一、概述
- 为什么树对于DB是一个好的数据结构?
- 查找数据更快
- 插入/删除数据更快
- 范围查找更快(这是比哈希表更优的地方)
二、B-tree vs B+ tree
在sqlite中,索引使用B树,而存储表格使用B+树
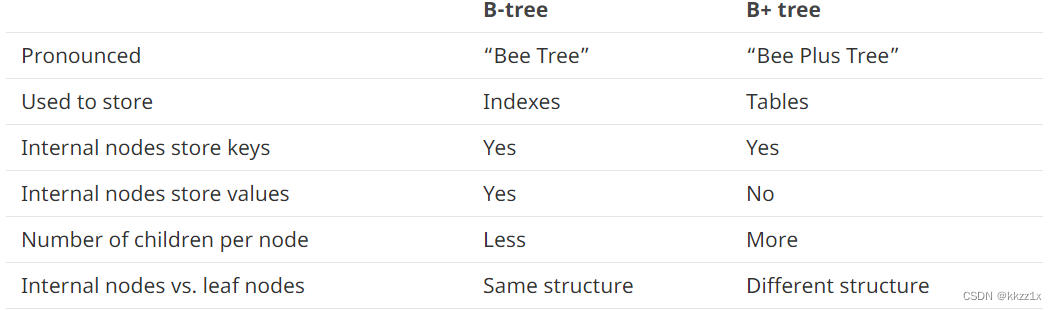
B+树的非叶子结点只存keys,而不存values;B树则存k-v,叶子结点和非叶子结点的结构是一致的。
B+树的非叶子节点vs叶子节点

三、改造成B+树
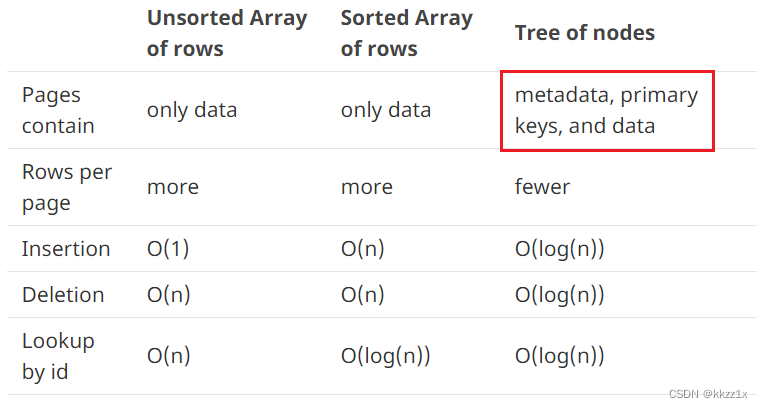
叶子结点不止存储一行数据,因此一个node可能需要包含元数据、主键、记录本身。
对原来的设计(数组存储),每个page只存储row的数据,并没有存元数据,所以在空间效率很高。插入也很快,因为只需要插入到最后就行。但是找到指定的行需要扫描全表;删除指定的行也需要把数组整个往前移动。
如果我们用有序数组存储,查找指定的行可以用二分查找,但是插入新行同样需要移动很多行。
如果采用树形结构存储,树的每个node可以保存好几行,所以需要存储一些额外信息来指明行数;还有非叶结点无法存储数据的空结点开销;但是换来的是:大表可以更快地插入、删除和查找。
数据结构设计
- NodeType
- Common Node Header Layout(NodeType,IsRootSize,ParentPointerSize)
- Leaf Node Header Layout

最后的空间无法存整个k-v对,所以浪费掉;避免将一个k-v对分到两个Node去。
在这里,一个k-v对被称为一个cell
代码优化
总体思路: 所有按row访问全部改为按page访问。
在这一节中,我们的树仅限于根结点(叶子结点)一个节点。
- Pager需要增加属性num_pages,而不是table增加该属性。因为页面数是整个数据库需要使用的,而不是特定table有的。
B-树用根节点的page number表示,所以table中需要增加属性root_page_num。
这里要进行一点知识补充:
【from 小林coding】
MySQL里InnoDB存储引擎采用B+树组织数据。B+树的结点存放的是什么呢?
