博主志在以通俗的语言加图片来带着大家一起理解kmp算法,如有疑问,随时联系博主呦!接下来我们一起学习吧
前言
- 示范
给定一个字符串s = “abcabcabd” 另一字符串t = “abcabd”,在s中查找t是否存在,若存在返回t[0]在s中对应的首字符下标,例如本例应当返回3. - 用朴素算法实现

此算法又称BF算法,我们查找失败时通过回溯来重新查找,时间复杂度为O(nm)。但我们不难发现字符串s中元素被多次重复比较,通过第1步,我们就能知道s[2]是b, s[3]是c,s[4]是a,而t串串首元素是a,所以t串可以直接移动到第4步,第2、3步完全多余,可以省略,于是就演变出了我们的今天的主题—KMP算法
KMP算法是我们数据结构串中最难也是最重要的算法。难是因为KMP算法的代码很优美简洁干练,但里面包含着非常深的思维。真正理解代码的人可以说对KMP算法的了解已经相当深入了。而且这个算法的不少东西的确不容易讲懂,很多书本把概念一摆出直接劝退无数人。博主将尽量以最详细的方式配图介绍KMP算法及其改进。文章的开始我表示对KMP算法的三位创始人前辈致敬,懂得这个算法的流程后真的不得不佩服他们的聪明才智。

图解kmp
最后一个字符不匹配的情况
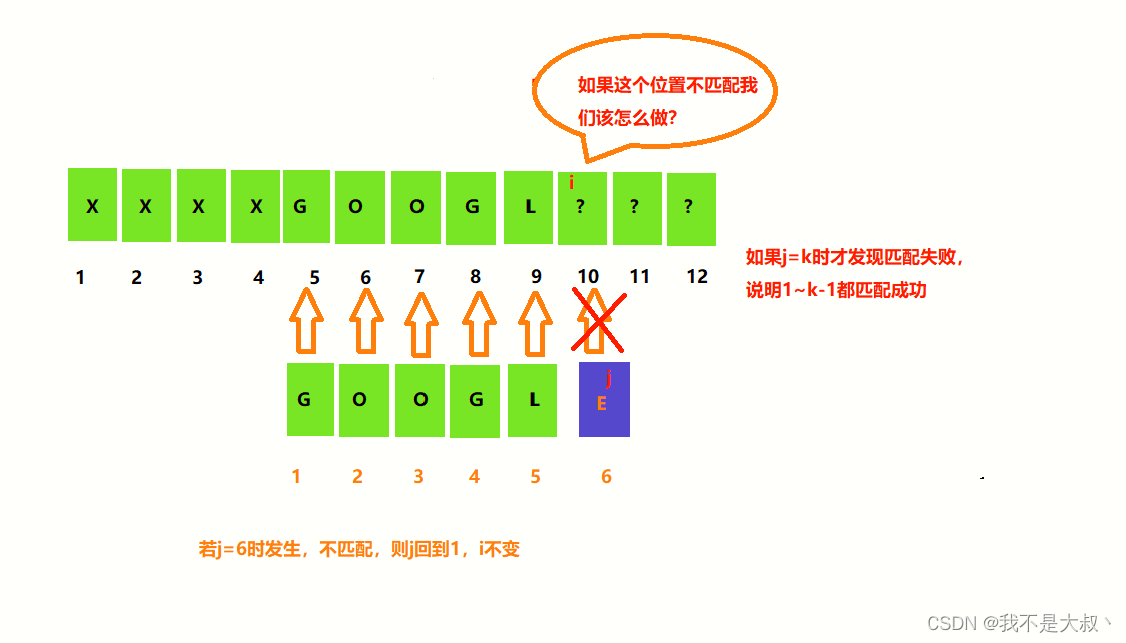
这时候我们的主串并不需要回溯,这个时候我们就只需要期待下标为10的‘?’是否等于G。如果不是,我们只需要i++,j依然指向1,然后判断j=1时是否与i++相同即可继续下一次查找。
倒数第二个字符不匹配的情况:
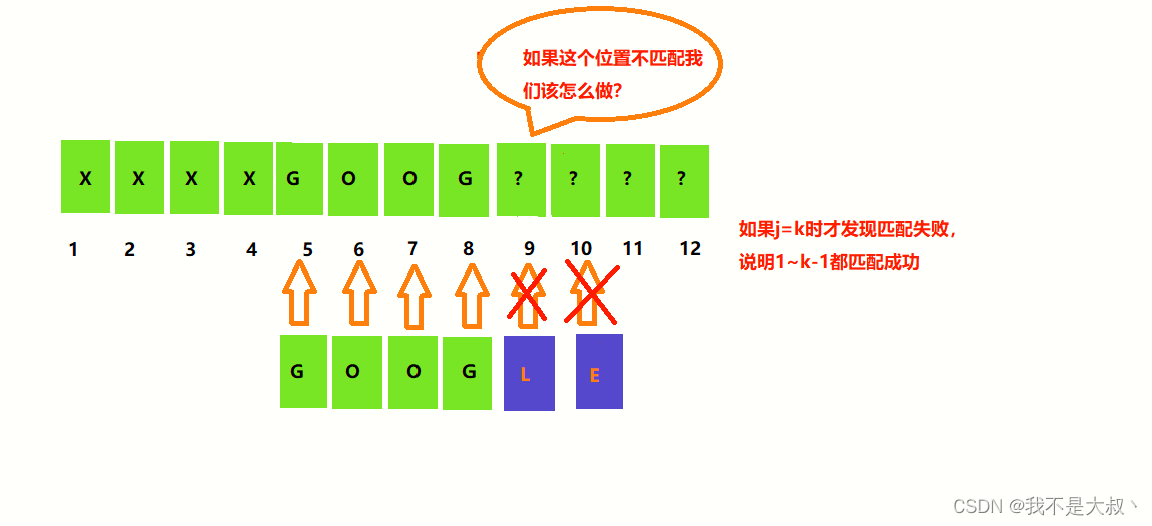
然而我们知道第五个元素不可能是我们要查找的串的首元素,同理6、7也是,当到了八的时候,又出现了可能查找成功的情况,如下:
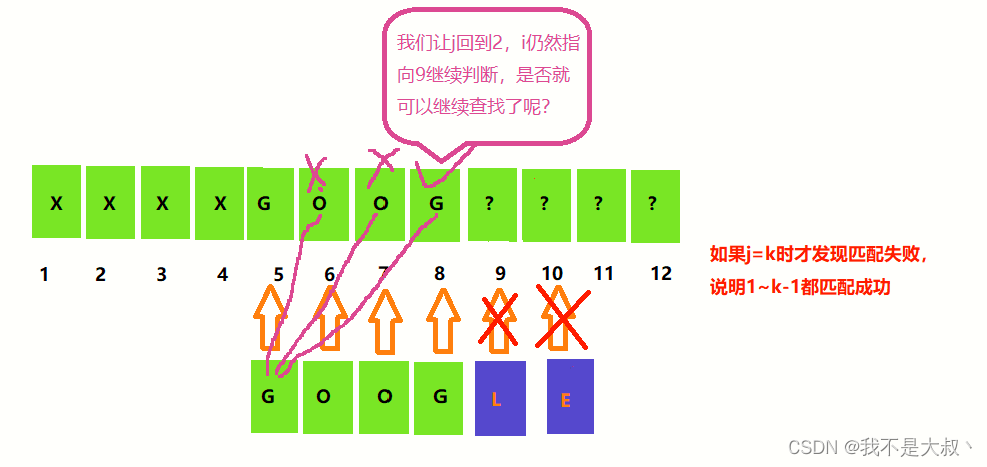
其他情况
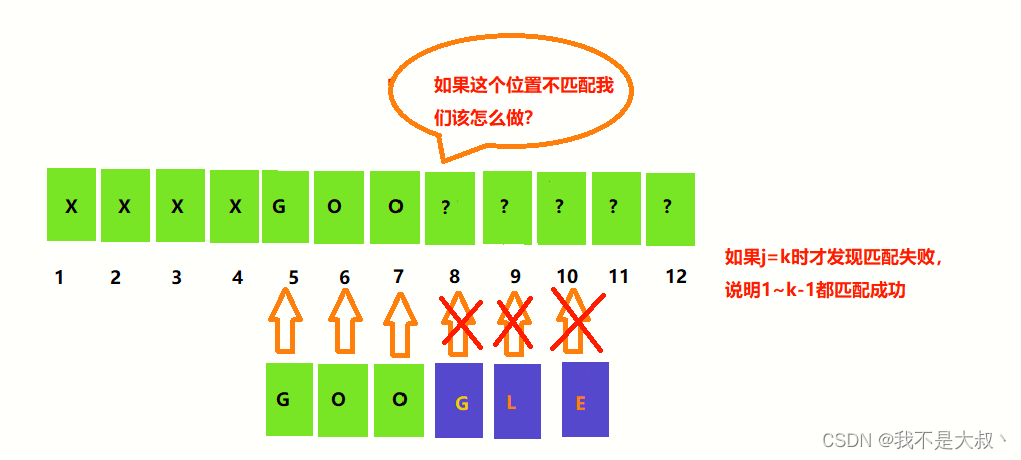
