文章目录
- Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation(ECCV2018)
- Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning(2016)
- Wide Residual Networks(2017)
- mixup: Beyond Empirical Risk Minimization(ICLR2018)
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
- Pyramid Scene Parsing Network(2017)
- Searching for MobileNetV3(2019)
- SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size(2016)
- Identity Mappings in Deep Residual Networks(2016)
- Aggregated Residual Transformations for Deep Neural Networks
- MLP-Mixer: An all-MLP Architecture for Vision(2021)
- MOCO:Momentum Contrast for Unsupervised Visual Representation Learning
- A ConvNet for the 2020s
- MAE:Masked Autoencoders Are Scalable Vision Learners
- Xception: Deep Learning with Depthwise Separable Convolutions
- CLIP:Learning Transferable Visual Models From Natural Language Supervision
- ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
- ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
- ResNeSt: Split-Attention Networks
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation(ECCV2018)
方法
代码地址
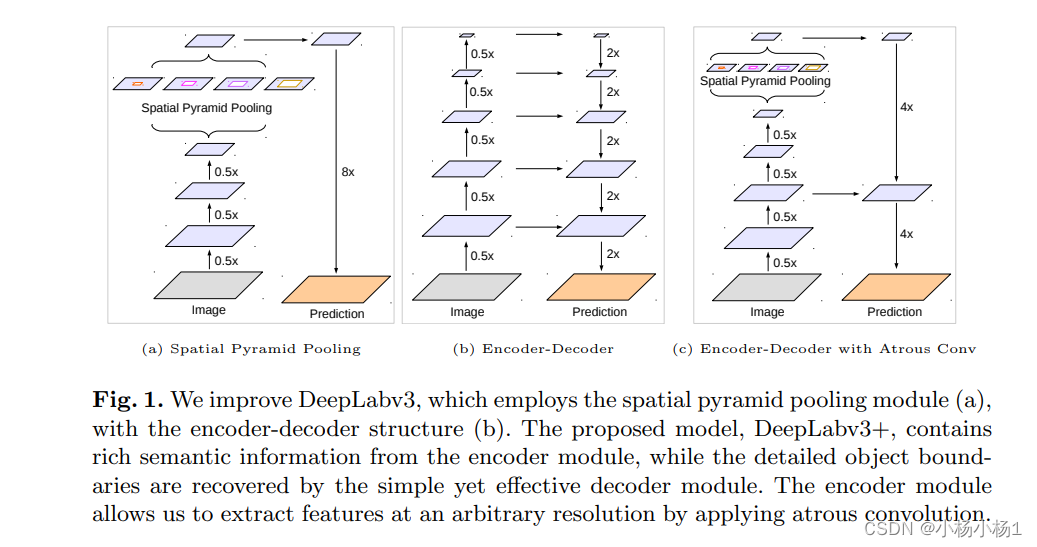
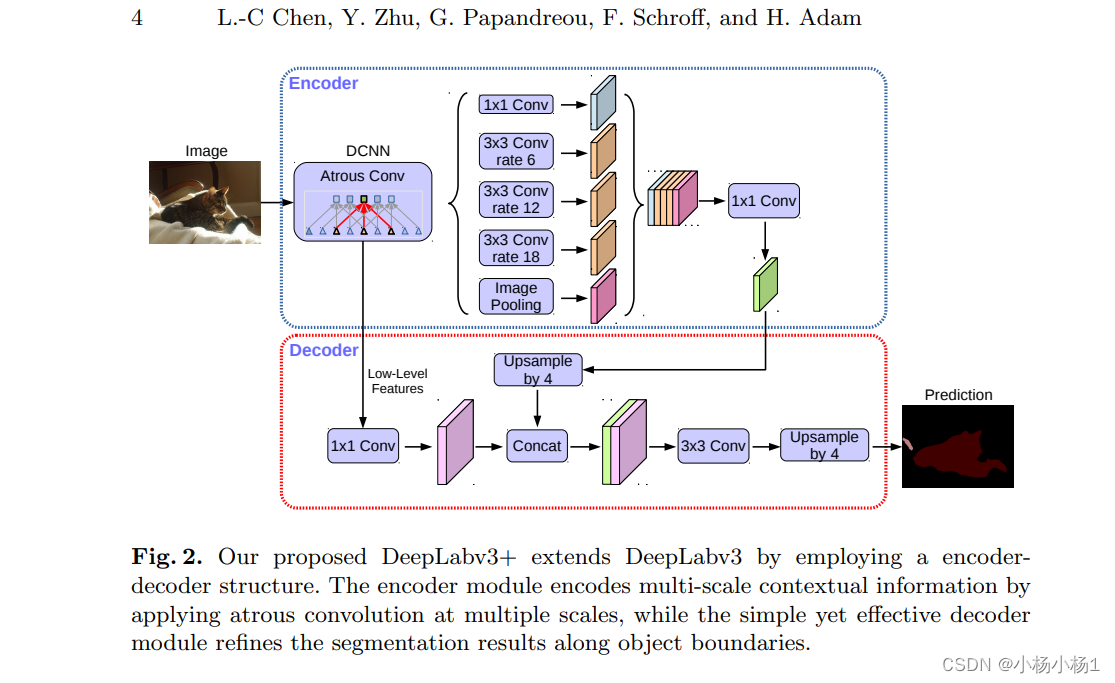
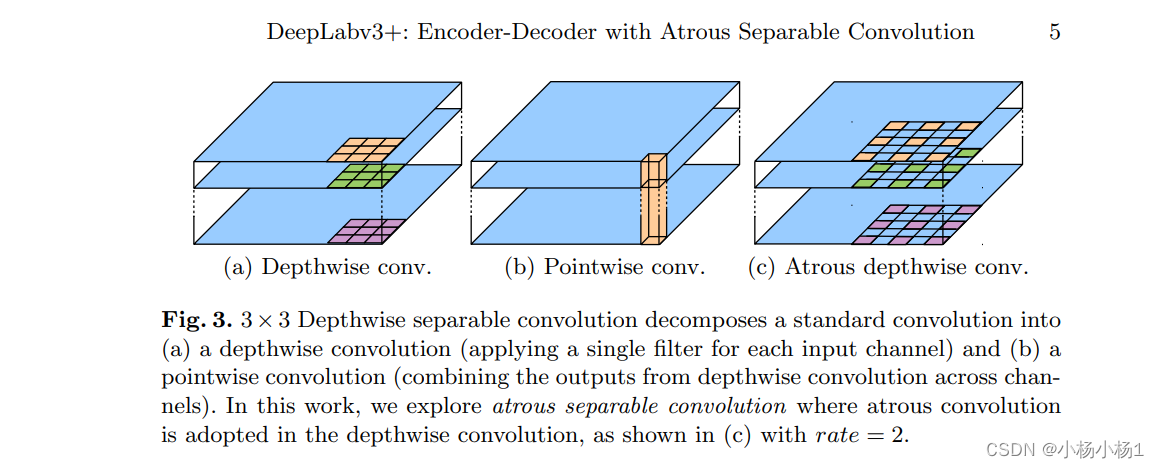
DeepLabV3+结构
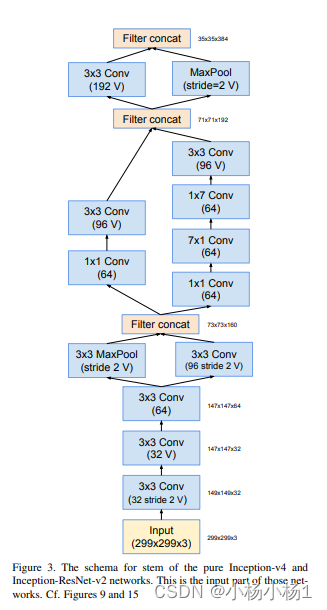