记录是按照行来存储的,但是数据库的读取并不以【行】为单位,否则一次读取(一次I/O)只能处理一行数据,效率很低。因此,InnoDB数据是按照【数据页】读写的,当要读一条记录的时候,要将这一页都读出来,整体读入内存。
数据库I/O操作的最小单位是页,InnoDB数据页默认大小16KB,意味着数据库每次读写都是以 16KB 为单位的,一次最少从磁盘中读取 16K 的内容到内存中,一次最少把内存中的 16K 内容刷新到磁盘中。
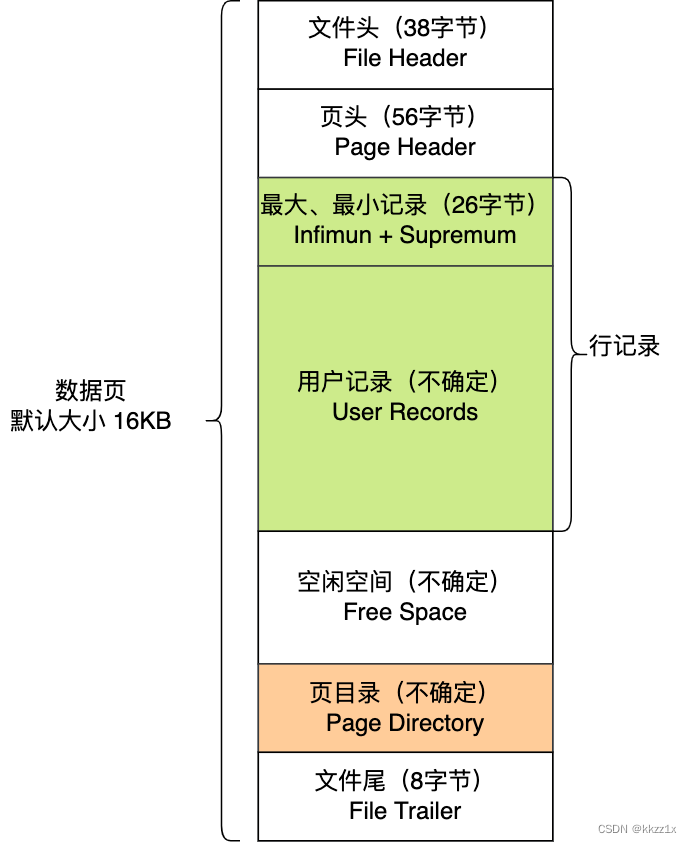
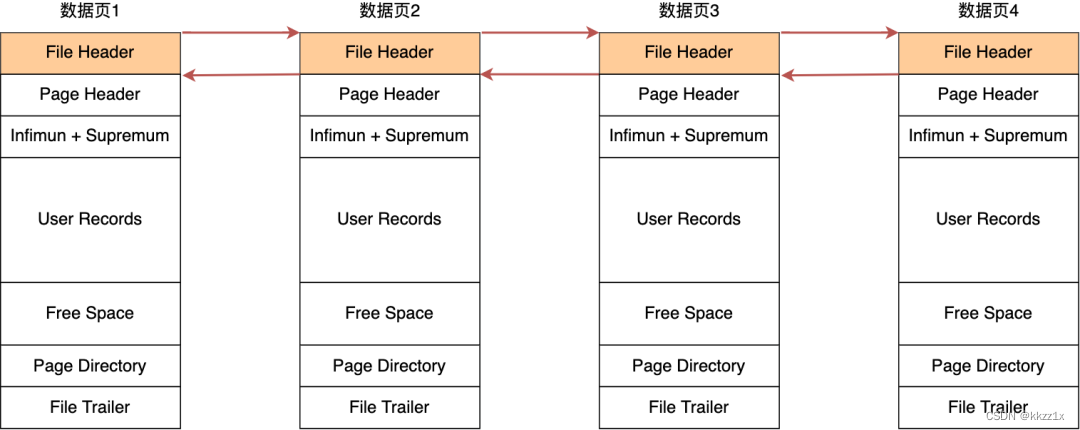
链表的结构是让数据页之间不需要是物理上的连续的,而是逻辑上的连续。
数据页之间用双向链表连接起来,而数据页中的记录按照主键顺序组成单向链表。但是因为链表的检索性能不高,因此数据页中还有个页目录,类似于索引,可以快速地找到记录。
B+树中每个节点都是一个数据页。
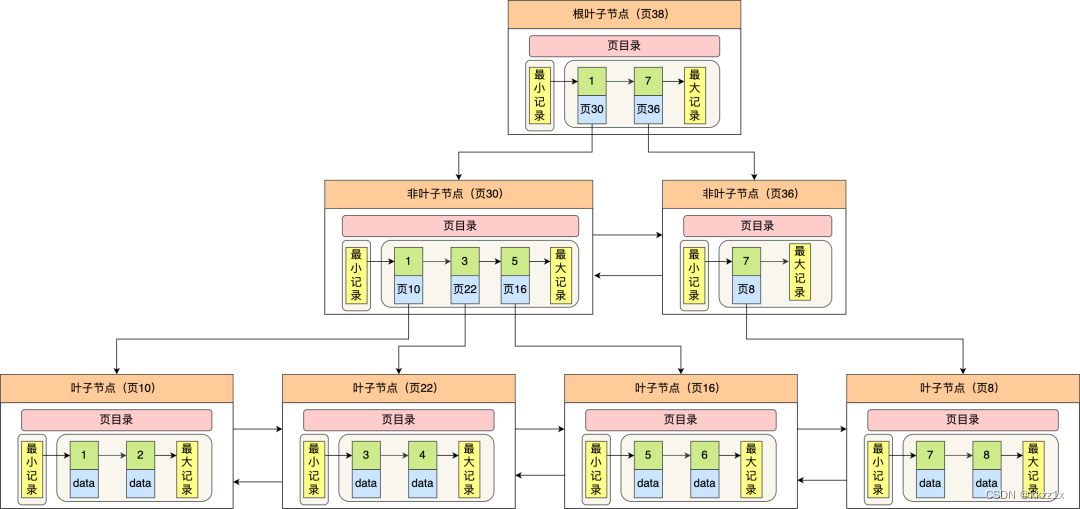
只有在叶子结点中才存放了数据,非叶子结点仅用来存放目录项作为索引。
在定位记录所在哪一个页时,通过二分法快速定位到包含该记录的页;定位到该页后,又会在该页内进行二分法快速定位记录所在的分组(槽号),最后在分组内进行遍历查找。
一个结点与一个page相联系。
Internal nodes包含指向children的指针。
在page的开头,结点需要存储一些元数据,包括说明这个结点的类型(叶子or非叶子),这个结点是否为root,和指向parent的指针。 所以定义以下常量:
typedef enum{
NODE_INTERNAL,
NODE_LEAF
}NodeType;
/**
* Common Node Header Layout
*/
const uint32_t NODE_TYPE_SIZE=sizeof(uint8_t); //1 byte
const uint32_t NODE_TYPE_OFFSET=0;
const uint32_t IS_ROOT_SIZE=sizeof(uint8_t); //1 byte
const uint32_t IS_ROOT_OFFSET=NODE_TYPE_OFFSET+NODE_TYPE_SIZE;
const uint32_t PARENT_NODE_SIZE=sizeof(uint32_t);//4 bytes
const uint32_t PARENT_NODE_OFFSET=IS_ROOT_OFFSET+IS_ROOT_SIZE;
const uint32_t COMMON_NODE_HEADER_SIZE=NODE_TYPE_SIZE+IS_ROOT_SIZE+PARENT_NODE_SIZE;
/**
* Leaf Node Header Layout
*
*/
const uint32_t LEAF_NODE_NUM_CELLS_SIZE=sizeof (uint32_t); //4 bytes
const uint32_t LEAF_NODE_NUM_CELLS_OFFSET=NODE_TYPE_OFFSET+COMMON_NODE_HEADER_SIZE;
const uint32_t LEAF_NODE_HEADER_SIZE=COMMON_NODE_HEADER_SIZE+LEAF_NODE_NUM_CELLS_SIZE;
/**
* Leaf Node Body Header
*
*/
const uint32_t LEAF_NODE_KEY_SIZE=sizeof(uint32_t); //k 4bytes
const uint32_t LEAF_NODE_KEY_OFFSET=0;
