这周有粉丝私信想让我出一期GWO-KELM的文章,因此乘着今天休息就更新了(希望不算晚)

作者在前面的文章中介绍了ELM和KELM的原理及其实现,ELM具有训练速度快、复杂度低、克服了传统梯度算法的局部极小、过拟合和学习率的选择不合适等优点,而KELM则利用了核学习的方法,用核映射代替随机映射,能够有效改善隐层神经元随机赋值带来的泛化性和稳定性下降的问题,应用于非线性问题的性能更优[1]。
而灰狼优化算法(GWO)通过模拟灰狼群体捕食行为,基于狼群群体协作的机制来达到优化的目的,这一机制在平衡探索和开发方面取得了不错的效果,并且在收敛速度和求解精度上都有良好的性能,具有原理简单、并行性﹑易于实现,需调整的参数少且不需要问题的梯度信息,有较强的全局搜索能力等特点。
因此作者将用ELM和KELM结合灰狼优化算法应用于回归拟合问题,并将之与BP神经网络这类传统机器学习算法以及PSO-KELM进行对比。
00目录
1 GWO-KELM模型
2 代码目录
3 预测性能
4 源码获取
参考文献
01 GWO-KELM模型
1.1 GWO与KELM原理
GWO即灰狼优化算法,KELM即核极限学习机,作者在前面的文章中讲解过其具体原理,文章链接如下,这里不再赘述。
