参考:
【快速理解张量】通过torch.rand和举例通俗解释张量tensor_Neo很努力的博客-CSDN博客
Pytorch官方文档学习笔记 —— 3. Build Model_pytorch build_model_Coding_Qi的博客-CSDN博客
Quickstart — PyTorch Tutorials 2.0.1+cu117 documentation (2条消息) pytorch基础-优化模型参数(6)_torch.optim.sgd(model.parameters(), lr=learning_ra_一只小小的土拨鼠的博客-CSDN博客
一、Tensor张量
-数据结构(类似数组矩阵)——使用张量对模型的输入、输出、参数进行编码
-最后一列 -1

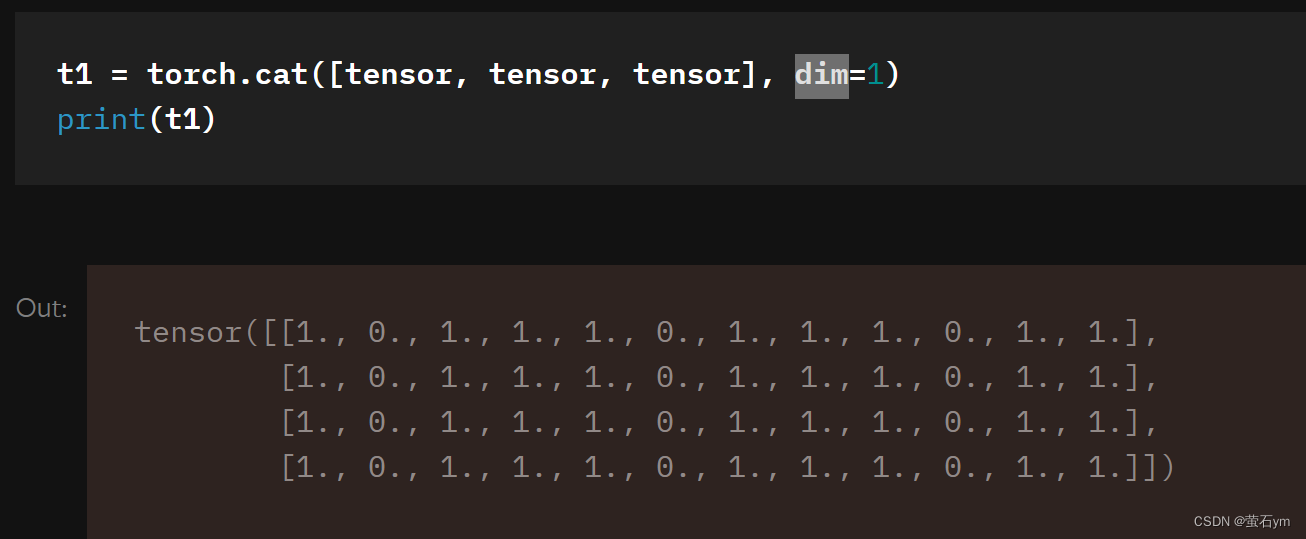
-连接张量,.cat
dim是指维度,没有中括号,dim=0; 1个中括号,dim=1;
-matplotlib是Python的2D绘图库
二、数据集和数据加载器
figure:特征;Lable:标签;
&自定义数据集:三个函数
_init_:在实例化数据集对象时运行一次,初始化图像、注释文件、两个转换(transform、target_transform)
_len_:返回数据集中的样本数
_getitem_:从给定索引处,将图像标签转换为张量,并返回张量图像和相应的标签
三、变换
transform和target_transform
特征作为规范化张量,标签作为one-hot独热编码张量,使用.ToTensor和Lambda进行转换
transform=ToTensor(),
target_transform=Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(0, torch.tensor(y), value=1))&ToTensor将 PIL 图像或 NumPy 转换为 a. 这样的形势,并且图像的像素强度值在 [0., 1.] 范围内
&Lambda转换:是一个Lambda函数,将整数转换为独热编码张量,
自然状态码为:000,001,010,011,100,101
独热编码为:000001,000010,000100,001000,010000,100000
target_transform = Lambda(lambda y: torch.zeros(
10, dtype=torch.float).scatter_(dim=0, index=torch.tensor(y), value=1))
首先创建一个大小为 10(我们数据集中的标签数量)的零张量,并调用 scatter_ 在标签给出的索引上分配一个
scatter_(input, dim, index, src):将src中数据根据index中的索引按照dim的方向填进input。可以理解成放置元素或者修改元素
- dim:沿着哪个维度进行索引
- index:用来 scatter 的元素索引
- src:用来 scatter 的源元素,可以是一个标量或一个张量
四、构建模型
-通过子类化nn.Module定义神经网络,用__init__来初始化神经网络层,每个nn.Module子类实现对forward方法中输入数据的操作
-Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。(3,32,64)是个三维数据,总共有3*32*64=6144个元素,将这个三维数据拉成一行,该行长度就是6144。
