huggingface TRL实现20B-LLM+Lora+RLHF
Introduction
作者首先表示RLHF在目前LLM的训练中是一种很powerful的方式,训练模型利用RLHF通常包括以下三步:
- Finetune一个预训练模型通过特定领域的qa问答数据。
- 训练一个reward model
- 进一步finetune LLM通过 reward model 和RL
具体方法可参考我的上一篇文章。
流程图如下:
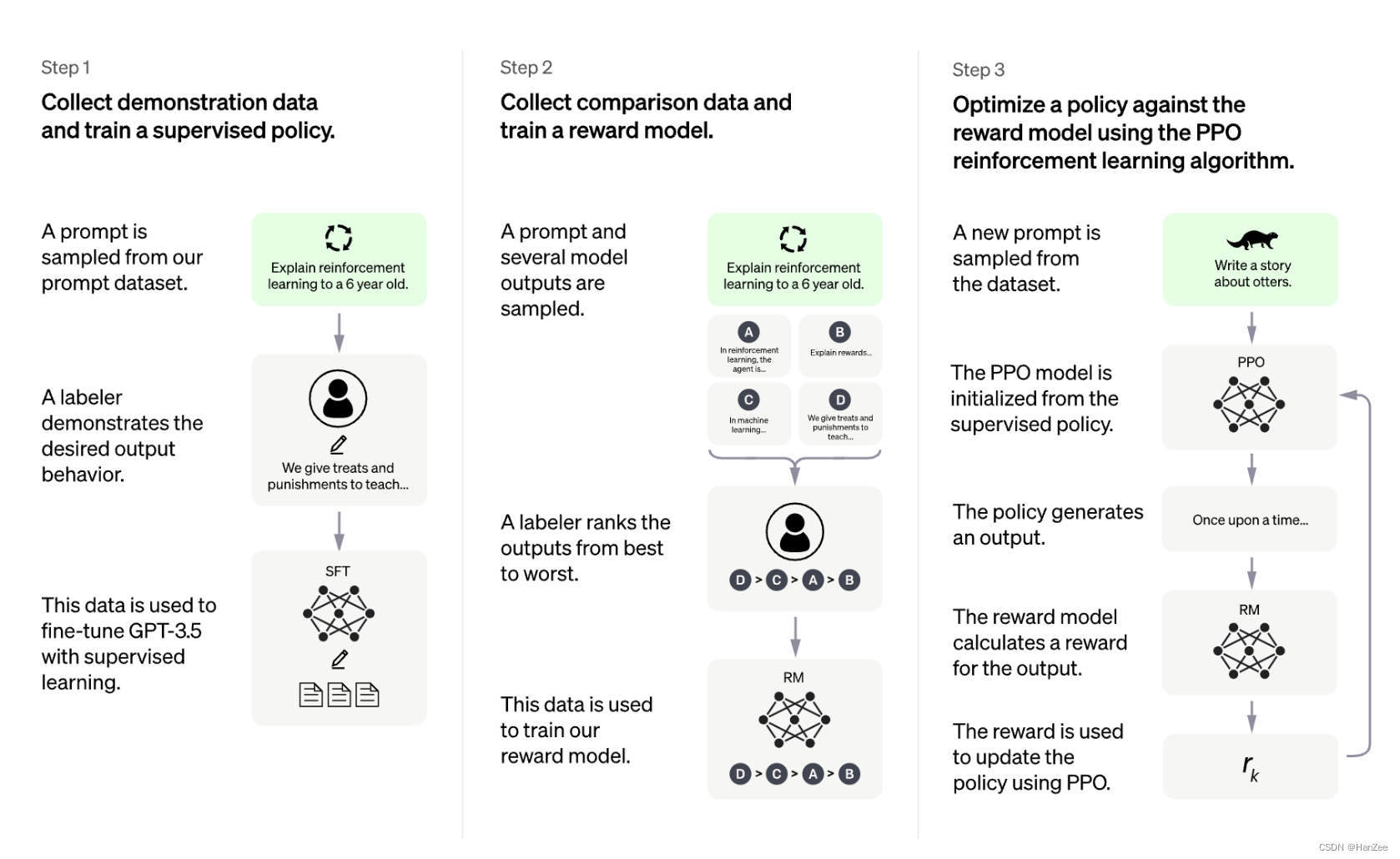
选择一个LLM也是很重要的事情,目前很好的选择有: BLOOMZ, Flan-T5, Flan-UL2, and OPT-IML. 如果你想得到一个还不错的效果,可能至少需要一个10B+的参数,但是这个尺寸的模型至少也需要一个40G的显存才能加载到显卡,如果还要训练,则需要更多。
What is TRL?
