CNN解释器地址:CNN Explainer
CNN解释器文献:CNN Explainer: Learning Convolutional Neural Networks with Interactive Visualization
CNN github地址:https://github.com/poloclub/cnn-explainer
Deep Learing官方PDF:deeplearningbook
基本卷积函数的变体
当我们提到神经网络中的卷积的时候,通常指的是由多个并行卷积组成的运算。这是因为具有单个核的卷积只能提取一种类型的特征,尽管它作用在多个空间位置上。而实际情况是我们希望网络的每一层都能在多个位置提取多种类型的特征。
另外,输入通常也不仅仅是实值的网格,而是由一系列观测数据的向量构成的网格。例如在多层卷积网络中,如果将第一层的输出作为第二层的输入,那么最终每个位置包含了多个不同卷积结果的输出。例如处理彩色图像时我们通常分为RGB三通道,那么卷积的输入输出就应当看作一个三维的张量,其中一个索引用于标明不同的通道,另外两个索引标明在每个通道上的空间坐标。
由于卷积网络通常使用多通道的卷积,因此即使使用了核翻转,也不一定保证网络的线性运算是可交换的。只有当其中每个运算的输入和输出具有相同的通道时,这些多通道的运算才是可交换的。
步幅
Z i , j , k = ∑ l , m , n V l , j + m − 1 , k + n − 1 K i , l , m , n Z_{i,j,k}=\displaystyle\sum_{l,m,n}V_{l,j+m-1,k+n-1}K_{i,l,m,n} Zi,j,k=l,m,n∑Vl,j+m−1,k+n−1Ki,l,m,n
上式是一个四维的核张量K与三维输入V的卷积运算,它表示输出中处于通道 i i i的一个单元核输入中处于通道 l l l的一个单元的连接强度,并且在输出单元核输入单元之间有 m m m行 n n n列的偏置。观测数据 V V V代表我们的输入,表示处于通道 l l l中第 j + m − 1 j+m-1 j+m−1行第 k + n − 1 k+n-1 k+n−1列的值。
有时候我们希望跳过核中的一些位置来降低计算的开销(相应的代价是提取特征没有全部计算那样好了)。我们可以把这一过程看作对全卷积函数输出的下采样——也就是通过隔位采样减少矩阵的采样点数,例如在输出的每个方向上每隔 s s s 个像素进行一次采样,如下面的一个下采样卷积函数 c c c所示:
