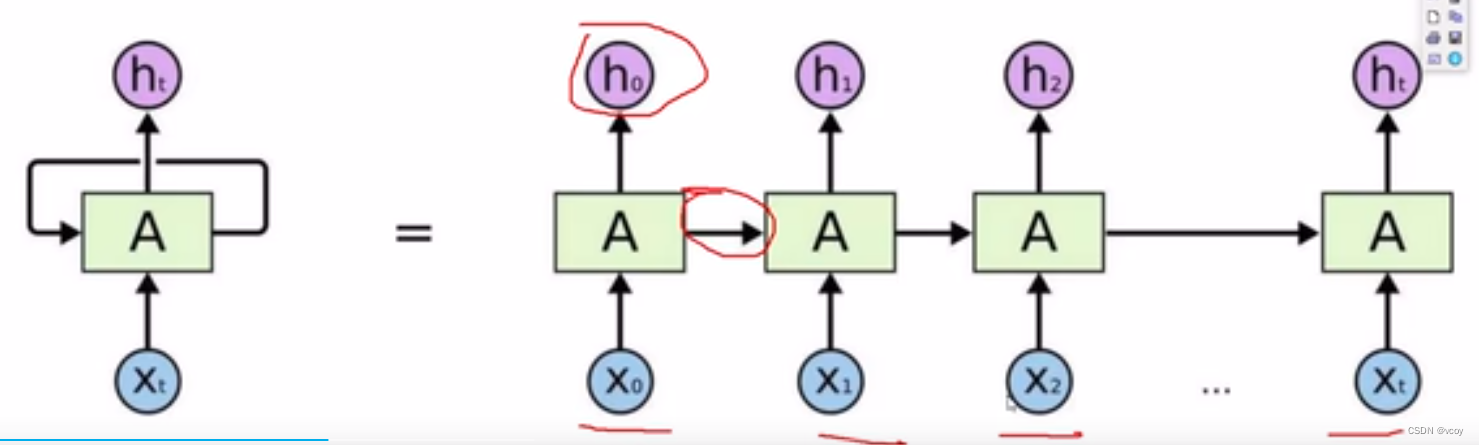
1.传统RNN网络
每一层都需要上一层执行完才能执行
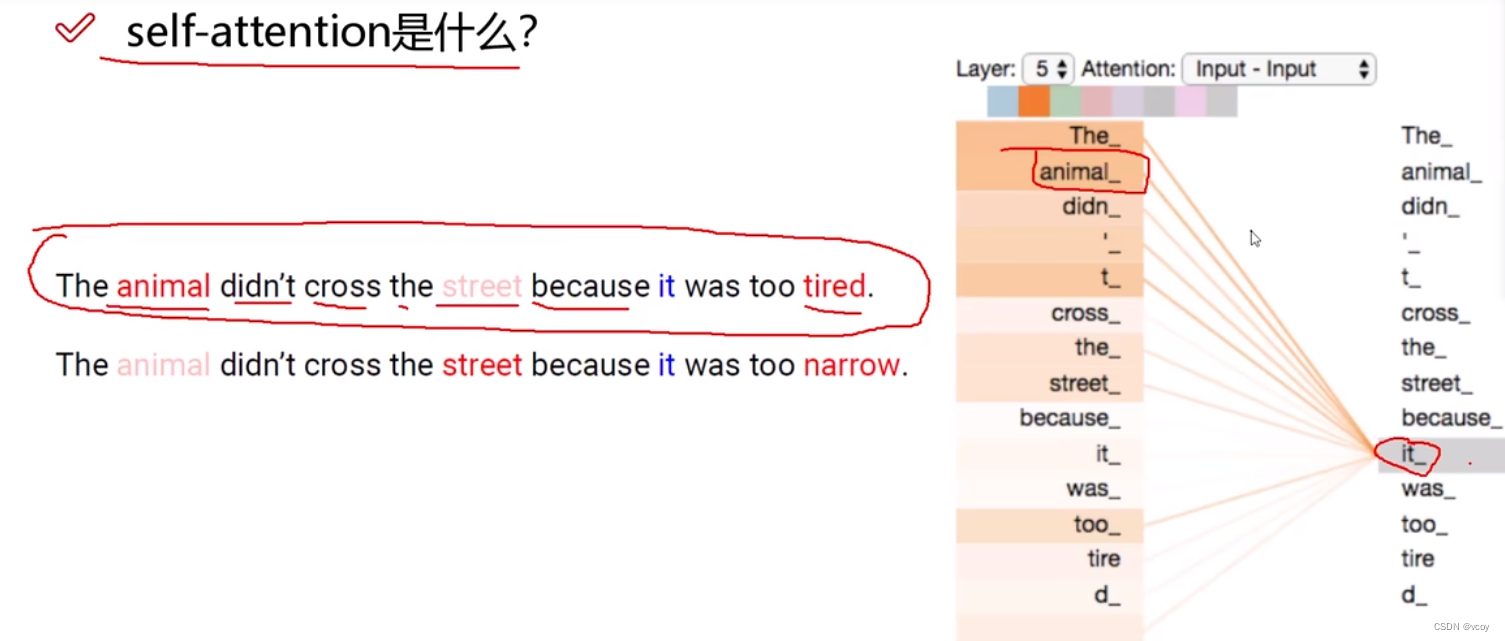
1.1 自注意力
在一句话中找到
it_指代的是什么,它的上下文语境是什么?
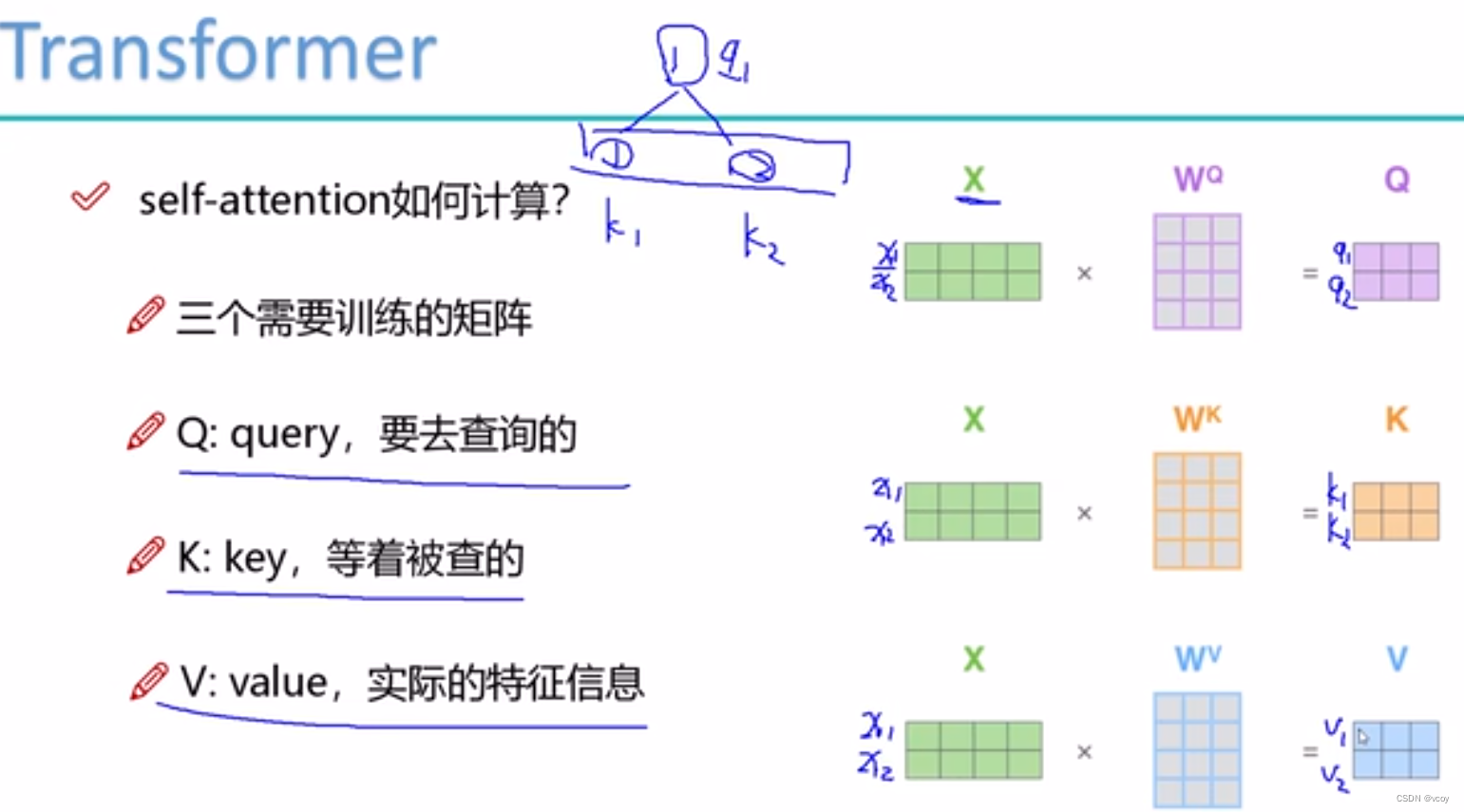
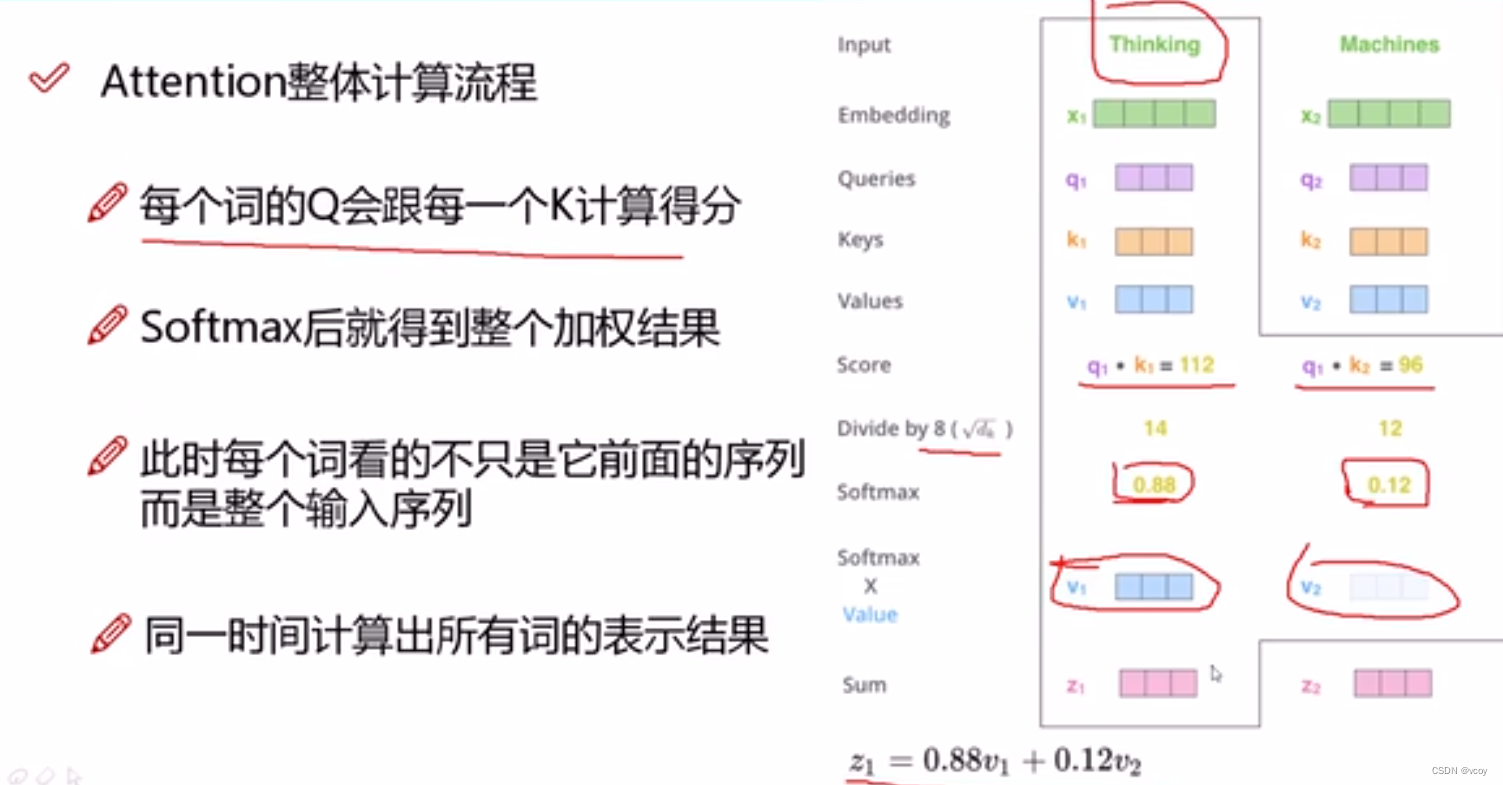
self-attetion计算



1.2 multi-header机制
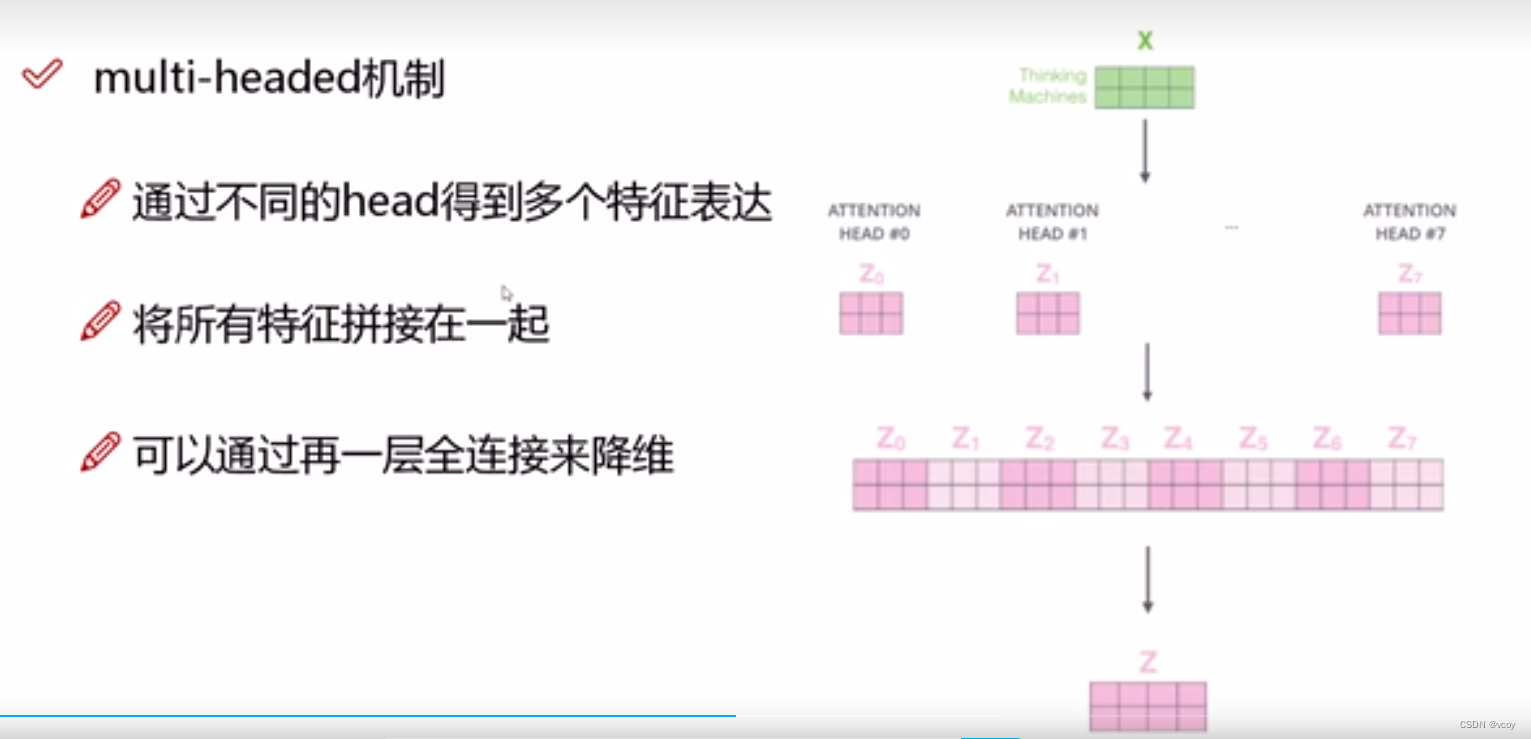
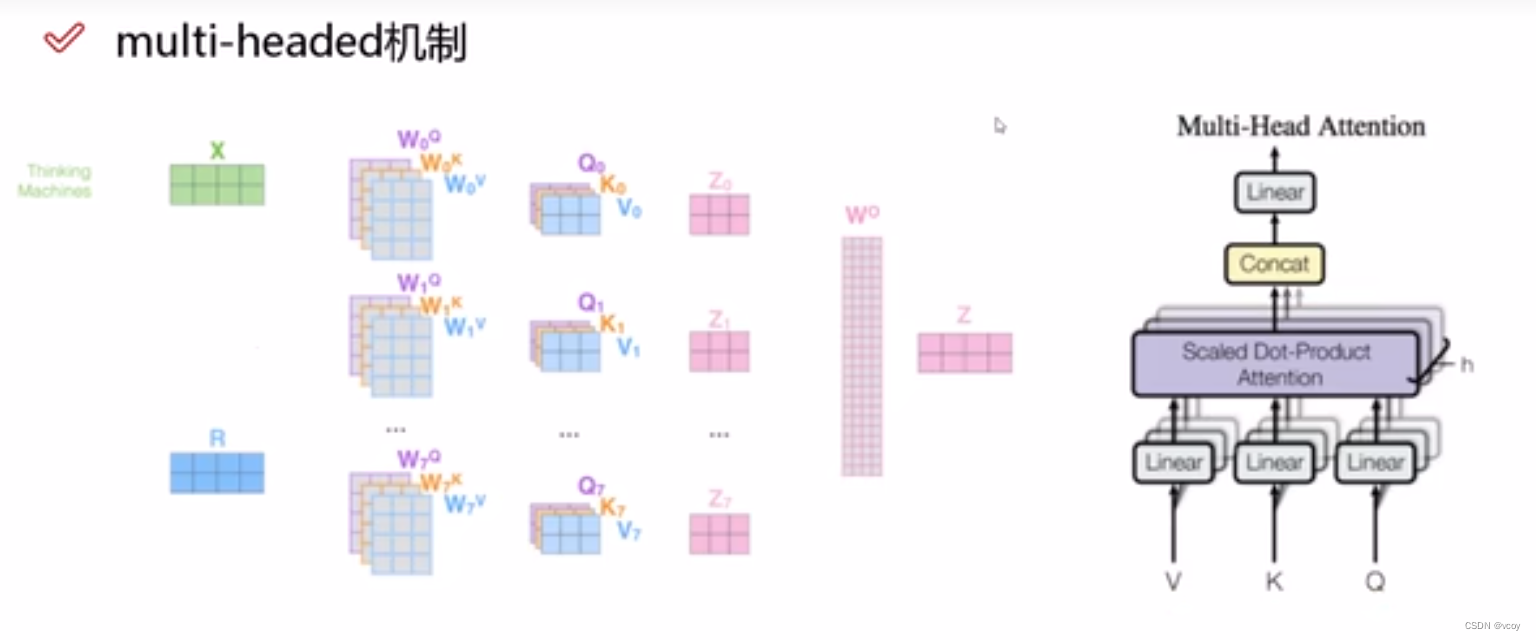
1.3 堆叠多层self-attention,相当于再一次卷积

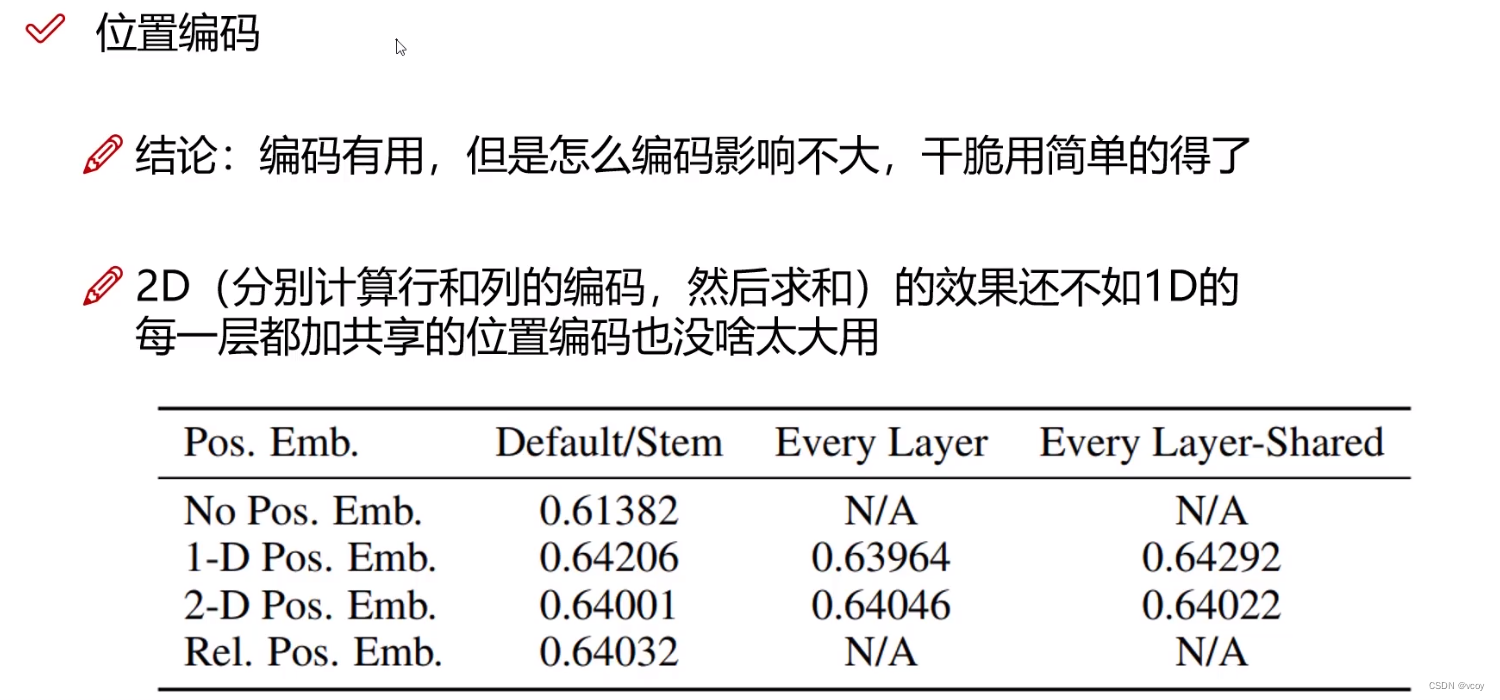