trl是一个基于peft的库,它可以让RL步骤变得更灵活、简单,你可以使用这个算法finetune一个模型去生成积极的评论、减少毒性等等。
在以前的 RLHF,我们需要复制两个模型(具体如下图,在损失函数公式上也有体现)的到每一个GPU上,随着模型尺寸的增大,这对单卡的情况很吃不消的。
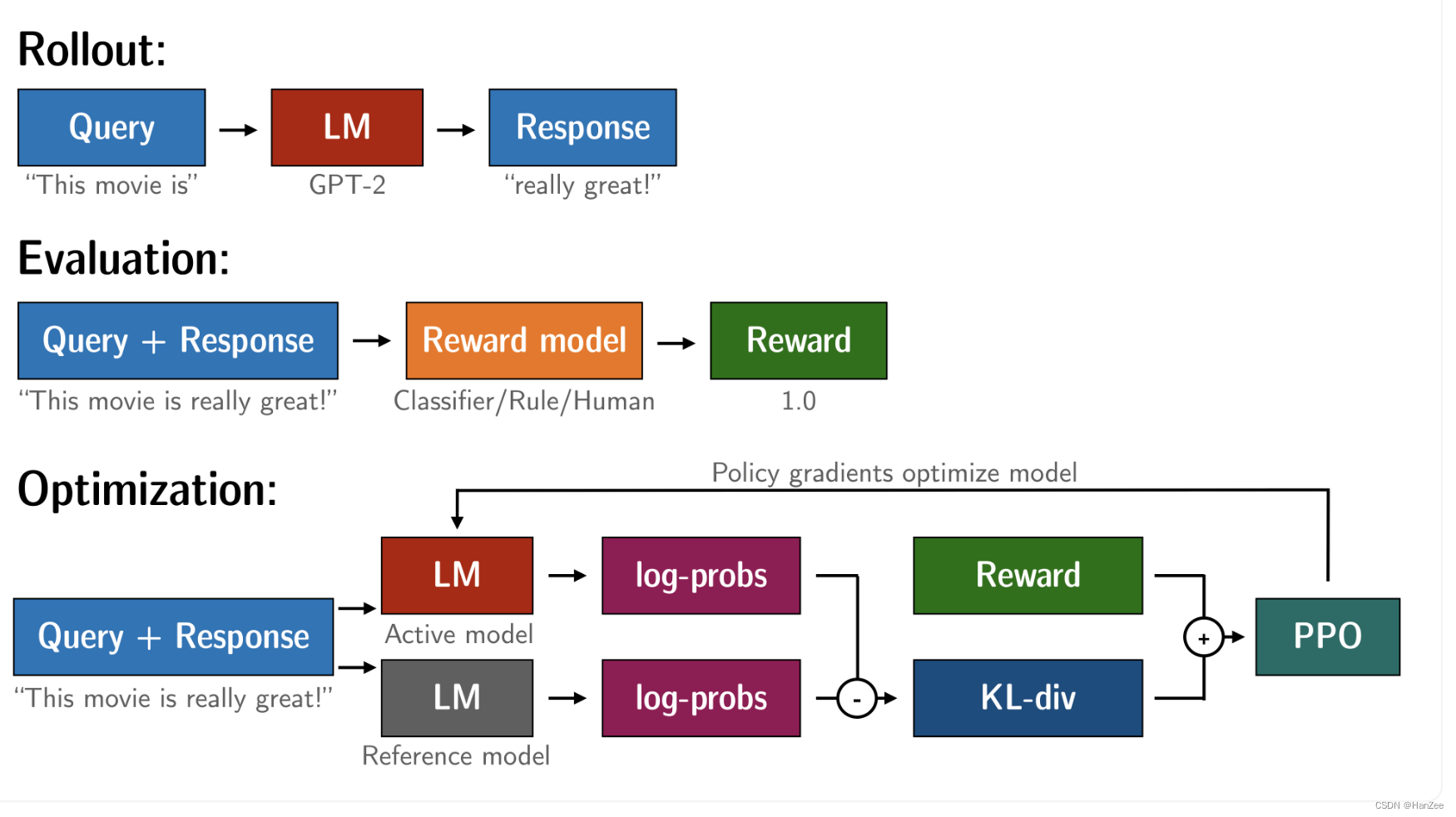
为了避免把两个模型的全部参数复制到GPU,trl的做法是使用模型的共享层。
Training at scale