Z i , j , k = c ( K , V , s ) i , j , k = ∑ l , m , n V l , ( j − 1 ) ∗ s + m , ( k − 1 ) ∗ s + n K i , l , m , n Z_{i,j,k}=c(K,V,s)_{i,j,k}=\displaystyle\sum_{l,m,n}V_{l,(j-1)*s+m,(k-1)*s+n}K_{i,l,m,n} Zi,j,k=c(K,V,s)i,j,k=l,m,n∑Vl,(j−1)∗s+m,(k−1)∗s+nKi,l,m,n
我们将 s s s称为下采样卷积的步幅,当然也可以对每个移动方向定义不同的步幅,如下图所示:

该图中上面的部分是在单个操作中实现的步幅为2的卷积。下面的部分代表了经过卷积(正常的卷积也可以视为步幅为1的卷积,或者叫单位步幅的卷积)后,对卷积输出进行了步幅为2的下采样。实际上两者的作用是一样的,因此上面的方式会更好,计算更简便。
零填充
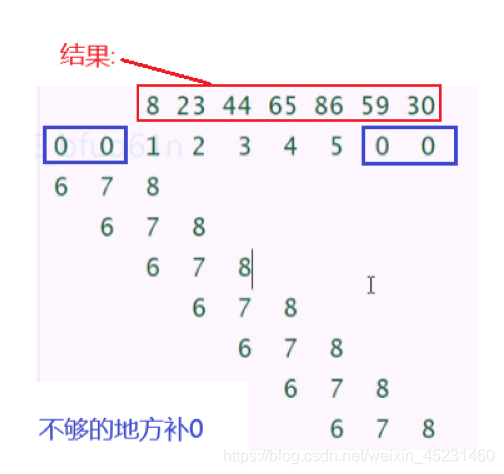
在卷积时有一个重要的性质叫做零填充,很好理解,试想一下我们滑动卷积核的时候,有时会出现卷积核超出输入的范围,在计算的时候就会自动为那些范围内的空输入赋予0值。如下图所示:
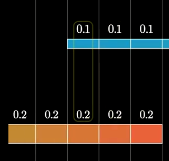
左边超出的部分被赋予了0值。其隐含的含义就是输入被0值加宽了。如果没有这一性质,那么表示的宽度就会在每一层进行缩减,且缩减的幅度比核少一个像素,例如对3个像素进行2个像素的卷积,无法对超出部分计算的话最终只能得到2个像素的卷积结果,再进行一次就只能得到1个像素的卷积结果了。
对输入进行零填充能够允许我们对核的宽度和输出的大小进行独立的控制。如果没有核填充,要么选择对网络空间宽度的快速缩减,要么选择一个小型的核——而这两种情况都会极大的限制网络的表示能力,如下图的一个例子:
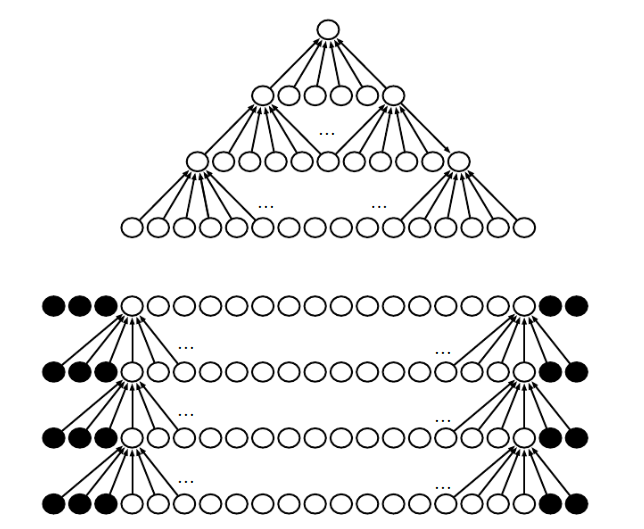
该图中我们可以看到,卷积层由下到上计算,上方的图像是不经过零填充的卷积,因此最终得到的卷积结果的网络空间宽度会快速缩减,最后一层由于只有一个输出结果甚至不能移动卷积核,所以最后一层根本算不上卷积,空间深度也被限定为四层。
下方是经过零填充的卷积,卷积空间大小不变,这允许我们设计一个任意深度的卷积空间。
三种零填充
