参考资料:
transformer原论文
深入理解transformer及源码
图解Transformer(完整版)
The Annotated Transformer
The Annotated Transformer的中文注释版
前言
本来今年(2020)七月份就想写这篇博客,因为毕业、工作入职等一系列事情一直拖到了现在(主要是因为懒)。transformer的实现不止一个版本的源码,本文主要讲解哈佛大学利用torch实现的版本。相对更“高级”的源码,这个用框架实现的版本显得不是那么底层,但我们大多数人阅读源码的主要目的还是为了更多的理解这个算法的细节然后去更好的使用它。
对transformer的入门级理解我个人认为可以分为三个层次,第一个层次是仅阅读了原论文,对transformer有了宏观的认识。读过后你会知道transformer的宏观结构、创新点和牛逼之处。但这远远不够,因为transformer的论文省略了非常多的细节;第二个层次是读过那篇传播很广的博客——图解transformer,这篇博客以图解的方式深入浅出的从微观角度讲解了什么是自注意力机制、多头等概念,读过后结合原论文你能大致理顺tranformer的前向传播机制,每一个解构开来的功能单元都能大致理解它的原理,此时你会有豁然开朗的感觉,但细想一段时间之后又会有很多疑惑,因为很多细节还是只知道模糊的原理,不知细节;第三个层次便是阅读源码了,如果读的足够认真,或者自己跟着实现一遍,你会知道transformer的前向传播中矩阵是怎么拼接、变换的,理解设计精巧的mask机制是怎么与损失函数协同工作的,这时候你才算真正入门了这个算法。
本文重点在于理解transformer的源码,在源码批注中写清楚了每一步计算前后矩阵的size,这样可以保证充分理解每一步数学运算的结果。但本文不是从零开始介绍transformer,且强烈依赖“图解transformer”中的大量图例,所以强烈推荐仔细读完原论文和“图解transformer”(开头参考资料有链接)后再来阅读,没有基础直接阅读会引起强烈不适。
transformer介绍
虽说已经推荐了大家有基础后再阅读,但这里还是简单的介绍一下。在深度学习领域一直有两种主流的特征抽取器结构,一种是CNN,一种是RNN。这两种特征抽取器以其独特的优势称霸了很久。尤其是RNN,其循环结构与nlp天然契合,在nlp中以RNN为基础的各种算法一直都是舞台的主角。transformer的出现打破了这个格局,transformer独特的自注意力机制既与自然语言任务契合,又解决了RNN一直被诟病的并行困难、梯度消失等问题,可谓是从各方面革了RNN的命。当然,transformer优异的性能并不仅仅是自注意力机制带来的,具体我就不展开聊了,感兴趣的推荐看看《放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较》,这篇类似综述一样的知乎文章可以说讲解的很清晰了。
 fig.1
fig.1
闲话就扯到这儿,下面我们就来进入transformer的源码解读。transformer的结构也是一个编码-解码结构。输入序列先进行Embedding,经过Encoder之后结合上一次output再输入Decoder,最后用softmax计算序列下一个单词的概率。下面以前向传播的顺序解读各个模块的源码。
1、Word Embedding and Positional Encoding
 fig.2
fig.2
文本进入到模型需要编码,transformer的编码方式包括Word Embedding和Positional Encoding。
word embedding一般有两种方式:
1、使用预训练模型直接生成,相当于提供一个lookup table;
2、 随机初始化,在模型训练过程中作为一个可训练的参数参与梯度优化,这样在模型训练完成之时词向量也会随之生成。
这两种方法没有孰优孰劣,只有适用场景。若针对一个特定的nlp任务,其训练集词库有限,即预测过程中可能出现词库外的词语,此时显然应该借助预训练模型。但抛开一个特定的nlp任务,若一个算法模型可以作为预训练模型,那word embedding层必然不能少。transformer作为一个算法而非任务显然属于后者,word embedding的代码实现如下:
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
"""
:param d_model: word embedding维度
:param vocab: 语料库词的数量
"""
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
"""
:param x: 一个batch的输入,size = [batch, L], L为batch中最长句子长度
"""
return self.lut(x) * math.sqrt(self.d_model) #这里乘了一个权重,不改变维度. size = [batch, L, d_model]
d_model是此向量的维度,理论上输入以后就是个定值了,那么最后乘的权重math.sqrt(self.d_model)显然也是个常数。所有随机向量乘一个常数,相当于同时放缩,理论上不会有什么影响。所以为什么要乘个常数?先记住这个问题。
transformer没有RNN的循环结构,无法感知一个句子中词语出现的先后顺序,而词语的位置是相当重要的一个信息。作者提出了位置编码,即Positional Encoding,来解决这个问题。
关于位置编码,作者提供了两种方法:
1、通过训练学习positional encoding 向量;
2、编了个公式来计算positional encoding向量;
作者经过试验后发现两种方式的结果是相似的,所以选择了第二种。毕竟要简单一点,减少了训练参数,而且在训练集中么有出现过的句子长度上也能用。公式如下:
P E ( p o s , 2 i ) = sin ( p o s / 1000 0 2 i / d m o d e l ) P E_{(p o s, 2 i)}=\sin \left(p o s / 10000^{2 i / d_{\mathrm{model}}}\right) PE(pos,2i)=sin(pos/100002i/dmodel) P E ( p o s , 2 i + 1 ) = cos ( p o s / 1000 0 2 i / d model ) P E_{(p o s, 2 i+1)}=\cos \left(p o s / 10000^{2 i / d_{\text {model }}}\right) PE(pos,2i+1)=cos(pos/100002i/dmodel )
