本文聚焦于Batch Normalization,Layer Normalization两个标准化方法,对其原理和优势等进行了详细的阐述。
这一篇写Transformer里标准化的方法。在Transformer中,数据过Attention层和FFN层后,都会经过一个Add & Norm处理。其中,Add为residule block(残差模块),数据在这里进行residule connection(残差连接)。而Norm即为Normalization(标准化)模块。Transformer中采用的是Layer Normalization(层标准化)方式。常用的标准化方法有Batch Normalization,Layer Normalization,Group Normalization,Instance Normalization等
Batch Normalization
本节1.2-1.3的部分,在借鉴天雨粟:Batch Normalization原理与实战解说的基础上,增加了自己对论文和实操的解读,并附上图解。上面这篇文章写得非常清晰,推荐给大家阅读~
提出背景
Batch Normalization(以下简称BN)的方法最早由Ioffe&Szegedy在2015年提出,主要用于解决在深度学习中产生的ICS(Internal Covariate Shift)的问题。若模型输入层数据分布发生变化,则模型在这波变化数据上的表现将有所波动,输入层分布的变化称为Covariate Shift,解决它的办法就是常说的Domain Adaptation。同理,在深度学习中,第L+1层的输入,也可能随着第L层参数的变动,而引起分布的变动。这样每一层在训练时,都要去适应这样的分布变化,使得训练变得困难。这种层间输入分布变动的情况,就是Internal Covariate Shift。而BN提出的初衷就是为了解决这一问题。
 ICS所带来的问题
ICS所带来的问题
(1)在过激活层的时候,容易陷入激活层的梯度饱和区,降低模型收敛速度。
这一现象发生在我们对模型使用饱和激活函数(saturated activation function),例如sigmoid,tanh时。如下图:

可以发现当绝对值越大时,数据落入图中两端的梯度饱和区(saturated regime),造成梯度消失,进而降低模型收敛速度。当数据分布变动非常大时,这样的情况是经常发生的。当然,解决这一问题的办法可以采用非饱和的激活函数,例如ReLu。
(2)需要采用更低的学习速率,这样同样也降低了模型收敛速度。
如前所说,由于输入变动大,上层网络需要不断调整去适应下层网络,因此这个时候的学习速率不宜设得过大,因为梯度下降的每一步都不是“确信”的。
1.1.2 解决ICS的常规方法
综合前面,在BN提出之前,有几种用于解决ICS的常规办法:
-
采用非饱和激活函数
-
更小的学习速率
-
更细致的参数初始化办法
-
数据白化(whitening)
其中,最后一种办法是在模型的每一层输入上,采用一种线性变化方式(例如PCA),以达到如下效果:
-
使得输入的特征具有相同的均值和方差。例如采用PCA,就让所有特征的分布均值为0,方差为1
-
去除特征之间的相关性。
然而在每一层使用白化,给模型增加了运算量。而小心地调整学习速率或其他参数,又陷入到了超参调整策略的复杂中。因此,BN作为一种更优雅的解决办法被提出了。
1.2 BN的实践
1.2.1 思路

上图所示的是2D数据下的BN,而在NLP或图像任务中,我们通常遇到3D或4D的数据,例如:
-
图像中的数据维度:(N, C, H, W)。其中N表示数据量(图数),C表示channel数,H表示高度,W表示宽度。
-
NLP中的数据为度:(B, S, E)。其中B表示批量大小,S表示序列长度,F表示序列里每个token的embedding向量维度。

训练过程中的BN
配合上面的图例,我们来具体写一下训练中BN的计算方式。

测试过程中的BN


采用这种方法的好处是:
-
节省了存储空间,不需要保存所有的均值和方差结果,只需要保存running mean和running variance即可
-
方便在训练模型的阶段追踪模型的表现。一般来讲,在模型训练的中途,我们会塞入validation dataset,对模型训练的效果进行追踪。采用移动平均法,不需要等模型训练过程结束再去做无偏估计,我们直接用running mean和running variance就可以在validation上评估模型。
1.3 BN的优势总结
-
通过解决ICS的问题,使得每一层神经网络的输入分布稳定,在这个基础上可以使用较大的学习率,加速了模型的训练速度
-
起到一定的正则作用,进而减少了dropout的使用。当我们通过BN规整数据的分布以后,就可以尽量避免一些极端值造成的overfitting的问题
-
使得数据不落入饱和性激活函数(如sigmoid,tanh等)饱和区间,避免梯度消失的问题
1.4 大反转:著名深度学习方法BN成功的秘密竟不在ICS?
以解决ICS为目的而提出的BN,在各个比较实验中都取得了更优的结果。但是来自MIT的Santurkar et al. 2019却指出:
-
就算发生了ICS问题,模型的表现也没有更差
-
BN对解决ICS问题的能力是有限的
-
BN奏效的根本原因在于它让optimization landscape更平滑
而在这之后的很多论文里也都对这一点进行了不同理论和实验的论证。 (每篇论文的Intro部分开头总有一句话类似于:“BN的奏效至今还是个玄学”。。。)
图中是VGG网络在标准,BN,noisy-BN下的实验结果。其中noisy-BN表示对神经网络的每一层输入,都随机添加来自分布(non-zero mean, non-unit variance)的噪音数据,并且在不同的timestep上,这个分布的mean和variance都在改变。noisy-BN保证了在神经网络的每一层下,输入分布都有严重的ICS问题。但是从试验结果来看,noisy-BN的准确率比标准下的准确率还要更高一些,这说明ICS问题并不是模型效果差的一个绝对原因。


