目录

前言
我们平时在MySQL已经可以直接使用like查询了,为啥还要一个倒排索引的东西?
我们用下面来说明下,假设有一本书,相应页码存储的文章内容如下
| 页码 | 内容 |
|---|---|
| 1 | 生命在于运动 |
| 2 | 运动是生命的源泉 |
| 3 | 日复一日地坚持练下去吧,只有活动适量才能保持训练的热情和提高运动的技能.——塞涅卡 |
| 4 | 活动是生活的基础!——歌德 |
| 5 | 人的健全,不但靠饮食,尤靠运动 |
| 6 | 奥林匹克的格言是“更高,更快,更强” |
| 7 | 身体的健康因静止不动而破坏,因运动练习而长期保持.——苏格拉底 |
| 8 | chenqionghe喜欢运动,绳命是如此的精彩,绳命是如此的辉煌 |
书有N篇文章,要在一本书中找出有“运动”的文章,只能去一页页的翻书,看哪一页有,书越厚,你找的时间越久(这其实也是MySQL中的全表扫描)
针对这样的内容检索场景,倒排索引就派上用场了
一、倒排索引的原理
倒排索引是怎么提高检索速度的,其实是相当于创建了关键词目录,记录有哪些文档包含了某个单词,如下
| 关键词 | 页码 |
|---|---|
| 运动 | 1,2,5,8 |
| 活动 | 3,4 |
| 生命 | 1,2 |
| chenqionghe | 8 |
当我们要搜索找到有运动的文章时,会先去关键词目录找,找到了都在1,2,5,8这几页,然后直接把书翻到这些页就能获取到相应的内容了。
然后如果我们要搜索“运动生命”,得先把这个内容分成运动和生命,再去目录分别找,怎么分词,也是一种艺术。
二、倒排索引的应用
Lucene
Lucene是目前最为流行的开放源代码全文搜索引擎工具包,隶属于Apache基金会,由资深全文索引/检索专家Doug Cutting所发起,并以其妻子的中间名作为项目的名称。Lucene不是一个具有完整特征的搜索应用程序,而是一个专注于文本索引和搜索的工具包,能够为应用程序添加索引与搜索能力。
ElasticSearch
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。
Solr
Solr是一个高性能,采用Java开发,基于Lucene的全文搜索服务器,封装了很多Lucene细节,是一个有HTTP接口的基于Lucene的查询服务器,
