part1:数据的引入,和前一个linear regression基本是一样



part2:数据解析——也就是数据的“规格化”
 首先,打算用dataMat[]和labelMat[]数据存储feature和label,并且文件变量fr
首先,打算用dataMat[]和labelMat[]数据存储feature和label,并且文件变量fr
然后,是这个for line in fr.readlines()循环,就是逐行的读取字符串到line中,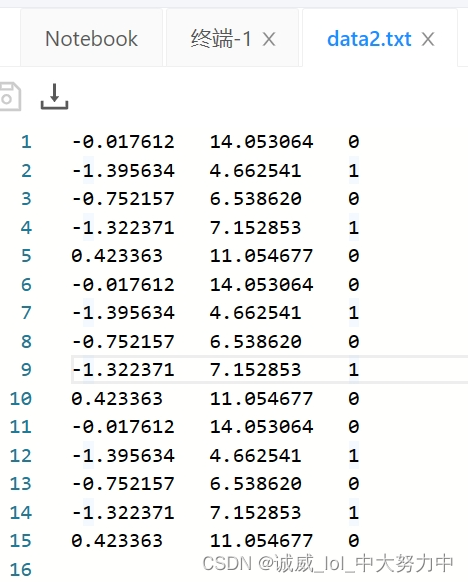
比如上面的那个data.txt中的数据,一行有3个数据用"\t"制表符进行分隔,结果就是这个3个数据作为curLine[]这个一维数组中的3个数据,
dataMat,存储的是[1.0,curline[0],curline[1]]作为元素的数组,总共15组
labelMat,存储的是curline[2]作为元素的数组,总共15组
part3:定义那个sigmoid function

part4:通过输入dataMat 和 labelMat作为 训练集,通过线性gradien descent计算出分割线的斜率
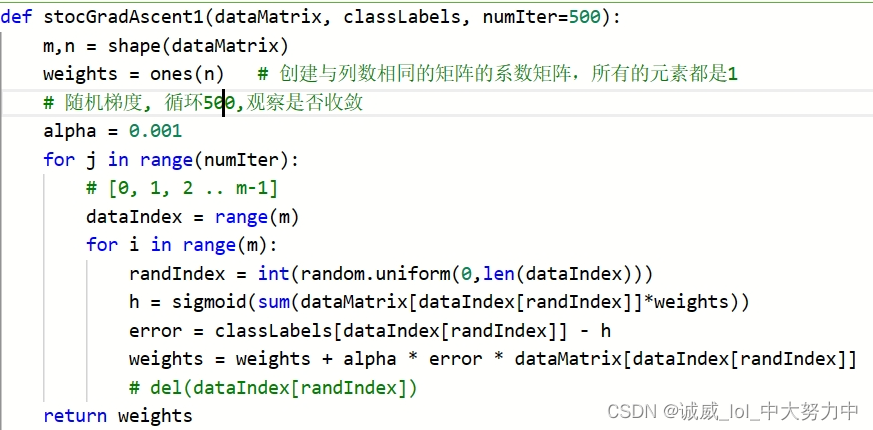 (1)具体的过程应该就是 如何通过训练集中的数据 计算出对应的 logistic regression的分割线的问题,详细可以参考李宏毅老师的 logistic regression相关的代码
(1)具体的过程应该就是 如何通过训练集中的数据 计算出对应的 logistic regression的分割线的问题,详细可以参考李宏毅老师的 logistic regression相关的代码
(2)里面的alpha是学习率,可以通过设置不同的学习率和循环次数观察结果
part5:绘制出 需要测试的点的数据 并将label用颜色标出, 最后画出由训练集得到的 分割线
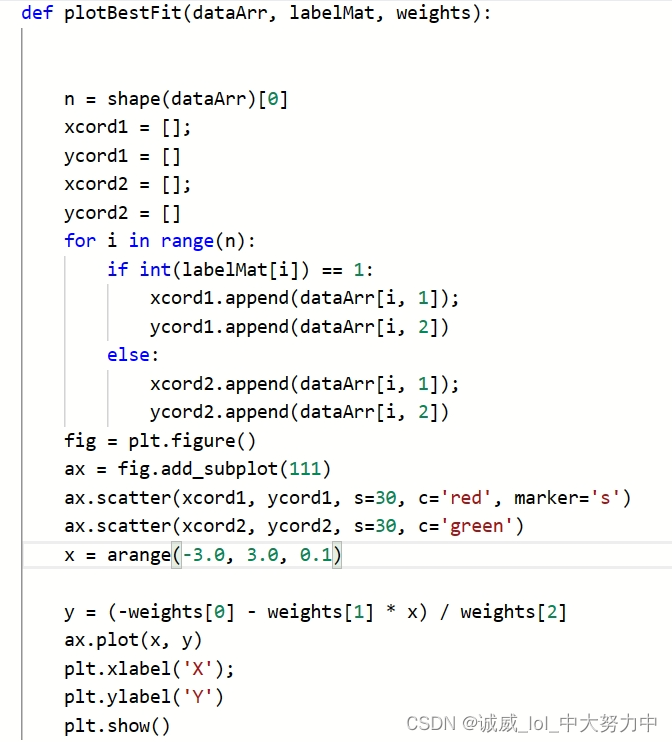
part6:调用上述定义的函数,并且得到最终的结果:

其实这个代码和data.txt给的一点也不好,
(1)它只有训练集,最终的结果也只是在训练集上做的测试
(2)data.txt看着有15组数据,其实只有5组,都是重复的,所以最终的图只有5个点