本文所有分析仅代表个人观点,不代表官方,仅供参考。
CSDN:川川菜鸟
公众号:川川带你学AI
`
‘

一、问题一

1.1 第一点
应对异常数据及打折、退货、无销售单品等情形进理。
首先说数据异常,我用到的方法:首先使用箱线图对销量的数据进行检测,大致如下:
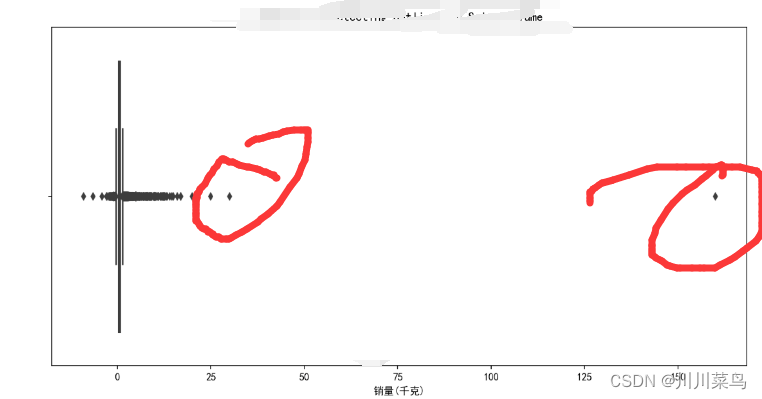
检测后如何处理呢?对检测到的异常值,我们可以用四分位的方法进行处理,用中位数替换异常值这个方法而不是直接删除。
打折销售数据分布:
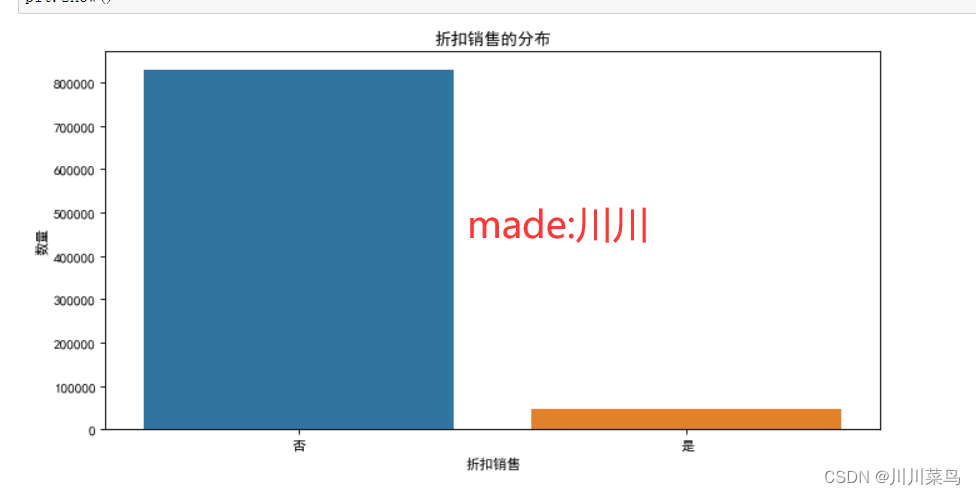
如何处理呢?这个我没有啥处理,我认为这是真实数据,就只能把“是”“否”编码为01,这样简单的映射编码。
退货数据为负数,退货的是销量,我采取的是累加处理。比如我卖出去10个土豆,然后客户反馈退了两个土豆(-2),那真实销量就是10+(-2)=8,因此我认为做累加是一种可行方式。
12 第二点
在研究品类和单品的分布及变化规律中,应考虑时间效应。
解读:在品类和单品的分布及变化规律中更明确地考虑时间效应,例如季节性、节假日影响等。我认为考虑到其中一点即可,大多数人应该是考虑季节性了,分析到即可。
数据转换:
merged_data = pd.merge(data2, data1, on='单品编码')
# 将销售日期转换为日期格式,并提取月份和季节作为新的列
merged_data['销售日期'] = pd.to_datetime(merged_data['销售日期'])
merged_data['月份'] = merged_data['销售日期'].dt.month
merged_data['季节'] = merged_data['销售日期'].dt.month % 12 // 3 + 1
merged_data['周内天数'] = merged_data['销售日期'].dt.weekday
merged_data
如下得到季节,月份,周内天:
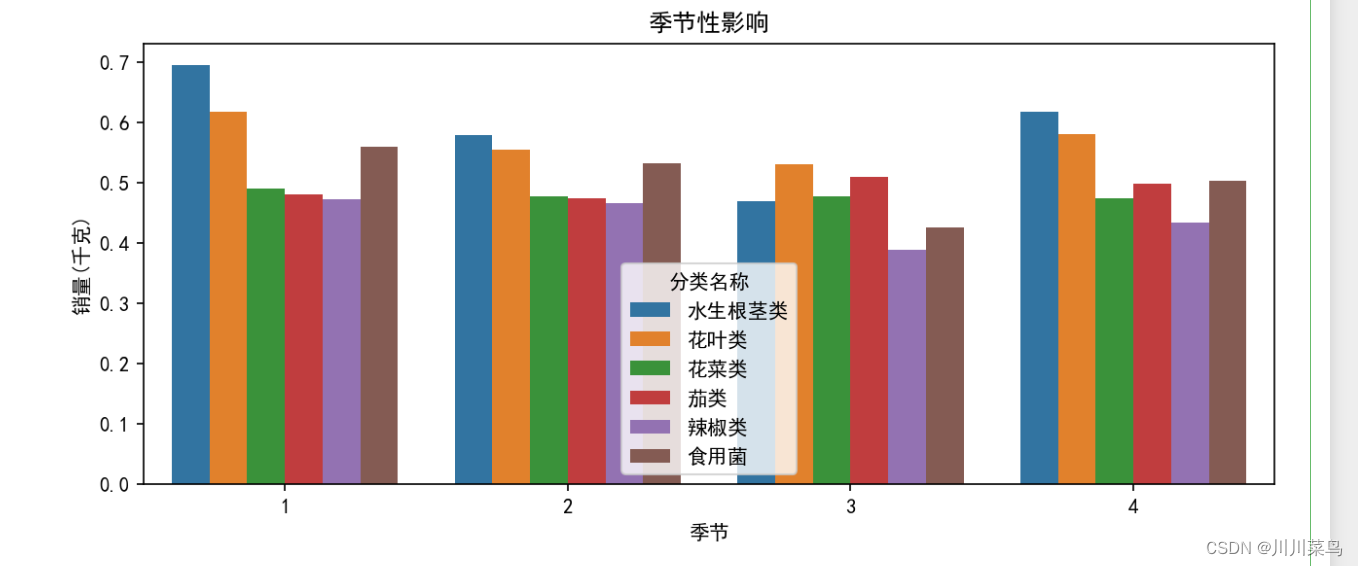