1.4 位置信息编码

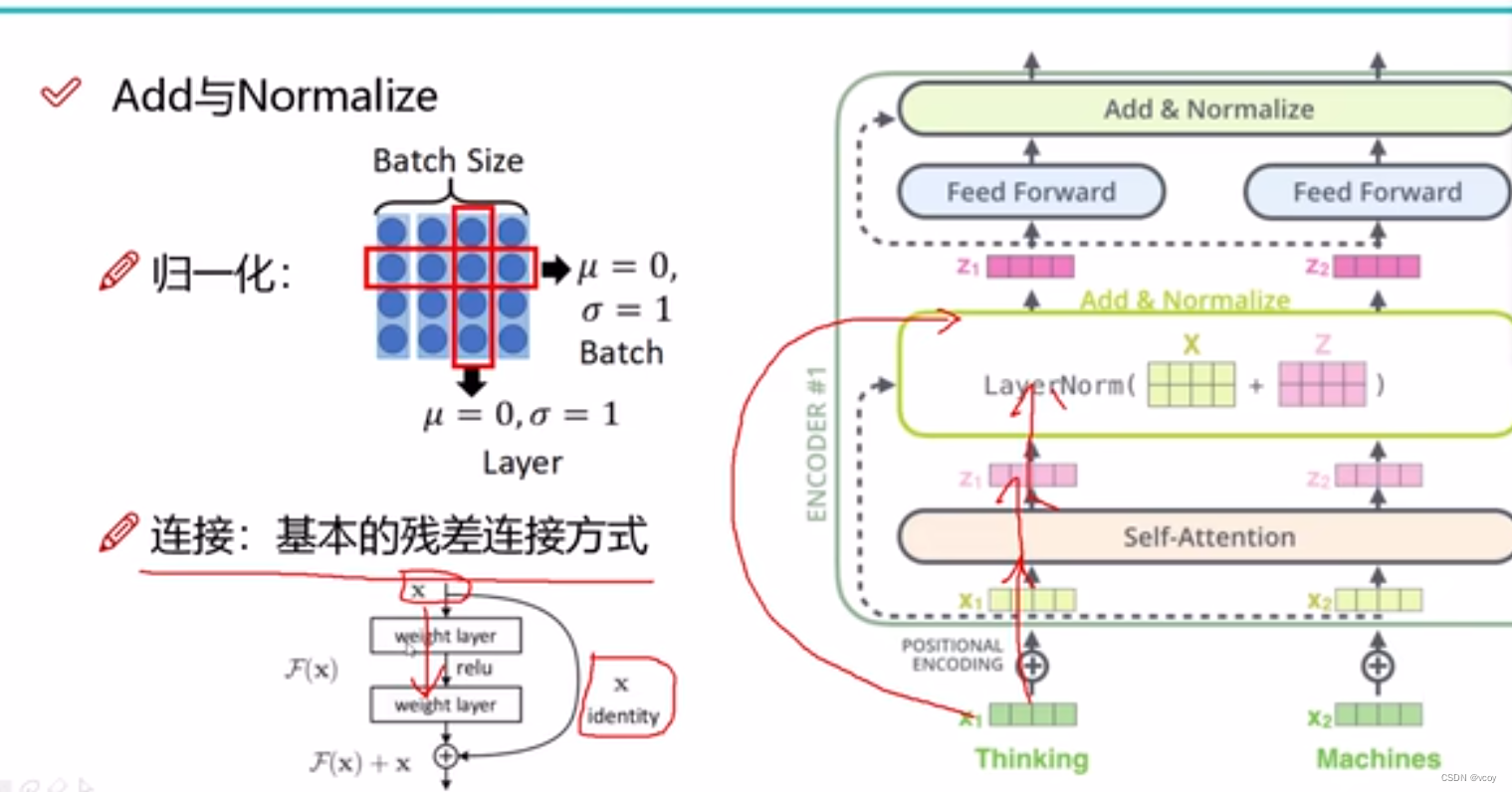
1.5 残差连接与归一化
归一化(让训练速度更快更稳定),u=0是均值为0,=1是指标准层为1
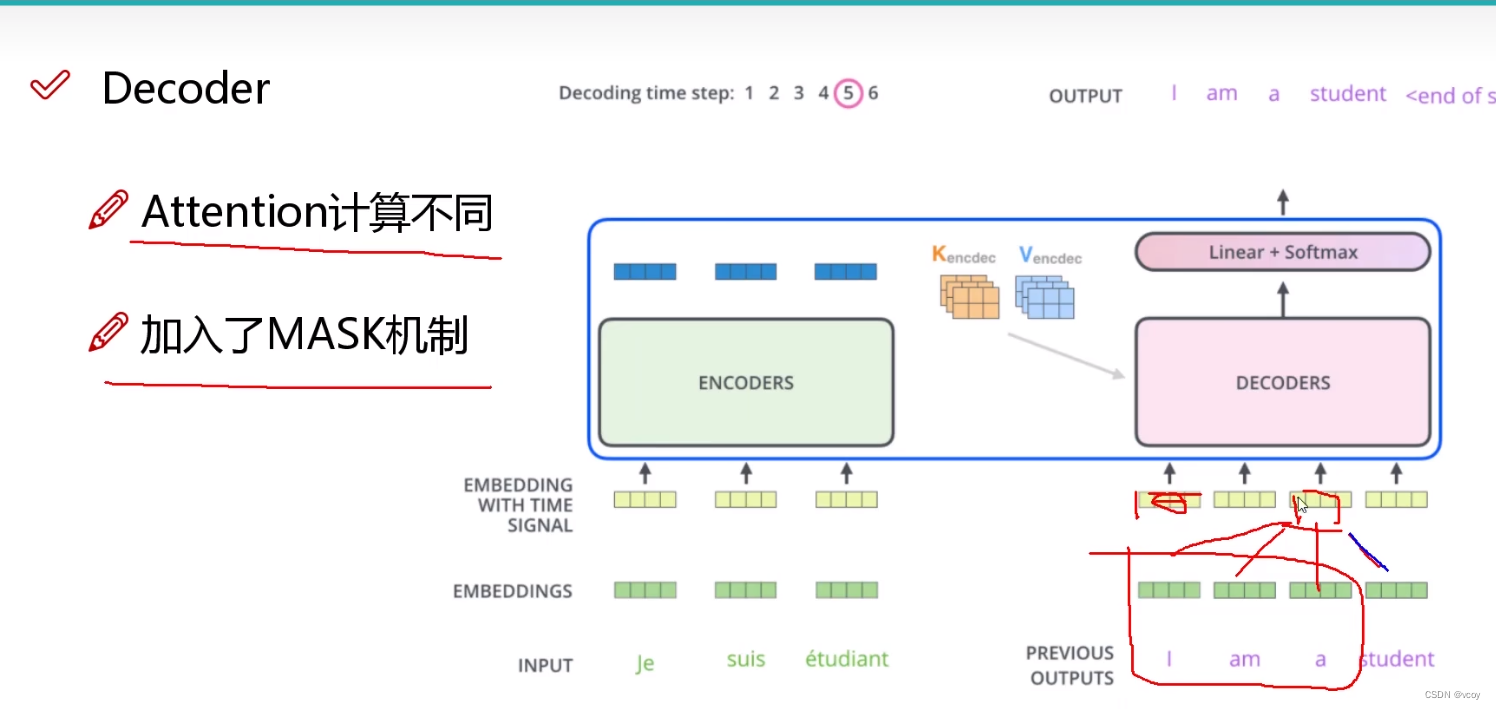
1.6 decoder
其他的和encoder一样
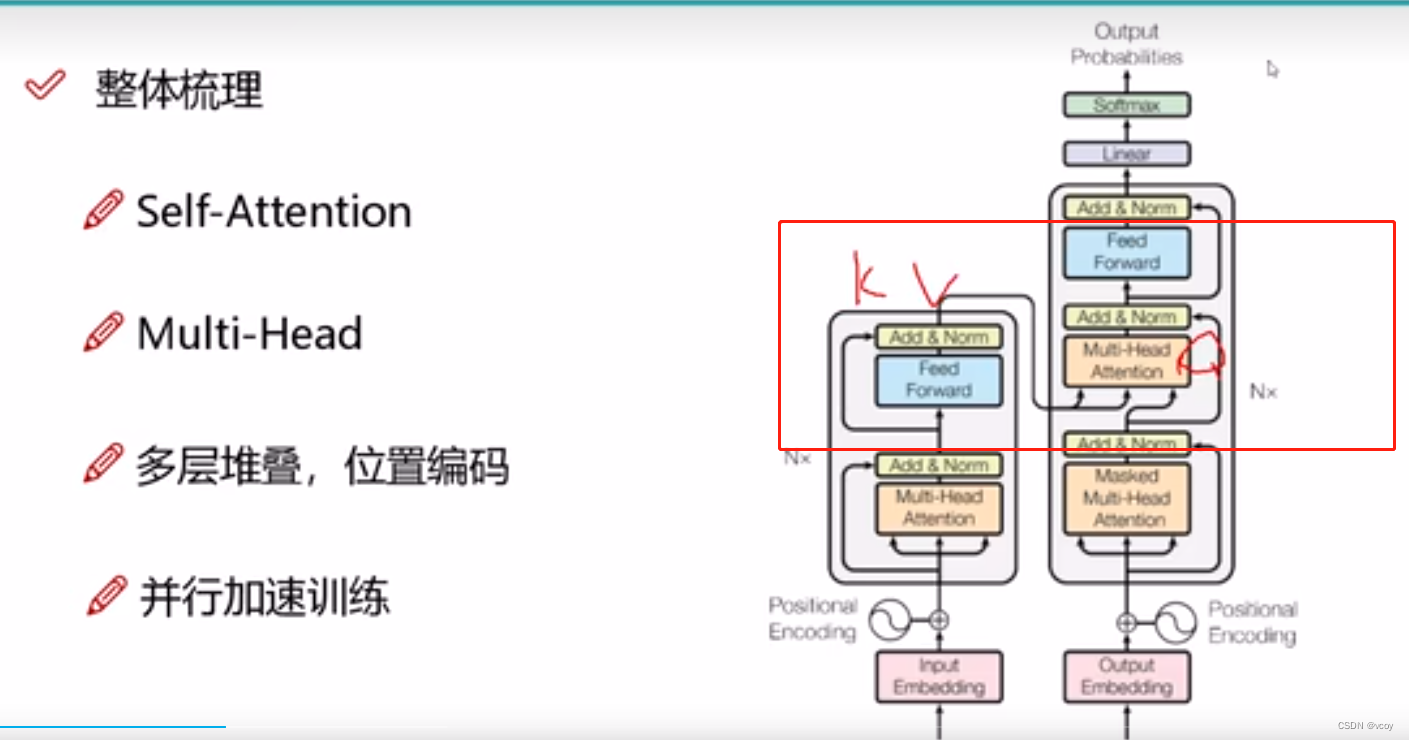

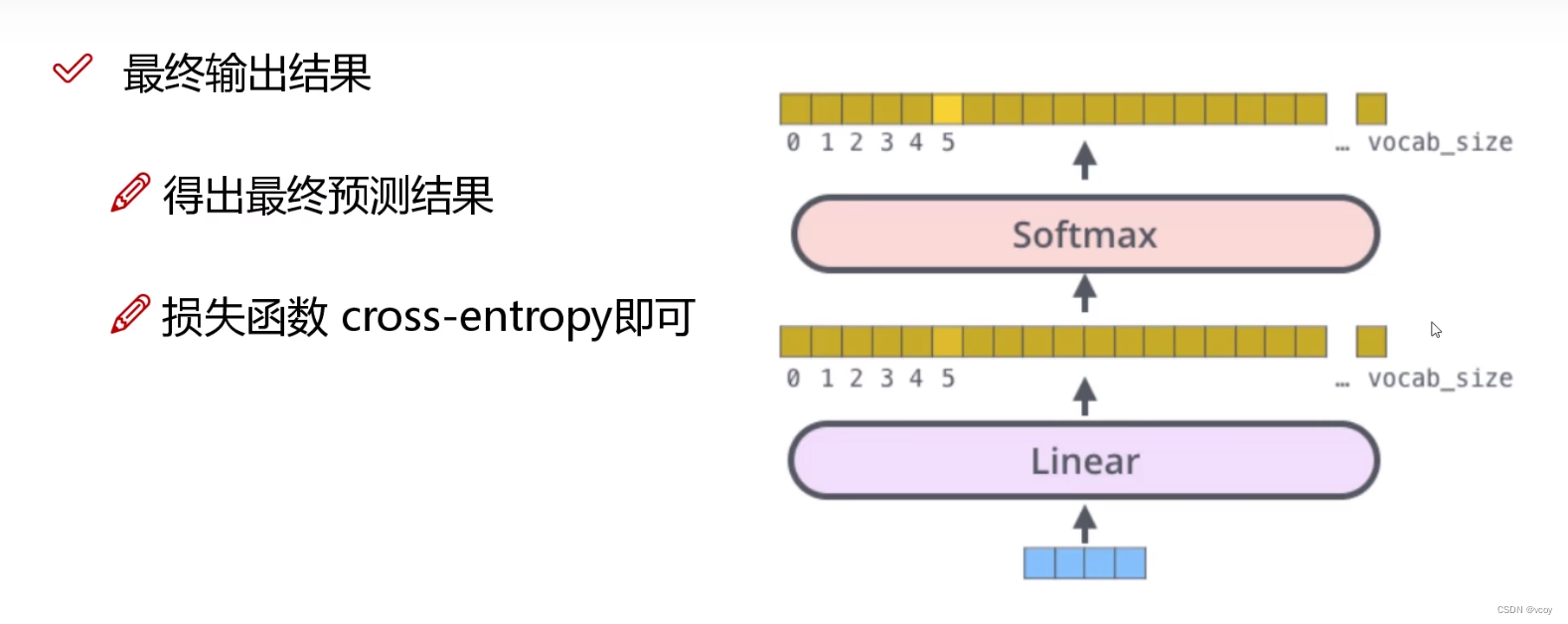
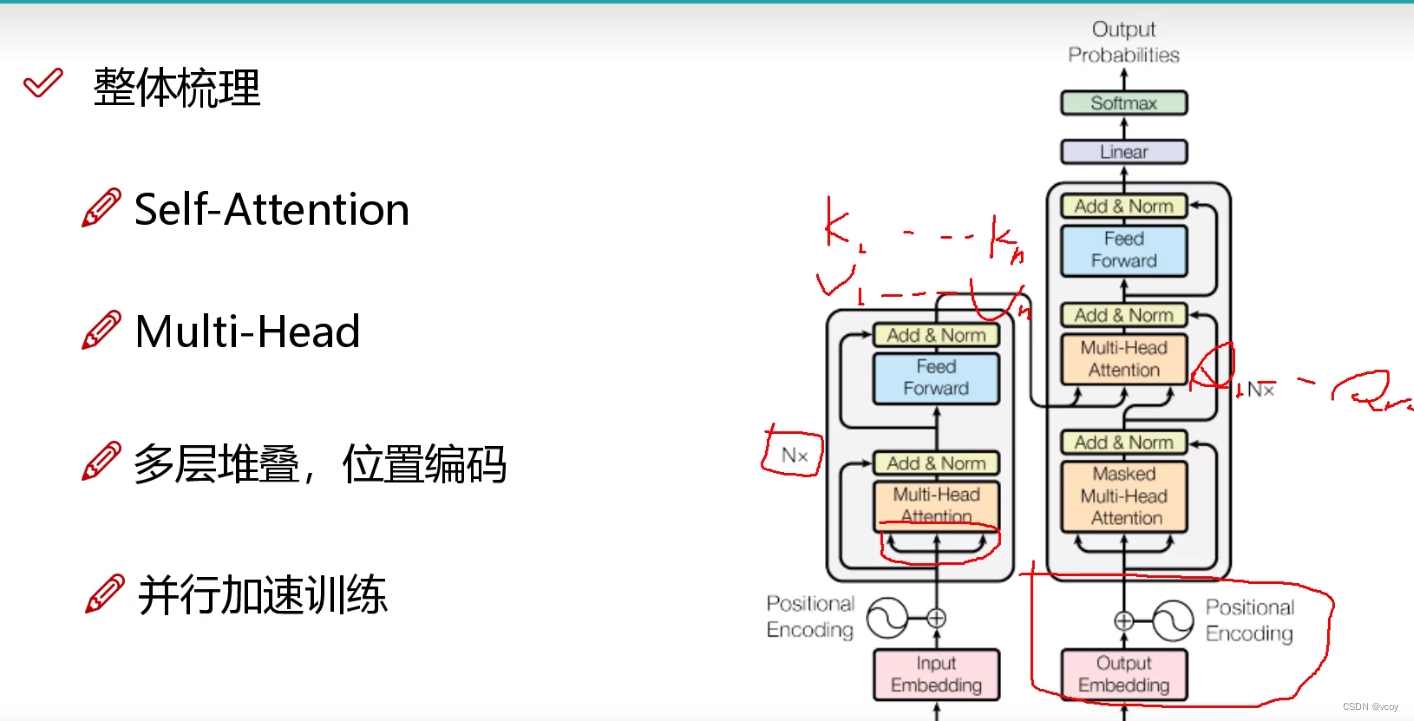
1.7 整体架构
encoder:输入文本序列,进行多次(N次)的encoder(self-attention),然后进行多头的self-attention(multi-head attention),可能越学越差,因此加入残差连接和归一化。