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning(2016)
方法
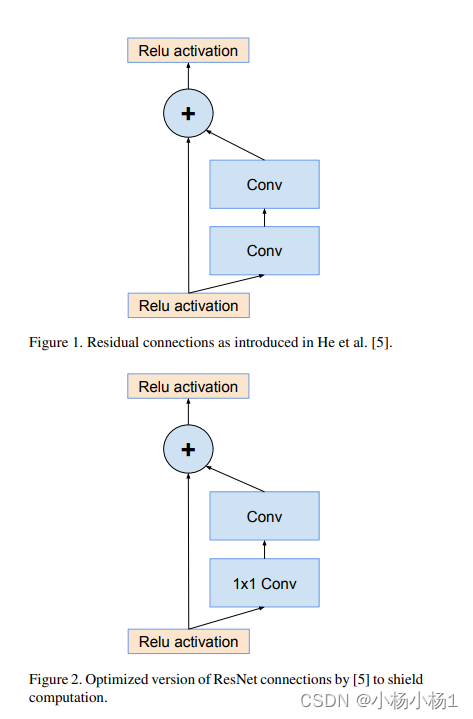
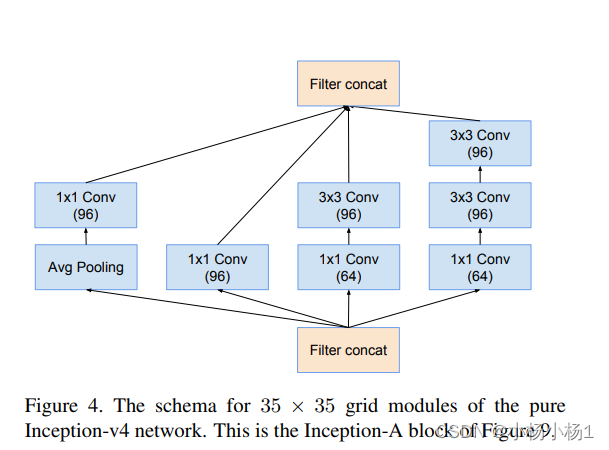
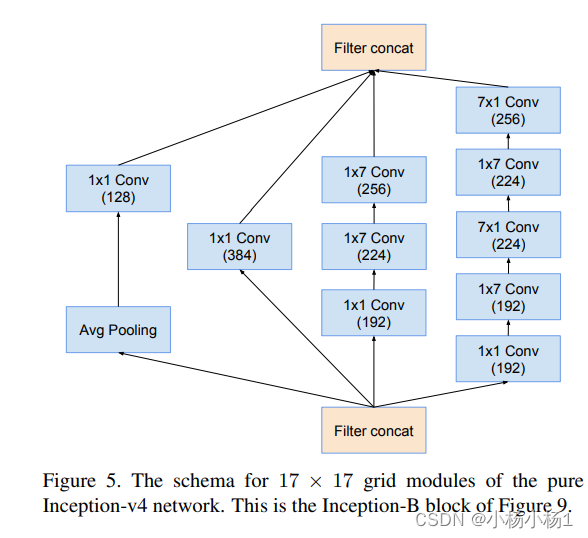
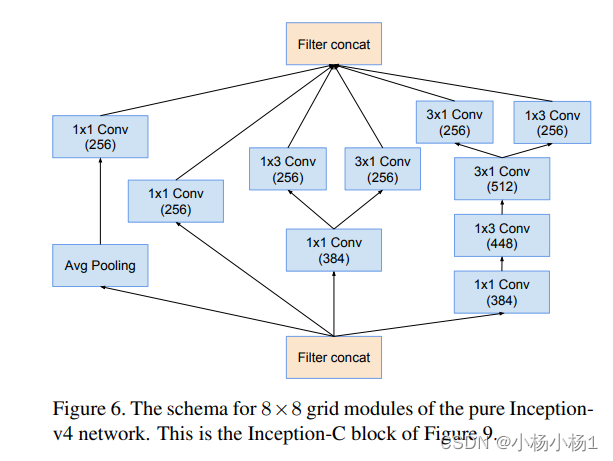

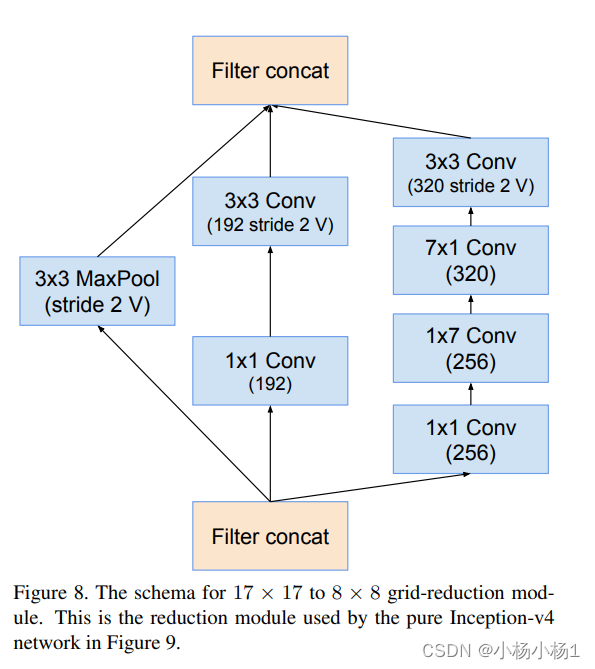
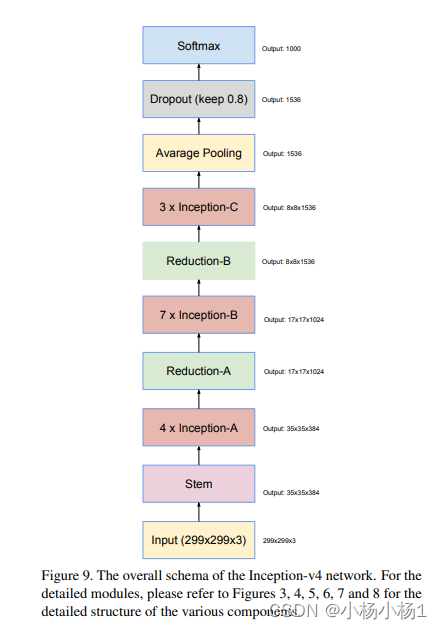
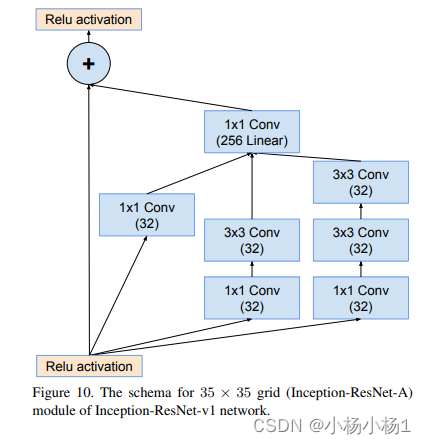
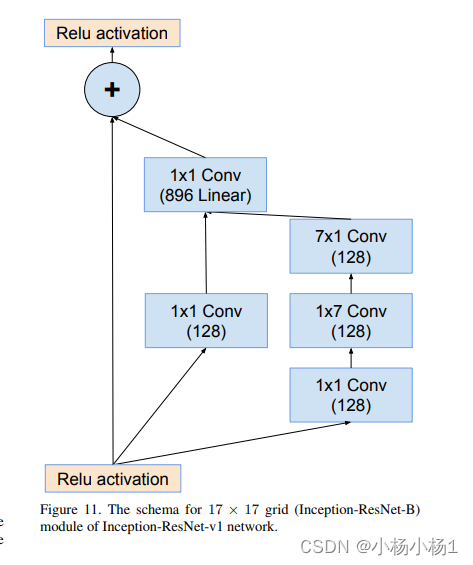
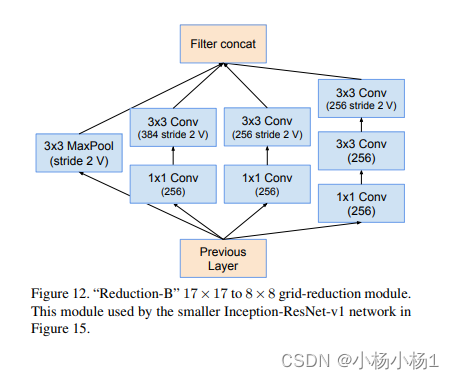