# 季节性影响
plt.figure(figsize=(10, 4),dpi=150)
seasonal_effect = merged_data.groupby(['分类名称', '季节'])['销量(千克)'].mean().reset_index()
sns.barplot(x='季节', y='销量(千克)', hue='分类名称', data=seasonal_effect)
plt.title("季节性影响")
plt.show()
# 月度影响
plt.figure(figsize=(10, 4),dpi=150)
monthly_effect = merged_data.groupby(['分类名称', '月份'])['销量(千克)'].mean().reset_index()
sns.barplot(x='月份', y='销量(千克)', hue='分类名称', data=monthly_effect)
plt.title("月度影响")
plt.show()
# 周内效应
plt.figure(figsize=(10, 4),dpi=150)
weekday_effect = merged_data.groupby(['分类名称', '周内天数'])['销量(千克)'].mean().reset_index()
sns.barplot(x='周内天数', y='销量(千克)', hue='分类名称', data=weekday_effect)
plt.title("周内效应")
plt.show()
如下:
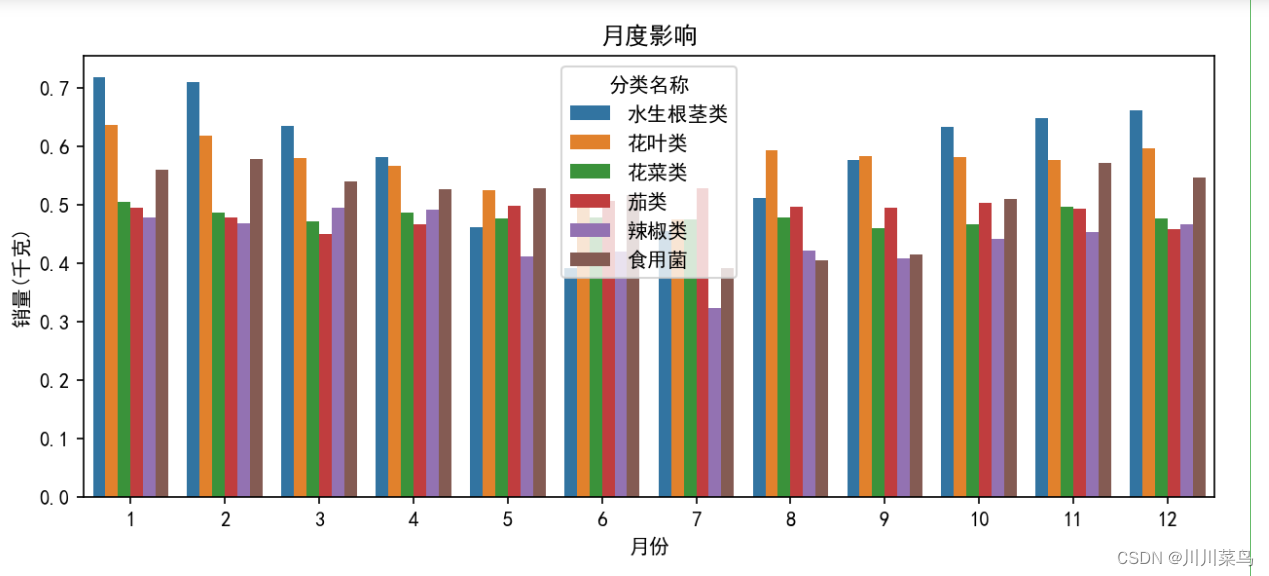
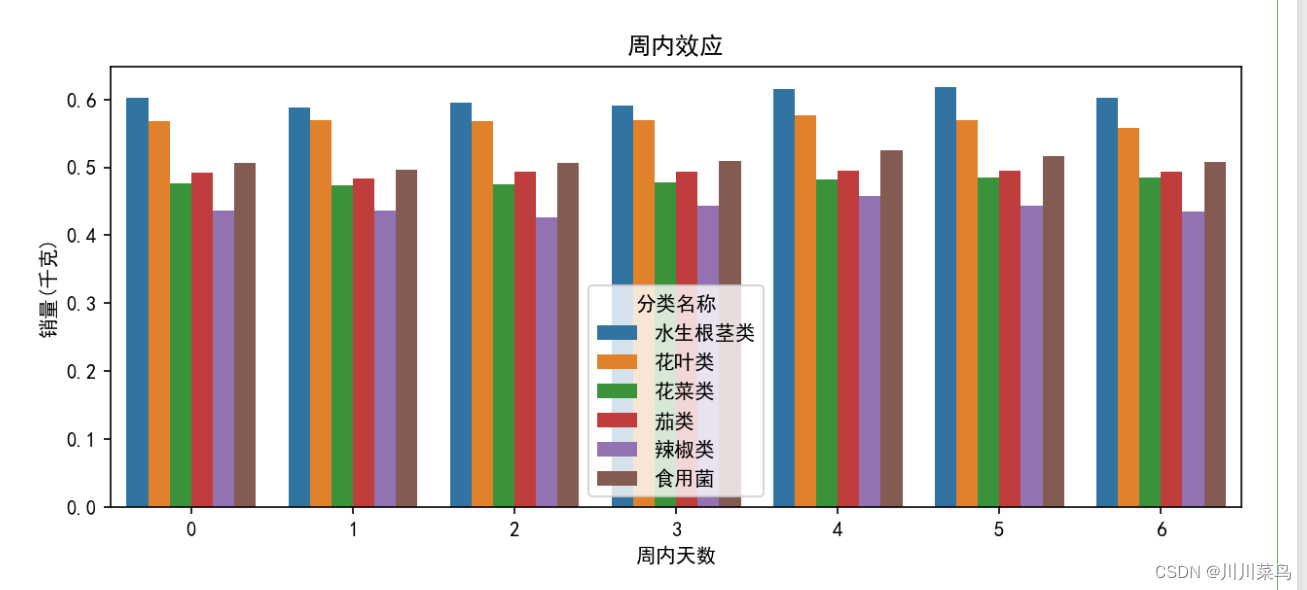
1.3 第三点
在品类及单品销量的关联性分析中,应考虑相关性分析方法的使用条件。如果对品类或单品分布类型进行讨论应予以鼓励。
首先说在品类及单品销量的关联性分析中,应考虑相关性分析方法的使用条件。这一点我对数据进行了正态性分布检测:
import scipy.stats as stats