Layer Normalization

这是一个结合实验的解释,而引起这个现象的原因,可能不止是“长短不一”这一个,也可能和数据本身在某一维度分布上的差异性有关。目前相关知识水平有限,只能理解到这里,未来如果有更确切的想法,会在这里补充。
2.2 思路
整体做法类似于BN,不同的是LN不是在特征间进行标准化操作(横向操作),而是在整条数据间进行标准化操作(纵向操作)
 在图像问题中,LN是指对一整张图片进行标准化处理,即在一张图片所有channel的pixel范围内计算均值和方差。而在NLP的问题中,LN是指在一个句子的一个token的范围内进行标准化。
在图像问题中,LN是指对一整张图片进行标准化处理,即在一张图片所有channel的pixel范围内计算均值和方差。而在NLP的问题中,LN是指在一个句子的一个token的范围内进行标准化。

训练过程和测试过程中的LN

Transformer LN改进方法:Pre-LN
原始transformer中,采用的是Post-LN,即LN在residule block(图中addtion)之后。Xiong et al. (2020)中提出了一种更优Pre-LN的架构,即LN在residule block之前,它能和Post-LN达到相同甚至更好的训练结果,同时规避了在训练Post-LN中产生的种种问题。两种架构的具体形式可以见下图。

这篇论文通过理论分析和实验的方式,证明了Pre-LN相比的Post-LN的优势,主要表现在:
-
在learning rate schedular上,Pre-LN不需要采用warm-up策略,而Post-LN必须要使用warm-up策略才可以在数据集上取得较好的Loss和BLEU结果。
-
在收敛速度上,由于Pre-LN不采用warm-up,其一开始的learning rate较Post-LN更高,因此它的收敛速度更快。

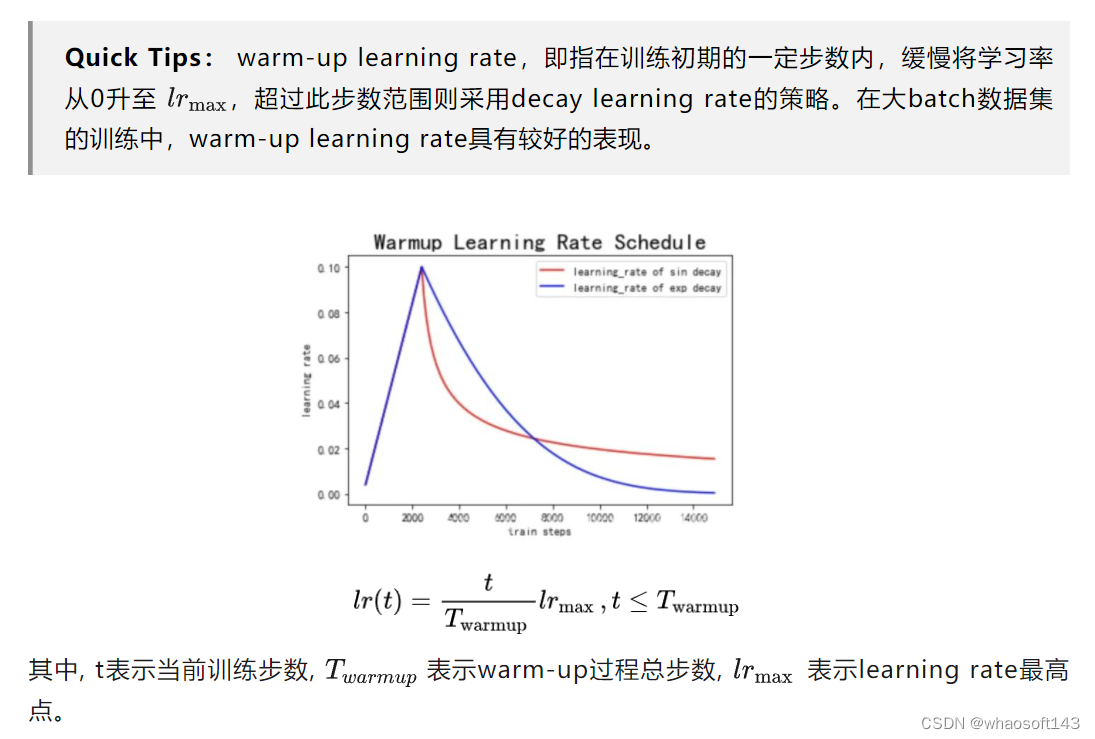
总结看来,Pre-LN带来的好处,基本都是因为不需要做warm-up引起的。而引起这一差异的根本原因是:
-
Post-LN在输出层的gradient norm较大,且越往下层走,gradient norm呈现下降趋势。这种情况下,在训练初期若采用一个较大的学习率,容易引起模型的震荡。
-
Pre-LN在输出层的gradient norm较小,且其不随层数递增或递减而变动,保持稳定。
-
无论使用何种Optimzer,不采用warm-up的Post-LN的效果都不如采用warm-up的情况,也不如Pre-LN。

whaosoft aiot http://143ai.com