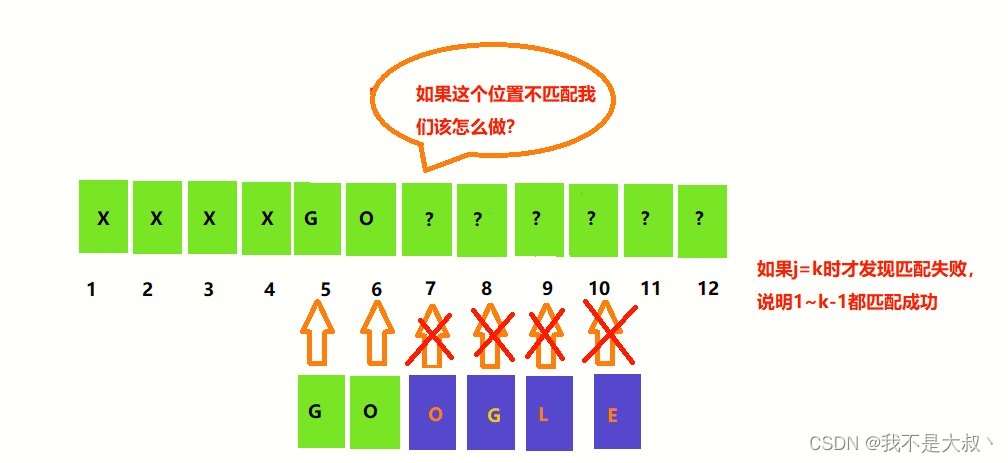
同样的第一,第二个位置不匹配也类似上述情况,我们将返回值列一个表格可得:
若当前两个字符匹配,则i++,j++
若 j=1 时发生不匹配,则应让 i++,而j依然是1
若j=2时发生不匹配,则应让j回到1
若j=3时发生不匹配,则应让j回到1
若j=4时发生不匹配,则应让j回到1
若j=5时发生不匹配,则应让j回到2
若j=6时发生不匹配,则应让j回到1
我们用next数组来保存他**(考虑数组下标是从0开始)**:int next[6]={-1,0,0,0,1,0};
我们来看具体实现过程:
int Index_KMP(SqString S, SqString T, int next[])
{
int i = 0, j = 0;
while (i < S.length && j < T.length)
{
if (j == -1 || S.data[i] == T.data[j])