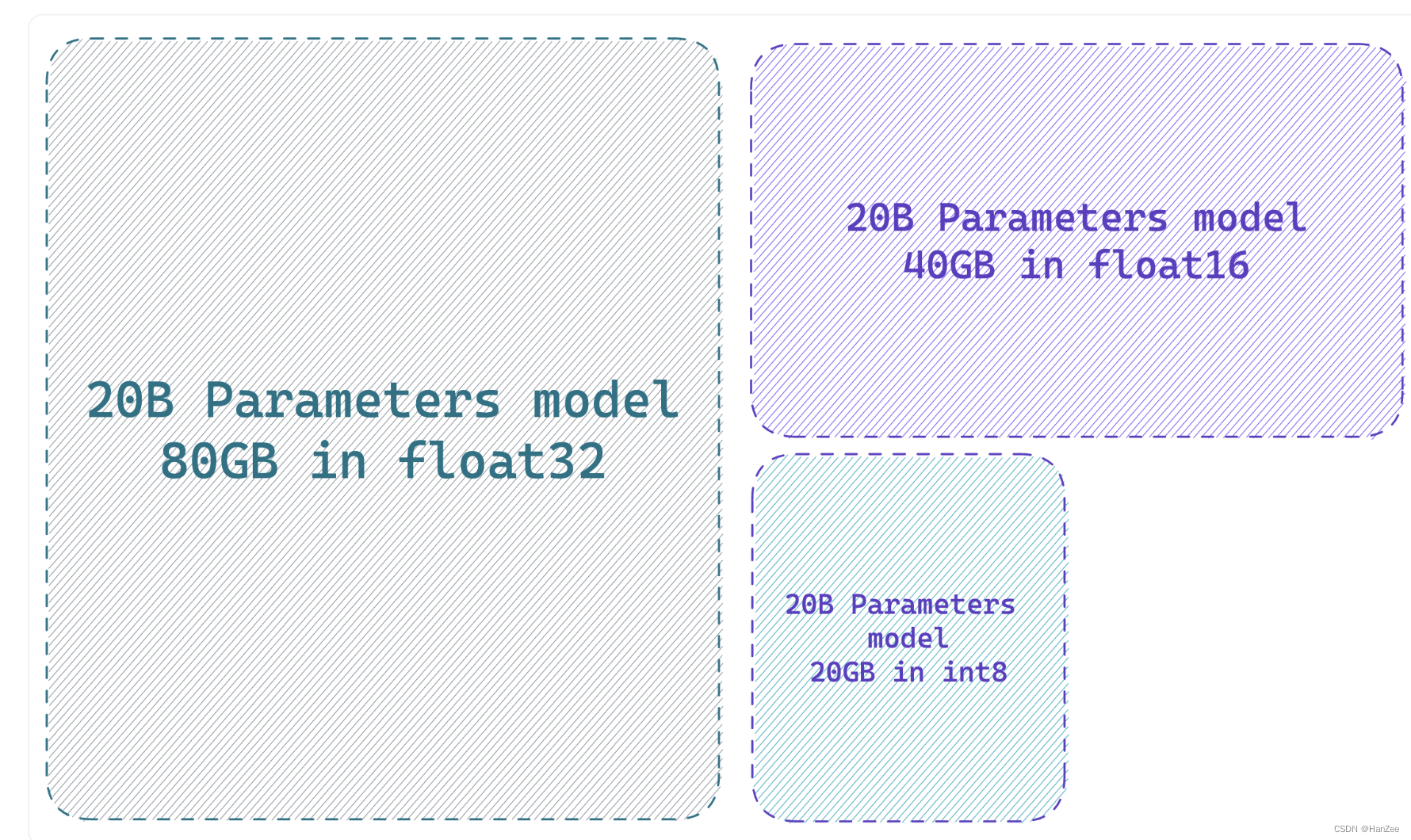
作者表示训练模型面临的第一份挑战就是在优化阶段。一个参数所占的显存取决于它的精度如 float32 ,float16 int 8,当把1B参数精度为fp32的模型加载进需要4G,fp16需要2G,int 8 则需要1G。
在这里说一下是如何计算的:
在计算机中,比特是可以存储或操作的最小数据单元。它的值只能是0或1。另一方面,字节是一个由8个比特组成的数据单元。字节和比特之间的关系是一个字节等于八个比特。