dcoder:加入掩码,输入为encoder的k1…kn和v1…vn序列,及decoder的q1…qn。其他和encoder一样
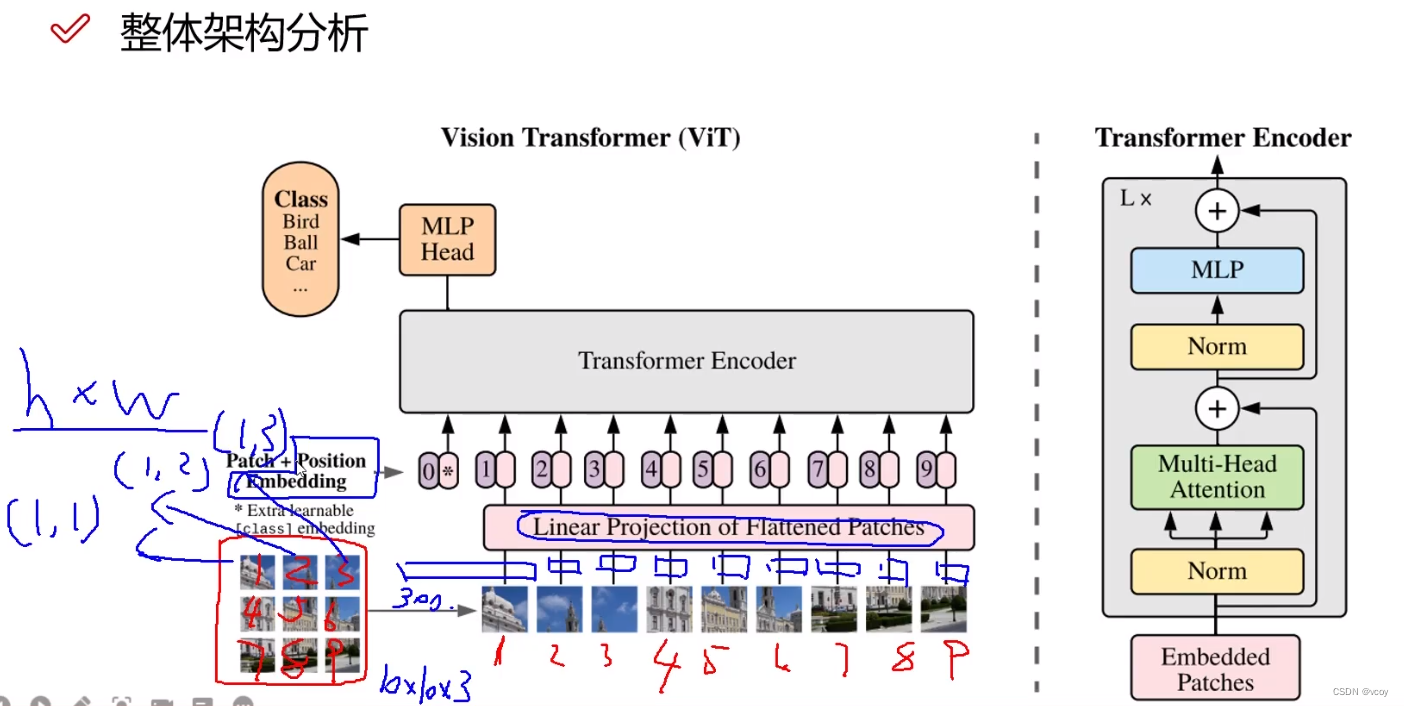
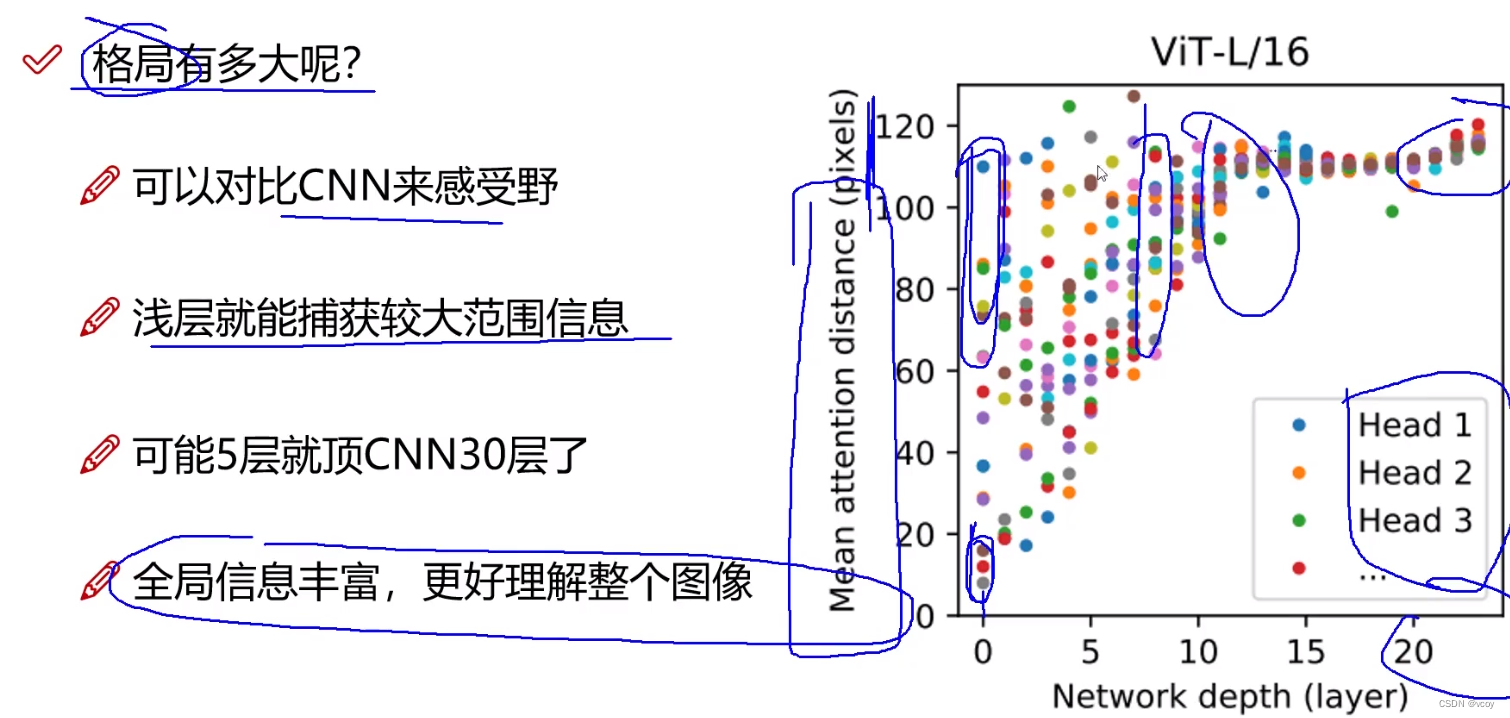
2 处理图像架构VIT
图像经过卷积提取出特质,然后将其转换为300的向量。然后将向量经过全连接层,如把300维的向量映射为256的(特征重新整合)。
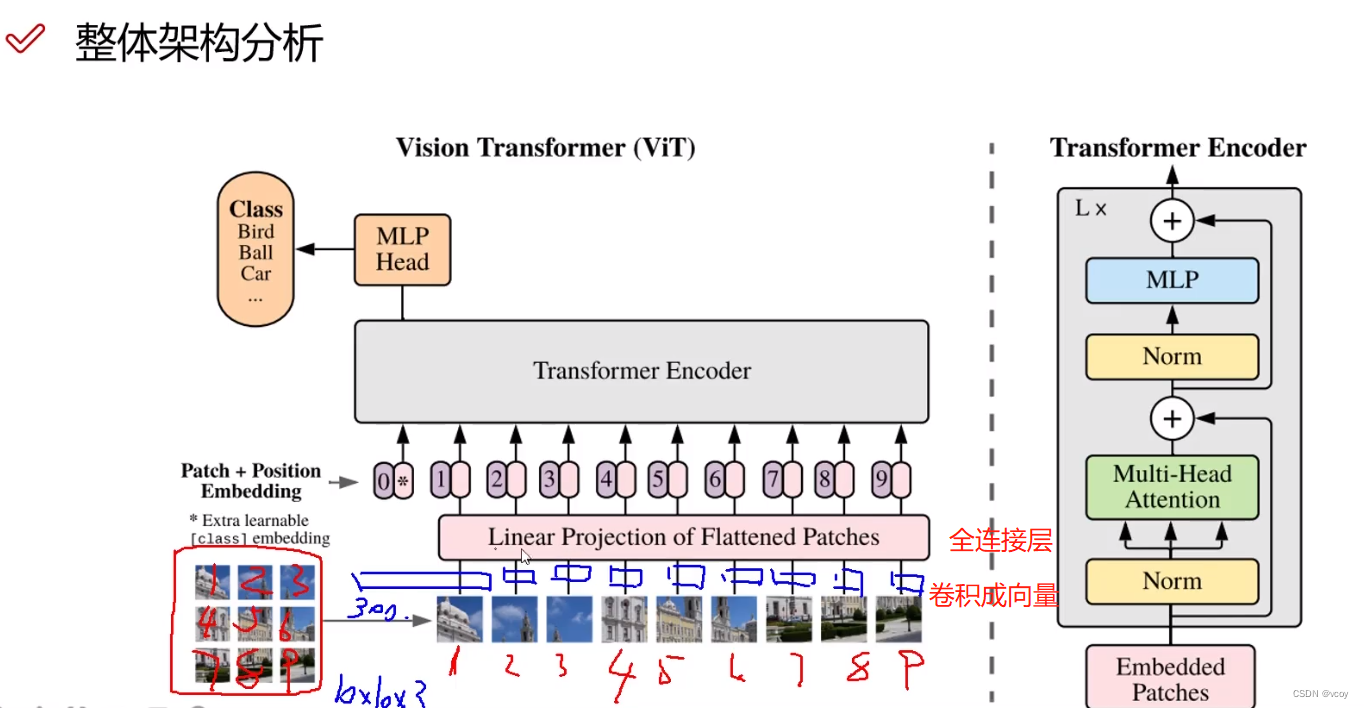
2.1 VIT图像分割后位置编码
vit中方式1:不加位置编码;方式2:二维形式比位置编码;方式3:分割顺序位置编码。
位置编码中0不是所有任务都用到,一般用于分类,在分割检测时候就没有了。
经过encoder将图像转换为一种计算机可以识别的特征形式。
在处理分类任务时会将1-9的结果整合到0,然后用0性*特征向量驱处理分类。