{
i++;
j++;
}
else
j = next[j];
}
if (j >= T.length)
return (i - T.length);
else
return -1;
}
我们在匹配不成功时,让j=next[j];即可,当然上述next数组只是针对于我们上述特定的字符串来实现的,而next数组不是一成不变的,打起精神,我们继续看下列内容:
next数组实现
这时候问题来了,我们要实现在主串查找子串的功能又该怎么做呢?毕竟我们只是分析了上述查找“GOOGLE”这个子串,换个子串又得怎么做呢?如何去获得属于他的next数组呢?接下来我们去分析next数组如何求取。
首先我们看abcabd这种情况:
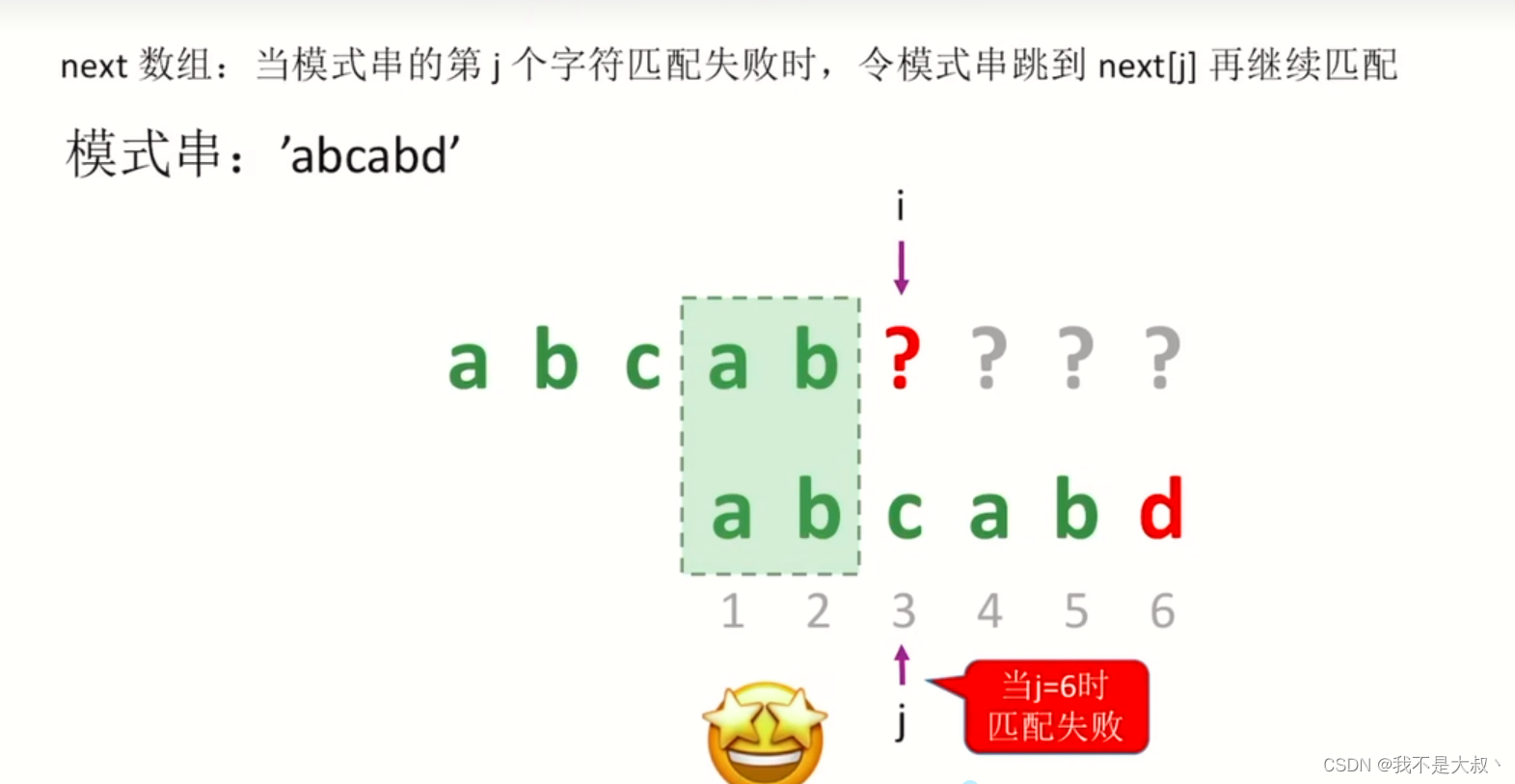
**这时候我们让next[6]=3;
在看:我们可以看到向后移两个便可继续匹配,然而如图,如果我们向后跳四个,也是可以匹配的,那我们可以取向后跳四个的情况吗?
