wikipipedia 如下描述
In computer science, a B-tree is a self-balancing tree data structure that maintains sorted data and allows searches, sequential access, insertions, and deletions in logarithmic time. The B-tree is a generalization of a binary search tree in that a node can have more than two children.[1] Unlike self-balancing binary search trees, the B-tree is well suited for storage systems that read and write relatively large blocks of data, such as discs. It is commonly used in databases and file systems.
B-树是一种自平衡树数据结构,它维护已排序的数据,并允许对数时间的搜索、顺序访问、插入和删除。B-树是二叉搜索树的推广,因为节点可以有两个以上的子树。[1]与自平衡二叉搜索树不同,B-树非常适合于读取和写入较大数据块(如磁盘)的存储系统。它通常用于数据库和文件系统中。
b-tree 不是binary tree 而是banlance tree
b树的结构常常用于数据库的索引。
二叉查找树查询的时间复杂度是O(logN),查找速度最快和比较次数最少,既然性能已经如此优秀,但为什么实现索引是使用B-Tree而不是二叉查找树,关键因素是磁盘IO的次数。
数据库索引是存储在磁盘上,当表中的数据量比较大时,索引的大小也跟着增长,达到几个G甚至更多。当我们利用索引进行查询的时候,不可能把索引全部加载到内存中,只能逐一加载每个磁盘页,这里的磁盘页就对应索引树的节点。
磁盘读取依靠的是机械运动,分为寻道时间、旋转延迟、传输时间三个部分,这三个部分耗时相加就是一次磁盘IO的时间,大概9ms左右。这个成本是访问内存的十万倍左右;正是由于磁盘IO是非常昂贵的操作,所以计算机操作系统对此做了优化:预读;每一次IO时,不仅仅把当前磁盘地址的数据加载到内存,同时也把相邻数据也加载到内存缓冲区中。因为局部预读原理说明:当访问一个地址数据的时候,与其相邻的数据很快也会被访问到。每次磁盘IO读取的数据我们称之为一页(page)。一页的大小与操作系统有关,一般为4k或者8k。这也就意味着读取一页内数据的时候,实际上发生了一次磁盘IO。
二叉搜索树 和b树的区别就在于 每次寻找一次节点都在内存里加载一次,二叉树每次只存一个节点 也就是说一次访问只有一个数 何不如在一个节点里面多装些数据呢 这样的话 更具有效率 在内存里比对花费的时间要远远比在磁盘里花费的时间短得多 相同的树种 但树的节点b树要少的多。
于此同时还有b+树 b+树是个稳定的结构 每次都要访问到叶子节点
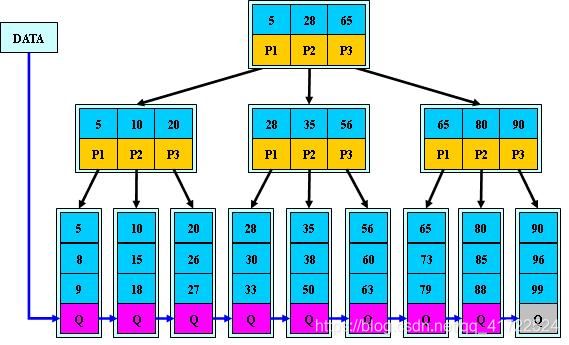
B+Tree是B树的变种,有着比B树更高的查询性能,来看下m阶B+Tree特征:
1、有m个子树的节点包含有m个元素(B-Tree中是m-1)
2、根节点和分支节点中不保存数据,只用于索引,所有数据都保存在叶子节点中。
3、所有分支节点和根节点都同时存在于子节点中,在子节点元素中是最大或者最小的元素。
4、叶子节点会包含所有的关键字,以及指向数据记录的指针,并且叶子节点本身是根据关键字的大小从小到大顺序链接。