0-9分别是10个token
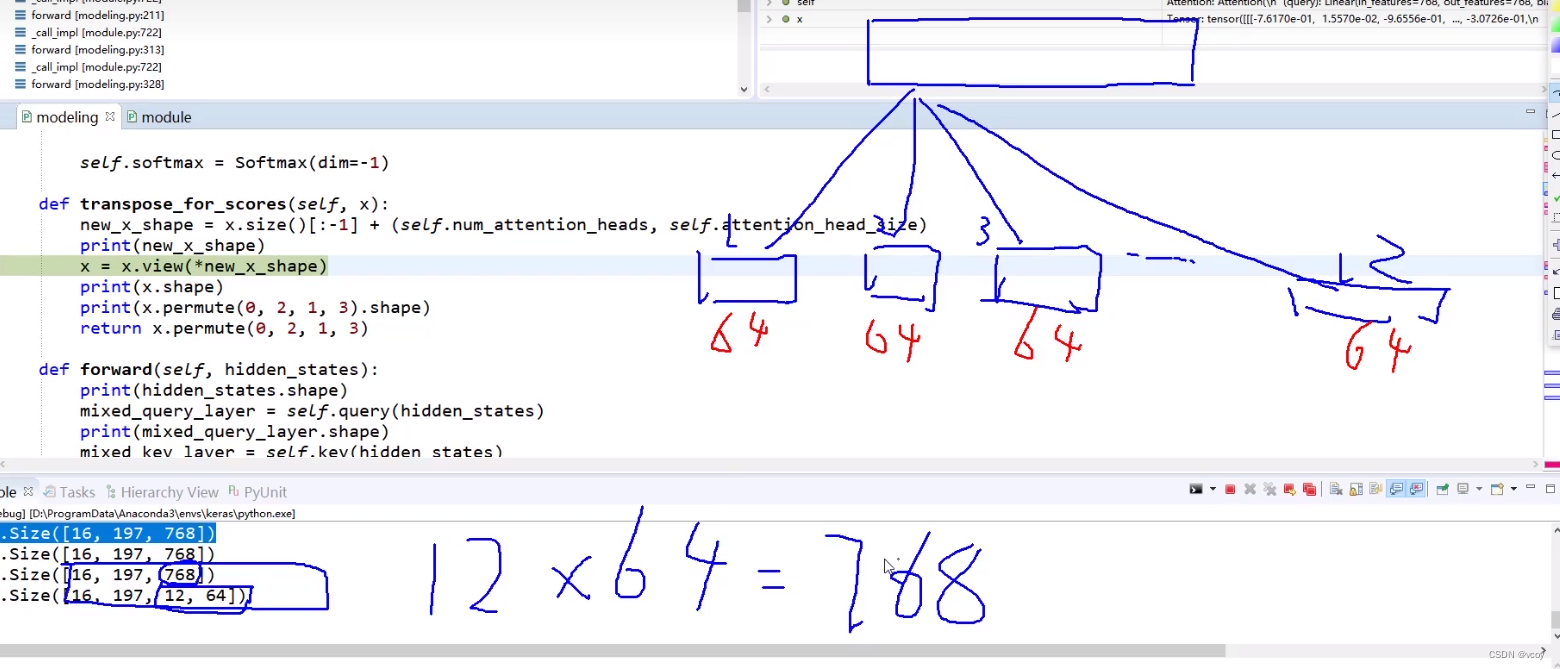
代码步骤二做完的事情,图1
图二
图三
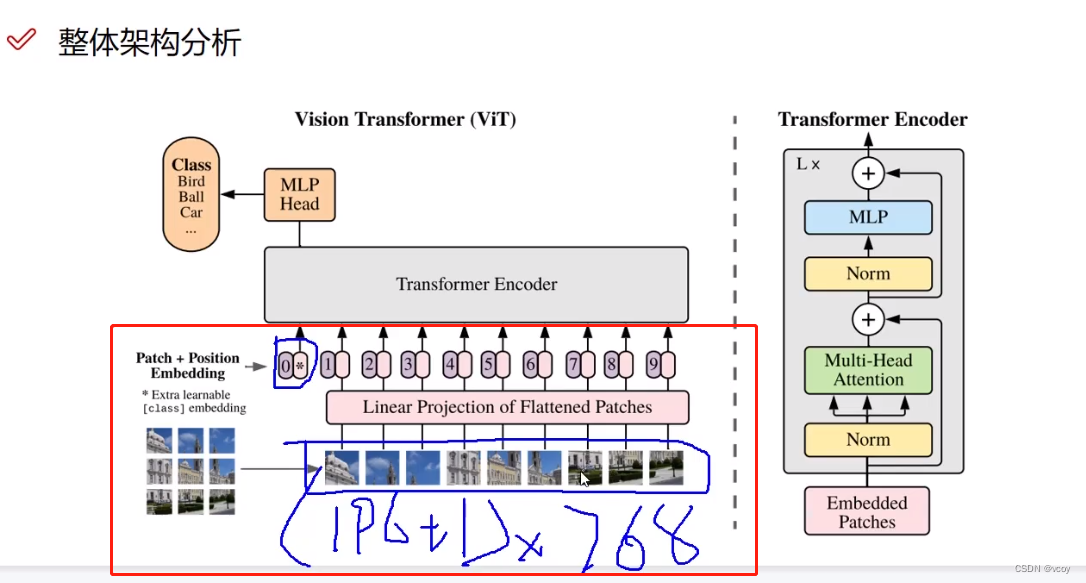
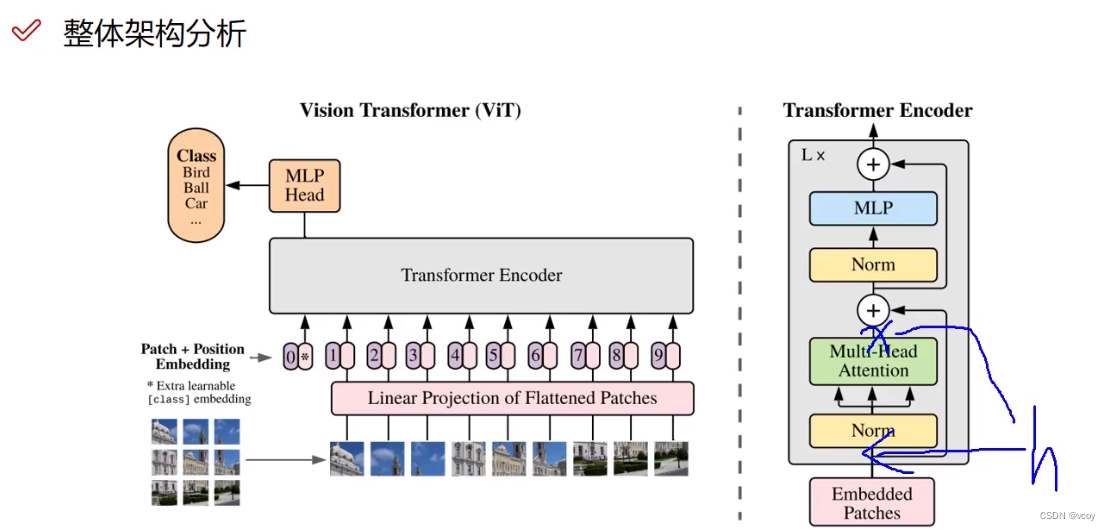
2.2 VIT图像计算公式
E代表编码,ppc代表输入一个patch(图像分割块),D是映射(全连接层),即将256映射为512,映射后变为ppd
Epos位置编码最后一个维度D必须和E一样,N+1代表多了一个0*(N代表图像分割的patch块数),表示一个分类token。
第一个E表示对D做一个映射。
z0表示将位置编码信息加到每一个数据上。
MSA-多头注意力机制,LN-归一化,加上Zt-1代表加上残差连接。

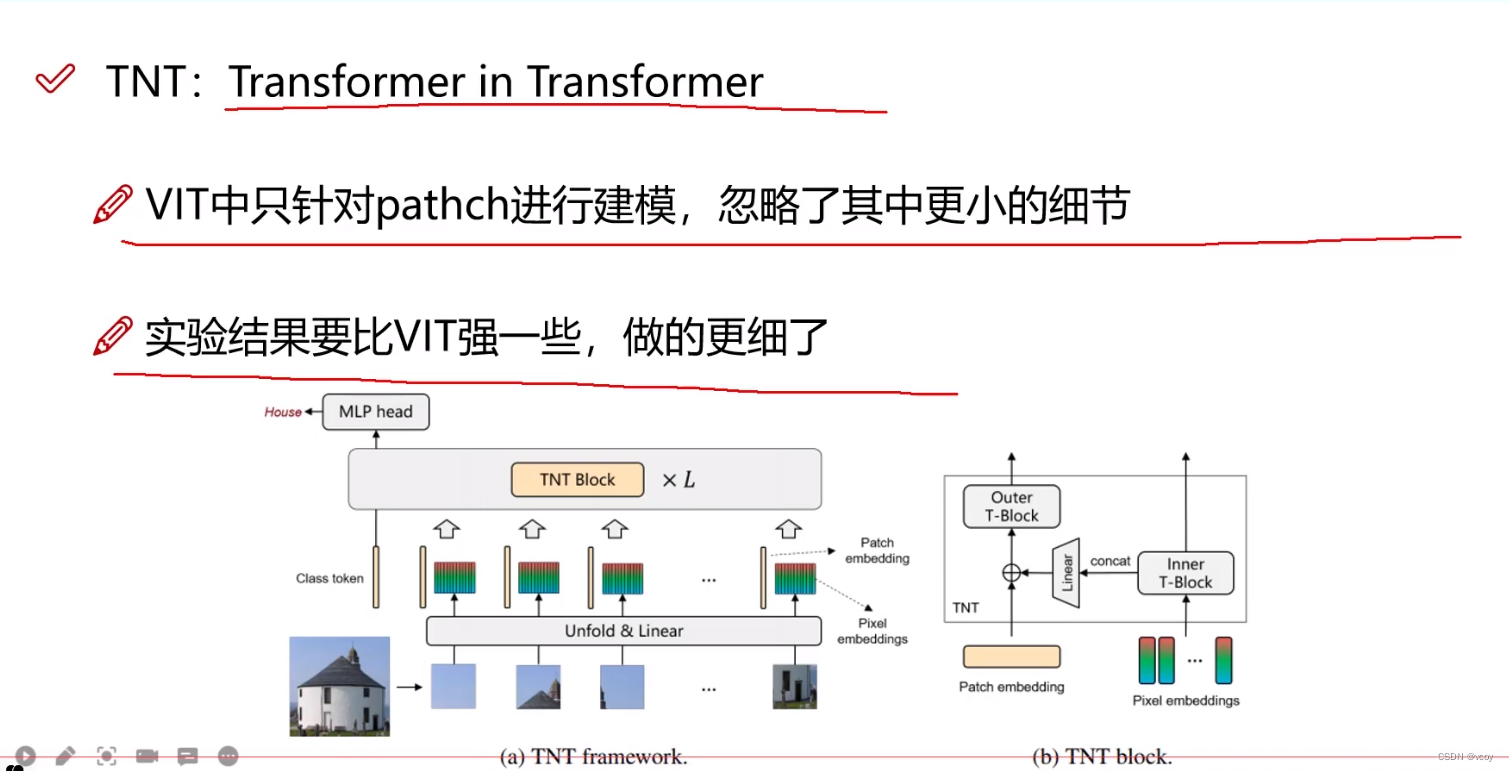
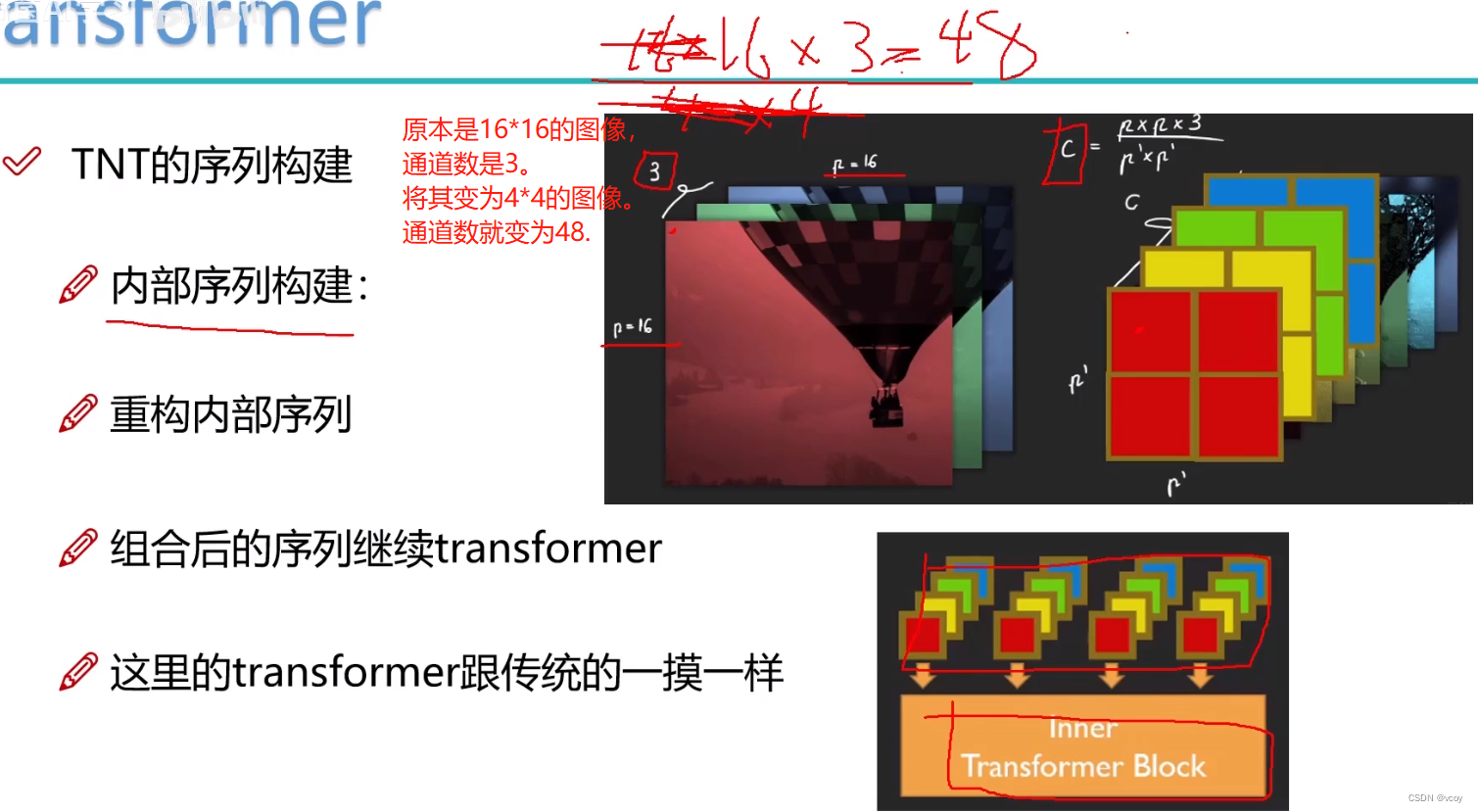
