概述
本质
本质:很长的二进制向量(数组)
主要作用:判断一个数据在这个数组中是否存在,如果不存在为0,存在为1

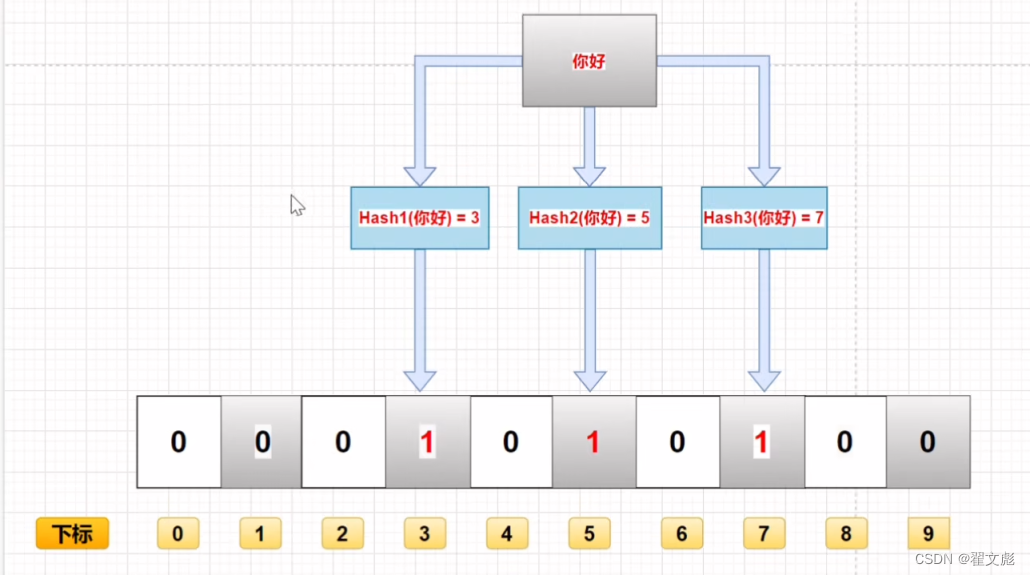
实例:将“你好”存入到布隆过滤器中——插入过程
- “你好”先经过三个(N)哈希函数,分别会计算三个哈希值
- 将三个哈希值映射到数组中,将对应下标位置改为1
查询过程:我们可以根据下标到布隆过滤器中查询数据是否存在,只有当三个下标查询的结果都为1的时候才能确认数据存在。只要有一个下标的二进制数据不是1就证明不存在。
注意,布隆过滤器很难做删除操作。
删除数据:
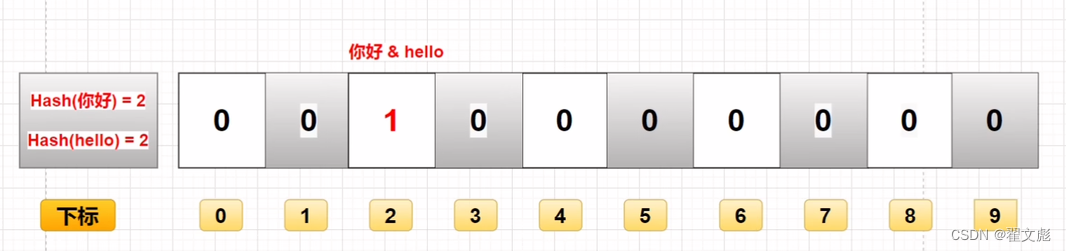
现状:下标为2的位置存储了两个数据:你好 & hello,在这种情况下,我们就不知道下标为2的这个地方是你好还是hello。这是由于这些数据由于一系列的hash运算计算出来的哈希值是相同的,哈希值相同导致根据哈希值计算出来的下标也是相同的。
这就会导致,我们在想要删除你好的时候,将下标为2的位置的数据由1改为0,这时就将hello的数据也给删除掉了,这样就会造成数据的误删除。
优缺点
优点:
- 二进制数组组成的数据,占用空间很小
- 插入和查询的速度很快,因为他是计算哈希值,再由哈希值映射到数组下标中,基于数组的特性,他的查询和插入时非常快的。只需要根据算好的下标找对应的数据即可,所以他的时间复杂度是O(N)
- 保密性非常好,他存储的数据都是0和1,别人根本不知道0和1这两个数据代表的含义是什么,并且它本事是不存储原始数据的。
缺点:
- 很难做删除的操作
- 容易出现误判,本身不存在与集合中,但是经过一系列的运算之后,他判断这个数据是存在于这个集合当中。这是由于,不同的数据计算出来的哈希值可能是相同的。
实际应用
代码实操:

误判率是会影响误判的结果的,并且误判率越低,出现误判的结果越少,但是也会造成运算的时间增长,执行效率降低。
是否可以将误判率设置的无限小呢?
