
论文链接:https://openreview.net/pdf?id=dUV91uaXm3
代码链接:无
1. 动机
近年来,基于Transformer的模型在视觉和语言领域都出现过平滑现象(其实就是输入的token之间越来越相似,这与论文《Vision Transformers with Patch Diversification》动机相似)。然而,目前还没有深入研究这一现象的主要原因。本文试图从图的角度分析过平滑问题。
2. 方法
将self-attention中的亲和矩阵看作是图的归一化邻接矩阵。基于这一联系,进行一些理论分析,发现层归一化对基于Transformer模型的过平滑问题起着关键作用。具体来说,如果层归一化的标准差足够大,Transformer堆的输出将收敛到特定的低秩子空间,导致过平滑。为了缓解过度平滑的问题,本文考虑了分层融合策略,将不同层次的表示自适应地组合在一起,使输出更加多样化。
- BERT模型存在过平滑吗?
使用 token-wise cosine similarity对token进行相似性度量:
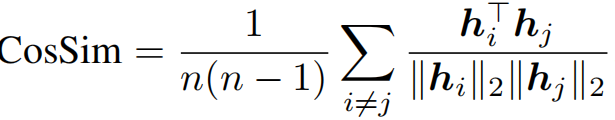
如下图1(a)所示,模型越深,相似度越大,即过平滑问题越严重
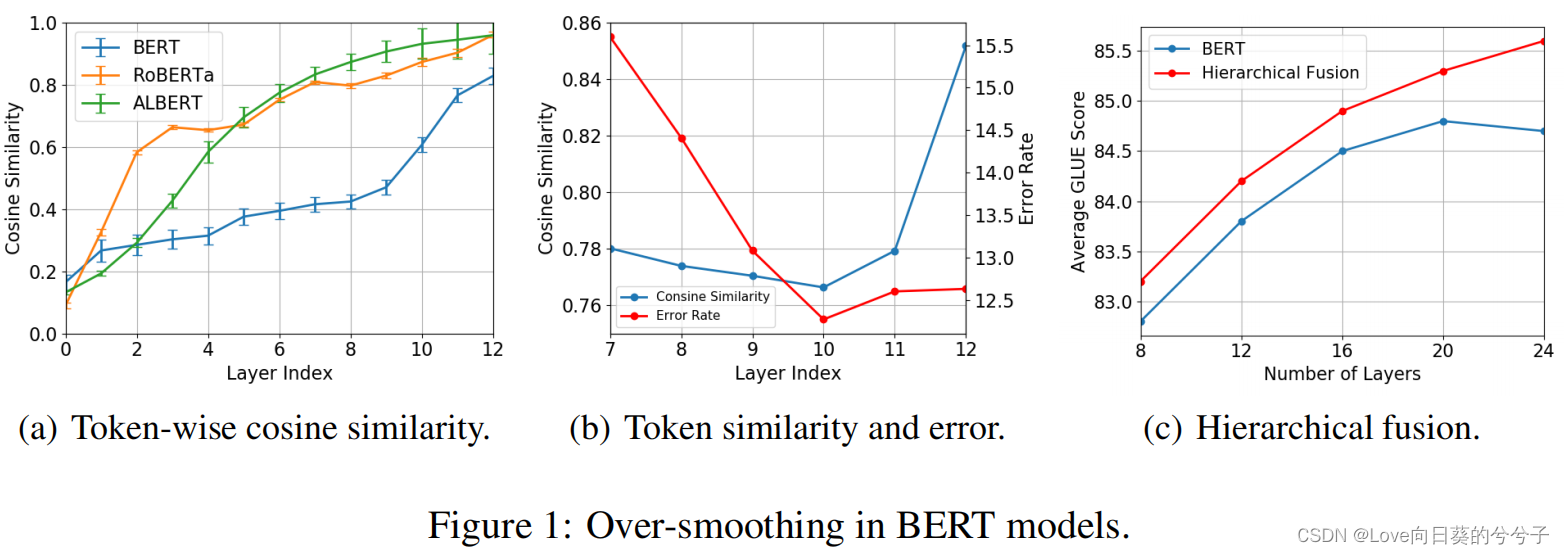
注意:over-thinking现象,即浅表征优于深表征。为了说明over-thinking和over-smoothing之间的关系,如图1(b)所示,将每一层的标记方向余弦相似度与相应的错误率进行比较,对于第i层对应的错误率,我们使用第i层的表示作为最终输出,并对分类器进行微调。可以发现第10层余弦相似度和错误率最低。在第11层和第12层,token具有更大的余弦相似性,使它们更难区分,并导致性能下降。因此,over-thinking可以用over-smoothing来解释。 - self-attention与graph的关系
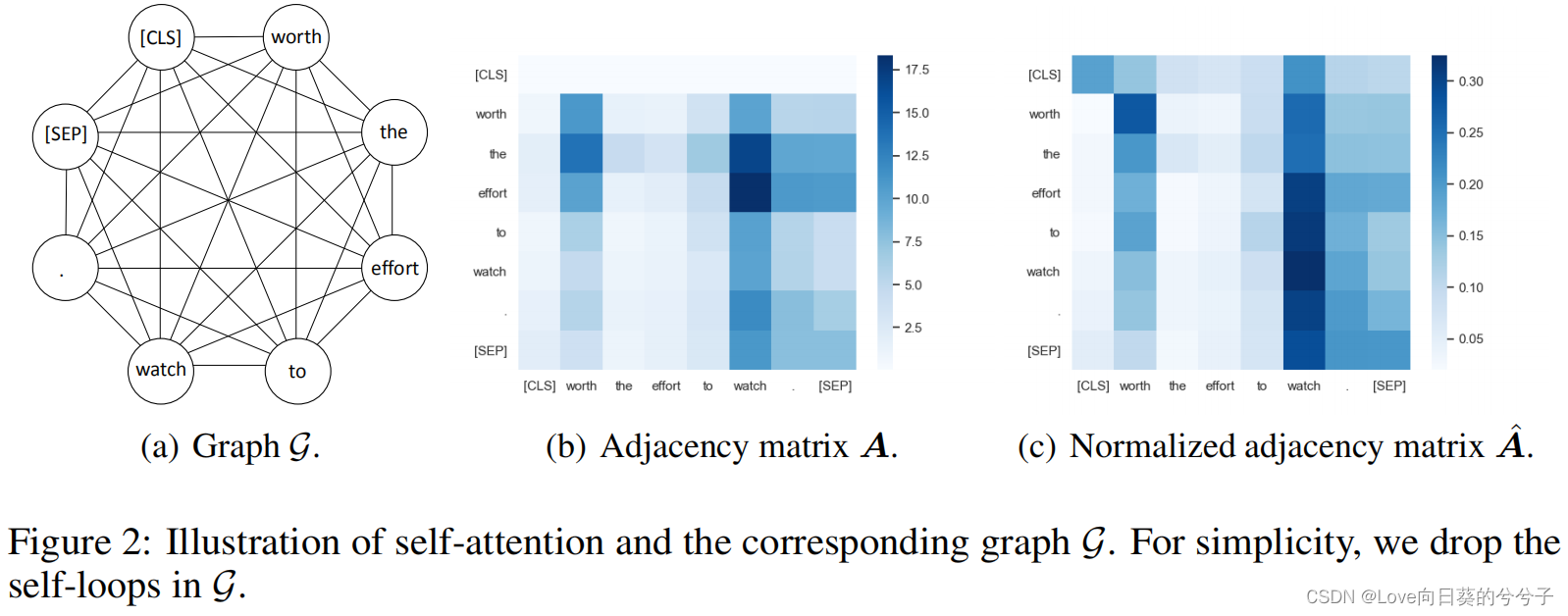
Transformer模型输入的每个token相当于图中的节点,attention矩阵就是邻接矩阵A.