这意味着,如果你有一个大小为1字节的文件,它包含8个比特的数据。同样,一个大小为10字节的文件包含80个比特的数据。
一个完整精度模型(32位=4字节)每十亿个参数需要4GB,半精度模型每十亿个参数需要2GB,int8模型每十亿个参数需要1GB。
如果你使用AdamW优化器,每个参数需要8个字节(例如,如果你的模型有1B个参数,模型的完整AdamW优化器将需要8GB的GPU内存来源)。
目前主流的方法为 Tensor Parallelism,Data Parallelism,如下图:
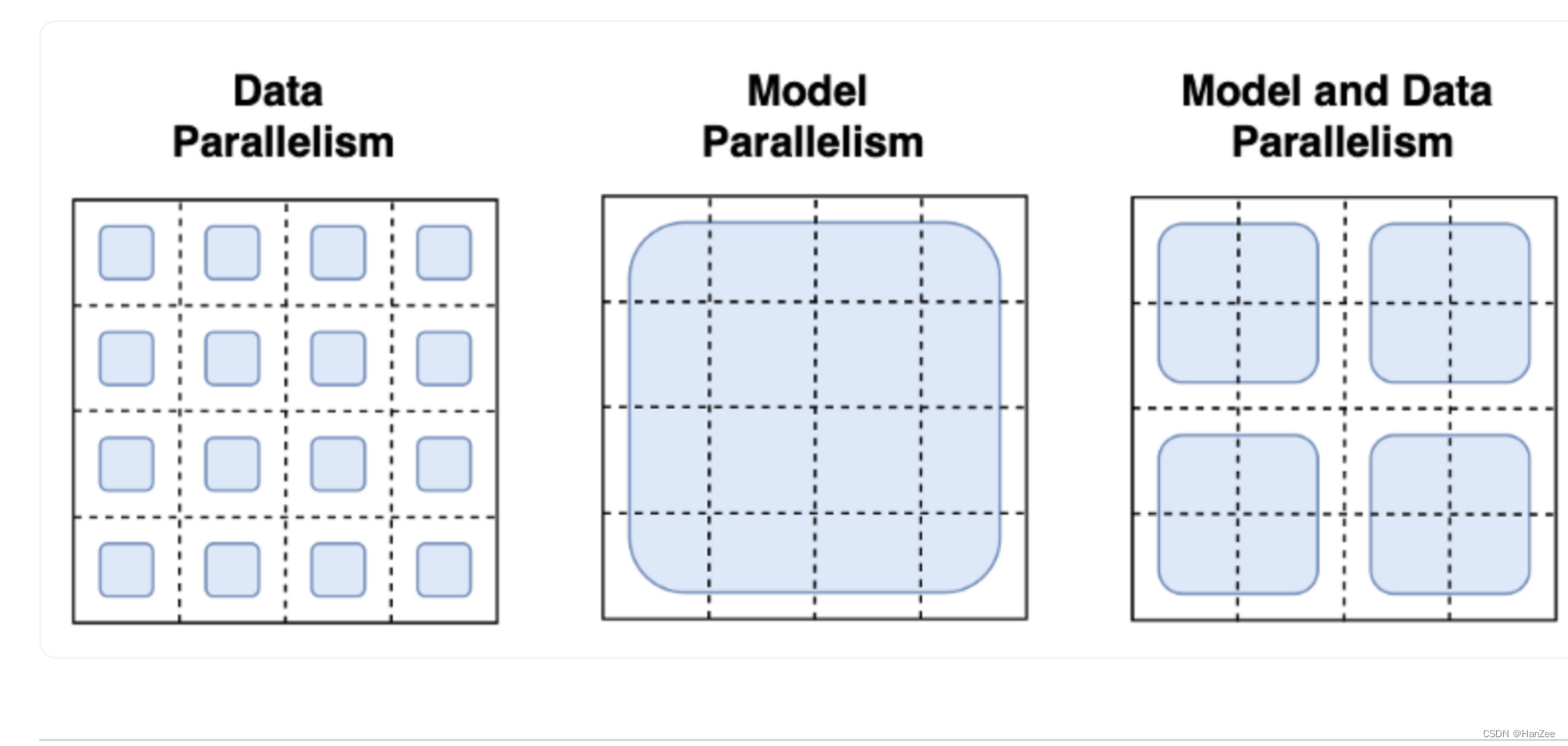
数据并行是指我在每一个GPU上都拷贝一个模型,然后对每个GPU送入不同的数据,但是作者表明他没有根本的解决上面问题。
模型并行是指把模型跨许多设备分割模型权重,这需要定义跨进程的激活和梯度的通信协议。这是比较困难的,可能需要DeepSpeed等框架。
然后作者提出了一个新的方式:8-bit matrix multiplication。
8-bit matrix multiplication