核极限学习机原理及其MATLAB代码实现
灰狼优化算法原理及其MATLAB代码实现
1.2 GWO-KELM预测模型
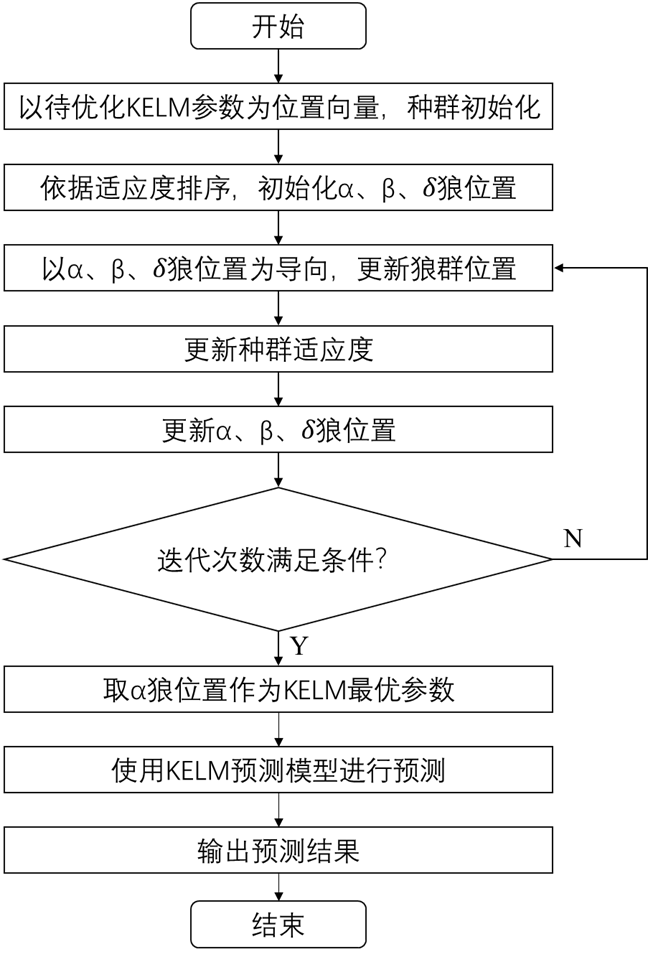
将GWO与KELM结合,以KELM模型预测的MAE作为GWO的适应度,该模型流程如下:
02 代码目录
其中,MY_XX_Reg.m都是可单独运行的主程序,而result.m用于对比不同算法预测效果,result.m可依次运行5个MY_XX_Reg.m,并对其预测结果进行对比。
03 预测性能
3.1 评价指标
为了验证预测结果的准确性和精度,分别采用均方根差(Root Mean Square Error,RMSE) 、平均绝对百分误差( Mean Absolute Percentage Error,MAPE)和平均绝对值误差( Mean Absolute Error,MAE) 作为评价标准。
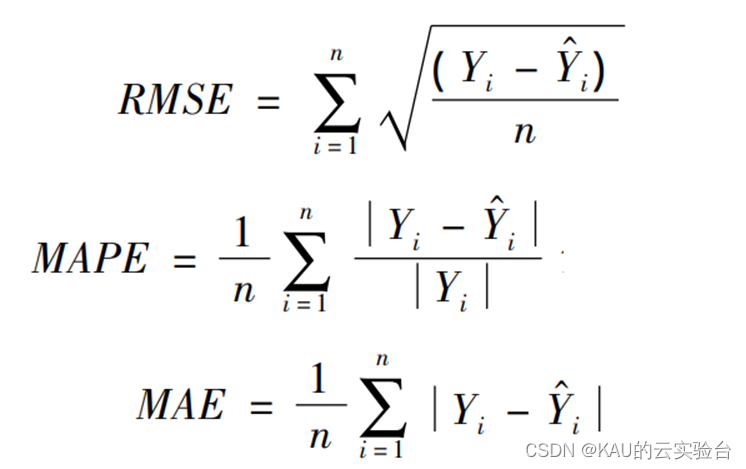
式中 Yi 和Y ^ i分别为真实值和预测值; n 为样本数。
3.2 结果对比
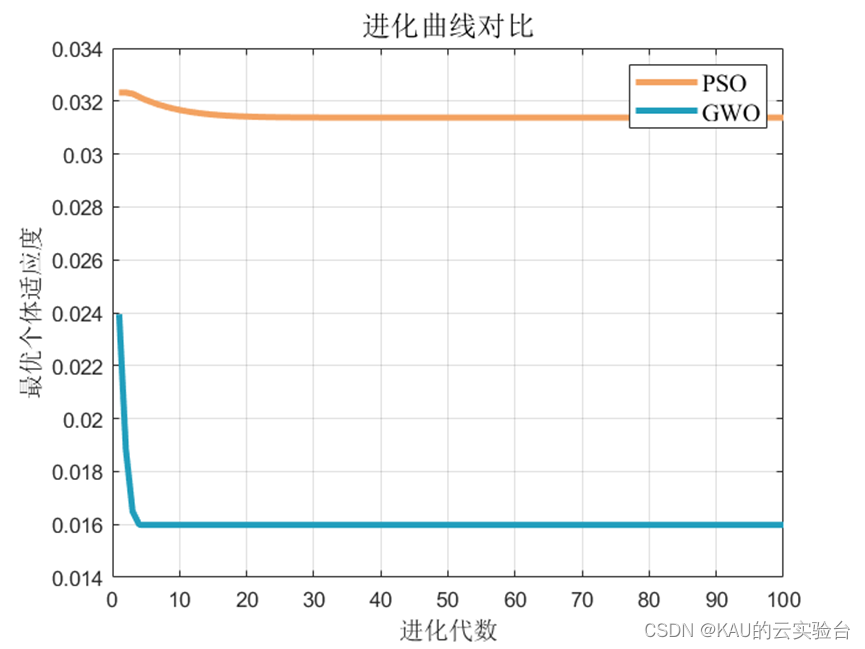