# 可视化检查(直方图)
plt.figure(figsize=(12, 6),dpi=150)
sns.histplot(data2['销量(千克)'], bins=30, kde=True)
plt.title('销售量的直方图')
plt.show()
# 可视化检查(概率图)
plt.figure(figsize=(12, 6),dpi=150)
stats.probplot(data2['销量(千克)'], plot=plt)
plt.title('销售量的概率图')
plt.show()
# 计算偏度
skewness = data2['销量(千克)'].skew()
print(f"数据的偏度: {skewness}")
# 正态性检验(Shapiro-Wilk检验)作用:便于我们后面的相关性里面选择哪个方法
_, p_value = stats.shapiro(data2['销量(千克)'])
print(f"Shapiro-Wilk检验的p值: {p_value}")
# 根据p-value判断是否符合正态分布
alpha = 0.05
if p_value > alpha:
print("数据呈正态分布(无法拒绝 H0)")
else:
print("数据未呈正态分布(拒绝 H0)")
结果如下:
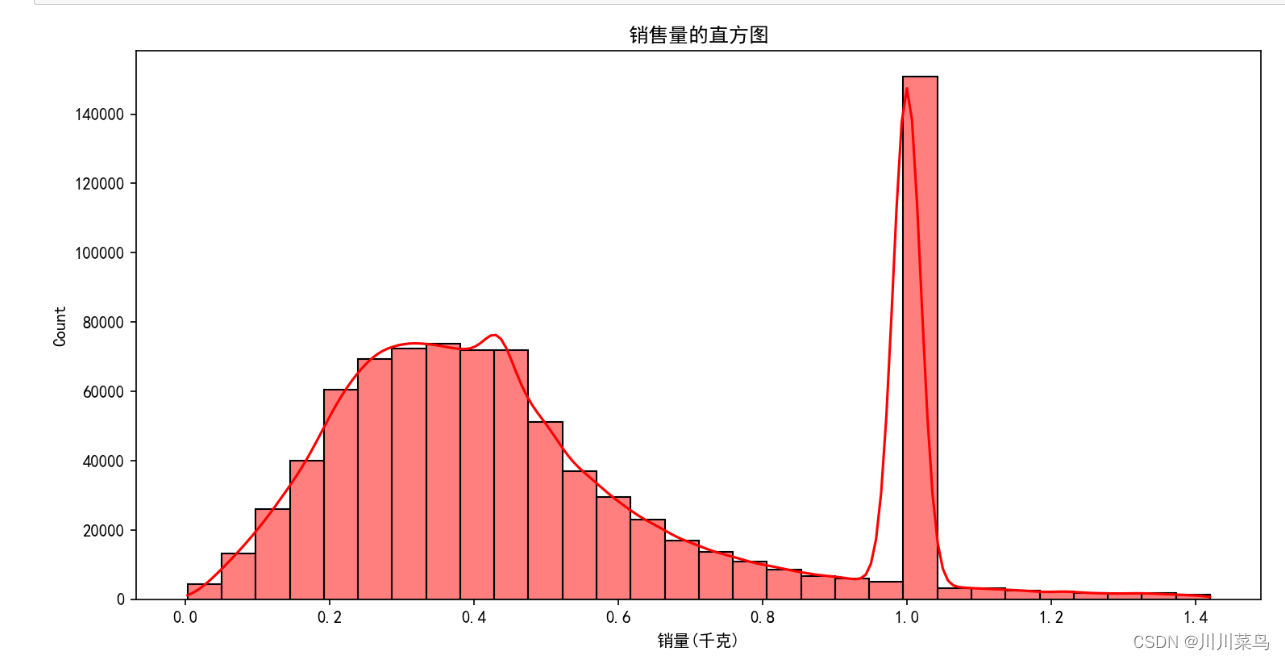
数据的偏度: 0.6795134003514179
Shapiro-Wilk检验的p值: 0.0
数据未呈正态分布(拒绝 H0)
肯定不是符合皮尔逊的前提要求了,所以使用斯皮尔曼进行相关性可视化分析。
Pearson相关性系数(对于正态分布的数据)或Spearman和Kendall秩相关性系数(对于非正态分布或顺序数据)
1.4 第四点
仅做简单的可视化,统计描述是不够的。
首先,统计描述和一些可视化是必须的,不能没有。在这些已有的数据中,我们可以分析很多可视化,每一个可视化都会有一定的分析结果。这里我不做展示。
比如这样的一个柱形分布:
以及热力图:
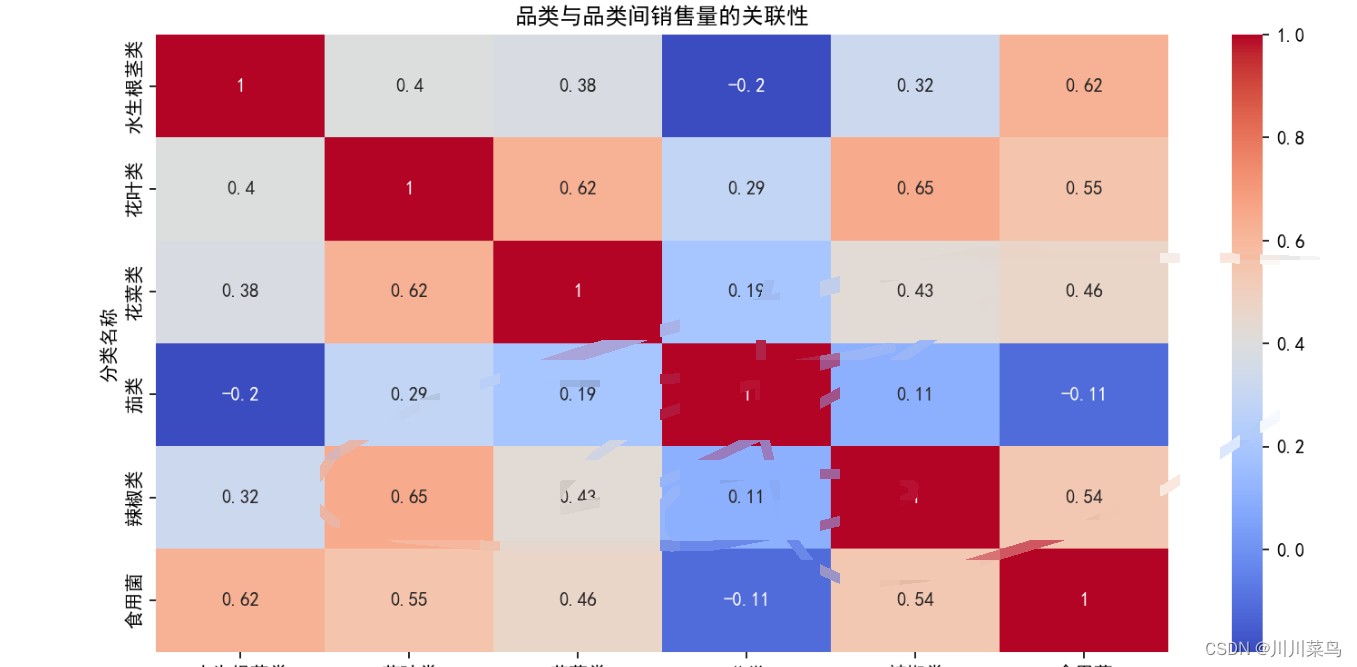