其中, p o s pos pos指的是这个word在这个句子中的位置; 2 i 2i 2i指的是embedding词向量的偶数维度, 2 i + 1 2i+1 2i+1指的是embedding词向量的奇数维度。具体代码如下:
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
"""
:param d_model: pe编码维度,一般与word embedding相同,方便相加
:param dropout: dorp out
:param max_len: 语料库中最长句子的长度,即word embedding中的L
"""
super(PositionalEncoding, self).__init__()
# 定义drop out
self.dropout = nn.Dropout(p=dropout)
# 计算pe编码
pe = torch.zeros(max_len, d_model) # 建立空表,每行代表一个词的位置,每列代表一个编码位
position = torch.arange(0, max_len).unsqueeze(1) # 建个arrange表示词的位置以便公式计算,size=(max_len,1)
div_term = torch.exp(torch.arange(0, d_model, 2) * # 计算公式中10000**(2i/d_model)
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term) # 计算偶数维度的pe值
pe[:, 1::2] = torch.cos(position * div_term) # 计算奇数维度的pe值
pe = pe.unsqueeze(0) # size=(1, L, d_model),为了后续与word_embedding相加,意为batch维度下的操作相同
self.register_buffer('pe', pe) # pe值是不参加训练的
def forward(self, x):
# 输入的最终编码 = word_embedding + positional_embedding
x = x + Variable(self.pe[:, :x.size(1)],requires_grad=False) #size = [batch, L, d_model]
return self.dropout(x) # size = [batch, L, d_model]
为什么上面的两个公式能体现单词的相对位置信息呢?作者也举了一个例子来说明,写一段代码取位置编码向量的四个维度进行可视化:
plt.figure(figsize=(15, 5))
pe = PositionalEncoding(20, 0)
y = pe.forward(Variable(torch.zeros(1, 100, 20)))
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.legend(["dim %d"%p for p in [4,5,6,7]])
 fig.3
fig.3
从图中可以看出,位置编码基于不同位置添加了正弦波,对于每个维度,波的频率和偏移都有不同。也就是说对于序列中不同位置的单词,对应不同的正余弦波,可以认为他们有相对关系。
代码中的构造函数是Positional Encoding公式的代码实现,但从forward函数中可以看出,词语最终的编码是word_embedding + positional_embedding,所以positional_embedding的维度与word_embedding一致。此时就直到为什么word_embedding末尾要乘一个常量权重了,就是为了放大,防止因与positional_embedding的量级相差过大,做加法后被忽视掉。
2 Encoder
一个batch的数据经过embedding后,就要进入transformer的编码器了。transformer的编码器主要包含几个功能点:多头自注意力机制、求和与归一化、前馈神经网络。
 fig.4
fig.4
其中“多头自注意力机制”和“mask掩码机制”是颇具创新的两个亮点,也是后续重点关注的部分。
MultiHeadedAttention
多头自注意力机制就是多个自注意力机制。多头注意力机制的源码如下:
def clones(module, N):
"工具人函数,定义N个相同的模块"
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout):
"""
实现多头注意力机制
:param h: 头数
:param d_model: word embedding维度
:param dropout: drop out
"""
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0 #检测word embedding维度是否能被h整除
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h # 头的个数
self.linears = clones(nn.Linear(d_model, d_model), 4) #四个线性变换,前三个为QKV三个变换矩阵,最后一个用于attention后
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"""
:param query: 输入x,即(word embedding+postional embedding),size=[batch, L, d_model] tips:编解码器输入的L可能不同
:param key: 同上,size同上
:param value: 同上,size同上
:param mask: 掩码矩阵,编码器mask的size = [batch , 1 , src_L],解码器mask的size = [batch, tgt_L, tgt_L]
"""
if mask is not None:
# 在"头"的位置增加维度,意为对所有头执行相同的mask操作
mask = mask.unsqueeze(1) # 编码器mask的size = [batch,1,1,src_L],解码器mask的size= = [batch,1,tgt_L,tgt_L]
nbatches = query.size(0) # 获取batch的值,nbatches = batch
# 1) 利用三个全连接算出QKV向量,再维度变换 [batch,L,d_model] ----> [batch , h , L , d_model//h]
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2) # view中给-1可以推测这个位置的维度
for l, x in zip(self.linears, (query, key, value))]
# 2) 实现Scaled Dot-Product Attention。x的size = (batch,h,L,d_model//h),attn的size = (batch,h,L,L)
x, self.attn = attention(query, key, value, mask=mask,dropout=self.dropout)
# 3) 这步实现拼接。transpose的结果 size = (batch , L , h , d_model//h),view的结果size = (batch , L , d_model)
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x) # size = (batch , L , d_model)
clones函数不用多说,就是一个工具人函数,负责定义N个相同的模块。
MultiHeadedAttention类即实现多头注意力机制的类。其构造函数中首先检测word embedding的维度能否被头数h整除,其原因是因为必须整除才能讲word embedding均分到每个头上。说到这里可能有读者会疑惑,因为与图解transformer中的实现方式不同。图解transformer中即=每个word embedding是不变的,变得是 W q W_q Wq, W k W_k Wk, W v W_v Wv三个权值矩阵,每一组不同的权值矩阵与word embedding相乘后会得到不同的Query、Key和Value矩阵,即对应不同的头。也就是说,图解transformer中,多头的实现是靠多个权值矩阵实现的。其实这里的实现方式其实也是与之等效的,后面会具体讲到。
构造函数中除了定义了一些后面用到的变量之外,还定义了四个相同的线性变换。这里说的相同,不是指完全相同,是指输入维度和输出维度是相同的,其权值是不同的。这里的线性变换切勿与前馈神经网络混淆,如果加了激活函数(即引入非线性)才是前馈神经网络。四个线性变换中,前三个代表与权值矩阵 W q W_q Wq, W k W_k Wk, W v W_v Wv相乘的过程,对应图解transformer中的下图。
 fig.5
fig.5
最后一个线性变化表示attention求解的结果拼接后的线性变化,用来约束结果的维度。对应图解transformer的下图。而约束维度的目的就是为了讲维度控制至与输入的word embedding一致,方便实现下一步的“求和”操作。
 fig.6
fig.6
forward函数中,我们首先关注第35行,这里是利用前三个线性变换,与word embedding相乘,得到,对应fig.5中的操作。仔细的读者可能会发现,这个forward函数的输入参数是三个,即query、key、value,为什么又说三个线性变换都与word embedding相乘呢?原因是,多头注意力机制,它的Query、Key、Value三个矩阵并不一定全是同样的输入word embedding与 W q W_q Wq, W k W_k Wk, W v W_v Wv相乘得到的。编码器中要求解每个词与其他词之间的attention值,也就是“自注意力”,所以输入全是word embedding。在解码器中就不是如此,所以这里索性留出三个参数以便函数在多种情况下的复用。
然而“自注意力”的训练过程中,并不是一条一条数据进去的,而是一个batch的数据以矩阵的形式进入。既然是矩阵运算这里就涉及了一个问题,一个batch的句子长度并不是一致的,在进入之前会有一个pad token将句子补齐,全部补齐成当前batch中最长句子的长度,pad token也会有自己的word embedding。这样在求解的过程中,词语与pad token之间的attention值就变成了多余的东西,对后续计算一定会有影响,这里就是mask机制发挥作用的地方。其实这里还有一个问题,为什么是补齐成当前batch的最长长度,而不是所有样本最长长度?原因是batch之间长度L的不同并不影响模型权值的数量,权值是作用在词编码的维度上的。先带着这个答案继续往下看。
第35行,求Query、Key、Value三个矩阵的过程可以表示成下图。
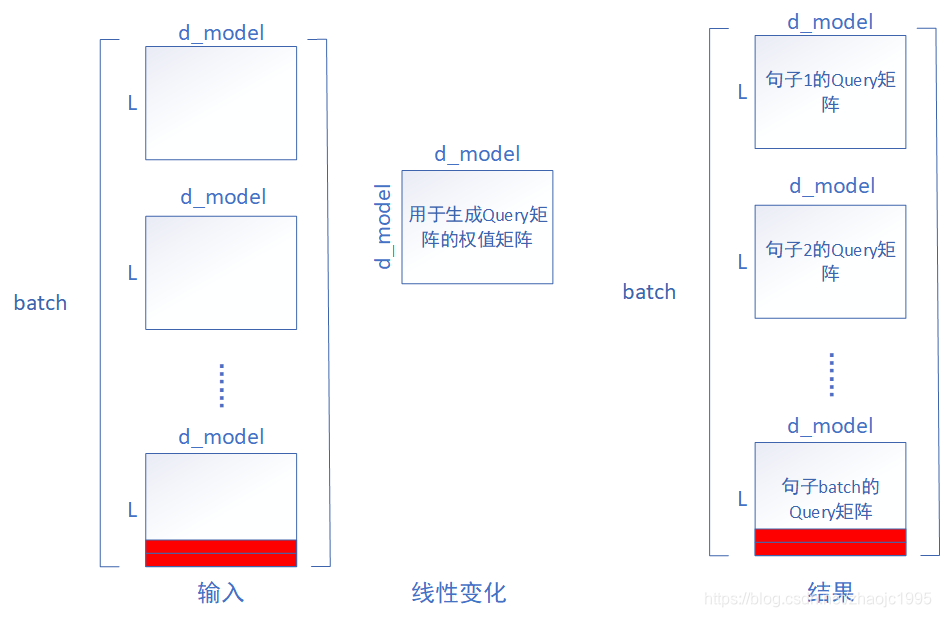 fig.7
fig.7
fig.7虽然只示意了Query矩阵的求解过程和size,但其实Key和Value矩阵都是一个道理。fig.7对应第35行代码,其中红色的部分表示pad token的word embedding,可以看出,在线性变换的过程中,pad token也被带到了结果中,并且对应的位置没变。第35行代码除了线性变换,还要将变换后结果的size从 [batch,L,d_model] ----> [batch , h , L , d_model//h],其实就是将结果的d_model均分成h份,来代表多头。这与“图解transformer”中的利用多个权值矩阵来生成结果其实是一样的,因为transformer并没有规定权值矩阵的size必须是(d_model,d_model),只要是(d_model,?)能保证矩阵相乘即可。在这套源码中,为了便利将线性变换的输入输出维度都设置成了d_model,将结果h份均分,其实等价于h个size为(d_model, d_model/h)的权值矩阵与输入进行了线性相乘,即h个头。这也是为什么构造函数中检验能否整除的原因。
得到Query、Key、Value三个矩阵后,就到了正式计算attention的时候了,论文中称之为“Scaled Dot-Product Attention”(fig.8),对应代码中的第40行。