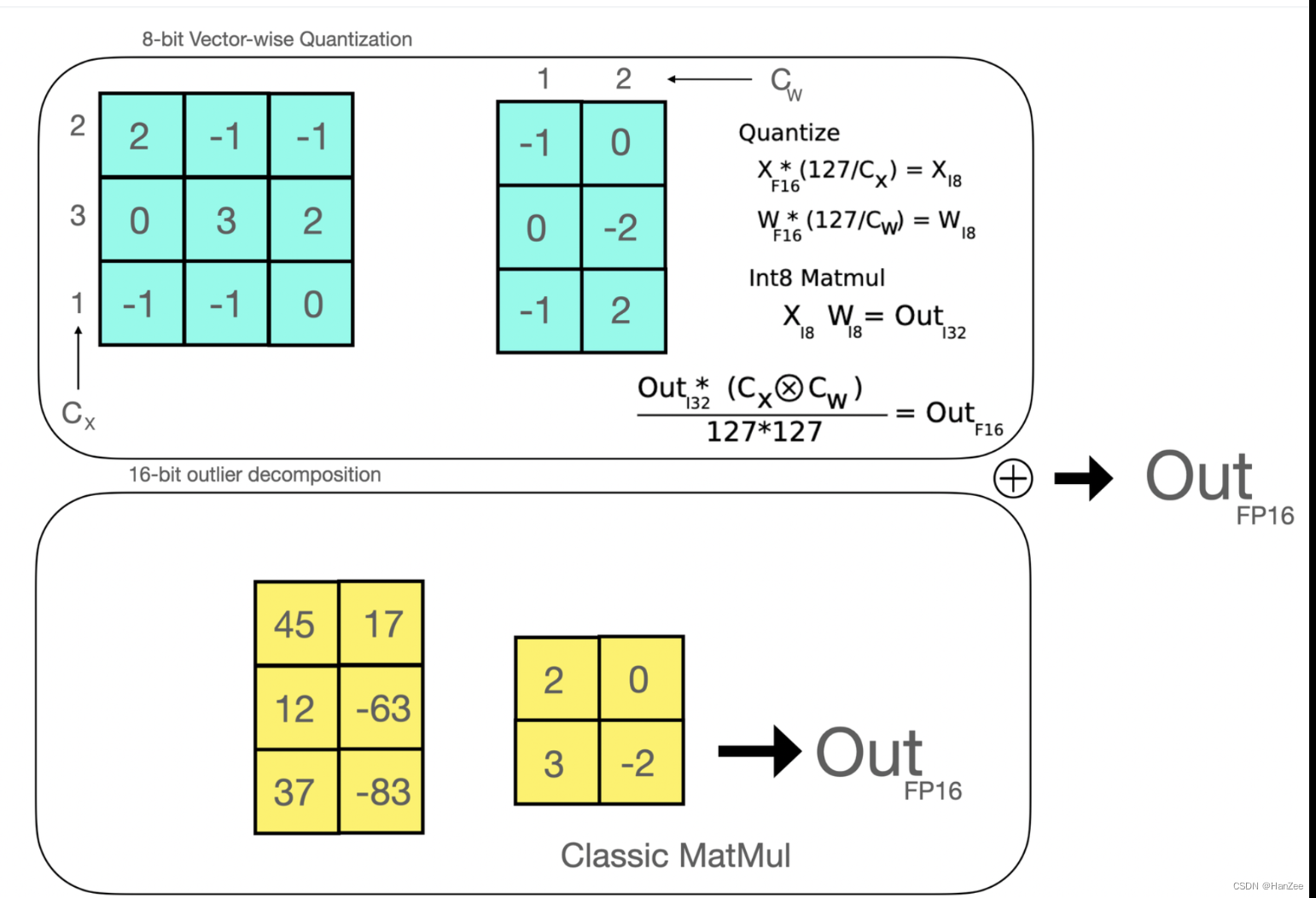
这种方法方法旨在解决量化大规模模型时性能下降的问题。提出的方法将线性层中应用的矩阵乘法分解为两个阶段:将在float16中执行的离群值隐藏状态部分和在int8中执行的“非离群值”部分。
Lora
https://blog.csdn.net/qq_18555105/article/details/129901193?spm=1001.2014.3001.5502
What is PEFT?