-nn.Sequential 类是 torch.nn 中的一种序列容器,通过在容器中嵌套各种实现神经网络中具体功能相关的类,来完成对神经网络模型的搭建;该类括号内的内容就是我们搭建的神经网络模型的具体结构
-nn.Linear:用于定义模型的线性层,完成前面提到的线性转换,参数有(输入特征数,输出特征数、是否使用偏置(默认为true)),会自动生成对应维度的权重参数和偏置
-nn.ReLU 类属于非线性激活分类,在定义时默认不需要传入参数。
-logits 就是一个向量,下一步通常被投给 softmax 的向量。softmax归一化指数函数
-torch.rand的作用通俗来说就是产生均匀分布的数据,torch.rand()括号里面输入几个数那就是生成几维张量
x = torch.rand(3,4):2维张量,三行四列
理解三维张量也相对容易,二维张量可以看作一个平面,而三维张量就可以看作很多个二维张量平面两两平行摆放。
例如我们常见的RGB图像就可以理解为3个二维灰度图像并排摆放。
五、Autograd自动求导
梯度:损失函数对参数的导数
反向传播算法:参数(模型权重)根据损失函数相对于给定参数的梯度进行调整。
torch.autograd 支持任何计算图的梯度自动计算。
六、Optimization优化参数
-在每次训练模型迭代过程中,模型对输出进行猜测,计算猜测和实际标签的误差,收集误差关于其参数的导数,并使用梯度下降优化这些参数
-通过调整超参数来控制模型优化过程。不同的超参数值会影响模型训练和收敛速度
-损失:使用给定数据样本的输入进行预测,并将其与真实数据标签值进行比较。
-SGD 优化器
-训练循环,三个步骤进行优化
·调用 optimizer.zero_grad() 来重置模型参数的梯度。默认情况下渐变加起来;为了防止重复计算,我们在每次迭代时明确地将它们归零。
·通过调用 loss.backward() 对预测损失进行反向传播。PyTorch将与损失有关的每个参数的梯度储存起来。
·一旦我们有了梯度,我们调用 optimizer.step() 来通过反向传播中收集的梯度来调整参数。
训练循环优化代码:
def train_loop(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
for batch, (X, y) in enumerate(dataloader):
# Compute prediction and loss
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad() #用于清空优化器中的梯度
loss.backward() #计算损失函数对参数的梯度,自动求导
optimizer.step() #根据梯度更新网络参数的值
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
使用梯度下降算法来更新模型参数,在该算法中,需要计算损失函数关于模型参数的梯度,这个计算过程就是反向传播算法
loss.backward() 的作用是对损失函数进行求导,得到每个模型参数关于损失函数的梯度。这个梯度可以表示模型参数在当前状态下对损失函数的贡献大小和方向,即参数更新的方向和大小。
更新后的参数将被用于下一次的前向传递计算和反向传播计算
七、Save & Load Model保存和加载模型
PyTorch 模型将学习到的参数存储在称为 state_dict 的内部状态字典中。 这些参数可以通过 torch.save 方法保存起来