3 TNT
↑内部的transformer将每个分割过的图像patch再次分割为多个patch。外部的transformer和一般情况下做的事情一样。
↑TNT内部序列重组构建

VIT总结:
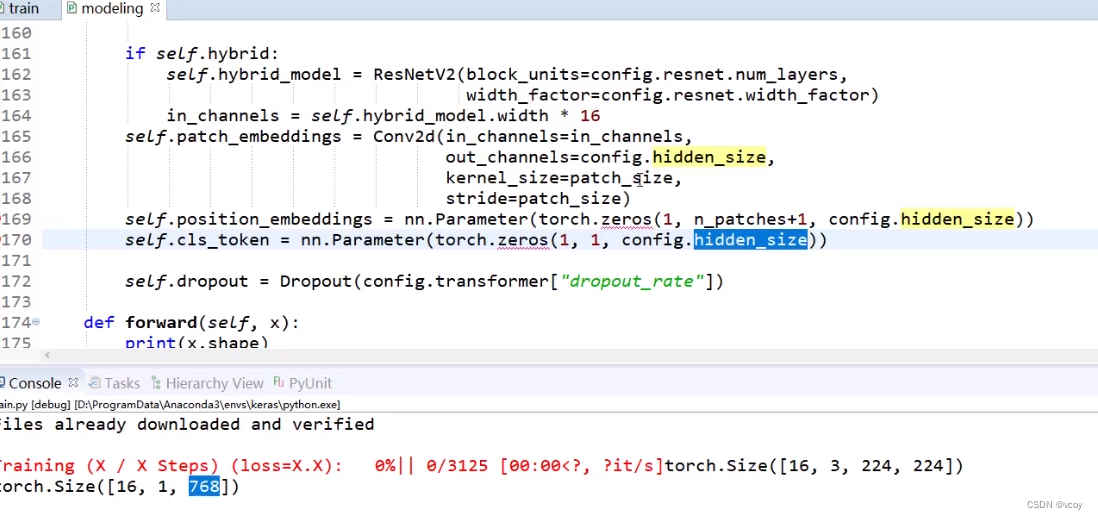
图像进行position_enbeddings,只需要进行一次卷积即可。
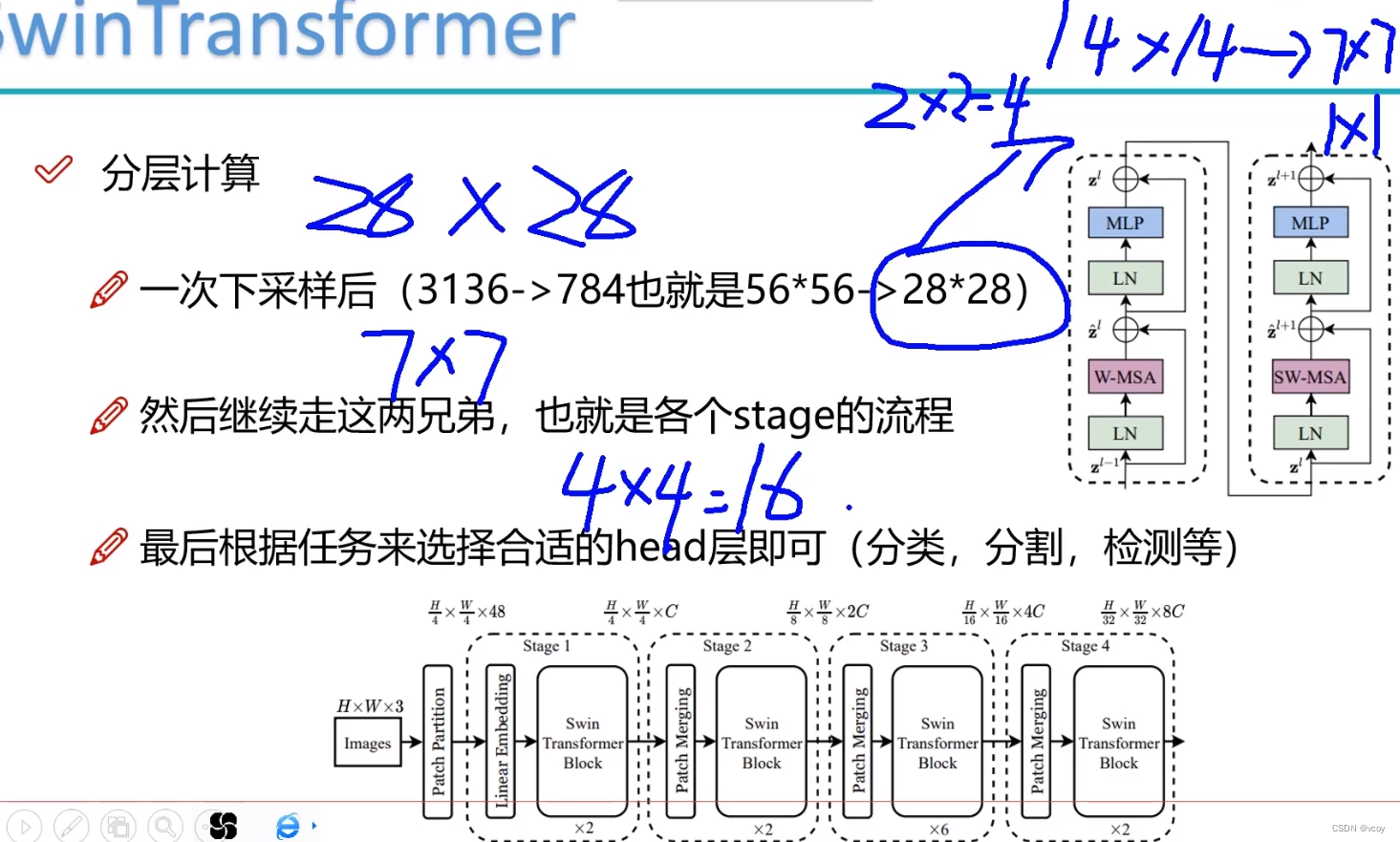
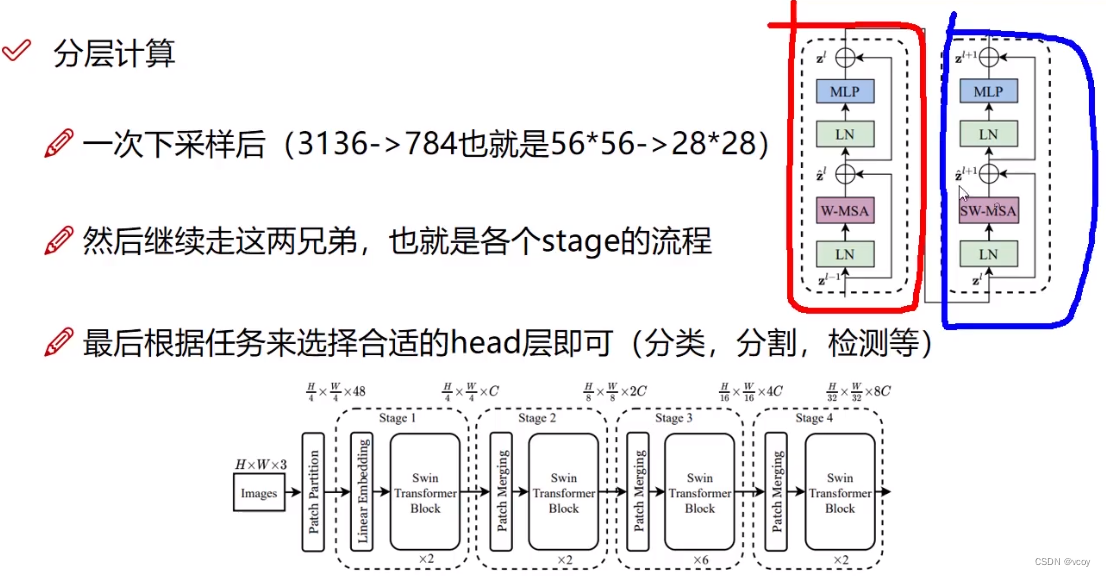
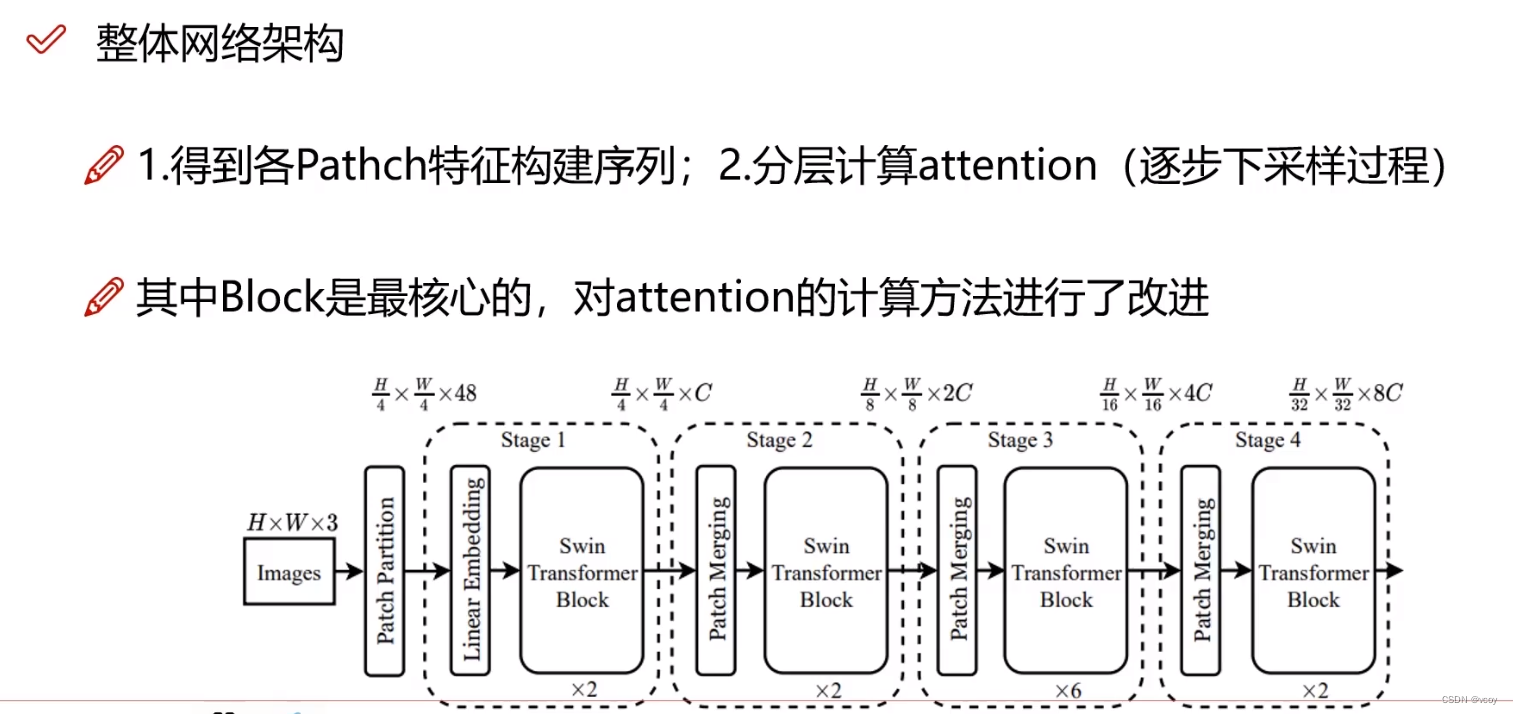
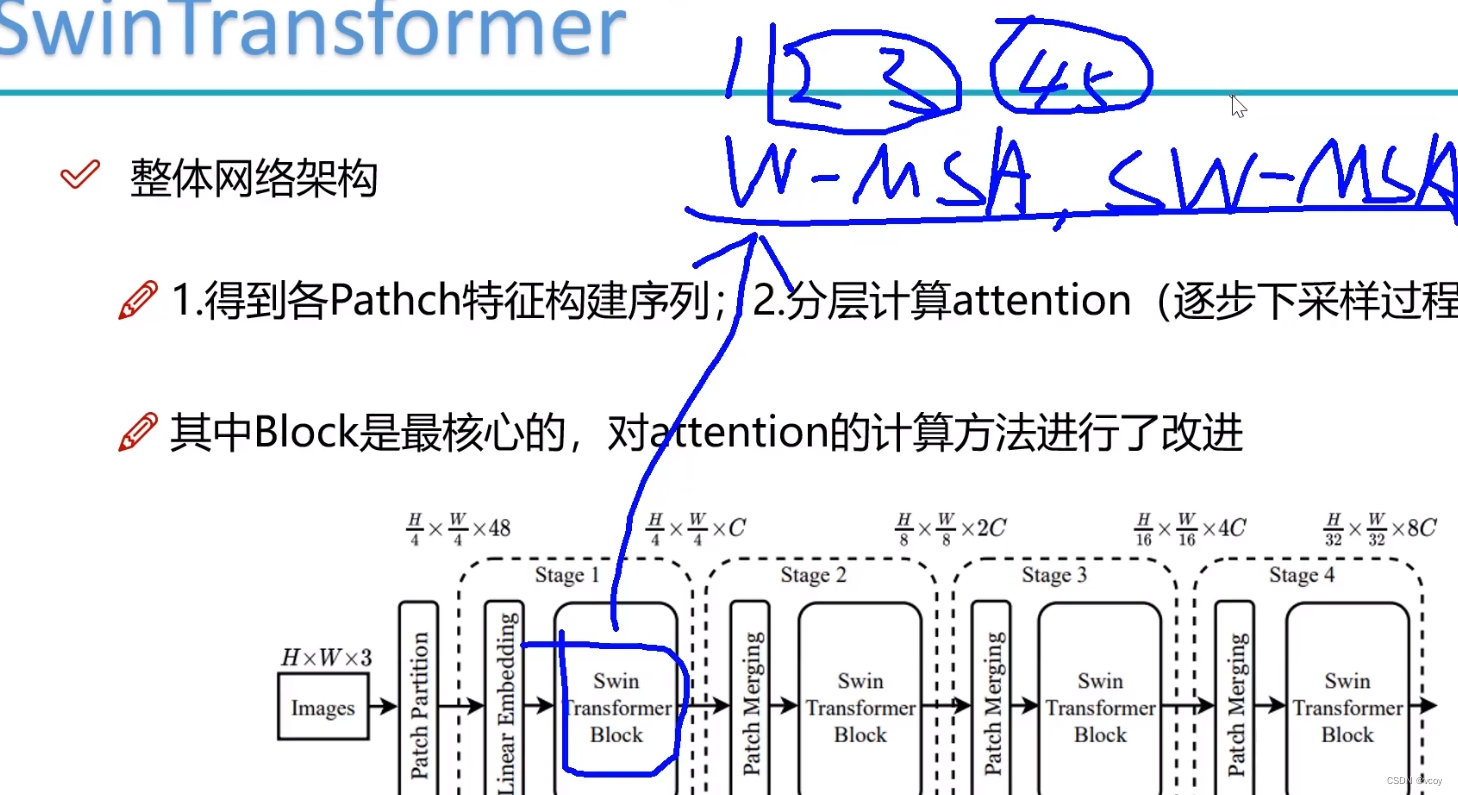
4.swin Transformer