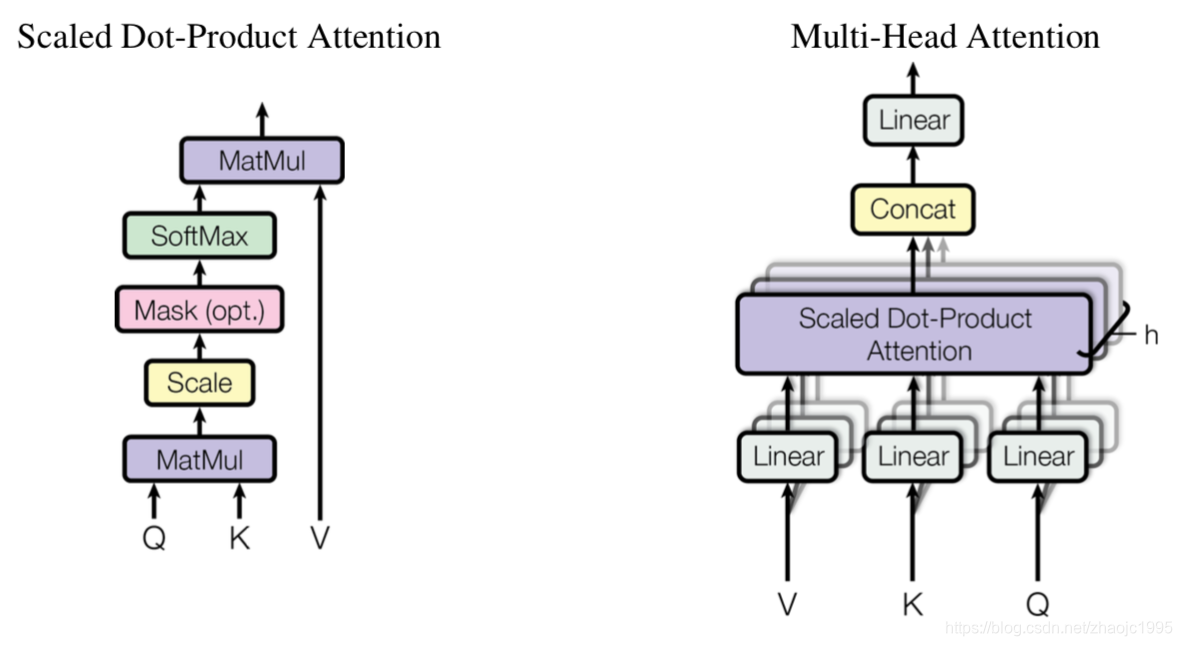 fig.8
fig.8
对应公式: Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text { Attention }(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V Attention (Q,K,V)=softmax(dkQKT)V
第40行代码引用的函数源码如下:
def attention(query, key, value, mask=None, dropout=None):
"""
实现 Scaled Dot-Product Attention
:param query: 输入与Q矩阵相乘后的结果,size = (batch , h , L , d_model//h)
:param key: 输入与K矩阵相乘后的结果,size同上
:param value: 输入与V矩阵相乘后的结果,size同上
:param mask: 掩码矩阵
:param dropout: drop out
"""
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k) #计算QK/根号d_k,size=(batch,h,L,L)
if mask is not None:
# 掩码矩阵,编码器mask的size = [batch,1,1,src_L],解码器mask的size= = [batch,1,tgt_L,tgt_L]
scores = scores.masked_fill(mask=mask, value=torch.tensor(-1e9))
p_attn = F.softmax(scores, dim = -1) # 以最后一个维度进行softmax(也就是最内层的行),size = (batch,h,L,L)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn # 与V相乘。第一个输出的size为(batch,h,L,d_model//h),第二个输出的size = (batch,h,L,L)
attention函数中第11行即计算Query、Key矩阵相乘并缩放,缩放的目的是作者认为过大的值会影响softmax函数,将其推入一个梯度很小的空间。具体为什么会这样,我也不清楚…这步对应的图解如图fig.9
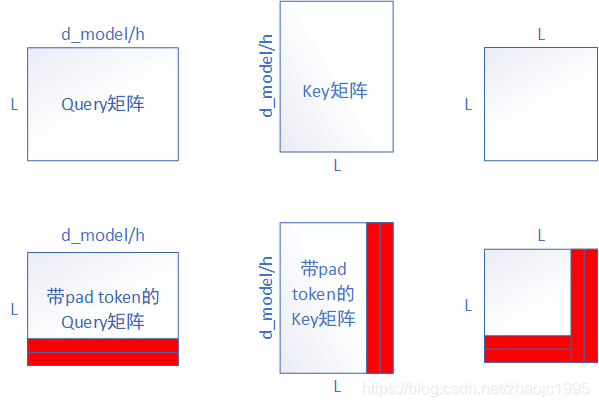 fig.9
fig.9
图9中忽略了缩放,因为缩放不影响矩阵的形状。从图9中我们可以看到,结果为L*L的一个方阵,表示这个句子中,每个词都与其他词打了个照面。对于pad token,最终传播到结果中,行列都有,列表示别的词与pad token的结果,行表示pad token与别的词的结果。按步骤下一步应该softmax了,但图中红色部分是与pad token相关的,理论上是不应参与softmax的,所以需要一点手段将其屏蔽,即mask矩阵。观察attention函数的第14行,mask矩阵的作用是将图中红色部分替换一个极小的数字,这样就使得softmax几乎忽略掉它。生成mask矩阵的代码如下:
class Batch:
def __init__(self, src, trg=None, pad=0):
"""
:param src: 一个batch的输入,size = [batch, src_L]
:param trg: 一个batch的输出,size = [batch, tgt_L]
"""
self.src = src
self.src_mask = (src != pad).unsqueeze(-2) #返回一个true/false矩阵,size = [batch , 1 , src_L]
if trg is not None:
self.trg = trg[:, :-1] # 用于输入模型,不带末尾的<eos>
self.trg_y = trg[:, 1:] # 用于计算损失函数,不带起始的<sos>
self.trg_mask = self.make_std_mask(self.trg, pad)
self.ntokens = (self.trg_y != pad).data.sum()
@staticmethod #静态方法
def make_std_mask(tgt, pad):
"""
:param tgt: 一个batch的target,size = [batch, tgt_L]
:param pad: 用于padding的值,一般为0
:return: mask, size = [batch, tgt_L, tgt_L]
"""
tgt_mask = (tgt != pad).unsqueeze(-2) # 返回一个true/false矩阵,size = [batch , 1 , tgt_L]
tgt_mask = tgt_mask & Variable(
subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data)) # 两个mask求和得到最终mask,[batch, 1, L]&[1, size, size]=[batch,tgt_L,tgt_L]
return tgt_mask # size = [batch, tgt_L, tgt_L]
def subsequent_mask(size):
"""
:param size: 输出的序列长度
:return: 返回下三角矩阵,size = [1, size, size]
"""
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8') #返回上三角矩阵,不带轴线
return torch.from_numpy(subsequent_mask) == 0 #返回==0的部分,其实就是下三角矩阵
Batch类中生成了两种mask,一种用于编码器,一种用于解码器。这里我们暂时仅需要关注第一种,在Batch类构造函数的第8行。这里的mask的size为[batch , 1 , src_L],表示针对batch中的每一条分词后的句子,都有一个形为[1,src_L]布尔矩阵与每个词一一对应,这里的src_L即本batch输入的最长句子长度。mask矩阵要处理的矩阵形状为[L,L],算上多头,形状为[h,L,L],再算上batch,mask矩阵最终要遮盖的矩阵形状为[batch,h,L,L],那么目前mask矩阵的形状肯定还是对应不上的。现在回到MultiHeadedAttention代码块的第29行,这里增加了一个维度,值为1,意为在这个维度上执行相同的操作,即对每个头执行相同的掩码操作。