const uint32_t LEAF_NODE_VALUE_SIZE=ROW_SIZE;
const uint32_t LEAF_NODE_VALUE_OFFSET=LEAF_NODE_KEY_SIZE+LEAF_NODE_KEY_OFFSET;
const uint32_t LEAF_NODE_CELL_SIZE=LEAF_NODE_KEY_SIZE+LEAF_NODE_VALUE_SIZE;
const uint32_t LEAF_NODE_FOR_CELL_SIZE=PAGE_SIZE-LEAF_NODE_HEADER_SIZE; // max space for cells
const uint32_t LEAF_NODE_MAX_NUM=LEAF_NODE_FOR_CELL_SIZE/LEAF_NODE_CELL_SIZE;// how many cells can be placed in one page
前文所写的row_num全部失效,而现在我们的读取单位变成了page(而并非row)
因此修改table,cursor的相关属性。
- 插入第一个叶子结点
K-V对可以不断插入直到一个叶子结点满了
db_open:
在我们第一次打开数据库的时候,数据库文件是空的,所以我们将page 0作为一个空的叶子结点(也是root结点)
Table *db_open(const char* filename){
Pager* pager=pager_open(filename);
Table *table=(Table*) malloc(sizeof (table));
table->pager=pager;
table->root_page_num=0;
if(pager->num_pages==0){
//new database file
void* root_node= get_page(pager,0);
initialize_leaf_node(root_node);
}
return table;
}
db_close时的刷盘操作,也以页为单位:
void db_close(Table* table){
Pager * pager=table->pager;
uint32_t num_pages=pager->num_pages;
for(uint32_t i=0;i<num_pages;i++){
if(pager->pages[i]==NULL){
continue;
}
pager_flush(pager,i); //如果内存中page[i]有改动,将pager的第i页写入文件(磁盘)
free(pager->pages[i]);
pager->pages[i]=NULL;
}
游标cursor则负责插入记录时的定位。因此与游标cursor相关的一系列操作也需要进行该表。
cursor中存放对应的table,所在的page_num,和记录对应的cell_num
Cursor* table_start(Table* table){
Cursor *cursor= malloc(sizeof(Cursor));
cursor->table=table;
cursor->page_num=table->root_page_num;
cursor->cell_num=0;
void* root_node=get_page(table->pager,table->root_page_num);
uint32_t num_cells= *leaf_node_num_cells(root_node);
cursor->end_of_table=(num_cells==0);
return cursor;
}
Cursor* table_end(Table* table){
Cursor* cursor= malloc(sizeof (Cursor));