以及扇形图:
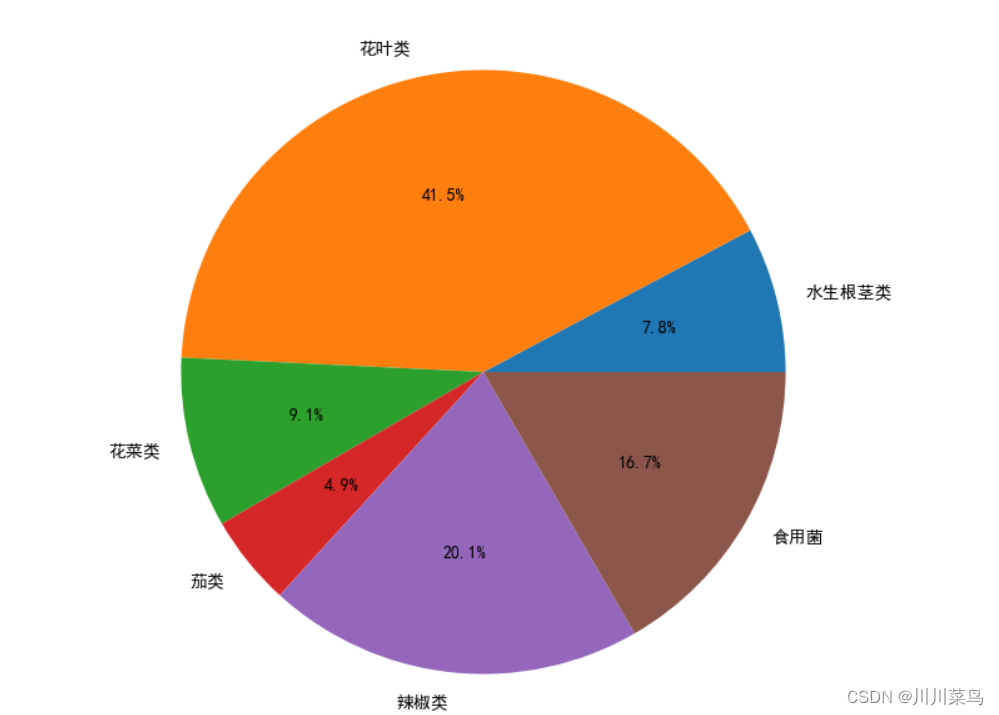
等等,这些我认为都是必须做出一些分析的,不仅仅是展示图,每一个图都有一定的意义。
问题二

第一点
从定性和定量两个方面分析销售量与各品类的补货量和价格之间是否相关:若相关,应建立定量关系模型。
在这一点中,我所做的方法是:使用了ARIMA模型和遗传算法来预测销售量,并制定了补货和定价策略。
定性分析:通过业务逻辑和市场调研来分析补货量和价格对销售量的影响。例如,高价格可能会降低销售量,但也可能提高总收入。
定量分析:使用统计测试(斯皮尔曼相关性)来量化补货量和价格与销售量之间的关系。
第二点
从机理的角度考虑补货量与价格相互依赖的关系是一种好的处理方式。
补货量和价格确实在现实业务中有相互依赖的关系正常应该如下:
- 高价格可能导致需求下降,因此补货量应相应减少。
- 低补货量可能导致缺货,从而促使提高价格以平衡需求
可以用可视化来展示一下即可吧:
import seaborn as sns
import matplotlib.pyplot as plt
grouped_data=merged_data
# Create a subset of the data for visualization
subset_data = grouped_data[['销售日期', '单品名称', '单次销量(千克)', '单位总成本', '推荐售价']].copy()
subset_data['销售日期'] = pd.to_datetime(subset_data['销售日期'])
subset_data.set_index('销售日期', inplace=True)
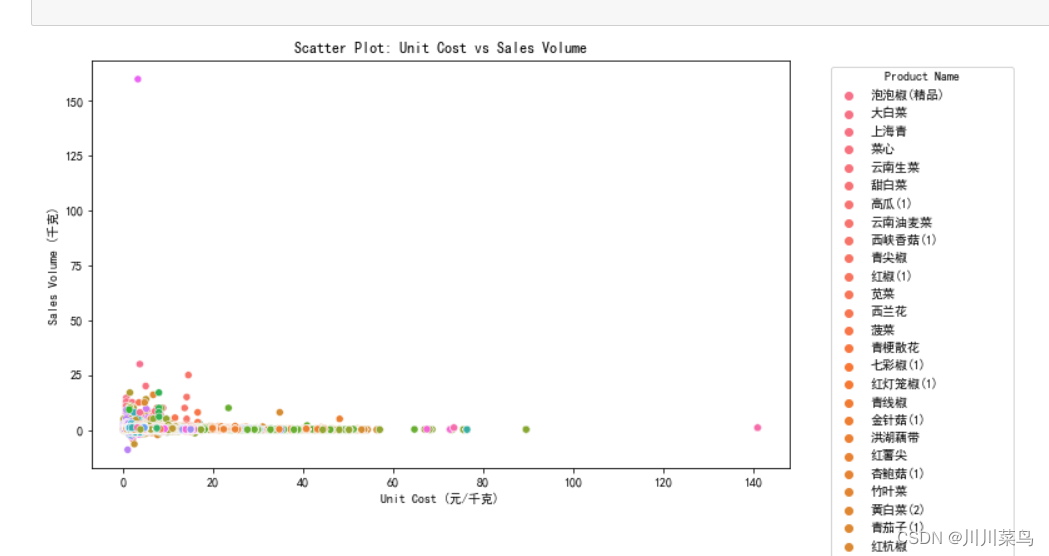
# 1. 散点图
plt.figure(figsize=(10, 6))
sns.scatterplot(data=subset_data, x='单位总成本', y='单次销量(千克)', hue='单品名称')