掩码的最细粒度,就是利用size为[1,src_L]的mask对一个size为[L,L]的矩阵进行掩码,mask中的维度1意为在此维度上进行相同的操作。具体过程可以看下图。
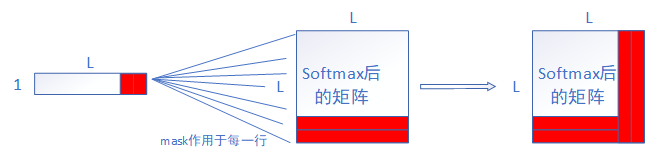 fig.10
fig.10
执行完mask就该softmax了,对应attention函数代码块的第15行,由于每行表示同一个词与其他词“打照面”的结果,所以对行进行softmax。图11中的softmax,每行可以看作一个词自己与其他所有词的权重。比如第一行的L个权重,归属第一个词,意为第一个词与其他L个词(包括自己)的“相关性“,当然这里的”相关性“只是比喻。与Value矩阵进行矩阵乘法,就将L个权重作用到了L个词的Value值上。其中softmax矩阵右侧红色竖列是经过mask处理的,下端红色的行为pad token引入,这两者都是我们不考虑的。图11的过程对应第18行,完成这步后至此完成Scaled Dot-Product Attention。
 fig.11
fig.11
结果如图10所示,一个批次中带有pad token,那么最终会传播到结果中,还是原位置。得到结果后就要执行图6的拼接和线性变换的操作,对应MultiHeadedAttention代码块的第43-45行。最终h个头拼接后的size为[batch,L,d_model],正好对应MultiHeadedAttention的18行定义的输入输出维度都为d_model的最后一个线性变换。所以看到这里可以明白,克隆4个线性变换、要求d_model整除h,都是作者刻意设计的结果,这些设计让整个代码更加简洁。这部分结束后transformer最复杂的地方也就清楚了,下面是一些不那么创新的组件,但仍然发挥了重要的作用。
SublayerConnection and LayerNorm
自注意力求解完后就轮到了求和与归一化。这部分原理比较简单,直接上代码。
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
"""
实现层归一化
"""
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features)) # 类似BN层原理,对归一化后的结果进行线性偏移,feature=d_model,相当于每个embedding维度偏移不同的倍数
self.b_2 = nn.Parameter(torch.zeros(features)) # 偏置。系数和偏置都为可训练的量
self.eps = eps # 保证归一化分母不为0
def forward(self, x):
"""
:param x: 输入size = (batch , L , d_model)
:return: 归一化后的结果,size同上
"""
mean = x.mean(-1, keepdim=True) # 最后一个维度求均值
std = x.std(-1, keepdim=True) # 最后一个维度求方差
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2 #归一化并线性放缩+偏移
class SublayerConnection(nn.Module):
"""
实现残差连接
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size) # 读入层归一化函数
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"""
:param x: 当前子层的输入,size = [batch , L , d_model]
:param sublayer: 当前子层的前向传播函数,指代多头attention或前馈神经网络
"""
return self.norm(x + self.dropout(sublayer(x))) #这里把归一化已经封装进来,size = [batch , L , d_model]
LayerNorm是一个层归一化的函数,比较基础就不多聊了。SublayerConnection是残差连接,其构造函数把层归一化集成了进来,forward函数中的sublayer指代一个传播函数,它可以是多头注意力机制也可以是前馈神经网络,因为在transformer中这两个部分之后都用到了求和与归一化,这样写可以让其通用。无论是归一化还是残差连接,他们都不会改变输入的维度,所以输出结果的size还是[batch,L,d_model]。
PositionwiseFeedForward
完成求和与归一化后,下面要经过一个特别的前馈神经网络,称为Position-wise Feed-Forward Networks,公式如下:
F F N ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 \mathrm{FFN}(x)=\max \left(0, x W_{1}+b_{1}\right) W_{2}+b_{2} FFN(x)=max(0,xW1+b1)W2+b2代码如下:
class PositionwiseFeedForward(nn.Module):
"实现全连接层"
def __init__(self, d_model, d_ff, dropout):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
"""
:param x: size = [batch , L , d_model]
:return: size同上
"""
return self.w_2(self.dropout(F.relu(self.w_1(x))))
Position-wise Feed-Forward Networks由两个线性变换和一个relu激活函数组成,构造函数中定义了两个线性变换,第14行实现了公式。完成Position-wise Feed-Forward后仍然是一个“求和与归一化”,直接复用上一小节的代码即可。至此编码器的组建就全部介绍完了,下一步利用这些组件组成编码器层。