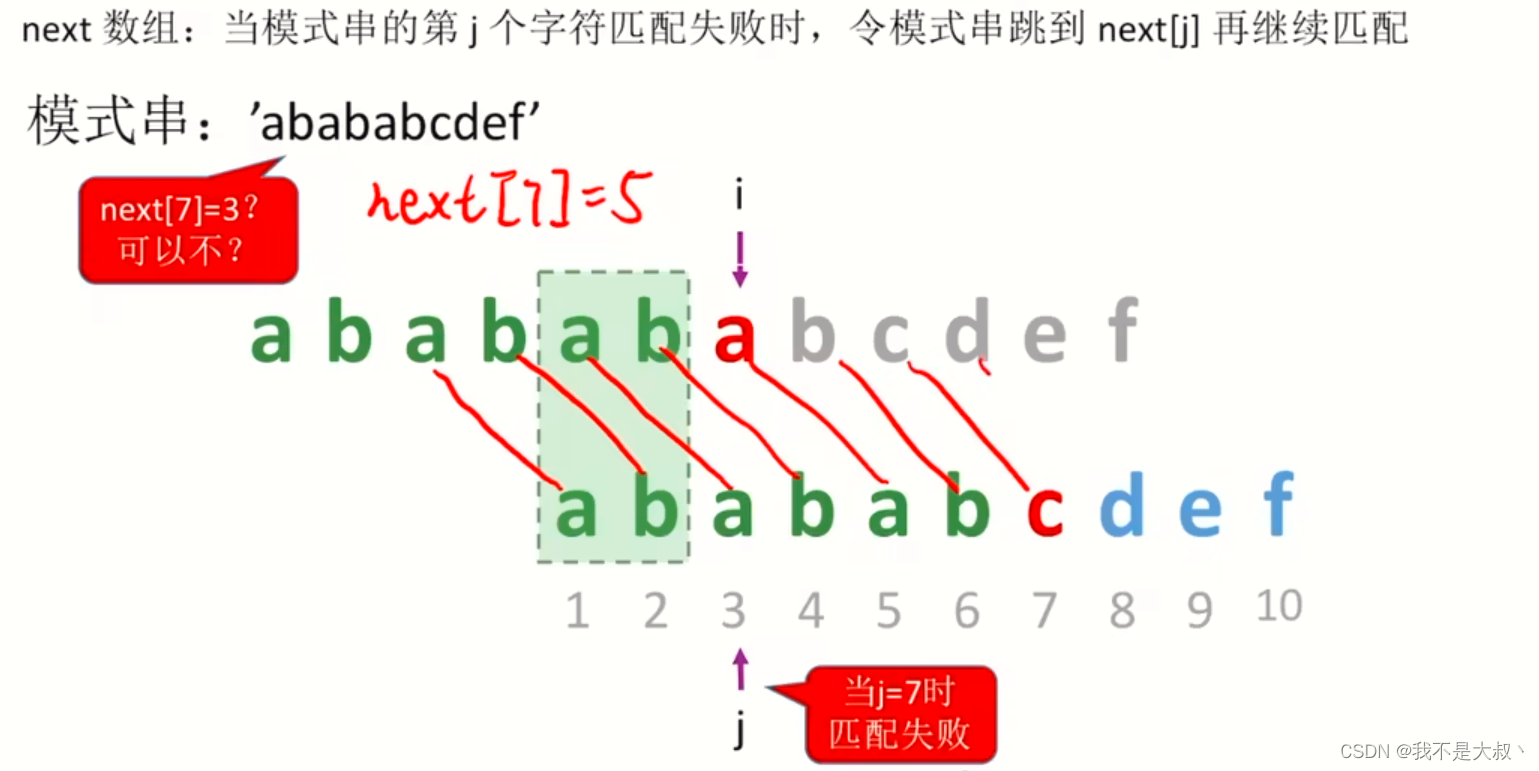
我们可以看到,在第三个元素我们就找到了我们需要的结果,如果向后移四个,且不说可不可以找到,找到了他也不是我们需要的最准确的结果,所以我们是不是应该先寻找匹配到的相同元素最大的,或者可以说最先找到的呢?我们有以下概念:
串的前缀:包含字符串的第一个字符,不包含最后一个字符的子串;
串的后缀:包含字符串的最后一个字符,不包含第一个字符的子串。
例如:
字符串 abcdab
前缀的集合:{
a,ab,abc,abcd,abcda}
后缀的集合:{
b,ab,dab,cdab,bcdab}
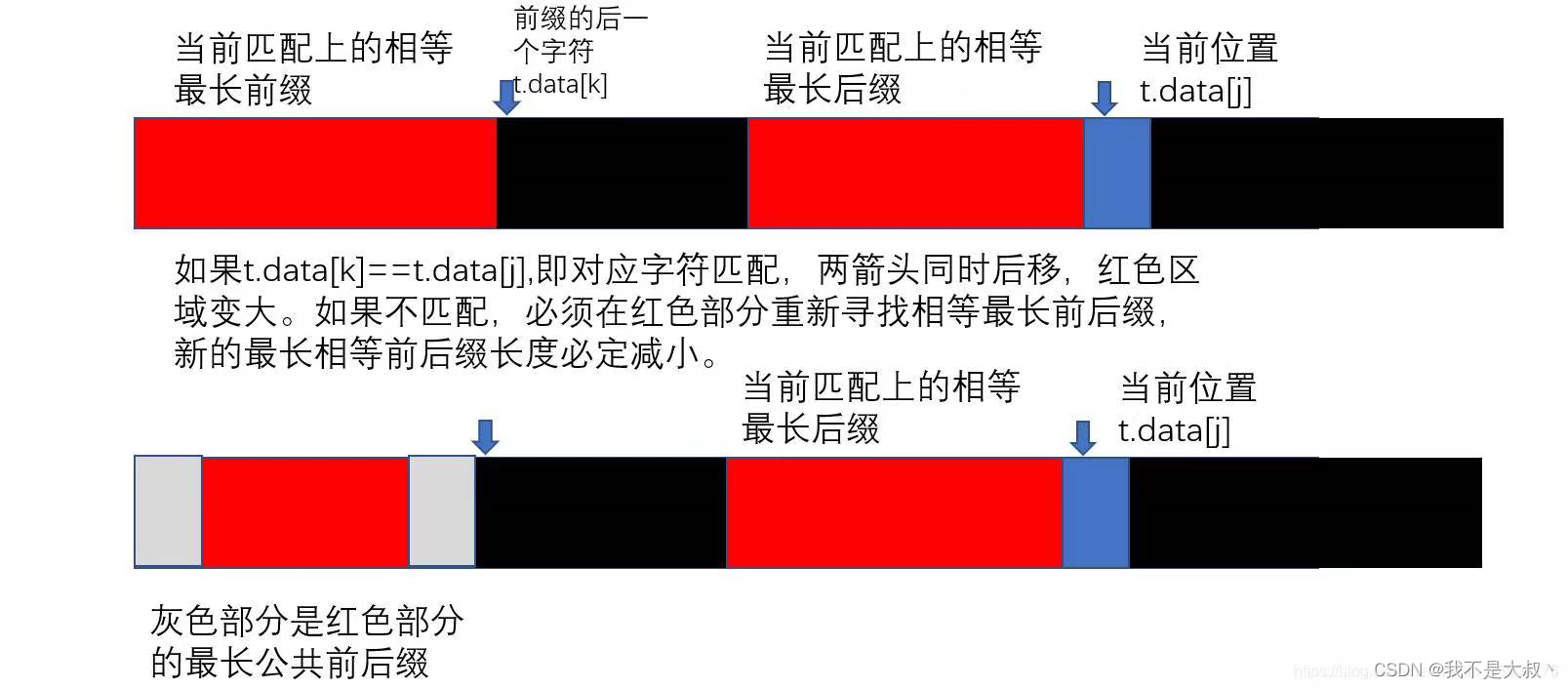
当第j个字符匹配失败,则前1~j-1个元素记作S,其中next[j]=S最长相等前后缀+1;那这样求next数组就变得很轻松了,我们也可以考虑用代码实现。我们总结求next公式如下图:

下面的长条代表子串,红色部分代表当前匹配上的最长相等前后缀,蓝色部分代表t.data[j]。
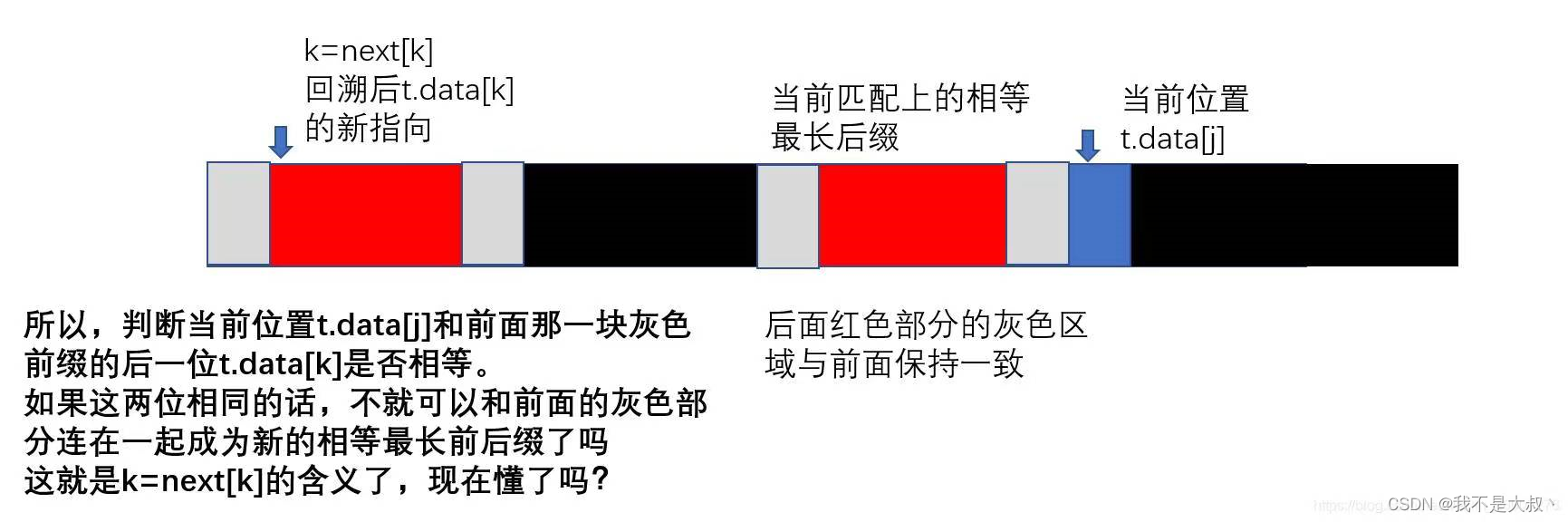
根据这些内容,我们做出如下代码:
typedef struct
{
char data[MaxSize];
int length; //串长
} SqString;