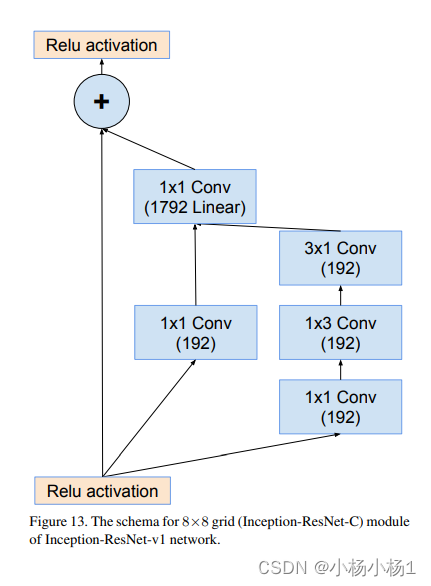

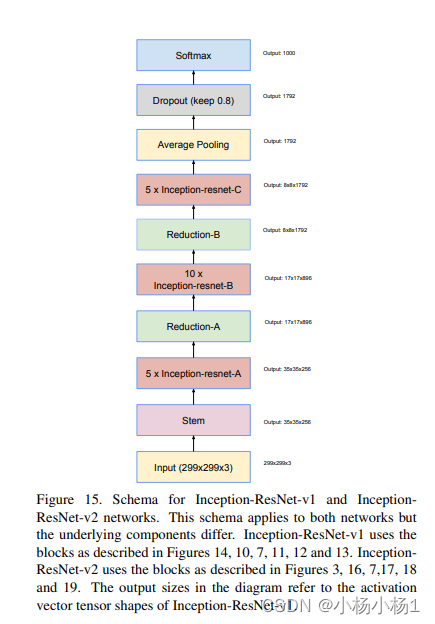
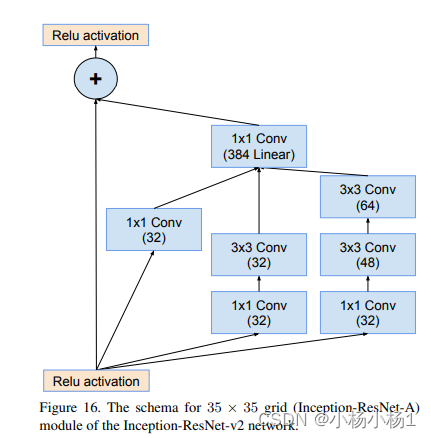
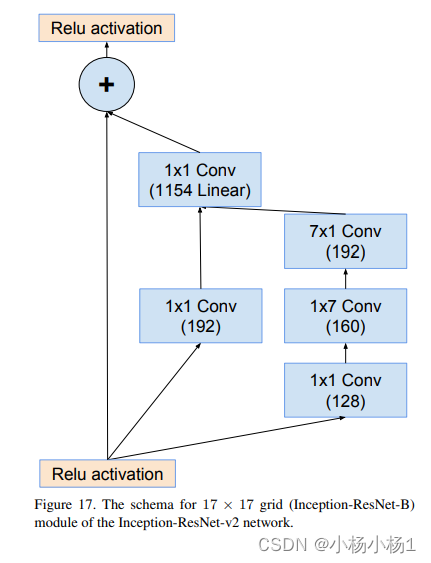
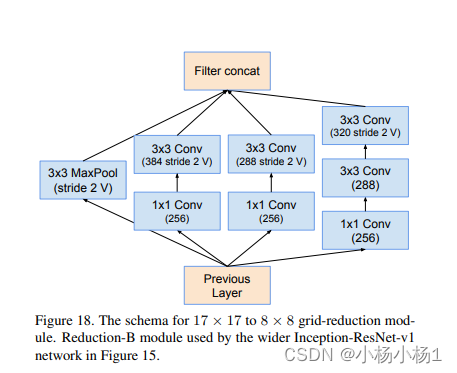
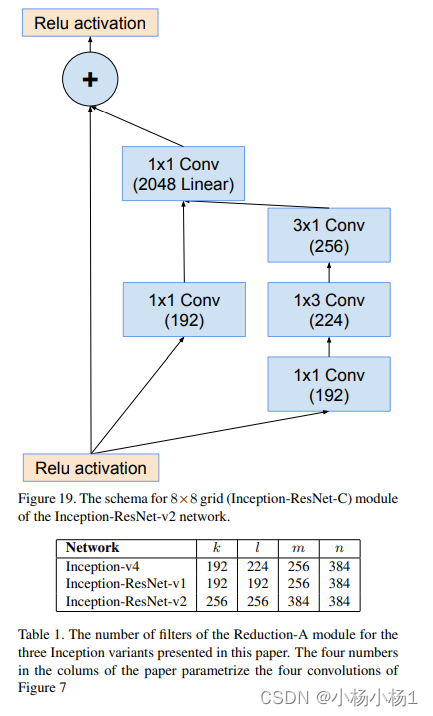
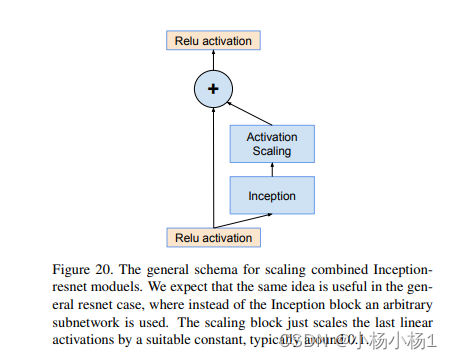
Wide Residual Networks(2017)
方法
代码地址
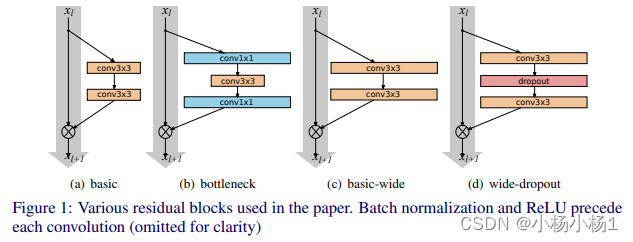
我感觉是没啥变化
mixup: Beyond Empirical Risk Minimization(ICLR2018)
方法