EncoderLayer
这里之所以叫编码器层而不叫编码器,是因为编码器可能含有N个编码器层。编码器的代码如下:
class EncoderLayer(nn.Module):
"""
Encoder层整体的封装,由self attention、残差连接、归一化和前馈神经网络组成
"""
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn #定义多头注意力,即传入一个MultiHeadedAttention类
self.feed_forward = feed_forward #定义前馈,即传入一个PositionwiseFeedForward类
self.sublayer = clones(SublayerConnection(size, dropout), 2) #克隆两个残差连接,一个用于多头attention后,一个用于前馈神经网络后
self.size = size
def forward(self, x, mask):
"""
:param x: 输入x,即(word embedding+postional embedding),size = [batch, L, d_model]
:param mask: 掩码矩阵,编码器mask的size = [batch , 1 , src_L],解码器mask的size = [batch, tgt_L, tgt_L]
:return: size = [batch, L, d_model]
"""
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask)) #实现多头attention和残差连接,size = [batch , L , d_model]
return self.sublayer[1](x, self.feed_forward) #实现前馈和残差连接, size = [batch , L , d_model]
构造函数中定义了多头注意力、前馈网络和残差连接,其中的size参数是word embedding的维度,即d_model。在forward函数中,由于SublayerConnection类中提前留了函数接口,所以按先后顺序把多头自注意力和前馈网络放进去即可,这段代码我认为是极其清晰的,也非常佩服作者的设计、整合能力。
看到这里我们注意到,在最开始我们的输入size为[batch,L,d_model],这里最终输出的size也是一样,这为无限套娃多层累加提供了极大便利,也是transformer算法设计上的一个小妙处。
Encoder
接下来就是真正的编码器了,编码器就是多层编码器层。代码如下:
class Encoder(nn.Module):
"""
Encoder最终封装,由若干个Encoder Layer组成
"""
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N) # N层Encoder Layer
self.norm = LayerNorm(layer.size) # 最终输出进行归一化
def forward(self, x, mask):
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
编码器就是多个编码器层组成,这里还是非常清晰的,唯一有疑问的是,不知道作者最后为什么还要进行归一化,按我的理解在最后一层编码器中已经归一化过了,不过这个倒是无伤大雅。
3 Decoder
我们再把图1搬过来,看一下解码器的结构。
解码器的输入是目标label的embedding,同样包括word embedding和position embedding。编码后的label经过一个带有特殊mask操作的“多头注意力机制”,然后再经过一个与编码器结果有交互的“多头注意力机制”与“求和归一化”,最后经过“前馈神经网络”。当然,这几个模块两两之间都夹杂了“求和与归一化”。
解码器的输入同样是一个batch的label,包含了label的所有信息。但预测时,我们显然是没有输入的,这里的处理方式就如同RNN一次样,以SOS起始符为第一个词输入,下一个词预测出来,再与当前输入连接作为新的输入。为了模拟这个过程,在解码器的“多头注意力机制”中采用了一种特殊的mask方式。接下来解读一下解码器解码的整个过程。
Decoder Layer
Decoder Layer的宏观结构还是比较简单的,就是将上文讲过的几个模块堆叠起来,代码如下:
class DecoderLayer(nn.Module):
"解码器由 self attention、编码解码self-attention、前馈神经网络 组成"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size # embedding的维度
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3) #克隆3个sublayer分别装以上定义的三个部分
def forward(self, x, memory, src_mask, tgt_mask):
"""
:param x: target,size = [batch, tgt_L, d_model]
:param memory: encoder的输出,size = [batch, src_L, d_model]
:param src_mask: 源数据的mask, size = [batch, 1, src_L]
:param tgt_mask: 标签的mask,size = [batch, tgt_L, tgt_L]
"""
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask)) # self-atten、add&norm,和编码器一样, size = [batch, tgt_L, d_model]
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask)) # 编码解码-attention、add&norm,Q来自target,KV来自encoder的输出,size = [batch, tgt_L, d_model]
return self.sublayer[2](x, self.feed_forward) # 前馈+add&norm, size = [batch, tgt_L, d_model]
