本文就是将一组图像映射到文本embedding中,映射的目标可能是一组新词,再通过新词引导文生图模型生成相应概念的图像,和dreambooth有些相似,但是dreambooth约束性要更强一些。
1.abstract
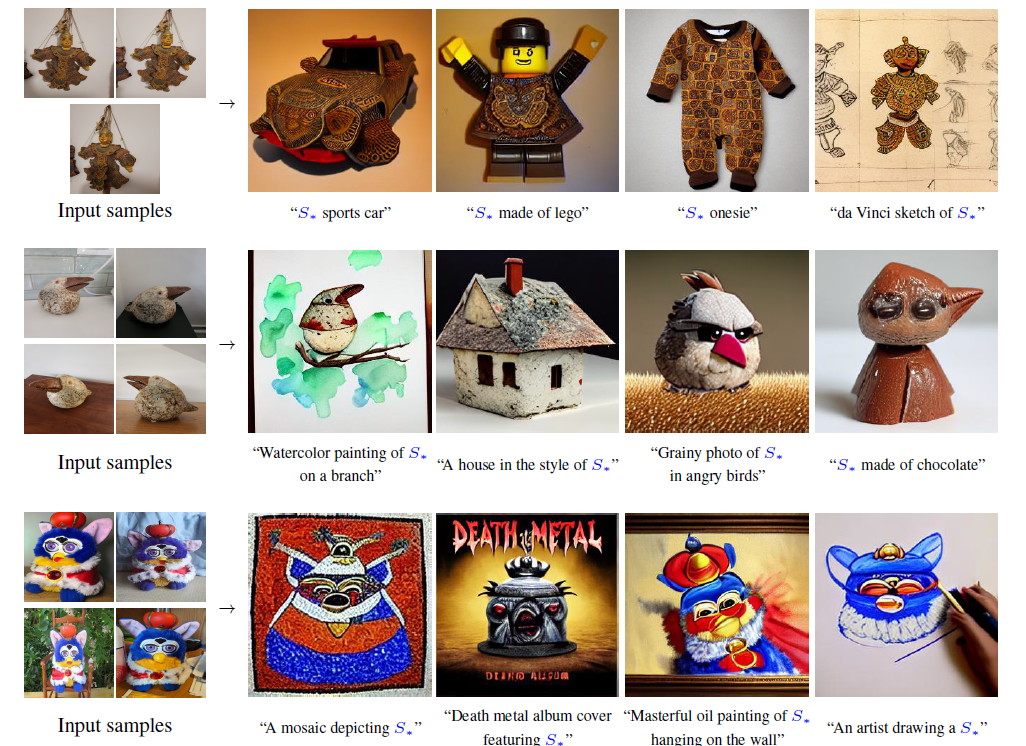
仅使用用户提供的概念(如对象和风格)的3-5张图像,通过冻结的文本到图像模型的嵌入空间中的新词来学习代表它。单个词的embedding足以捕捉独特且多样的概念。
2.introduction
在大模型中引入新概念通常很困难,为每个新概念重新训练一个模型的数据集成本太高,并且在少量数据上进行微调通常会导致灾难性的遗忘。

用一个伪字来表示一个新的embedding,用S表示,这个伪字可以被视为任何其他单词,用来生成相应概念。为了找到这些伪字,提出了一个固定的预训练文本到图像模型和一组包含该概念的少量图像(3-5张图),目标是找到一个单词嵌入,使得类似 a photo of S的句子能够重构一组图像。这个embedding是通过文本逆推得到的。
3.Related work
基于文本,
Gan inversion. inversion:使用生成网络对图像进行操作通常需要找到给定图像的相应潜在表示,一般基于优化或者编码器来执行,优化方法直接优化一个潜在向量,使得将其通过GAN将重新创建目标图像,编码器利用大量图像训练一个将图像映射到它们潜在表示的网络。
基于扩散. inversion可以通过向图像中添加噪声,然后通过网络去噪来执行。
4.method
目标是实现基于语言的新概念的生成,将这些概念编码到预训练的文本到图像模型的中间表示中,可以利用这些模型所代表的丰富语义和视觉先验,引导概念的直观视觉表达。

Cθ通过bert文本编码器实现。

Text embedding. BERT将输入字符串中的每一个单词或者子单词转换为一个标记,token,该标记是预定义字典中的索引,然后将每个标记与一个唯一的embedding相关联,可以通过基于索引的查找来检索,这些embedding通常作为文本编码器Cθ的一部分来学习。本文选择这个embedding作为反演的目标,指定一个占位符S来表示我们希望学习的新概念,干预嵌入过程,并用一个新的学习的嵌入v替换与分词字符串相关联的向量,实质就是将这个概念注入到我们的词汇中。
Textual inversion. 为了找到这些新的嵌入,使用一小组图像(3-5张),这些图像描绘了目标概念在多个背景或姿态设置下的情况。通过直接优化来找到v,即最小化Lldm损失,随机采样中性文本背景,形如a photo of S,和ldm相同的方法训练,去噪网络和图像编码的clip权重均不变。
2个V100,bs=4.
5.Qualitatibe comparsions and application