传统transformer将图像作为一个个的patch,每个patch作为序列的一小部分,传统的尽可能将patch分的细一点,但此时需要构建更长的序列,则token就越多。而transformer需要将其中的一个token和其他token做计算,此时计算量就大。如第一层输入400个token,则下一层还是400个。传统的transformer输入的向量维度和输出的一样。
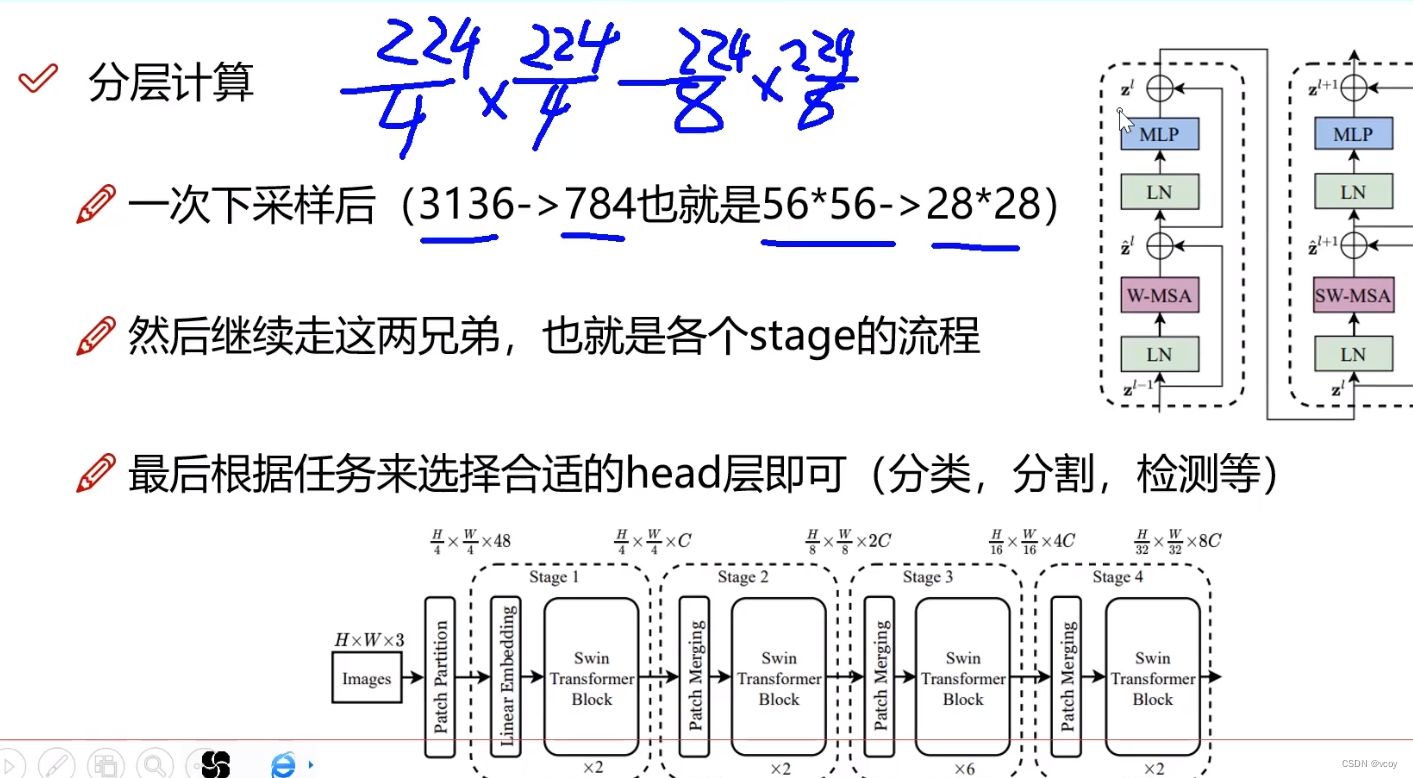
而swin transformer第一层400个,第二层进行合并变为200个,后续依次类推。

步骤:
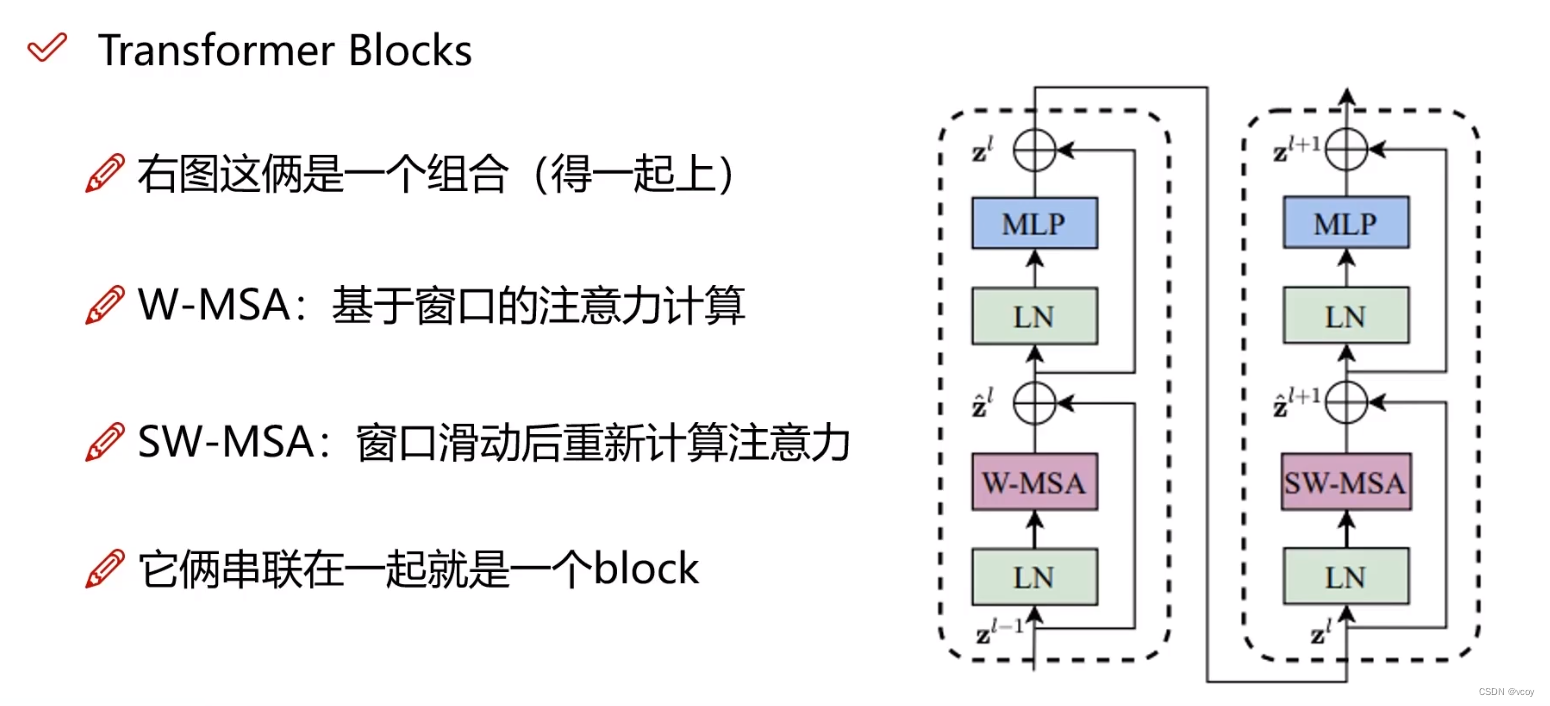
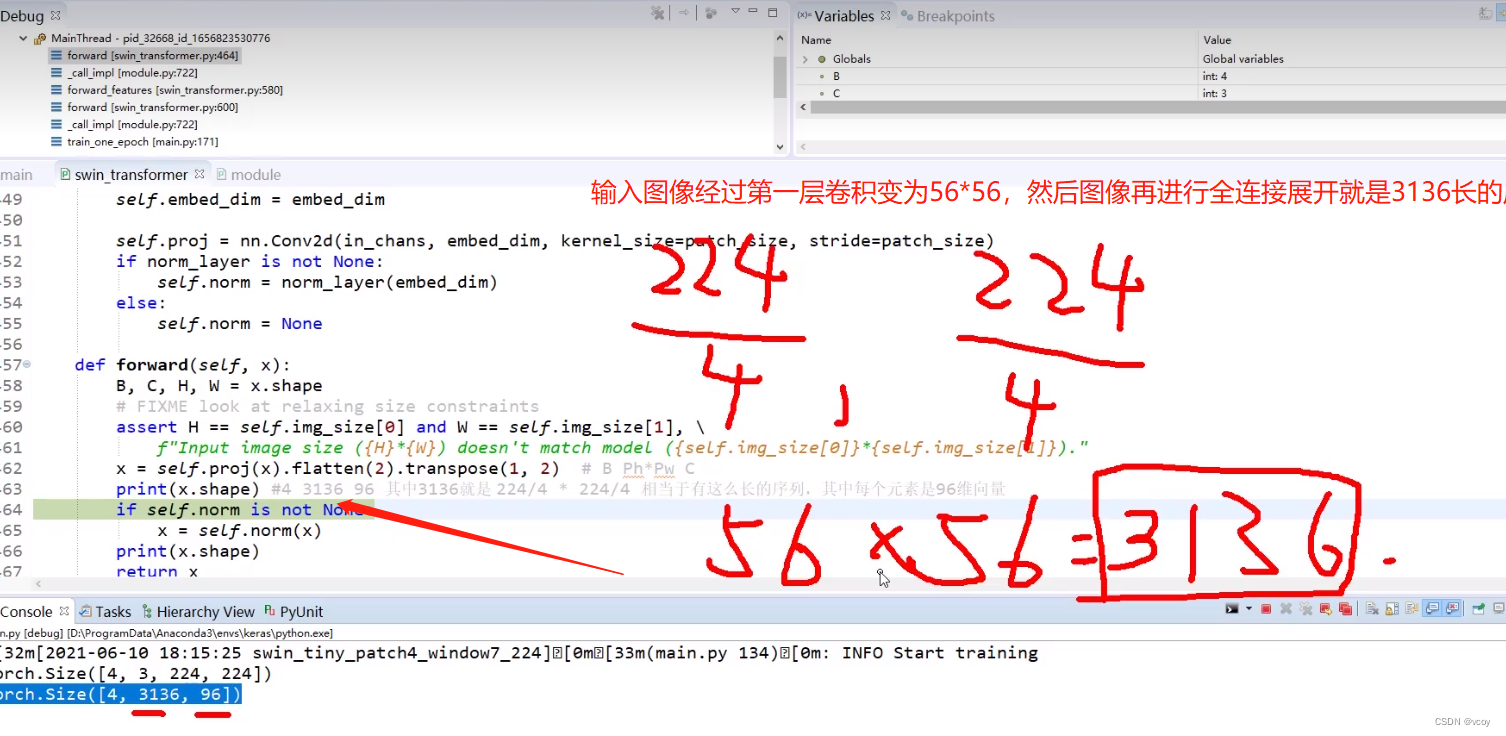
4.1 图像的初始输入
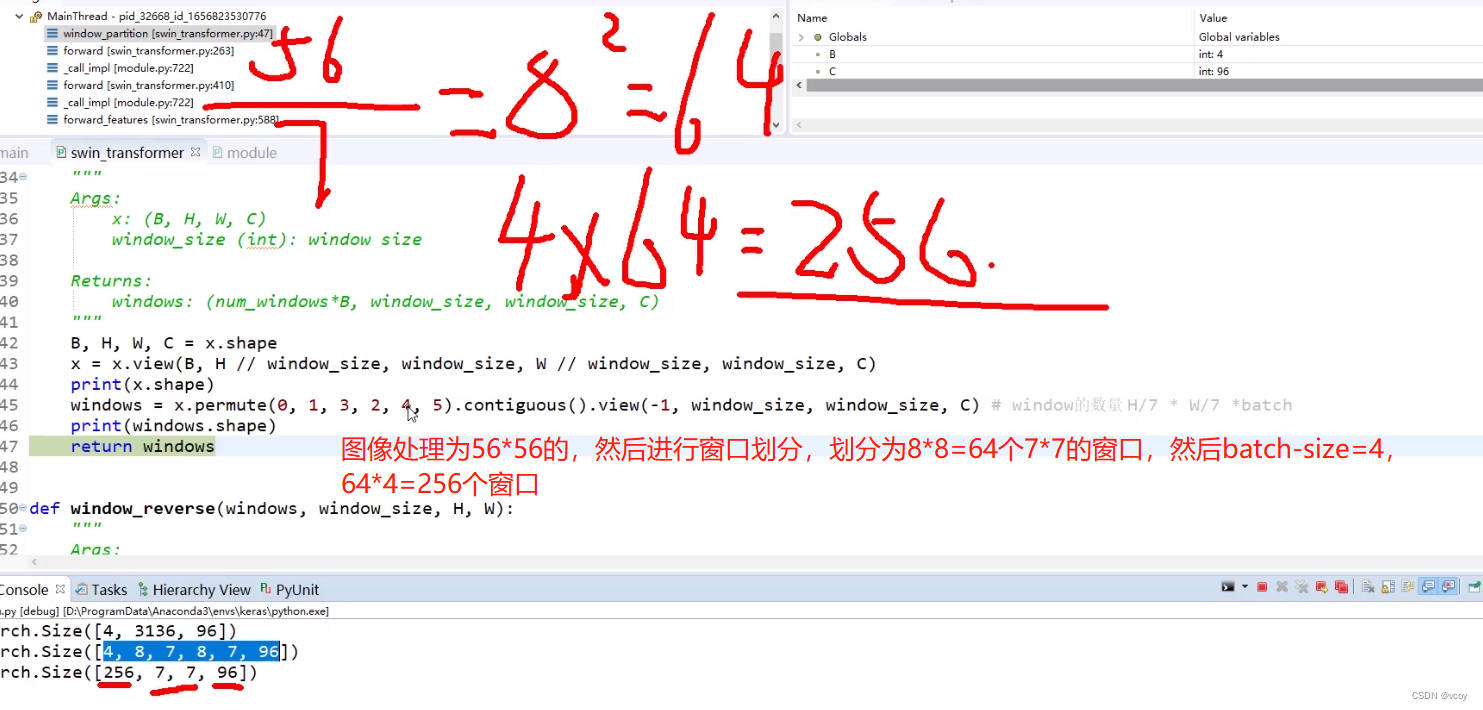
4.2 将图像的特征图中的序列转换为多个窗口,即基于window的自注意力机制