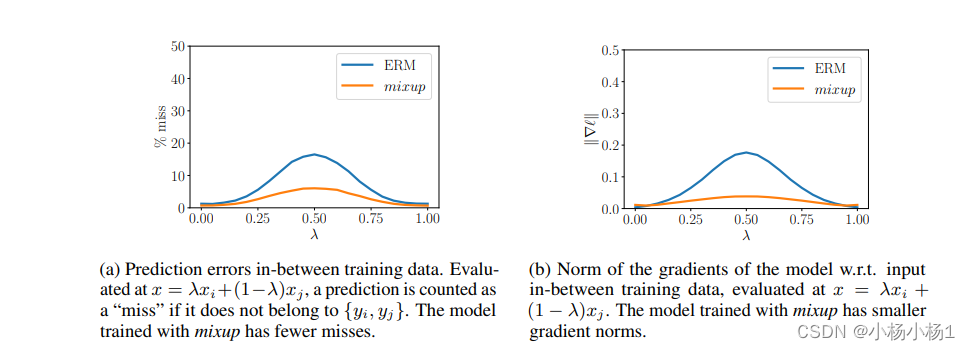
主要看代码里面得lam和alpha
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
方法
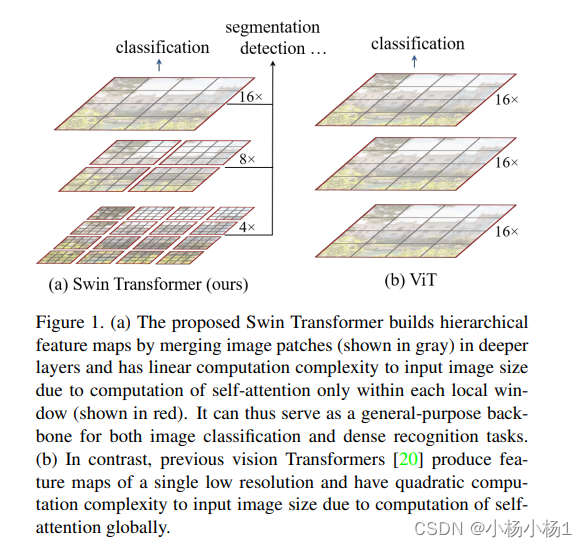
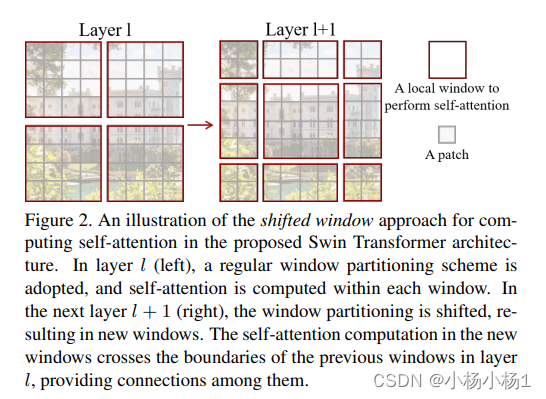
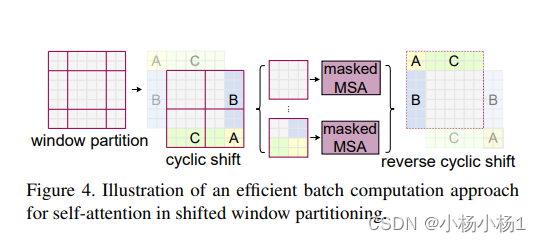
Vit的滑动窗口版本
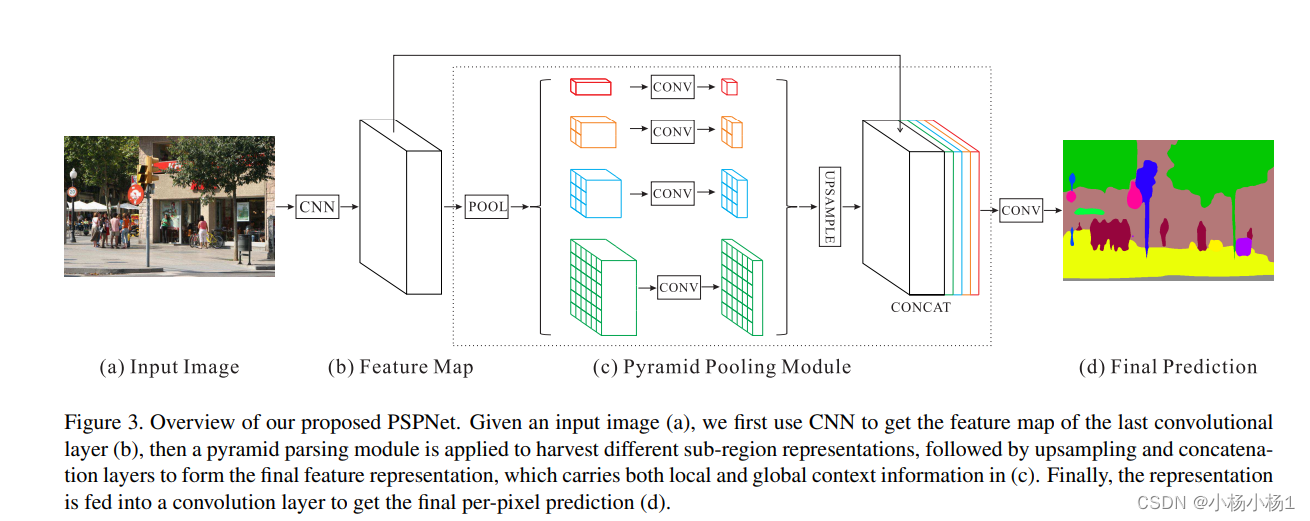
Pyramid Scene Parsing Network(2017)
Searching for MobileNetV3(2019)
方法
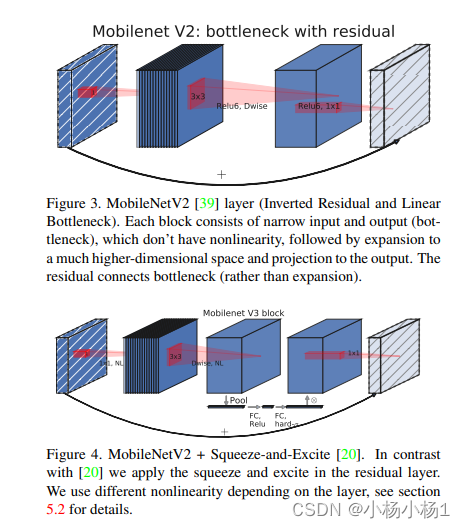
这是一篇关于网络架构搜索的文章
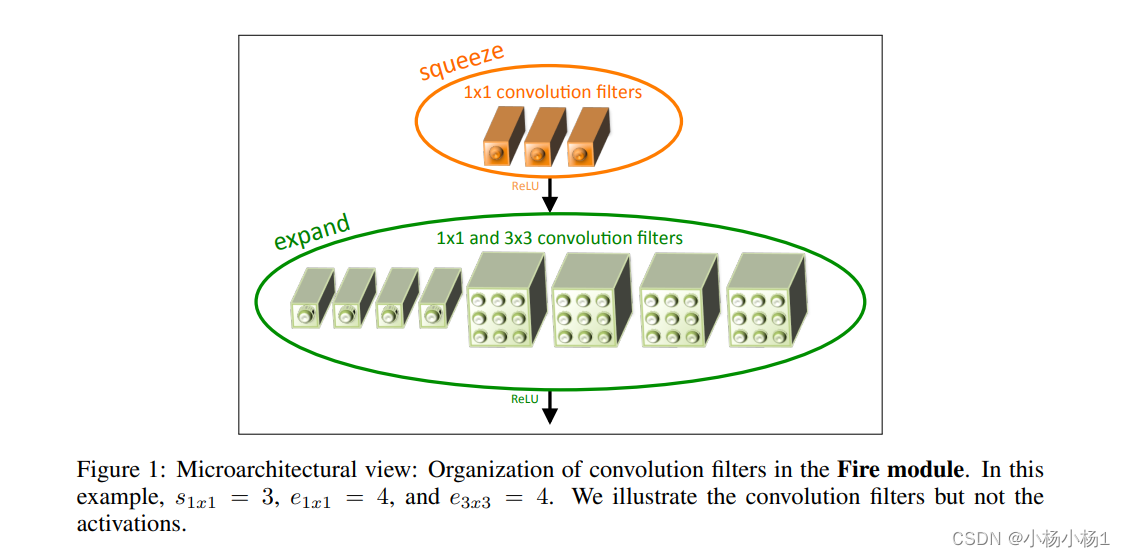