1)attention
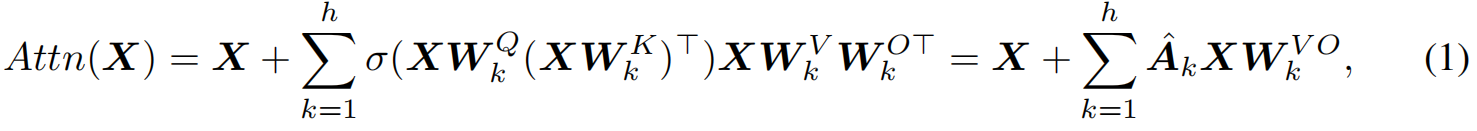
2)ResGCN
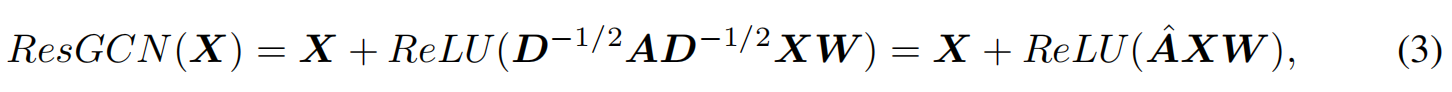
两个形式相似!!! - 分层融合策略
1)Concat Fusion:一种简单而直接的分层Concat Fusion方法。由于该方案需要保存来自所有层的特征图,随着模型的深入,内存开销将非常大;
2)Max Fusion:受广泛采用的max-pooling机制思想的启发,我们通过为表示的每个维度取所有层的最大值来构造最终的输出。最大融合是一种自适应的融合机制,它可以动态地确定表示中每个元素的重要层。Max Fusion是最灵活的策略,因为它不需要学习任何额外的参数,在速度和内存方面更有效。