Decoder Layer的构造函数相当简单,就是传入几个模块,forward函数也和编码器的类似,这里就不展开细聊了,唯一不同的是,在第20行传入的mask矩阵稍有不同,这里的mask矩阵同样在Batch类中生成。为了读者阅读的方便,再次将Batch类的代码搬运过来。
class Batch:
def __init__(self, src, trg=None, pad=0):
"""
:param src: 一个batch的输入,size = [batch, src_L]
:param trg: 一个batch的输出,size = [batch, tgt_L]
"""
self.src = src
self.src_mask = (src != pad).unsqueeze(-2) #返回一个true/false矩阵,size = [batch , 1 , src_L]
if trg is not None:
self.trg = trg[:, :-1] # 用于输入模型,不带末尾的<eos>
self.trg_y = trg[:, 1:] # 用于计算损失函数,不带起始的<sos>
self.trg_mask = self.make_std_mask(self.trg, pad)
self.ntokens = (self.trg_y != pad).data.sum()
@staticmethod #静态方法
def make_std_mask(tgt, pad):
"""
:param tgt: 一个batch的target,size = [batch, tgt_L]
:param pad: 用于padding的值,一般为0
:return: mask, size = [batch, tgt_L, tgt_L]
"""
tgt_mask = (tgt != pad).unsqueeze(-2) # 返回一个true/false矩阵,size = [batch , 1 , tgt_L]
tgt_mask = tgt_mask & Variable(
subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data)) # 两个mask求和得到最终mask,[batch, 1, L]&[1, size, size]=[batch,tgt_L,tgt_L]
return tgt_mask # size = [batch, tgt_L, tgt_L]
def subsequent_mask(size):
"""
:param size: 输出的序列长度
:return: 返回下三角矩阵,size = [1, size, size]
"""
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8') #返回上三角矩阵,不带轴线
return torch.from_numpy(subsequent_mask) == 0 #返回==0的部分,其实就是下三角矩阵
同样的,label输入的size也为[batch,tgt_L],label的mask由两个部分生成。第一个部分是第21行,生成方式与输入的mask系统,也是统计出哪些地方是pad token,size也为[batch,1,tgt_L]。第二部分是由subsequent_mask函数生成的一个size为[1,tgt_L,tgt_L]下三角矩阵,如下所示,其中0代表false,即在后面要掩住的地方。
[[[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]] size = [1,tgt_L,tgt_L]
然后在代码第23行对两个mask矩阵进行了求和操作,可以理解为求并集。[batch, 1, L] & [1, size, size] = [batch,tgt_L,tgt_L],size中为1的部分,表示在对方此维度上进行“广播”,也就是进行相同的操作。最终结果的size为[batch, tgt_L, tgt_L],也就是说对于batch中的每一个句子,都对应一个size为[tgt_L, tgt_L]的掩码矩阵。
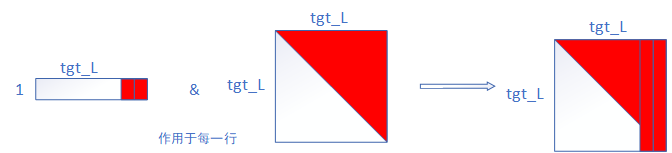 fig.12
fig.12
在编码器的讲解流程中,先讲了传播过程,在传播过程中遇到mask需求时候,才自然引出mask的介绍。这里之所以没有按照这个顺序是因为,解码器mask的设计不光针对transformer的训练阶段,与模型预测阶段也息息相关甚至更相关。但不清楚训练阶段又无法理解测试阶段,所以我们先陈述“现象”,带着问题,当所有的“现象”陈述完毕之后,自然就能明白解码器mask为何这样设计。
我们先来推导在训练阶段label的正向传播。label经过embedding后,size与编码器的输入是一致的,也是[batch,tgt_L,d_model]。labe的第一个“多头注意力”机制传播如图13。
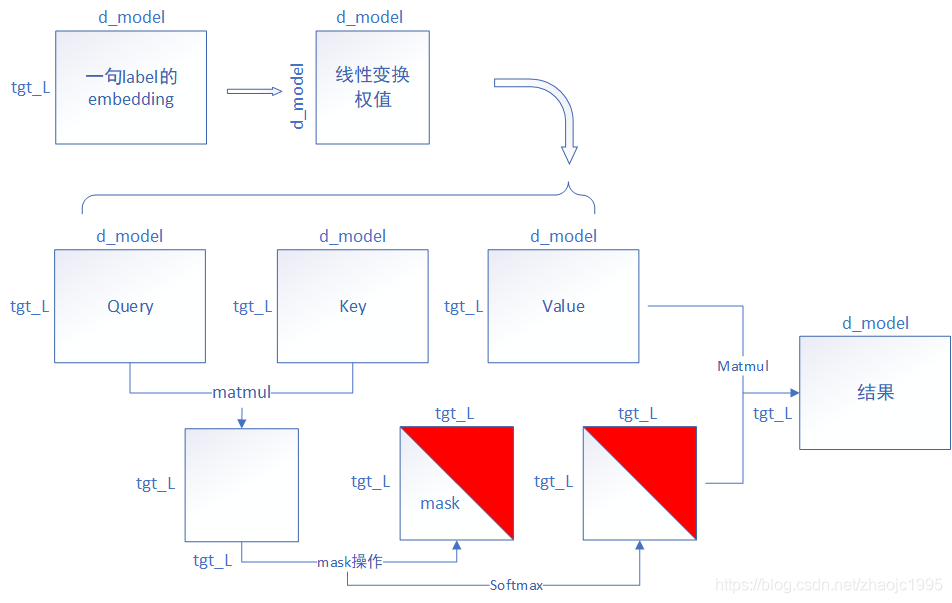
fig.13
图13简化了传播流程,忽视了batch维度和多头h的维度,仅在最小粒度表示一条label的传播过程。其中Query、Key、Value矩阵生成的过程,完全与图7一致,最终结果的size依然是[batch,tgt_L,d_model]。然后Query矩阵与Key矩阵相乘生成size为[batch,h,tgt_L,tgt_L]的矩阵。图13在这里mask也进行了简化,着重突出解码器特有的下三角矩阵,而忽略了pad token进行掩码的情况。
从结果往前反推,结果的第一行,只受到了第一个词与自身attention值的影响;第二行只受到了第二个词与第一个词的attention值、第二个词与自身attention值的影响。举个全网都在举的例子,假设这里输入的lael为[我,爱,机器,学习]四个词语(忽略与),结果的第一行只与attention(我,我)有关系,后面的部分被mask掉了。第二行仅与attention(爱,我)、attention(爱,爱)有关系,其余部分被mask掉了,结果第三、四、五行等等也是同样的道理。这么设计的原因,很多博客会说到这是在模拟预测时的情况,因为预测结果是迭代生成的,这是为了不让模型“偷看”到未来的内容。emmm…其实这样的解释,也不能说错,但终究还是没说透彻。我们带着问题先继续往下看。