plt.title('Scatter Plot: Unit Cost vs Sales Volume')
plt.xlabel('Unit Cost (元/千克)')
plt.ylabel('Sales Volume (千克)')
plt.legend(title='Product Name', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.show()
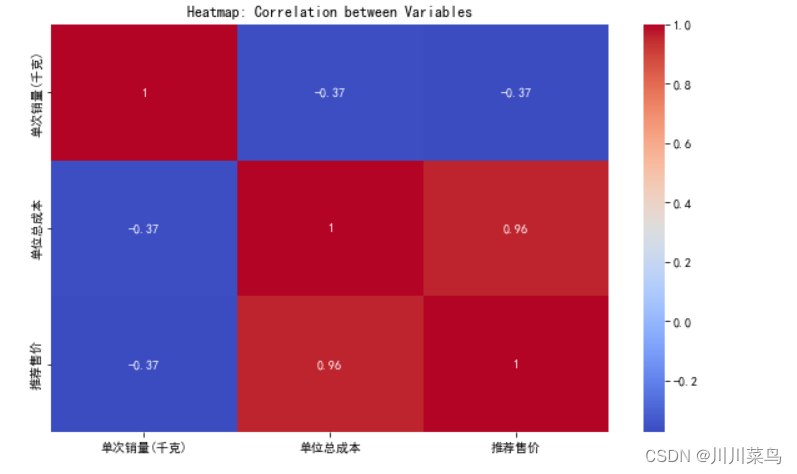
# 2. 热力图
correlation_matrix = subset_data.corr()
plt.figure(figsize=(10, 6))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')
plt.title('Heatmap: Correlation between Variables')
plt.show()
# 3. 多维度平行坐标图
from pandas.plotting import parallel_coordinates
top_5_products = subset_data['单品名称'].value_counts().index[:5]
subset_top_5 = subset_data[subset_data['单品名称'].isin(top_5_products)]
plt.figure(figsize=(12, 6))
parallel_coordinates(subset_top_5, '单品名称', cols=['单位总成本', '推荐售价', '单次销量(千克)'])
plt.title('Parallel Coordinates Plot: Multi-Dimensional Analysis')
plt.legend(title='Product Name', bbox_to_anchor=(1.05, 1), loc='upper left')
plt.show()
)散点图
)热力图
)平行坐标图
第三点
