在2017年左右,深度强化学习(Deep Reinforcement Learning)逐渐兴起并引起广泛关注。特别是在2017年6月,OpenAI与Google DeepMind联合推出了一项名为《Deep Reinforcement Learning from Human Preferences》(RLHF)的研究项目,该项目基于人类偏好进行深度强化学习。这项研究旨在解决深度强化学习中一个重要的挑战,即如何有效地设计奖励函数来引导智能体的学习过程。传统的强化学习方法通常使用手工设计的奖励函数,但这种方法往往难以捕捉到复杂任务中的细微差别和人类的偏好。
论文链接:https://arxiv.org/pdf/1706.03741
RLHF提出了一种全新的方法,利用人类偏好来训练深度强化学习模型。在这个方法中,人类参与者被要求观看智能体在执行任务时的表现,并根据他们的偏好进行选择。这些选择被用作奖励信号,用于训练深度强化学习模型。RLHF可以使智能体更好地学习任务的目标和优先级。这种方法不仅能够提高强化学习模型的性能,还能够使模型的行为更加符合人类的期望和偏好。
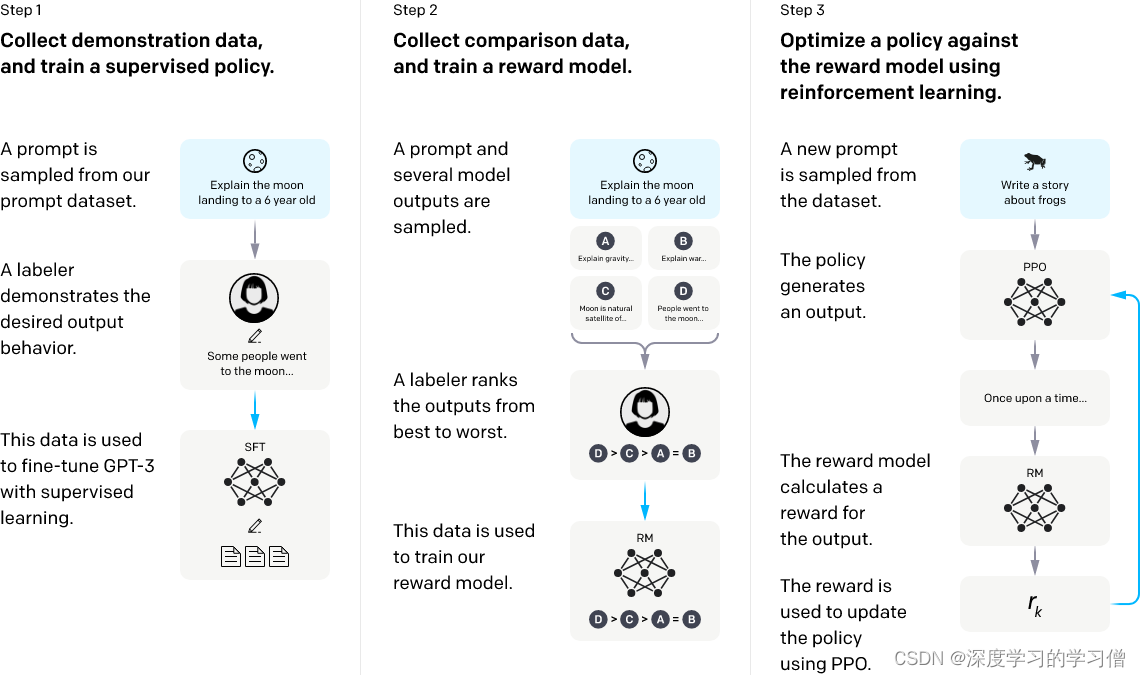
- 在Zieglar等人(2019年)的论文《Fine-Tuning Language Models from Human Preferences》中,他们介绍了一种使用人类参与的方法来训练奖励模型。在这个方法中,人类标注者会对由策略模型生成的文本进行选择,比如在四个答案选项(y0、y1、y2、y3)中选择一个最好的作为奖励模型的标签。通过这种方式,奖励模型可以学习到更准确的文本评估准则,并指导策略模型的训练。
论文链接:https://arxiv.org/pdf/1909.08593
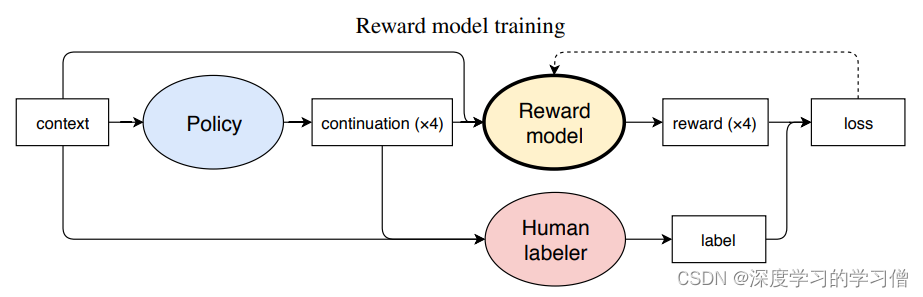
-