Sphinx
Sphinx是一款基于SQL的高性能全文检索引擎,利用Sphinx我们可以完成比数据库本身更专业的搜索功能,而且可以有很多针对性的性能优化。
另外其实MySQL的的全文索引也是基于倒排索引的,可以参考从零开始学习MySQL全文索引
三、倒排索引和大数据“三驾马车”的故事
倒排索引是对互联网内容的一种索引方法,例如我们使用百度或者谷歌,就是使用搜索词搜索到对应的互联网文档。
说到大数据,我们想到的是“三驾马车”,而这“三驾马车”最早提出是在2003年。
1.海量内容存储
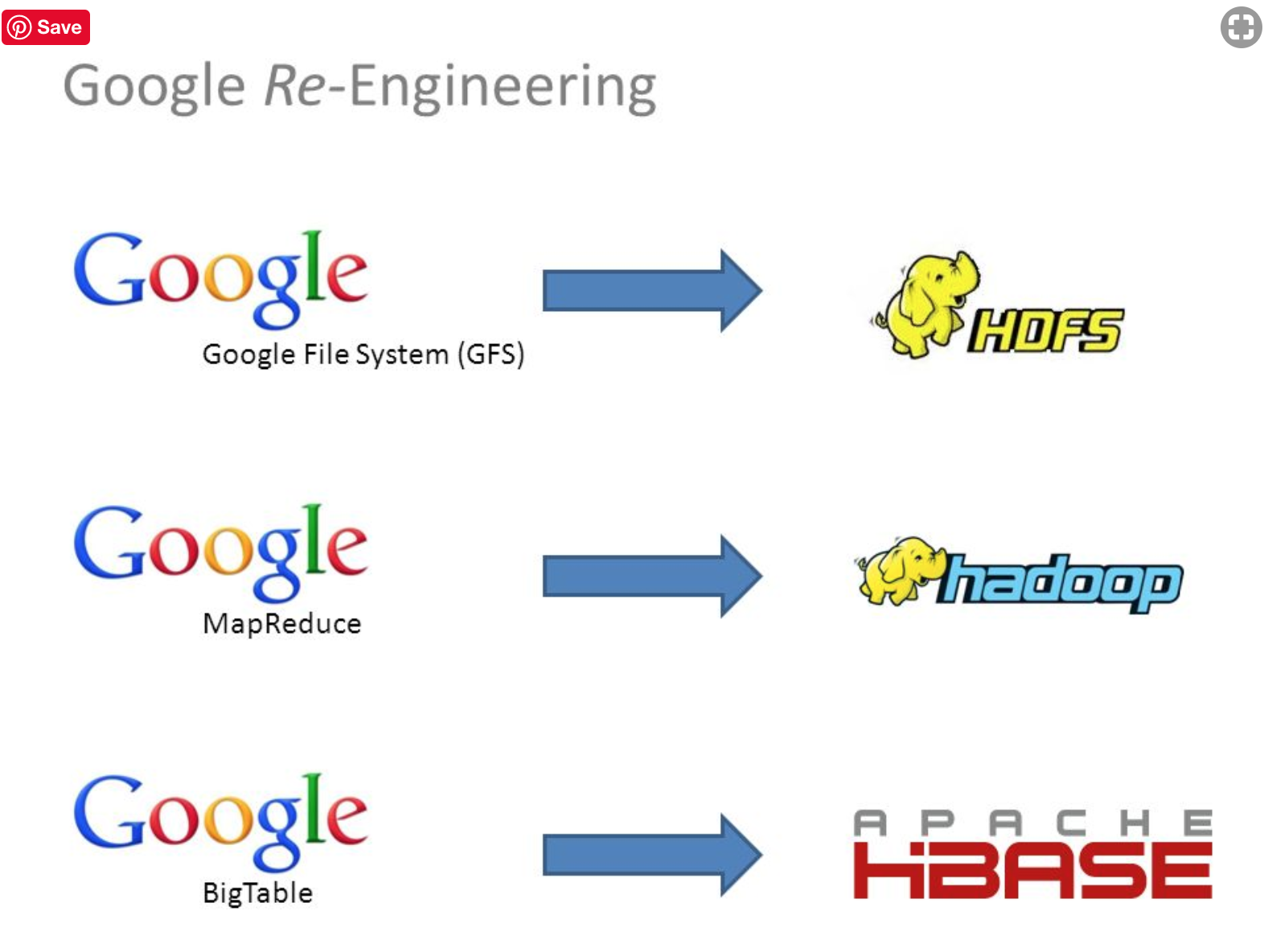
为了构建倒排索引,谷歌需要存储整个互联网的内容,并存储构建倒排索引所需要的内容,在以前的技术条件,世界上没有现成的产品可以实现这种规模的倒排索引。所以,谷歌发明了谷歌文件系统,基于大量的廉价计算机构建的海量存储系统,对应“三驾马车”的分布式存储系统GFS。
2.海量数据计算框架
为了从这个GFS中读取数据,需要一个牛逼的计算框架,这就是“三驾马车”中的MapReduce。
3.超级大表
虽然两驾马车已经可以实现存储互联网这种海量数据,但是互联网的内容变化太快,这种系统没办法做到增量更新。
这时候,第三驾马车BigTable出来了,一个Key-Value存储系统,可以存储多个版本的值,对应的开源产品是HBase。
通过这“三驾马车”,谷歌具备了存储和分析海量数据的能力,再通过个性化广告系统不断地吸金,走在了时代的前沿。当时还没有任何一个公司能在大数据这个领域赶上谷歌,谷歌这个技术也没有开源。
这“三驾马车”也是云计算机的重要的一大组成。
后来Hadoop出现了,出现了“三驾马车”的开源产品,HDFS、MapReduce、HBase。各个公司开始基于Hadoop生态构建出了自己的大数据平台,谷歌渐渐失去了在大数据时代的先发优势。
四、倒排索引和排序算法PageRank

有了倒排索引,我们可以快速得到了搜索结果,但是怎么决定搜索的优先级?这时候就用到了一种叫PageRank的算法,计算机网页的权重,按照权重进行排序,权重越高排得越靠前
关于PageRank的原理可以参考从小白视角理解
<数据挖掘十大算法>
数据的搜索与查找是计算机软件的核心算法,对海量文档进行快速检索,主要使用的就是倒排索引技术,大道至简,就是这么简单,惊不惊喜,意不意外