Anima模型又开源了基于QLoRA的最新的DPO技术。
DPO是最新的最高效的RLHF训练方法。RLHF一直是生成式AI训练的老大难问题,也被认为是OpenAI的压箱底独家秘笈。DPO技术改变了这一切,让RLHF彻底傻瓜化!
我们开源了RLHF的低成本QLoRA的实现,一台GPU机器就可以训练33B模型的DPO!
01 为什么RLHF对于AI落地至关重要 ❓
展开讲讲:生成式AI的最核心的技术创新之一就是所谓的“因果语言模型(Causal Language Model)损失函数”。说白了就是模型是训练去预测下一个词是什么。
很多最成功的技术,往往最简单直接。这种预测下一个词是什么的训练目标,因为足够简单,所以很容易扩展到无限多的训练数据。比因果语言模型更为精妙的模型设计很多,但是很多都太复杂,没法容易的scale到更多的训练数据。AI最重要的是数据。有了因果语言模型,提升数据量只需要一件事:砸钱 !就像马云老师的所说:能用钱解决的问题都不是问题 !

100 million
但是各路土豪砸了无数个小目标以后,发现这种因果语言模型训练存在一个缺陷——模型不容易控制。因为训练目标只是下一个词,太微观,很难告诉模型一些更为宏观的目标,比如:控制输出的长度,比如:整点有用的!别只说废话!
如何令生成式模型更容易控制是一个很热门的研究领域。有很多的paper,提出了很多不同的想法。但都没有能很好的解决问题。
直到2022年末,openAI的ChatGPT发布。ChatGPT表面上看是一个聊天AI,但是技术上讲最大的突破是他第一次有效的引入了强化学习技术PPO来训练大语言模型,进行RLHF(reinforcement learning from human feedback)训练(https://arxiv.org/abs/2203.02155)。RLHF取得了奇效:终于可以很好的实现对于生成式模型的精准控制与调校!
RLHF对于大语言模型在垂直领域的落地应用至关重要,特别是对于数据的拥有者,你可以使用自己的场景数据和用户反馈数据通过RLHF直接告诉模型什么是你要的,什么是你不想要的。或者就直接根据你的使用场景,去做一定量的人工标注,对于模型输出不够满意的案例人工标注出问题在哪里,更好的输出是什么。然后直接使用RLHF训练模型。
02 横空出世的RLHF的革命者DPO技术
OpenAI独家绝技PPO为啥这么难用?
RLHF和PPO的训练难度比较高。特别是对于数据要求很高,很不稳定。很多人说RLHF和PPO是OpenAI的独家秘笈。
OpenAI除了名字以外一点都不open,对于如何高效训练PPO的关键细节一直缄口不提。OpenAI最近在硅谷也喜提新昵称:ClosedAI。

Closed AI
OpenAI的独家秘籍的PPO技术源自于OpenAI早年的游戏AI的积累。PPO虽然强大,但是训练难度很高。训练过程需要首先额外训练两个model:reward model和finetune SFT model。不但需要额外的时间和硬件成本,这两个model都需要占用本来就非常宝贵的GPU显存!训练过程也很不稳定,经常就是训练失败,模型不收敛。对于标注数据的质量要求也很高。除非你像OpenAI一样壕 ,舍得花大钱搞标注,否则很可能数据质量不过关。
RLHF的革命者:DPO技术---让RLHF民主化
最近斯坦福和CZ Biohub联合论文中提出了DPO(Direct Preference Optimization,https://arxiv.org/abs/2305.18290)技术。可以说是一个屌丝平替版的RLHF PPO。不但大幅降低了RLHF的难度,非常容易训练,而且按照论文中的评测对比,训练性能也超越了PPO技术!
DPO的核心原理是:PPO训练难度核心是因为需要通过reward model来表达偏好,进行强化学习。如果能够省略掉reward model,问题就能瞬间变简单很多!
为了不再依赖于reward model进行强化学习,他进行了一系列的数学变换,直接推导出了基于Policy Language Model的标注偏好的概率表达形式,从而可以直接求解一个Language Model的最大似然估计。不再需要复杂繁琐的reward model和强化学习。
DPO最牛之处有以下几点:
- DPO去掉了reward model。原来PPO训练需要额外的两个辅助模型reward model和SFT model。现在只需要训练一个SFT model。这根本上克服了训练中波动过高带来的不稳定的来源,大大提升了训练的稳定性和成功率,降低了对于标注数据质量的要求。
- 由于去除掉了reward model,训练速度也大大提升了,而且大大降低了对于宝贵的GPU内存的需求。
- 可能更为重要的是,训练和迭代过程中少了一个reward model,大大降低了对于宝贵的GPU内存的需求。想想一台80GB H100的售价,降低GPU内存意味着什么就不容多说了吧?懂得都懂 !