有三种零填充的设定值得注意,第一种就是上图中的上半部分的模型,无论怎样都不使用零填充的情况,那么卷积核就只能允许访问图像中那些能够完全包含整个核的位置,在MATLAB术语中,这被称为有效(valid)卷积。这种情况下每个输出的像素,其输入都是相同数量的像素,这使得输入像素更加规范,然而会导致输出大小在每一层都会缩减。卷积核越大,缩减率越显著。
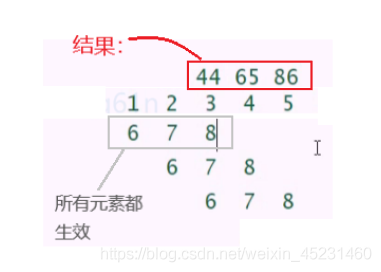
第二种特殊的情况是只进行足够的零填充来保持输入核输出(此处核输出指的是卷积核的核心元素)具有相同的大小,在MATLAB术语中称为相同卷积。因为卷积不会改变到下一层的输出的结构,这样网络就可以包含任意多的卷积层。然而输入像素中靠近边界的部分相比于中间部分对于输出像素的影响更小(因为边界有0填充),这可能导致边界像素存在一定程度的欠表示。
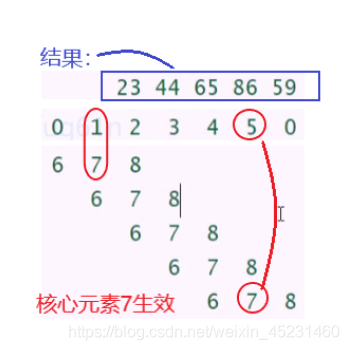
第二种是先让核心元素核原矩阵对其再卷积,其余位置零填充。第三种更为极端,只要有元素对其就卷积,在MATLAB中被称为完全卷积。它进行了足够多的零填充,使得每个像素在每个方向上恰好被访问了k次,最终输出图像宽度为 m + k − 1 m+k-1 m+k−1,这种情况下,输出像素中靠近边界的部分相比于中间部分是更少像素的函数。这将导致学得一个在卷积特征映射的所有位置都表现得不错的单核更为困难。
通常零填充的最优数量处于”有效卷积“和”相同卷积“之间的某个位置。
局部连接
有的时候我们并不是真的想使用卷积,而是想用一些局部连接的网络层。在这种情况下,我们的多层感知机对应的邻接矩阵是相同的,但每一个连接都有它自己的权重。我们会用到一个六维张量 W i , j , k , l , m , n W_{i,j,k,l,m,n} Wi,j,k,l,m,n,即每个连接都有不同的输出通道i,对应第j行第k列,输入通道为l,输入单元与输出单元间的行偏置为m,列偏置为n。(相比于原来的四维张量,多了两个维度用于记录处理的起始位置,这是由于我们并不是在使用卷积,也就是不同位置的处理并不是相同的卷积核,因此无法参数共享,需要对不同位置的卷积核分别记录)
局部连接层的线性部分可以表示为:
Z i , j , k = ∑ l , m , n V l , j + m − 1 , k + n − 1 w i , j , k , l , m , n Z_{i,j,k}=\displaystyle\sum_{l,m,n}V_{l,j+m-1,k+n-1}w_{i,j,k,l,m,n} Zi,j,k=l,m,n∑Vl,j+m−1,k+n−1wi,j,k,l,m,n
