参考
Python机器学习算法与量化交易
利用机器学习模型,构建量化择时策略
机器学习简介
机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。因为学习算法中涉及了大量的统计学理论,机器学习与推断统计学联系尤为密切,也被称为统计学习理论。
机器学习的常见算法包括:决策树、朴素贝叶斯、支持向量机、随机森林、人工神经网络、深度学习等。
策略简介
输入沪深300的行情数据到支持向量机中进行模型训练,预测沪深指数第二天的涨跌。
Why SVM?
因为数据集为沪深300的日线行情数据,总共只有几千个交易日(样本点),而SVM的小样本预测准确率较高,并且能够解决非线性分类问题,所以比较适合。
SVM简介
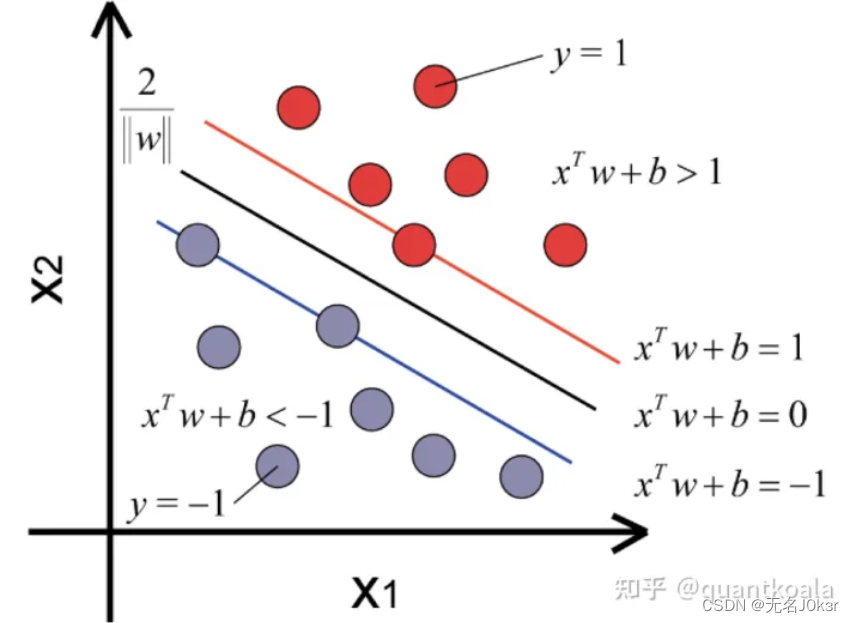
SVM最初的设计用来解决二分类问题(比如沪深指数的涨和跌),通过寻找一个最大间隔超平面(图中黑色斜线)将两类样本线性区分开,并保证两侧样本的最近边缘点到这个平面的距离最大,由于最大间隔超平面仅取决于两个类别的边缘点,例如上图中被红线和蓝线穿过的红点和蓝点,这些点就被称为支持向量。
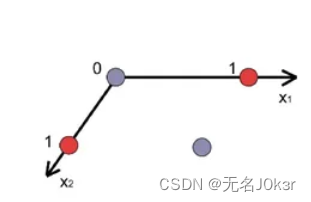
 数据集并非总是线性可分的,如下图。
数据集并非总是线性可分的,如下图。
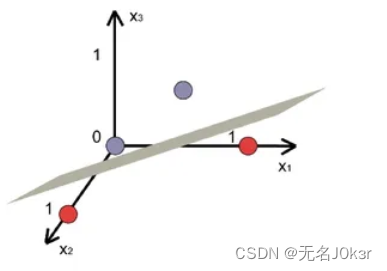
 对数据非线性可分的情况,SVM引入了核函数,将低维不可分的数据映射到线性可分的高维,如下。
对数据非线性可分的情况,SVM引入了核函数,将低维不可分的数据映射到线性可分的高维,如下。
常用的核函数有
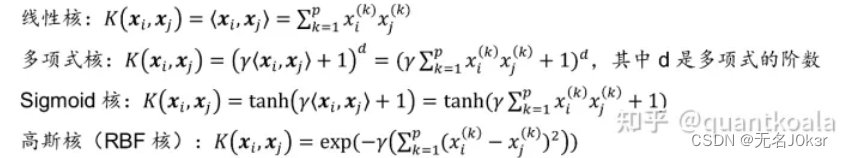 但在现实当中,由于噪声和极端样本点的存在,数据集无论在低维还是高维都可能出现线性不可分的情况,于是乎,SVM当中引入了松弛变量的概念,允许了最大间隔超平面不用完美区分两个类别,允许错误分类的存在,SVM通过惩罚系数C控制这些错误分类的容忍程度,C值越高分类准确率越高,但数值过高容易导致过拟合,C值过低则会导致准确率受损。
但在现实当中,由于噪声和极端样本点的存在,数据集无论在低维还是高维都可能出现线性不可分的情况,于是乎,SVM当中引入了松弛变量的概念,允许了最大间隔超平面不用完美区分两个类别,允许错误分类的存在,SVM通过惩罚系数C控制这些错误分类的容忍程度,C值越高分类准确率越高,但数值过高容易导致过拟合,C值过低则会导致准确率受损。
整体流程
收集数据
tushare接口
准备数据
借助TA-lib库,计算以下因子:
- EMA:加权的指数移动平均线,更重视近期值,反应价格在某个时间段的趋势。
- 价格波动率:衡量价格波动幅度的大小。
- 价格斜率:衡量价格走势的变化速度。
- RSI:衡量股价走势力量和速度,基于价格变动的大小和速度,通过计算最近一段时间内股价涨跌幅度的平均值,将过去一段时间内的涨跌幅度转化为0到100之间的数值。
- 威廉指标值:通过分析一段时间内的最高价、最低价和收盘价之间的关系来衡量市场波动的强度,在判断超买和超卖状况方面有较好的效果。
给每个样本点打上标签,计算出每个样本点第二天的涨幅,如果涨则设置标签为1,跌则设置标签为0。
建立模型
使用SVM模型
训练模型
- 将数据集的80%作为训练集,剩余20%作为测试集。
- 对数据集进行标准化处理,(原始值 - 均值) / 标准差,以尽量消除不同因子量纲的差别(如EMA均值为2919.6,而RSI均值为52.7)。
- 将训练集数据输入SVM中:实例化sklearn的svm后,把训练集因子数据和对应标签传入fit函数,惩罚系数1.0,核函数为RBF,开始训练。
测试模型
调节参数
现在使用的5个因子,还没有反应到价格波动的本质,还可以增改更多的因子。
还比如说,SVM模型当中的惩罚系数C过小,对错误样本的容忍度过高,RBF核函数不适合作为这个数据集的映射转换函数。