- 误判率越小,计算时间越长,性能越差。
- 需要根据自己的业务情况来进行设置
误判率的底层原理
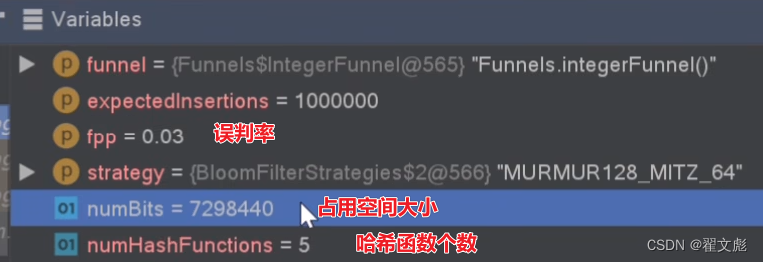
误判率为0.03的情况
误判率为0.01的情况
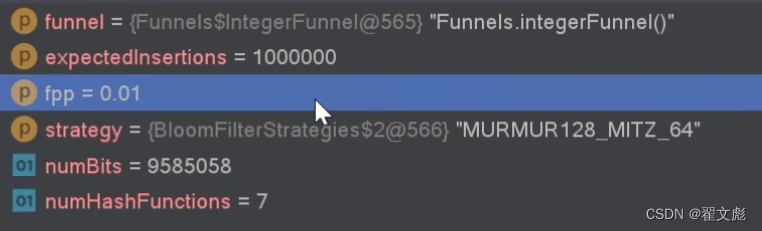
误判率越低占用的空间越大,使用的哈希函数个数越多
增加哈希函数的个数是为了降低出现哈希冲突的概率,每个哈希函数的算法是不同的,所以计算出来的结果也是不同的,哈希函数越多,计算出来的哈希值也越多,他所对应的二进制数据也越多。所以就会降低误判的个数。
解决redis缓存穿透问题:
问题描述:前端需要查询一个数据,但是redis中没有这个数据,于是就会到数据库中查询,就会导致前端请求直接打到数据库上,导致数据库压力过大。
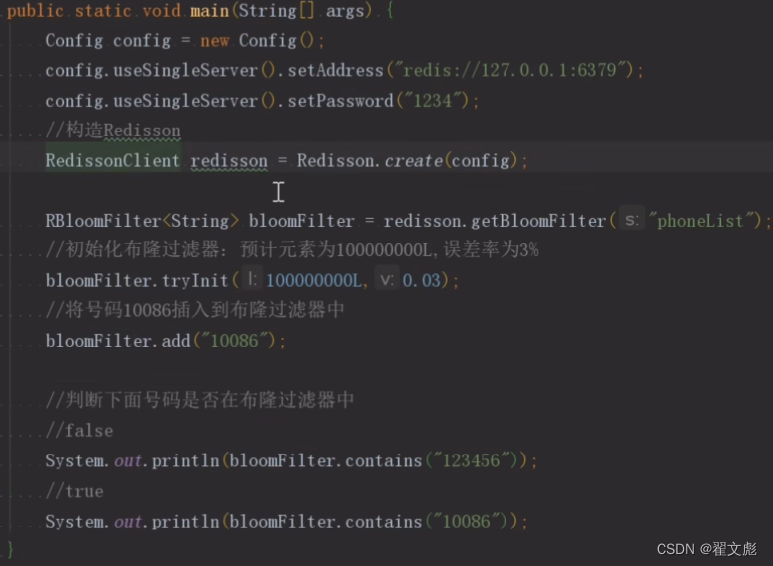
解决原理:布隆过滤器的二进制数据是全局的,若数据库中存在数据,那么布隆过滤器就会在该数据请求过后标记数据的存在. 从而避免其他大量数据库不存在的数据请求
理解:
布隆过滤器其实就是用来过滤无效请求,例如一个查询商品详情的接口,参数是 商品id,如果有人恶意用循环请求,参数是0,1,2,3这些垃圾数据,每次都要穿透redis,去请求DB,就算缓存在redis了,那时间也不会长。这个时候可以把id 放在布隆过滤器中,先去判断传入的id 是否在布隆过滤器中,存在,就去继续后续流程,如果不存在,就认为是无效id ,直接返回。