这有时也被我们称为非共享卷积,因为处理上和卷积很像,但并没有参数共享。如下图我们对一些连接方式进行了比较:
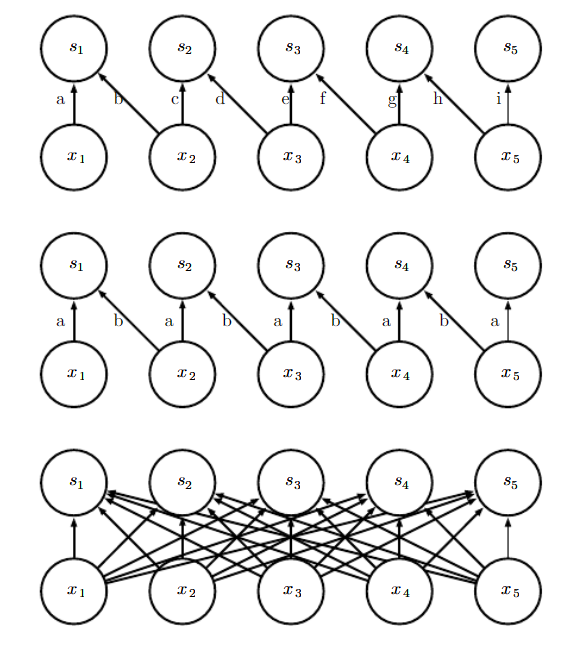
上图中第一种连接是每个接受域有两个像素的局部连接层,我们发现不同连接的参数都是独立的。
第二个连接是核宽度为2个像素的卷积层,卷积连接与局部连接具有完全相同的连接,然而卷积层可以实现参数共享,连接层不能。
第三个连接是全连接,它类似于局部连接,每个连接都有不同的参数,但不具有局部连接那样连接受限的特征。并且所有的输入单元和输出单元都存在连接。
当我们知道每一个特征都是一小块空间的函数,并且相同的特征不会出现在所有的空间上时(也就这不同空间的处理需要不同的参数),局部连接层是很有用的,例如如果想要辨别一张图片是否为人脸,我们只需要寻找嘴是否在图像下半部分即可。
一种优化局部连接的方法减少参数,例如我们可以使得输出的前m个通道仅仅连接到输入的前n个通道,接下来的[m+1,2m]个通道则连接到[n+1,2n]个输入通道,这允许我们对少量通道间的连接进行建模,并允许网络使用更少的参数,降低了存储消耗和计算量,如下图所示:
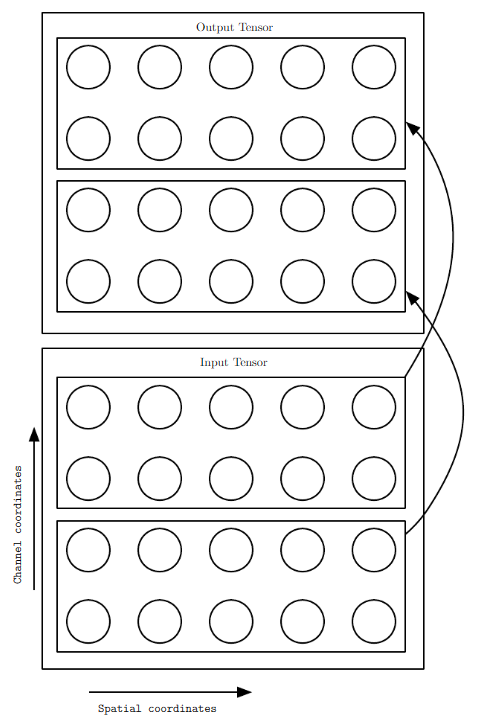
上图中每一行圆圈代表了一个通道,我们将每两个输出通道连接到两个输入通道,这样就减少了连接数量,也减少了所需的参数。
平铺卷积
一种折中的方法是使用平铺卷积。局部连接需要对每个空间位置的权重参数进行学习,我们可以用多组卷积习得的参数来在整个空间上进行循环利用。也就是说给出多组卷积,这意味着邻近的位置上拥有不同的过滤器,就行局部连接层一样。缺点在于对于卷积参数的存储需求会成m倍增长。m倍是指我们使用的卷积集合的卷积数量,例如使用了2种卷积就增加两倍。下图对局部连接,平铺卷积核标准卷积进行了比较:
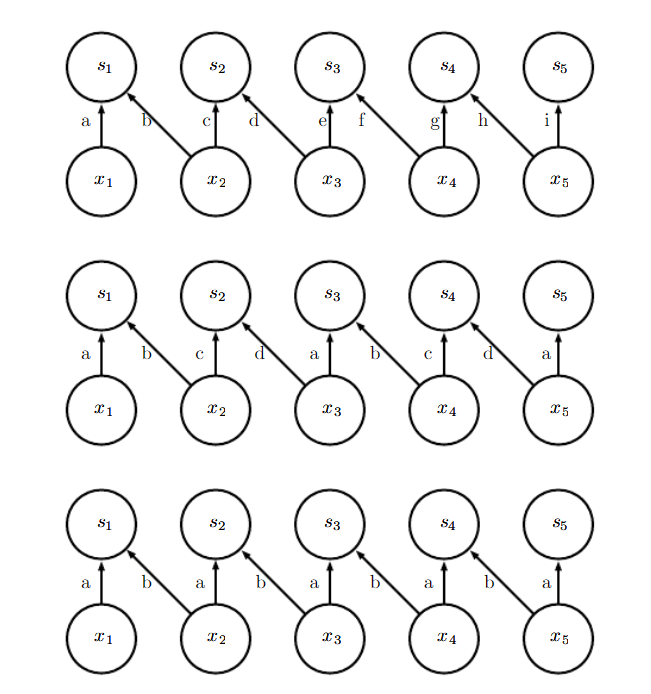
在这里我们使用了相同大小的核进行卷积,第一个模型是局部连接层,不同的连接参数不同。
而第二个模型是平铺卷积,我们在这里使用了两种不同的卷积依次交换,准确来说是按照顺序依次循环所有的t个核,因此可以看到连接出现了两组不同的参数,相邻的连接之间是两种不同的过滤器。
第三组就是一组传统卷积,等价于t=1的平铺卷积。