应考虑数据的时间因素,例如季节性、周期性、节假日、趋势性等。
这里和问题一类似,依然需要考虑时间因素,毕竟他是时间序列。我使用了ARIMA(自回归整合移动平均模型)和LSTM(长短时记忆网络)进行了时间序列分析,这两种模型都能捕捉到数据的季节性、周期性和趋势性。然而,对于节假日因素,这两种模型没有直接进行处理(忘了分析这个了)
感兴趣同学,节假日的影响可以使用更高级的时间序列模型,如Facebook的Prophet模型,自行去尝试,参考代码:
from fbprophet import Prophet
product_data = product_data.rename(columns={
'销售日期': 'ds', '单次销量(千克)': 'y'})
model = Prophet(yearly_seasonality=True, weekly_seasonality=True, daily_seasonality=False)
model.fit(product_data)
future_dates = model.make_future_dataframe(periods=365) # assuming you want to forecast the next 365 days
forecast = model.predict(future_dates)
fig = model.plot(forecast)
第四点
应给出各品类未来一周的补货量与定价的具体结果,须体现工作日与双休日的区别。
我通过时间序列的预测算法和遗传算法,最终给出了预测的补货量和定价策略,这个没有具体参考答案,合理即可。
关于工作日和周末,可以在时间序列模型中加入一个“是否为双休日”这样的变量,或者单独对工作日和双休日的数据进行模型训练和预测,从而得到不同的补货量和定价策略。PS:这一点我没有做,根本没想到就预测这么几天的数据,还要考虑周末的。
问题三
第一点
确定各品类中可替代或互补的单品,例如可以通过相关性分析对各品类中的单品进行分类等。