经过解码器第一个“自注意力机制”后是一个“求和与归一化”步骤,对应这一步不影响矩阵的size,且与编码器完全相同,就不展开讲了。紧接着又是一个“自注意力机制”,对应DecoderLayer的第21行。前面在编码器首次解释“自注意力机制”代码的时候,我就说过这份代码之所以把输入设计成三个,是因为Query、Key、Value矩阵并不一定是由一个东西线性变换生成的,这里就体现到了。解码器这里的输入为解码器上一步的结果和编码器最终的结果,其传播流向如图14。
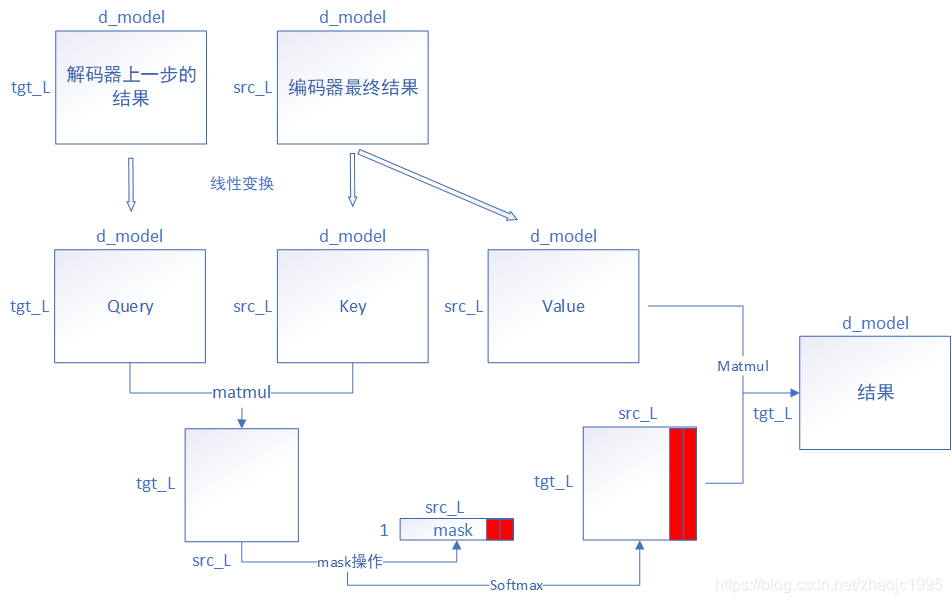 fig.14
fig.14
这次的“自注意力机制”与编码器就类似了,虽然输入编码器的结果引入了src_L(输入句子的长度),但这并不影响整个传播流程,这也得益于编码器的mask矩阵是以广播的形式对矩阵进行处理的。
在解码器第一个“自注意力机制”末尾我们讲到,结果第一行只受到了第一个词自身的attention值的影响,第二个词只受到了与第一个词的attention值、第二个词与自身attention值的影响。反映到图14中,图14的结果,第一行只受到了解码器上一步结果中第一行的影响,第二行只受到了第二行的影响,也就是说,经过两个“自注意力机制”,解码器特殊的mask矩阵带来的影响,是无缝传递过来的。
Decoder
解码器层与编码器层有一个相同的特点,那就是输出的size与输入的size会保持相同,这同样为无限套娃带来了方便。解码器就是N个解码器层组成的,代码如下:
class Decoder(nn.Module):
"解码器的高层封装,由N个Decoder layer组成"
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x) # size = [batch, tgt_L, d_model]
经过N层解码器层,输入的size依然是[batch, tgt_L, d_model]。
Encoder-Decoder
上面将编码器与解码器都介绍过了,整体的编码解码结构就是对两者的封装,代码如下:
class EncoderDecoder(nn.Module):
"""
编码解码架构
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder # 编码器
self.decoder = decoder # 解码器
self.src_embed = src_embed #源的embedding
self.tgt_embed = tgt_embed #目标的embedding
self.generator = generator # 定义最后的线性变换与softmax
def forward(self, src, tgt, src_mask, tgt_mask): # 编码解码过程
return self.decode(self.encode(src, src_mask), src_mask,
tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
经过编码解码之后,最后还有一个线性变换与softmax,这步是为了计算损失函数做准备,代码如下:
class Generator(nn.Module):
"""
定义一个全连接层+softmax
"""
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab) # vocab为整个词袋的词数
def forward(self, x):
"""
:param x: 输入的 size = [batch, tgt_L, d_model]
"""
return F.log_softmax(self.proj(x), dim=-1) #dim=-1在最后一维上做softmax
 fig.15
fig.15
图15表示了这个过程。vocab表示整个词袋的词数,将其线性变换为这个维度的原因就是为了在这个维度softmax,每一行会产生一组和为1的概率,共tgt_L行。例如,第一行会产生一组长为vocab的概率组,表示预测结果为词袋中任意一次的概率。同样的,第一行也会对应一个真实标签的one-hot编码。这样总共tgt_L个预测结果,对应tgt_L个真实标签的one-hot编码,两者做交叉熵,完成了损失函数的求解。
还记得前面说过,结果的第一行只受第一个词自身attention值的影响,第二个词只受到了与第一个词的attention值、第二个词与自身attention值的影响。。。这也会反映到图15最终的结果上。那么还是那个问题,为什么这么做模拟了预测过程?现在可以来解答这个问题。
首先讲一下transformer的预测过程。transformer虽然很复杂,但它仍然是一个编码解码的结构,其预测过程与其他编码解码结构的算法也是一致的。即首先输入,预测出第一个词,然后将预测值拼接回来,输入[,预测结果1]去预测第二个词,以此类推。在预测结果不断返回来拼接然后再次输入的过程中,有一个步骤是一直在重复经历的——解码器下三角矩阵mask机制。我们画个图来模拟一下这个过程。
 fig.16
fig.16
图16模拟了两步,我们发现了两个事实:
1、输入词起始符和词1的时候,仍然预测了词1,只不过我们选择性忽略,只抽取出词2然后继续拼接而已。
2、在图中第二步中,对应的attention,仍然只有自身与自身,这便是下三角矩阵掩码的结果。
那么为什么在预测阶段还要进行下三角矩阵的掩码?我们试想一下,如果不进行掩码,在第二步中,的attention除了与自身,还有与词1的,这就会导致在第二步中预测的词1与第一步不同。遵循这个规律,第三步中预测的词1、2与第二步中的也不同,而我们的做法是每次选择性忽略重复的预测的词,只摘取出最新预测的词语拼接然后继续预测,所以我们一定要保持每一步中重复预测的词语是一致的,否则我们不断拼接、不断迭代预测将变成一种脑瘫行为。
在训练阶段,label全量只进去一次,不是一个一个进去的,如果想要在训练阶段进去一次就能模拟出预测阶段多次预测、拼接的过程,将mask设计成下三角矩阵恰好能实现。
综上,总结一下解码器mask设计思路的原因:1、预测阶段要保持重复预测词一致——>必须保持每步attention的值不变——>掩码掉未来词——>mask下三角矩阵;2、恰好也可以使模型在训练阶段的传播过程与预测阶段一致。
结尾
至此,transformer的源码就介绍完了,个人感觉写得逻辑还算清晰,哪里有不明白或错误的地方欢迎留言。