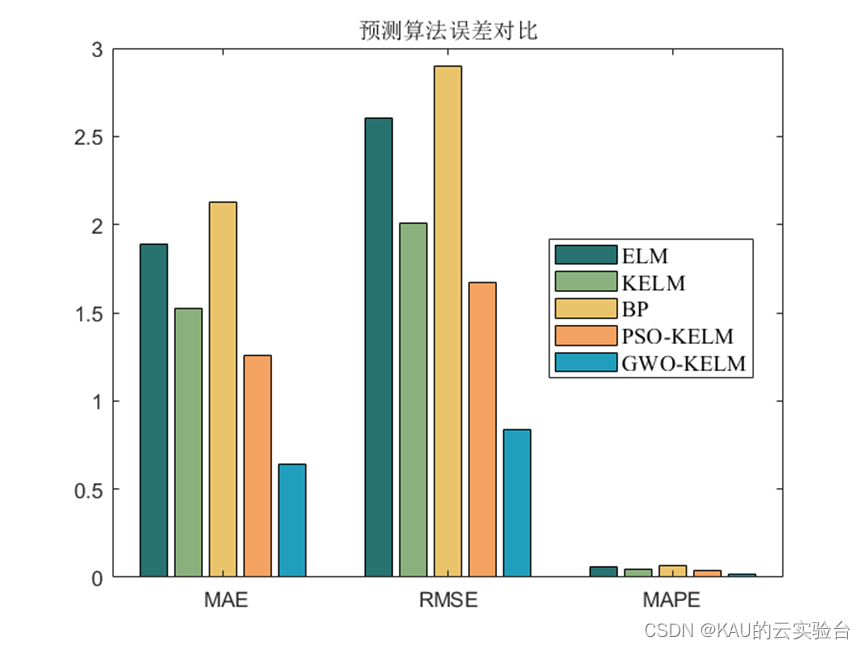
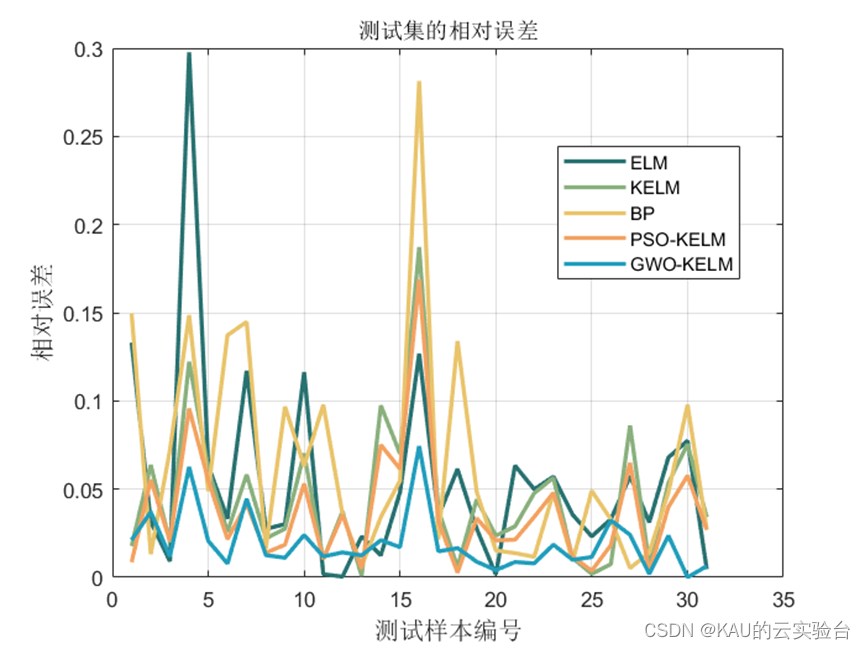
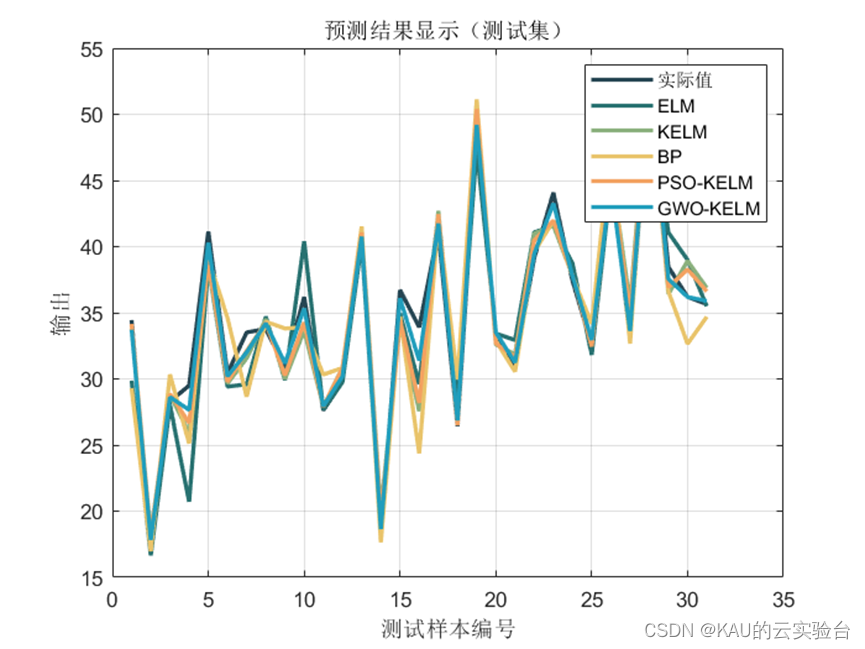
可以看出,预测模型中,经GWO和PSO优化后的KELM预测模型取得了不错的效果,而GWO的预测性能又更优于PSO,其收敛速度和精度都远好于PSO。
04 源码获取
在作者公众号:KAU的云实验台
参考文献
[1] Huang G B,Zhou H M,Ding X J,et al.Extreme learning machine for regression and multiclass classification[J].IEEE Transactions on Systems, Man,and Cybernetics,Part B (Cybernetics),2012,42(2):513.
另:如果有伙伴有待解决的优化问题(各种领域都可),可以发我,我会选择性的更新利用优化算法解决这些问题的文章。
如果这篇文章对你有帮助或启发,可以点击右下角的赞(ง •̀_•́)ง(不点也行),若有定制需求,可私信作者。