3)Gate Fusion:Gate机制是自然语言处理领域常用的信息传播机制。为了利用不同语义层次的优势,我们提出了一种垂直门融合模块,该模块预测不同层次的token-wise表示的各自重要性,并自适应地对它们进行聚合。
3. 部分实验结果
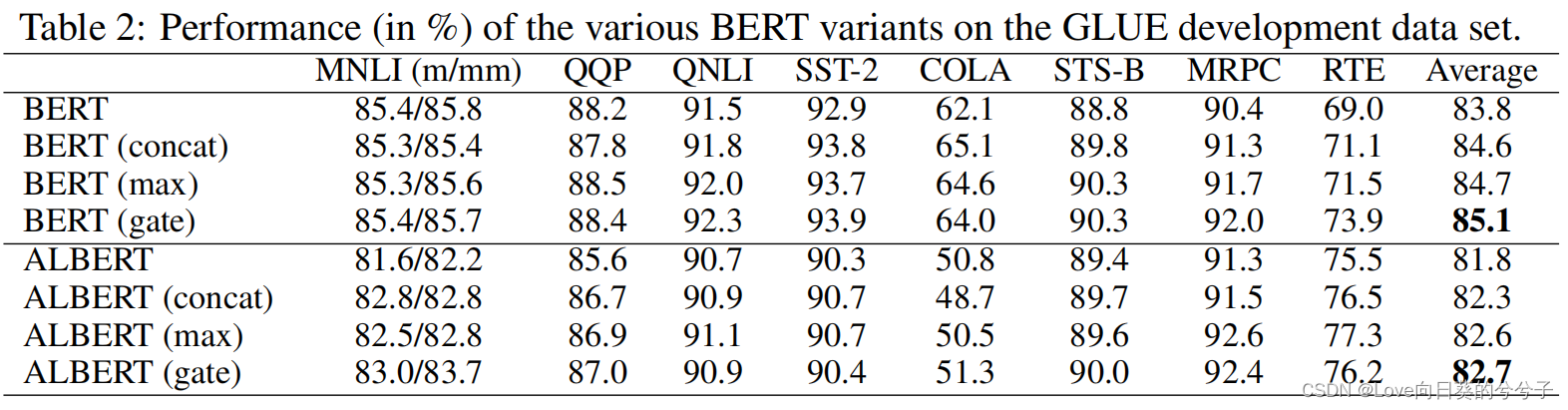
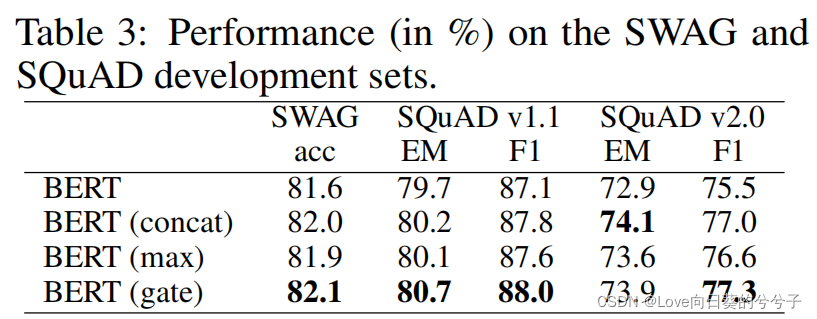
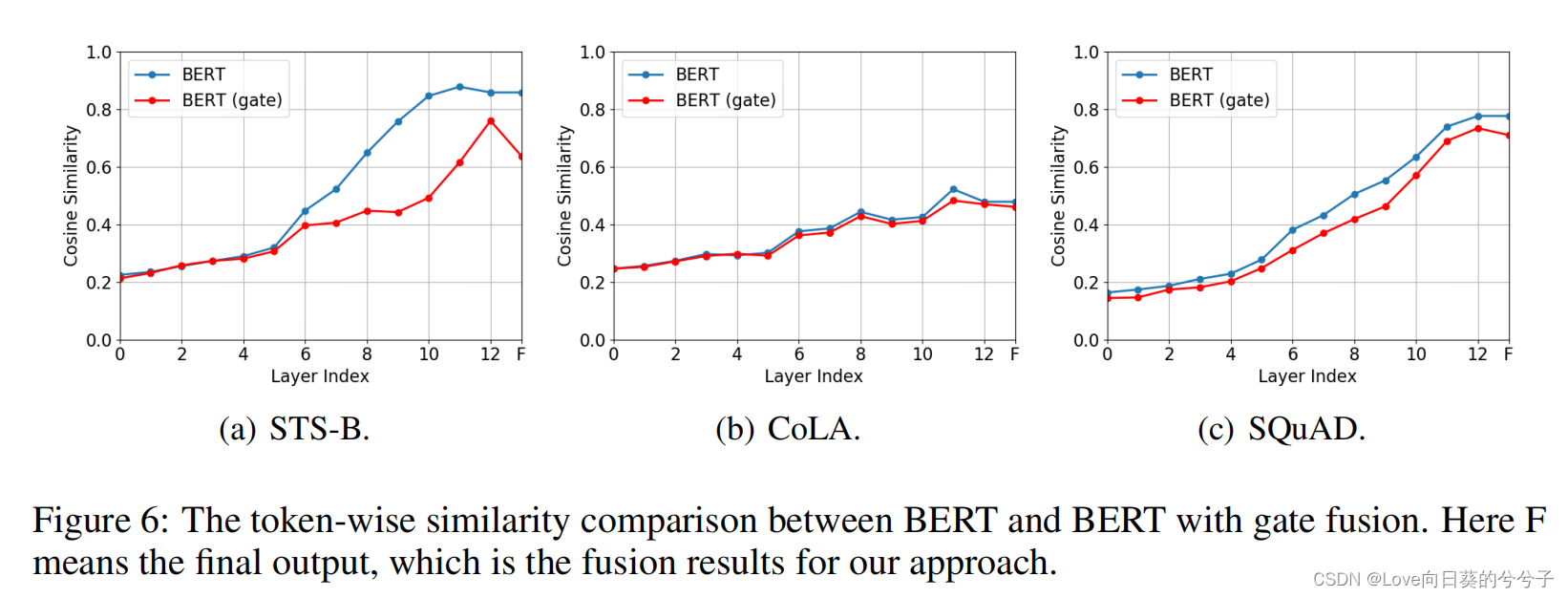
4. 结论
1)在本文中,重新讨论BERT模型中的过平滑问题。
2)为了缓解过度平滑的问题,提出了一种分层融合策略,自适应地结合不同层次的表示。