如果用代数的方法来定义平铺卷积的话,首先我们需要在非共享卷积的公式上改进,由于存在着每t个卷积的循环,因此我们需要用到取模运算%,例如t%t=0,(t+1)%t=1。
Z i , j , k = ∑ l , m , n V l , j + m − 1 , k + n − 1 K i , l , m , n , j % t + 1 , k % t + 1 Z_{i,j,k}=\displaystyle\sum_{l,m,n}V_{l,j+m-1,k+n-1}K_{i,l,m,n,j\%t+1,k\%t+1} Zi,j,k=l,m,n∑Vl,j+m−1,k+n−1Ki,l,m,n,j%t+1,k%t+1
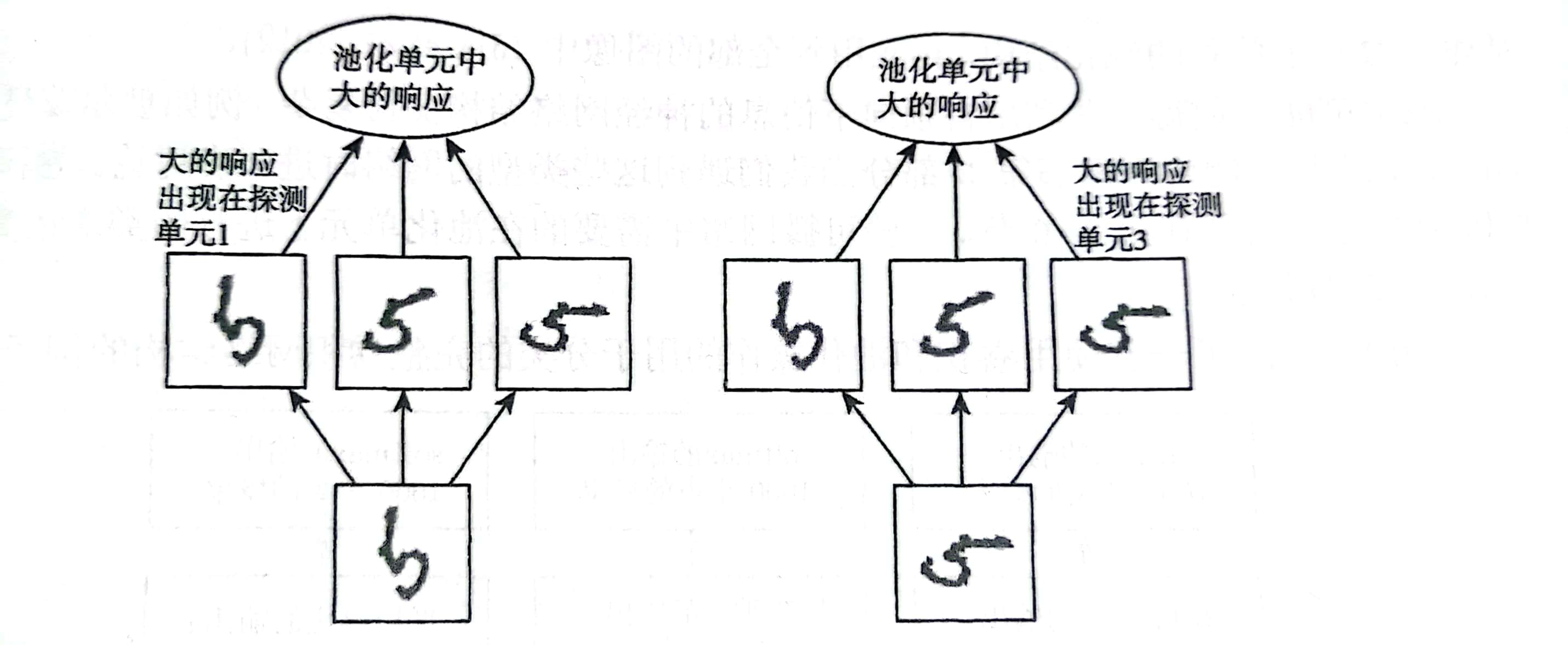
我们在学习池化的时候提到,如果过滤器能够学会探测相同隐含特征的不同变换形式,那么对于不同的激活值的最大池化就具有不变性。如果把卷积层替换为平铺卷积或是局部连接,这一结论也是成立的。
梯度学习
实现卷积网络时,为了实现学习,我们需要在给定输出的梯度时能够计算核的梯度。我们通常使用——卷积,从输出到权重的反向传播和从输出到输入的反向传播这三种运算。对于训练任意深度的前馈卷积网络,以及训练带有(基于卷积的转置的)重构函数的卷积网络,这三种运算都足以计算它们所需的所有梯度。
Z i , j , k = c ( K , V , s ) i , j , k = ∑ l , m , n V l , ( j − 1 ) ∗ s + m , ( k − 1 ) ∗ s + n K i , l , m , n Z_{i,j,k}=c(K,V,s)_{i,j,k}=\displaystyle\sum_{l,m,n}V_{l,(j-1)*s+m,(k-1)*s+n}K_{i,l,m,n} Zi,j,k=c(K,V,s)i,j,k=l,m,n∑Vl,(j−1)∗s+m,(k−1)∗s+nKi,l,m,n
假设我们想要训练这样的一个卷积网络:它包含步幅为s的步幅卷积,该卷积的核为 K K K,作用于多通道的图像 V V V,定义为 c ( K , V , s ) c(K,V,s) c(K,V,s),就像上式的下采样卷积函数一样。假设我们想要最小化某个损失函数 J ( V , K ) J(V,K) J(V,K)。在前向传播过程中,我们需要用 c c c本身来输出 Z Z Z ,然后 Z Z Z传递到网络的其余部分并且被用来计算损失函数 J J J。