我的理解就是各单品之间的相关性,用热力图表示进行分析即可。相关性分析可以帮助我们理解两个变量之间的关系。如果两个单品的销售量有很高的正相关性,那么它们可能是互补的。相反,如果它们有很高的负相关性,则可能是可替代的。
第二点
在考虑单品可替代性、互补性的前提下,给出商品品种多样性的量化方法,满足商品需求量和品种多样性的约束
单品可替代性和互补性: 通过相关性分析和聚类方法,具体为斯皮尔曼相关性和Kmeans+手肘法。
商品品种多样性的量化方法:可以考虑Shannon多样性指数。
# 计算总销售量
total_sales = forecast_results_new_method['预测销量_2023-07-01'].sum()
# 计算每种商品的相对丰度(这里使用预测的销售量)
forecast_results_new_method['relative_abundance'] = forecast_results_new_method['预测销量_2023-07-01'] / total_sales
# 计算Shannon多样性指数
shannon_diversity_index = -np.sum(forecast_results_new_method['relative_abundance'] * np.log(forecast_results_new_method['relative_abundance']))
shannon_diversity_index
值为:3.83996693368468,这里我认为可做的解释为商品品种具有相当高的多样性
第三点
求解可以借鉴问题2的模型与方法,但须明确品类与单品决策之间的差异。
主要差异如下:
- 决策层次:问题二更侧重于品类层次的决策,而问题三则需要在单品层次上做决策。具体到单品,还涉及到库存控制和定价策略。
- 约束条件:问题三具有更多的约束,如单品数量必须在27-33个之间,每个单品的最小陈列量等。
- 目标函数:问题二主要关注于最大化不同品类的总收益,而问题三则需要在满足各种约束的情况下,找出最优的单品组合以最大化收益。
- 方法应用:虽然问题二和问题三都可以应用类似的预测模型和优化算法(如ARIMA、遗传算法等),但在问题三中,可能还需要应用其他的方法,如相关性分析,以确定哪些单品可以替代或互补。