03 我们开源了低成本QLoRA版DPO算法,小白也能轻松玩转RLHF训练
之前我们开源了第一个基于QLoRA的33B中文大模型Anima 33B。第一次可以把33B级别的大模型训练成本降低到只需要一台GPU机器即可。
这一次,我们基于之前的工作Anima,基于QLoRA实现了DPO论文的算法。我们开源了全部的代码,小白也能几行代码就针对你的领域数据进行RLHF训练!
DPO的核心是以下的DPO Loss:
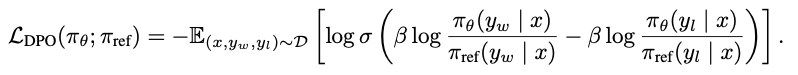
DPO Loss
这个Loss使得我们可以直接优化求解preference的最大似然解。
我们基于QLoRA框架,实现了这个DPO loss。
如何使用Anima QLoRA DPO训练?
- 准备数据:我们采用类似于https://huggingface.co/datasets/Anthropic/hh-rlhf数据集的格式:训练数据的格式为每一条数据有两个key:chosen和rejected。用于对比针对同一个prompt,什么是标注认为好的输出和不好的输出。可以修改--dataset参数指向本地数据集或者huggingface数据集。
- 训练Supervised Fine Tune(SFT) model:这个SFT model,其实就是针对标注样本数据集训练的一个普通的LLM,可以参考Anima的方法进行训练。这个模型会作为DPO训练的初始值,训练过程也会参考这个模型,防止偏差过大。
- 使用以下代码进行训练:
# 1. install dependencies
pip install -r requirements.txt
# 2. run DPO training
cd rlhf
./run_dpo_training.shrun_dpo_training.sh 中的参数大部分和Anima的训练参数一致。有几个额外的DPO的参数:
- dataset:标注偏好数据集
- reference_model:这个应该指向上一个步骤中训练的SFT model
- beta:beta是DPO Loss中用于平衡KL散度的超参,越小对于SFT model的参考越弱。beta为零时相当于忽略SFT model。beta一般取值0.1-0.5。
04 开源Anima 33B的DPO alignment版本模型
我们针对我们开源的Anima 33B训练了DPO alignment的版本。我们使用了Belle开源的1k评测集。(感谢Belle的开源贡献!)这个评测集针对每一个问题都给出了高质量的标准答案,可以用来作为高质量的正向样本,而原来模型的输出就作为负向样本。这样训练会鼓励模型尽量输出接近于Belle评测集中的正确答案的回答方式。
训练采用了一台80G的H100,一共100个step,用时5小时,训练过程丝滑稳定:

完整merge的模型已经在Huggingface发布:https://huggingface.co/lyogavin/Anima33B-DPO-Belle-1k-merged。
全部源代码都已开源,Github 地址在此:https://github.com/lyogavin/Anima/tree/main/rlhf。
以下是经过DPO训练的模型前后输出变化的举例:
- 问题1: 世界上最长的河流是什么?
- 原模型回答:尼罗河。
- DPO训练模型回答:世界上最长的河流是尼罗河。它从非洲西部开始,经过苏丹、埃及、肯尼亚、坦桑尼亚和肯尼亚等国家,向东方流入 Mediterranean Sea 海。它有约6650公里长度,是地球上第二长的河流之一(次于亚马逊川)。尼罗河源头位于拉比山群中心,流经多个湖泊,包括天池、白 Nilometer 、布加利亚湖、瓦拉湖、贾格纳湖、太古湖、阿尔卑斯湖、亚当湖、亚特提克湖、亚历山大湖、亚喀拉沙湖、亚威拉湖、亚姆拉湖
- 问题2: 水的化学式是什么?
- 原模型回答:H2O
- DPO训练模型回答:水的化学式为H₂O。其中“H”代表氢原子、“О”代表氧原子。水分解成两个氢原子和一个氧原子,形成了水分子
- 问题3: 根据提供的关键词列表,生成一篇描述这些关键词的段落。
秋天、枫叶、北方、清寒- 原模型回答:秋天是北方地区最美好的季节之一,枫叶变色时间到了,整个城市都被染上了橙黄红色的斑点。清寒的空气中弥漫着淡淡的香气,人们可以感受到自然的平和与温暖。
- DPO训练模型回答:秋天是一个美丽的季节,特别是在北方地区。秋天时,枫叶变色为红黄和橙色,形成了奇妙的景象。人们可以到森林中漫步,欣赏那份自然的靓亮和平静。清寒的空气使得旅行更加舒适,同时也让人体会到秋日的神情。清寒的气候不仅让人感受到秋日的冷凉,还让人感受到秋日的沉思。清寒的气候让人感受到秋日的厚重,让人想起过去的回忆,并对未来有希望。
- 问题4: 哪些国家是永久理事国?
- 原模型回答:五大核能武器持有国(中国、俄罗斯、法国、英国和美国),以及萨摩耶、意大利、日本、西班牙和德国。
- DPO训练模型回答:有五个国家被认为是永久理事国,他们分别是:中华人民共和国、法国、俄罗斯、英国和美国。这五个国家在联合国成立时就获得了永久理事国身份,并且不需要通过大会选举来保持其位。永久理事国拥有特权,例如可以提起安全性问题或者参加讨论与决定关于安全性问题的行动。
(完整数据已开源,可以在github找到。)
可见,DPO训练会非常有效的调校模型输出更接近于GPT4喜好的方式。输出更为详尽的信息和回答的思维过程。
输出更为详细的思维过程也有助于帮助模型提升正确率。我们认为提升模型的基础推理能力和编码基础的knowledge储备更适合通过大规模与训练进行。而DPO和RLHF更适合进行模型的输出控制,或者领域知识的训练。