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size(2016)
方法
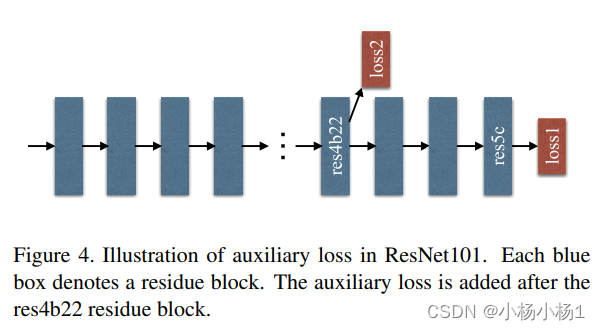
Identity Mappings in Deep Residual Networks(2016)
方法
讲了各种各样的跳跃连接分析
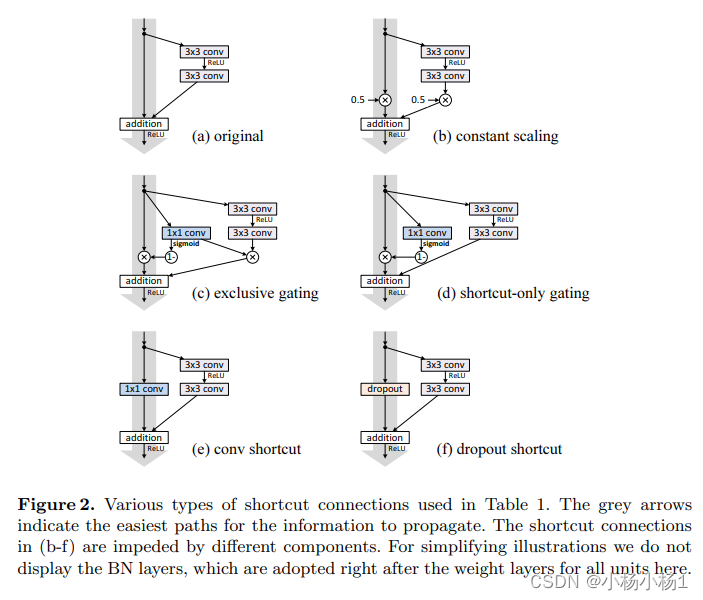
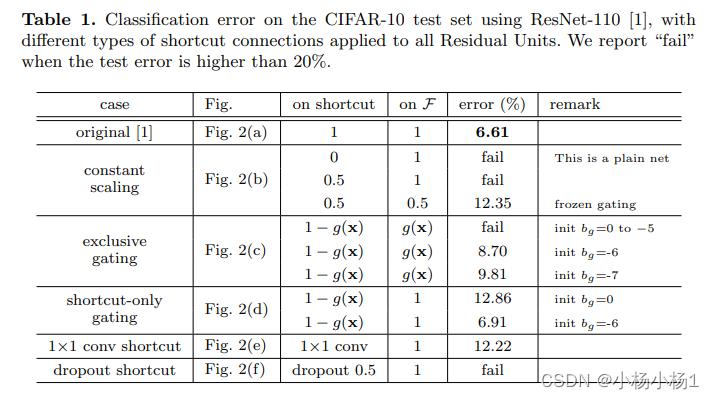
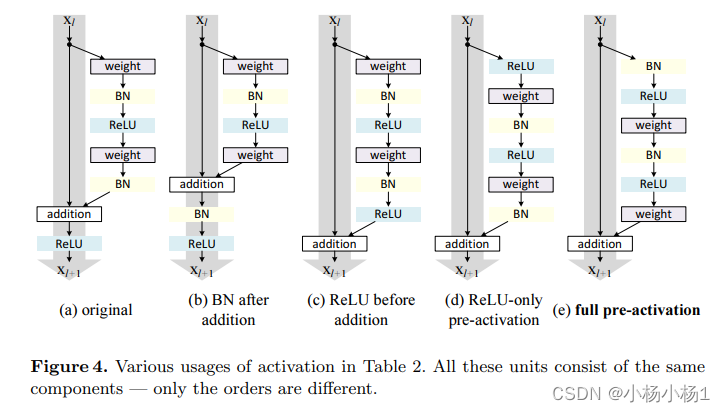
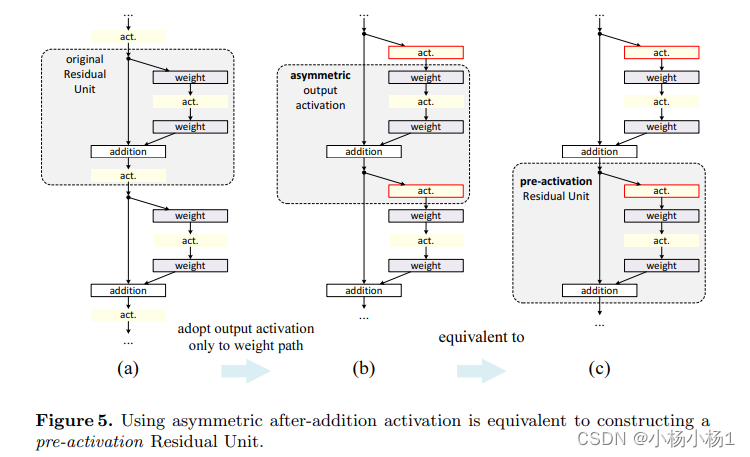
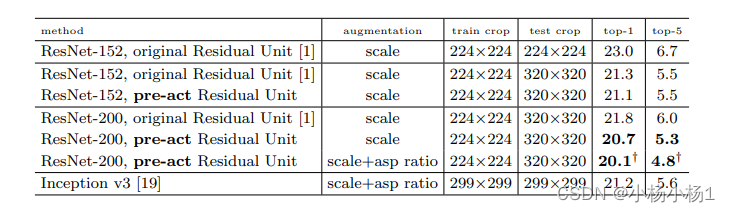
Aggregated Residual Transformations for Deep Neural Networks