在反向传播过程中,我们会得到一个张量 G G G满足 G i , j , k = δ δ Z i , j , k J ( V , K ) G_{i,j,k}=\frac{\delta}{\delta Z_{i,j,k}}J(V,K) Gi,j,k=δZi,j,kδJ(V,K)
为了训练网络,我们需要对核中的权重求导,我们可以使用一个函数:
G i , j , k = δ δ K i , j , k , l J ( V , K ) = ∑ m , n G i , m , n V j , ( m − 1 ) × s + k , ( n − 1 ) × s + l G_{i,j,k}=\frac{\delta}{\delta K_{i,j,k,l}}J(V,K)=\displaystyle\sum_{m,n}G_{i,m,n}V_{j,(m-1)×s+k,(n-1)×s+l} Gi,j,k=δKi,j,k,lδJ(V,K)=m,n∑Gi,m,nVj,(m−1)×s+k,(n−1)×s+l
(上式是对核K权重求导得到梯度)
如果这一层不是网络的底层,我们则需要对 V V V求梯度来使得误差进一步反向传播。我们可以使用如下的函数:
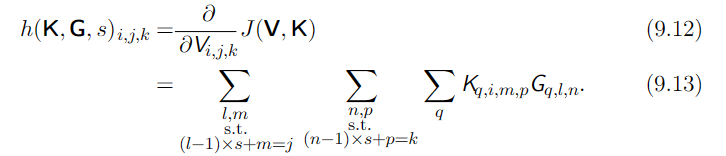
结构化输出
卷积神经网络可以用于输出高维的结构化对象,而不仅仅是预测分类任务的类标签或回归任务的实数值。通常这个对象只是一个张量,由标准卷积层产生。
经常出现的一个问题是输出平面可能比输入平面要小。用于对图像中单个对象分类的常用结构中,网络空间维数的最大减少来源于使用大步幅的池化层。为了产生与输入大小相似的输出映射,我们可以避免把池化放在一起。另一种策略是单纯地产生一张低分辨率的标签网格。最后,原则上可以使用具有单位步幅的池化操作。(也就是说要么避免连续地池化,要么接受这个产生的低分辨率图像,或者为了避免空间的大幅减少使用单位步幅的池化操作)
对图像逐个像素标记的一种策略是先产生图像标签的原始猜测,然后使用相邻像素之间的交互来修正该原始猜测。我们可以每一步使用相同的卷积来实现重复的修正步骤,并且该卷积在深层网络的最后几层之间共享权重。(简单总结就是多次循环相同卷积来逐步修正)这使得在层之间共享参数的连续的卷积层所执行的运算形成了一个特殊的循环神经网络,如下图所示:
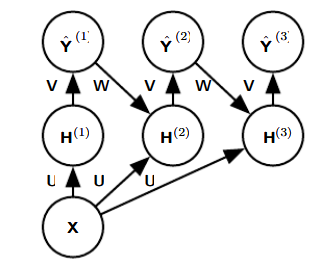