与第二问的主要区别是增加了很多的约束,我依然使用了启发式算法和时间序列的算法进行实现。在我的解决方案中,我已经考虑了这些差异,并针对问题三的特点进行了模型构建和求解。
第四点
鼓励有不同模型或优化方案下的结果对比。
这个做模型对比的话,可以对比时间序列的不同,启发式算法的不同。
问题四
第一点
给出建议收集的新数据,例如经营类数据(日补货量,库存表,日损耗率等),外部数据(天气类等)、消费者数据等,并说明理由(如何利用新数据改进模型)
日补货量理由:
- 了解每天的补货量有助于更准确地估算实际的库存量和随后的销售量。
- 如何利用:用于改进库存管理模型,进一步细化需求预测。
库存表:
- 库存数据可以帮助了解哪些商品更容易缺货或积压。
- 如何利用:用于优化补货策略,减少缺货和滞销风险。
日损耗率:
- 理由:每日的损耗率数据可以帮助更准确地预测实际可销售的商品量。
- 如何利用:整合到销售预测模型中,以提高预测准确性。
天气数据:
- 理由:天气条件(如温度、降水量)可能影响某些蔬菜的销售。
- 如何利用:作为预测模型的一个特征,以考虑其对销售的潜在影响。
节假日和活动日历:
- 理由:特殊日子(如节假日、促销活动日)通常会影响销售。
- 如何利用:用于模型中以考虑这些因素对销售的影响。
消费者购买历史:
- 理由:了解消费者的购买习惯可以帮助进行更个性化的推荐和库存管理。
- 如何利用:用于推荐系统以增加销售。
消费者反馈和评价:
- 理由:消费者的反馈可以用来了解哪些商品更受欢迎或存在问题。
- 如何利用:用于改进商品质量和调整库存。
第二点:
分析数据收集的可行性、经济性等因素。
PS:我认为不用实际的去收集数据,只需要描述清楚即可。
整体分析说明
问题一为常见的数据分析,需要有统计描述,不同类别方向分可视化分析。
问题二为预测+优化,但是约束几乎没有。因此你可以使用相关时间序列算法,以及启发式算法(差分进化、遗传、模拟退火等)
问题三:主要在问题二基础上增加了更多的约束,依然为预测+优化。
问题四:开放题,但要结合题目。