph_size # 公式中的(1−α)/N部分
flag = False
for i in range(self.max_iterations):
change = 0
for node in nodes:
rank = 0
for incident_page in self.graph.incidents(node): # 遍历所有"入射"的页面
rank += self.damping_factor * (page_rank[incident_page] / len(self.graph.neighbors(incident_page)))
rank += damping_value
change += abs(page_rank[node] - rank) # 绝对值
page_rank[node] = rank
print("This is NO.%s iteration" % (i + 1))
if change < self.min_delta:
flag = True
break
if flag:
print("finished in %s iterations!" % node)
else:
print("finished out of 100 iterations!")
return page_rank主函数
主函数的作用就是读取网页的链接数据,初始化有向图,迭代计算PR值直至收敛,最后输出计算结果。
测试的数据为维基百科网站上所有网页的链接数据,由于数据共有103689条,这里不再给出详细数据,文末附有数据集及源码,可执行文件下载链接。这里给出一部分样例的截图如下。数据格式为:网页ID——链接到的网页ID。

在主程序中,需要输入测试数据的路径和阻尼系数。运行结果如下图。
- 主程序源代码
if __name__ == '__main__':
# python NewPageRankDemo.py
# 输入数据和输出结果所在的文件夹位置
directory = input('输入数据和输出结果所在的文件夹位置:\n示例输入:C:\\Users\\37618\\Desktop\\PageRank\\\n')
damping_factor = input('输入阻尼系数α(一般取0.85):\n')
damping_factor = float(damping_factor)
# 储存训练样本数据
f = open(directory + 'WikiData.txt')
nodes = []
edges = []
for v in f:
tmp = v.split("\t")
tmp[1] = tmp[1].split("\n")[0]
if nodes.count(tmp[0]) == 0:
nodes.append(tmp[0])
if nodes.count(tmp[1]) == 0:
nodes.append(tmp[1])
edges.append((tmp[0], tmp[1]))
# 输出预测结果
import sys
output = sys.stdout
outputfile = open(directory + 'result(' +str(damping_factor)+ ').txt', 'w')
sys.stdout = outputfile
dg = digraph()
dg.init_nodes(nodes)
dg.init_edges(edges)
pr = PRIterator(dg, damping_factor)
page_ranks = pr.page_rank()
print("The final page rank is\n")
for page_rank in page_ranks:
print(page_rank, ' ', page_ranks.get(page_rank))
outputfile.close()
sys.stdout = output示例输出如下图。
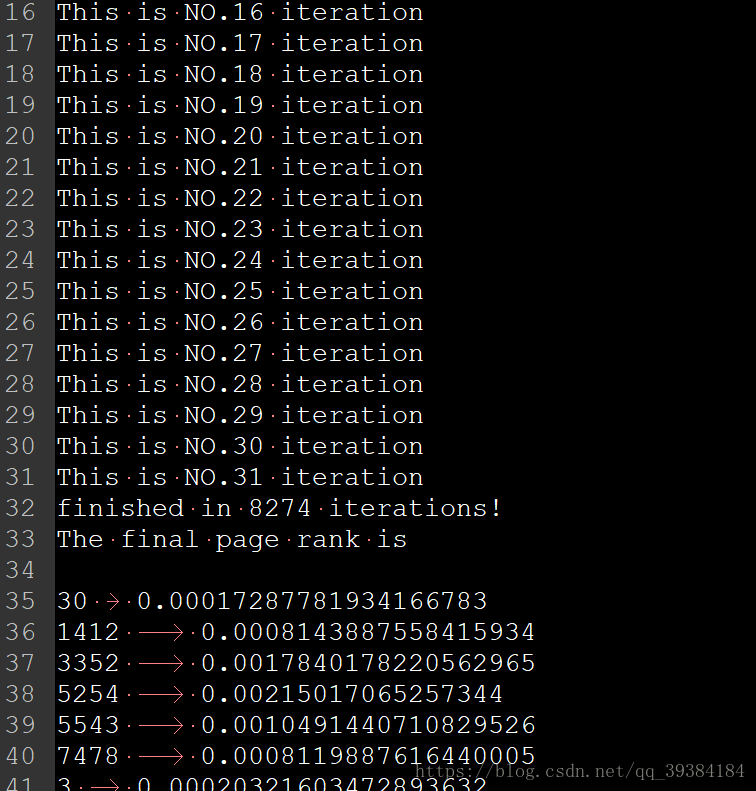
可以看到,程序在31次迭代后在ID为8274的网页处收敛,并输出了所有网页的PR值。