reshape操作(5656->6477),64个窗口,每个窗口为77大小4.3 计算自己窗口内的自注意力得分,得到权重矩阵
每个窗口由77=49个token组成,每个token是由3头注意力机制搞定,每一头搞定一个32维向量。
attention结果代表意思:64为64个窗口,3代表3种不同的权重项,49,49表示每个77(4949即49个token,其他48+自己的权[1]=49得分)的窗口中自己的自注意力得分。
4.4窗口重构,将窗口还原为输入时的特征
新的特征(64,49,96)分别代表64个窗口,每个窗口有77=49个点,每个点输入为96维向量,此时的96维向量还表示了与窗口内其他token点的关系。
每个窗口的点对应96个向量。此时96个向量是做了attention后表达的特征含义。
4.5 计算窗口内部特征后,进行窗口滑动再次计算注意力特征
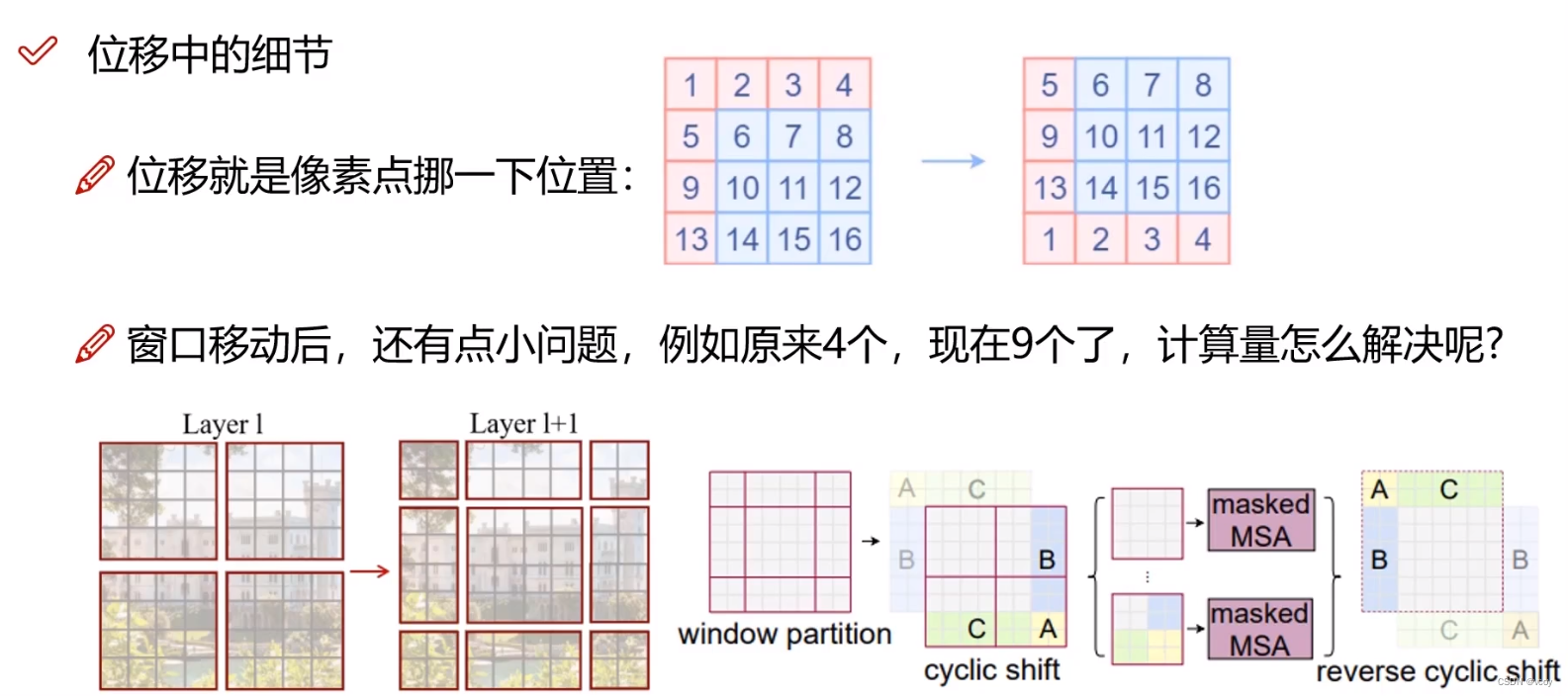
4.6 窗口偏移的问题及解决