Parameter- Efficient Fine-Tuning(PEFT)是一个huggingface的library。
该库支持许多最先进的模型,并拥有广泛的示例集,包括:

Fine-tuning 20B parameter models with Low Rank Adapter
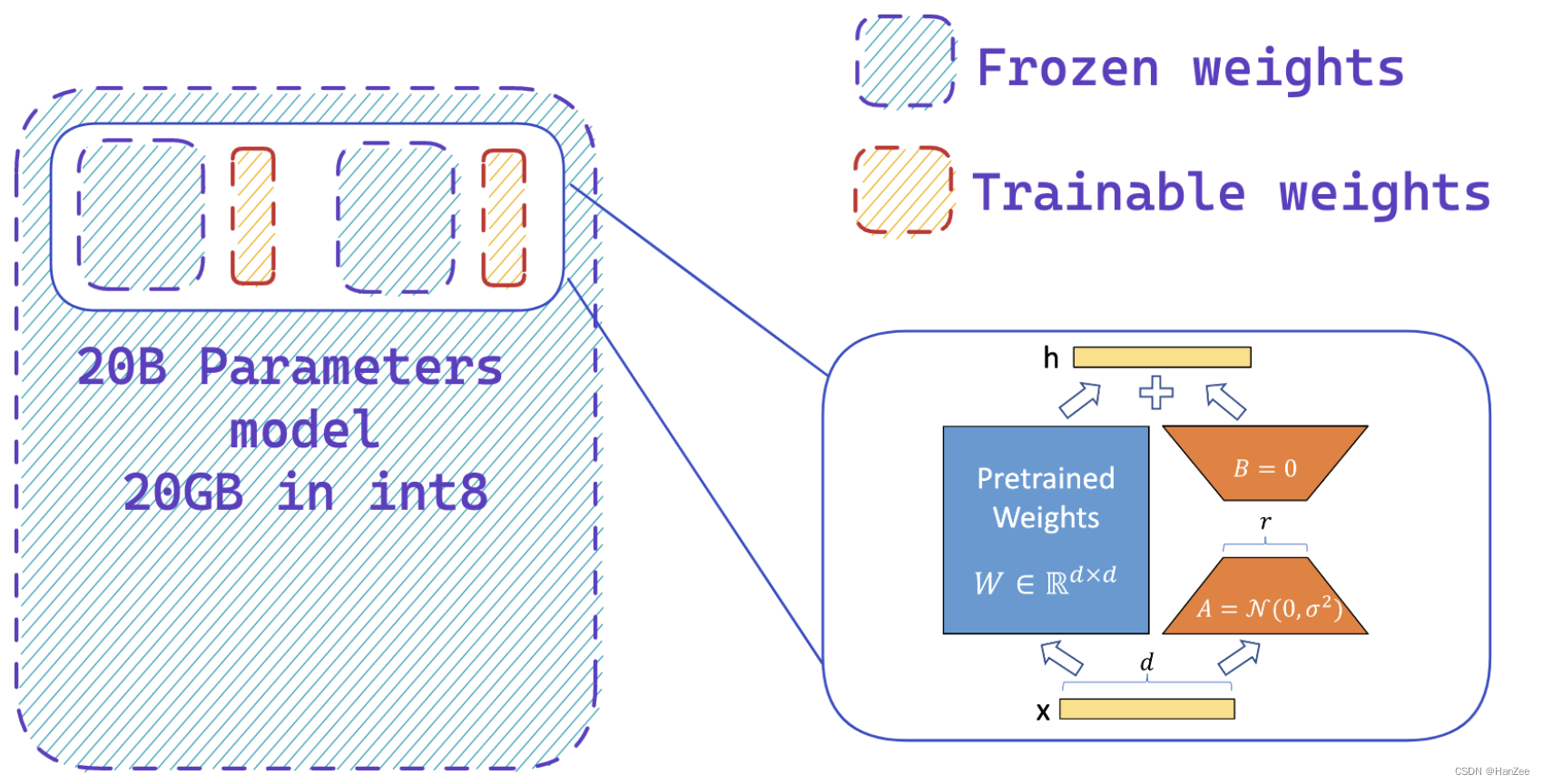
- 第一步:加载active model 以int8的精度。(与全精度模型相比,以8位精度加载模型可以节省多达4倍的内存)
- 第二步:冻结LLM参数,增加可训练的层,也就是Lora。
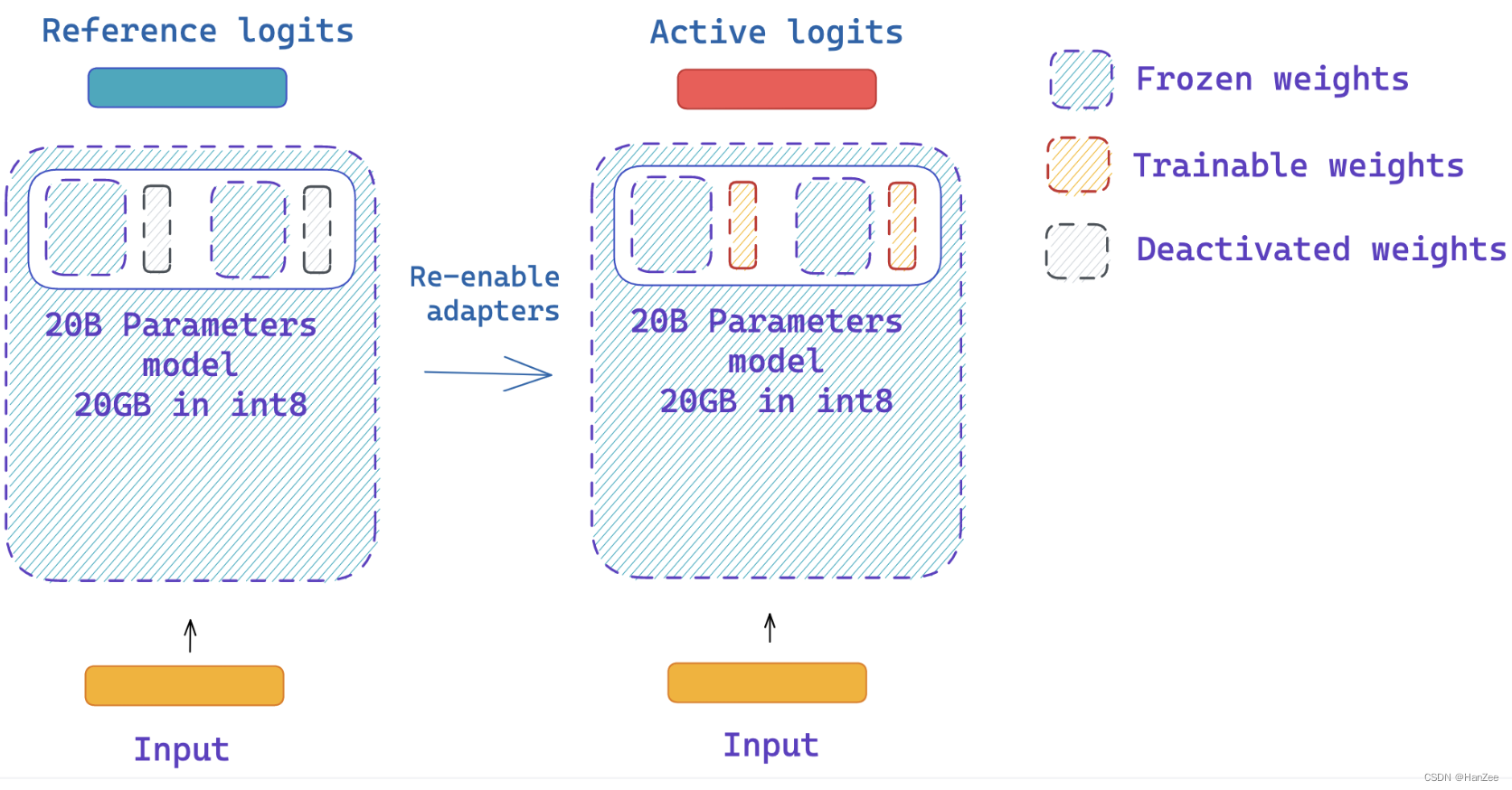
3. 第三步:使用相同的模型获取 reference and active logits
如下图,这里Reference logits作为奖励模型,获得得分,与InstructGPT不同(一个GPT3,一个6B的),作者是用了两个相同的模型,只不过reference model 去掉了adapter。
参考
https://huggingface.co/blog/trl-peft
parallelism paradigms: https://huggingface.co/docs/transformers/v4.17.0/en/parallelism
8-bit integration in transformers: https://huggingface.co/blog/hf-bitsandbytes-integration
LLM.int8 paper: https://arxiv.org/abs/2208.07339
Gradient checkpoiting explained: https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-activation-checkpointing.html