上述的神经网络中,我们可以将上一次的输出标签 Y ^ ( 1 ) \hat Y^{(1)} Y^(1)作为下一次新估计 H ( 2 ) H^{(2)} H(2)的输入,每次更新的估计都使用相同的参数,因此估计可以被我们改善任意多次,每一步使用的卷积核张量 U U U是用来计算给定输入图像的隐藏表示的。核张量 V V V用于产生给定隐藏值时标签的估计。核 W W W 对 Y ^ \hat Y Y^进行卷积来提供隐藏层的输入。构成了一个特殊的循环网络。
一旦我们对每一个像素进行了预测,就可以使用其他方法来进一步处理这些预测,以便获得图像在区域上的分割。一般的想法是假设大片相连的像素倾向于对应着相同的标签。图模型可以用于描述相邻像素间的概率关系,或者卷积网络可以被训练来最大化地近似图模型的训练目标。
总结,结构化输出的流程就是:
控制输出平面大小→图像逐个标记像素预测(重复卷积修正猜测)→处理预测
随机或无监督的特征
卷积网络训练中最昂贵的部分是学习特征,输出层的计算代价通常相对不高,这是因为在通过了若干层池化之后作为该层输入的特征的数量较少。当使用梯度下降执行监督训练时,每步梯度计算都需要完整地运行整个网络的前向传播和反向传播。减少卷积网络训练成本的一种方式是使用那些不是由监督方式训练得到的特征。
有三种基本策略,可以不通过监督训练而得到卷积核。其中一种是简单地随机初始化它们,另一种是手动设计它们,例如设置每个核在一个特定的方向或尺度来检测边缘。最后一种,可以用无监督的标准来学习核。(使用无监督的标准来学习特征的方法,允许这些特征的确定与位于网络结构顶层的分类层相分离,然后只需提取一次全部训练集的特征,构造用于最后一层的新训练集。假设最后一次类似逻辑回归或SVM,则学习最后一层通常是凸优化问题)
随机过滤器在卷积网络中表现得出乎意料的好,当赋予随机权重是,卷积和随后的池化组成的层,自然地变得具有频率选择性和平移不变性。这提供了一种廉价的的方法来选择卷积网络的特征:首先通过仅训练最后一层来评估几个卷积网络结构的性能,然后选择更好的结构并使用更昂贵的方法来训练整个网络。
虽然随机或无监督的学习效果不错,但是与其好处是难以说清的,无监督预训练可以提供一些相对于监督训练的正则化,或者它可以简单地允许我们训练更大的结构,因为它的学习规则降低了计算成本。
如今,大多数卷积网络以纯粹监督的方式训练,在每次训练迭代中使用通过整个网络的完整的前向和反向传播。
其他的一些单元诸如9.7,9.8,9.10,9.11可以自行阅读原书。