而在Stiennon等人(2020年)的论文《Learning to summarize with human feedback》中,OpenAI团队提出了一种类似于instructGPT和ChatGPT的训练模式。在这种模式下,人类标注者通过与模型交互,向模型提供反馈和指导,帮助模型学习如何进行摘要生成任务。通过与人类标注者的互动,模型可以逐步优化自身的生成能力,并生成更加准确和合理的摘要。
论文链接:https://arxiv.org/pdf/2009.01325
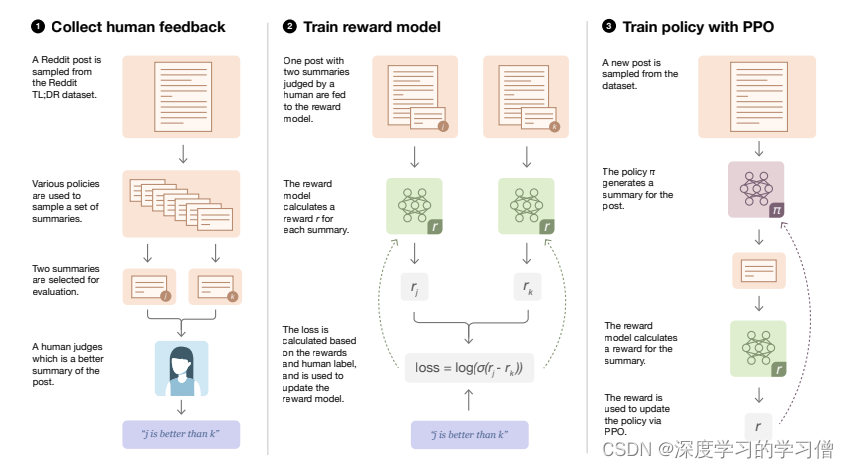
论文中提到三个关键步骤来微调监督模型并训练奖励函数。 -
根据人工标注数据微调监督模型:在预训练语言模型后,使用人工标注的数据来微调模型以适应特定任务。通过将任务相关的数据输入模型,并通过反向传播算法调整模型参数,使其更好地适应任务要求。这个过程类似于传统的监督学习,其中人工标注数据被用作训练样本,目标是优化模型的性能。
-
训练一个奖励函数:在传统的强化学习中,奖励函数通常由人工设计。然而,在这种情况下,训练一个奖励函数来代替人工设计的奖励函数。这个奖励函数的目的是根据任务的目标,给出对生成文本的评估。通过使用高质量标注数据训练奖励函数,我们可以让模型在生成文本时更好地符合任务的要求。
-
使用PPO优化模型的策略:PPO(Proximal Policy Optimization)是一种用于优化策略的算法。在这里,我们使用PPO算法来更新模型的策略,以最大化奖励函数的预期值。此外,为了避免奖励模型过于绝对,还添加了一个惩罚项来平衡奖励函数。(后续会专门写一个关于强化学习的博客,会详细介绍这部分内容。请耐心等待!)
这些论文都探索了利用人类参与来指导和改善语言模型的训练过程。通过结合人类的专业知识和判断力,可以提供更准确的标签和反馈,从而改善模型的生成能力和表现。这种人类参与的训练方法为语言模型的发展和进步提供了一种有益的途径。
相关知识正在学习,未完待续!预计一两天后完成