cursor->table=table;
cursor->page_num=table->root_page_num;
void* page= get_page(table->pager,cursor->page_num);
uint32_t num_cells=*leaf_node_num_cells(page);
cursor->cell_num=num_cells;
cursor->end_of_table=true;
return cursor;
}
// you can get row's position from a page(get offset of row in this page)
void* cursor_value(Cursor* cursor){
uint32_t page_num=cursor->page_num;
void* page= get_page(cursor->table->pager,page_num);
return leaf_node_value(page,cursor->cell_num);
}
//cell_num +1
void cursor_advance(Cursor* cursor){
uint32_t page_num=cursor->page_num;
void* page= get_page(cursor->table->pager,page_num);
cursor->cell_num++;
uint32_t num_cells=*leaf_node_num_cells(page);
if(cursor->cell_num>=num_cells){
cursor->end_of_table=true;
}
}
leaf_node_insert负责记录插入到叶子结点。
void leaf_node_insert(Cursor* cursor,uint32_t key,Row* value)
插入的位置时cursor指向的位置,插入内容为(key,value)
void leaf_node_insert(Cursor* cursor,uint32_t key,Row* value){
void* node= get_page(cursor->table->pager,cursor->page_num);
uint32_t num_cell= *leaf_node_num_cells(node);
if(num_cell>LEAF_NODE_MAX_NUM){
//游标大于一个叶子中可以保存的最大数,报错
printf("Need to implement splitting a leaf Node\n");
exit(EXIT_FAILURE);
}
if(cursor->cell_num<num_cell){
//不在叶子结点最后插入,需要挪动记录腾出插入的位置
for(uint32_t i=num_cell;i>cursor->cell_num;i--){
memcpy(leaf_node_cell(node,i), leaf_node_cell(node,i-1),LEAF_NODE_CELL_SIZE);
}
}
//找到位置插入数据
*leaf_node_num_cells(node)+=1; //该叶子结点中的记录(cell)数+1
*leaf_node_key(node,cursor->cell_num)=key; //插入对应的key
serialize_row(value, leaf_node_value(node,cursor->cell_num));//插入对应的valu
}
至此,我们完成了最简单的B+树的插入,这棵二叉树只有一个根结点,同时也是叶子结点。
插入为顺序插入,叶子结点中的数据还是无序的。