原本是4大块ABC和空格部分,划分后为0-8九个位置。但是计算还按照四个窗口计算,即4还当做其中一个,然后5和3当做一块,1和7当做一块,0、2、6、8四个当做一块,等于还是四块。
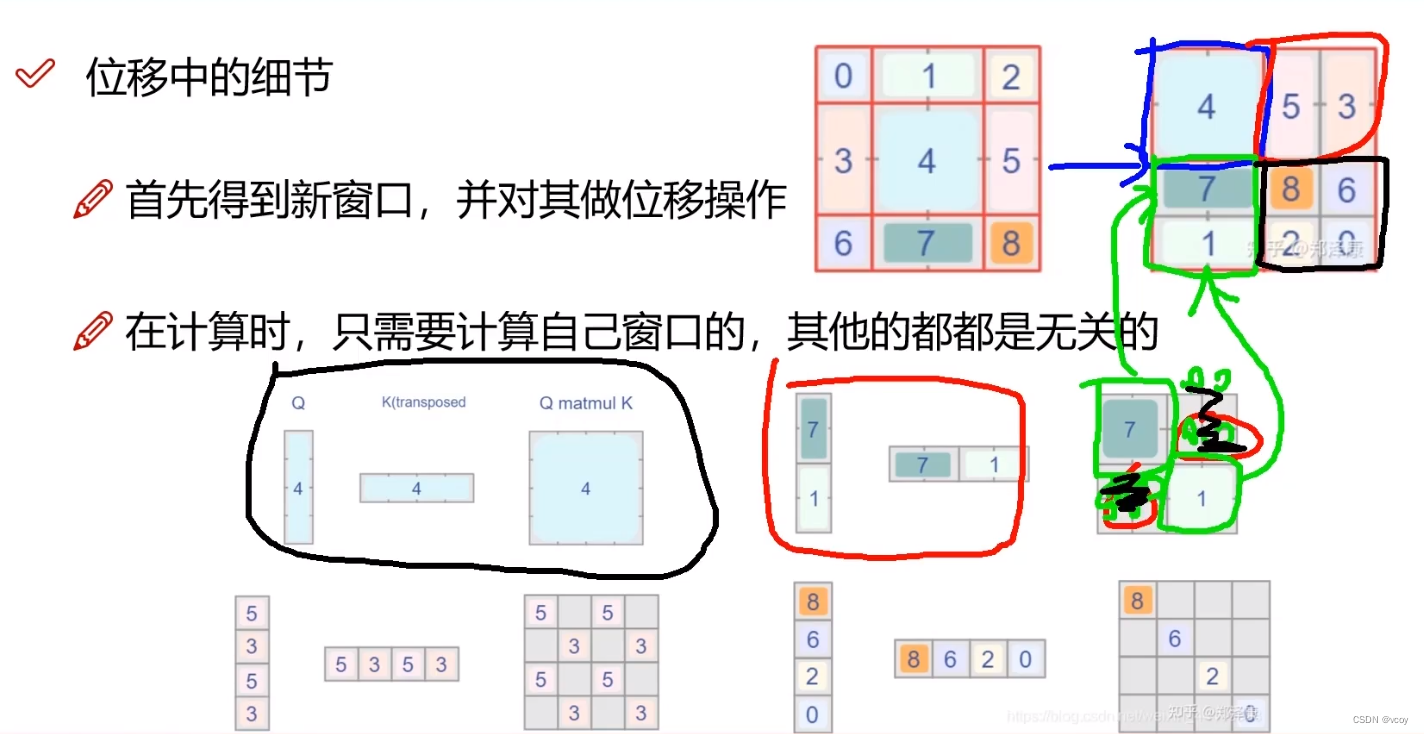
然后四块内计算块内的自注意力,没有意义的地方进行mask补0,不影响计算。
W-MSA和SW-MSA输入是一样的,都是4.3中(3,64,3,49,32),含义也是一样的。只是SW-MSA对窗口做了偏移,引入了masked,然后其他和W-MSA一样。>
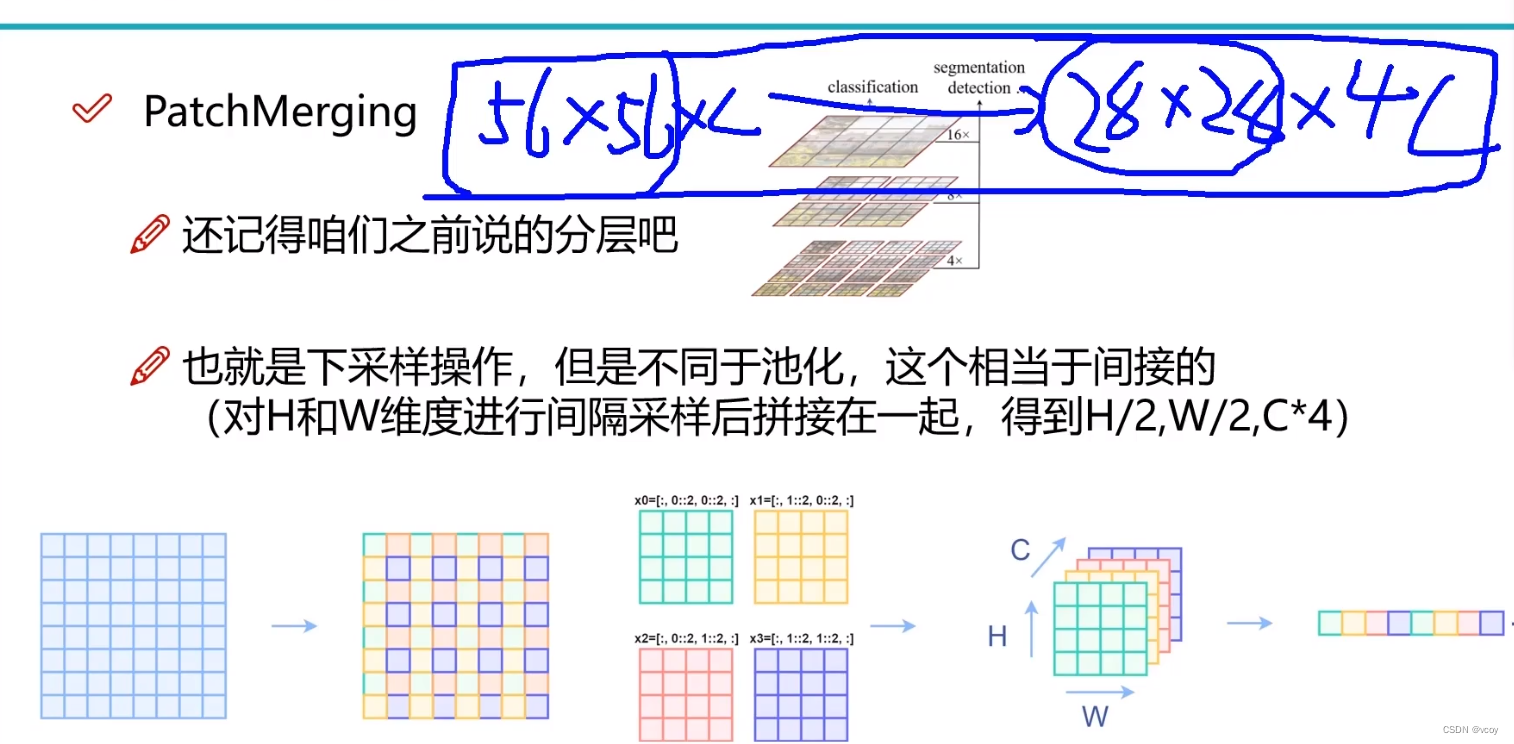
4.7 下采样
间隔取图像块。
第一次是64个窗口,第二次就变为16个窗口,第三次变为4个窗口,第四次变为1个窗口,选择7是因为7算的开。最终得到特征图
4.8 代码总结
图五
3136相当于3136个特征点,每一个点都是由96维向量组成的
图6
图七