//typedef重命名结构体变量,用SqString T定义一个结构体。
void GetNext(SqString T, int next[])
{
int j, k;
j = 0; k = -1;
next[0] = -1;//第一个字符前无字符串,给值-1
while (j < T.length - 1)
//因为next数组中j最大为T.length-1,而每一步next数组赋值都是在j++之后
//所以最后一次经过while循环时j为T.length-2
{
if (k == -1 || T.data[j] == T.data[k]) //k为-1或比较的字符相等时
{
j++; k++;
next[j] = k;
//对应字符匹配情况下,s与t指向同步后移
//通过字符串"aaaaab"求next数组过程想一下这一步的意义
}
else
{
k = next[k];
//我们现在知道next[k]的值代表的是该处字符不匹配时应该回溯到的字符的下标
//这个值给k后又进行while循环判断,此时t.data[k]即指最长相等前缀后一个字符
}
}
}
kmp算法的时间复杂度
现在我们分析一下KMP算法的时间复杂度:KMP算法中多了一个求数组的过程,多消耗了一些空间。我们知道KMP是以空间换时间的算法,我们设主串S长度为n,子串T的长度为m。求next数组时时间复杂度为O(m),因后面匹配中主串不回溯,比较次数可记为n,所以KMP算法的总时间复杂度为O(m+n),空间复杂度记为O(m)。相比于朴素的模式匹配时间(BF算法)复杂度O(m*n),KMP算法提速是非常大的,这一点点空间消耗换得极高的时间提速是非常有意义的,这种思想也是很重要的。
kmp代码实现
int Index_KMP(SqString S, String T)
{
int next[MAXSIZE], i = 0, j = 0;
GetNext(T, next);
while (i < S.length && j < T.length)
{
if (j == -1 || S.data[i] == T.data[j])
{
i++; j++;
}
else
j = next[j]; //i不变,j后退到next标记的下标处。
}
if (j >= T.length)
return(i - T.length); //返回匹配模式串的首字符下标
else
return(-1); //返回不匹配标志,表示查找失败
}
然而,我们的KMP还是可以优化的,那么他已经这么厉害了为什么还需要优化呢?
nextval数组实现
主串s=“aaabaaaaac”
子串t=“aaac”
这个例子中当‘b’与‘c’不匹配时我们知道没有必要再将‘b’与‘a’比对了,因为回溯后的字符和原字符是相同的,原字符不匹配,回溯后的字符自然不可能匹配。但是KMP算法中依然会将‘b’与回溯到的‘a’进行比对。这就是我们可以改进的地方了。
那我们应该咋做呢?
其实我们可以简述为: 如果a位字符与它next值指向的b位字符相等,则该a位的nextval就指向b位的nextval值,如果不等,则该a位的nextval值就是它自己a位的next值。
这应该算是比较通俗的解释了!
我们将求next数组的代码修改为:
void GetNextval(SqString T, int nextval[])
{
int j = 0, k = -1;
nextval[0] = -1;
while (j < T.length)
{
if (k == -1 || T.data[j] == T.data[k])
{
j++; k++;
if (T.data[j] != T.data[k])
nextval[j] = k;
else
nextval[j] = nextval[k];
//此时nextval[j]的值就是就是T.data[j]不匹配时应该回溯到的字符的nextval值
}
else k = nextval[k];
}
}
总结
kmp算法的核心在于求解next(nextval)数组,博主也是苦于kmp久矣,今日顿悟,也是愈发感觉到计算机前辈的厉害之处,大家一定不要放弃kmp,仔细品味,终究会彻悟的!加油!
如果博主的文章给你提供了帮助,给博主一个不要钱的赞可好?对博主来说可美可香了!