方法
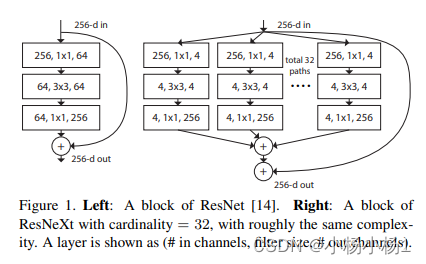
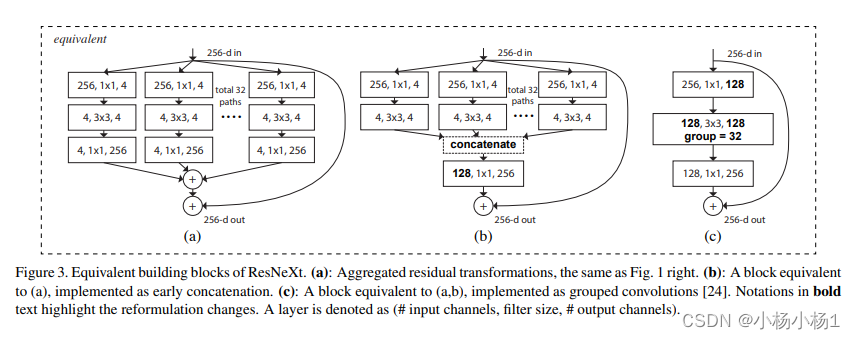
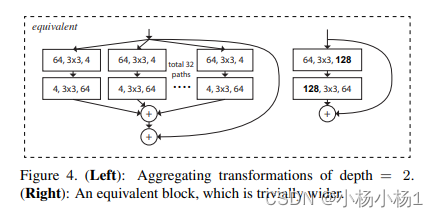
相当于就是参数减少
MLP-Mixer: An all-MLP Architecture for Vision(2021)
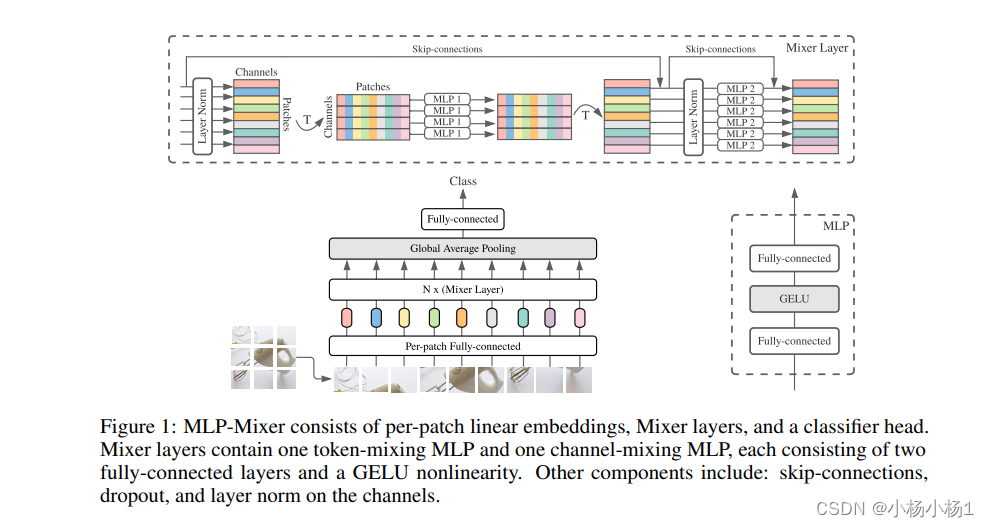
token混合和channel混合
MOCO:Momentum Contrast for Unsupervised Visual Representation Learning
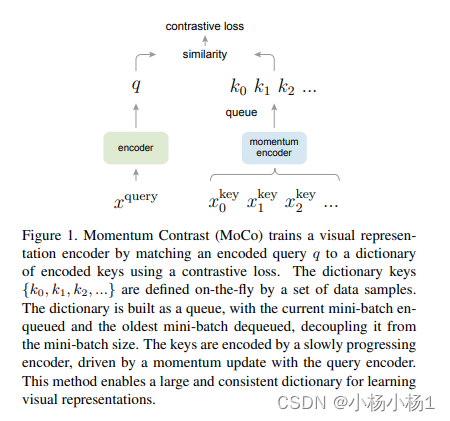
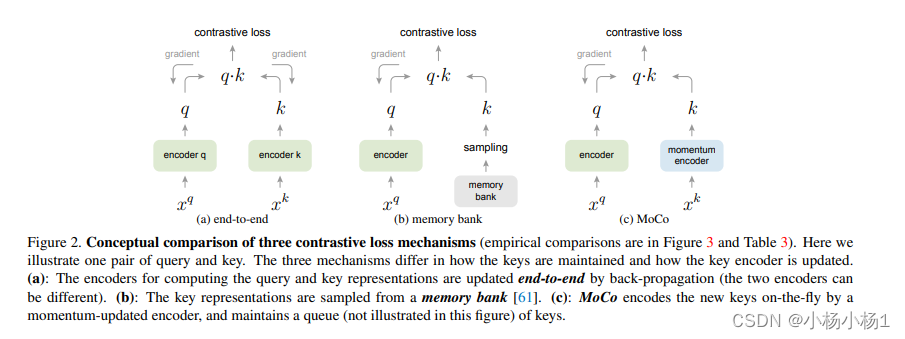
采用不同存储结构,moco采用的是队列
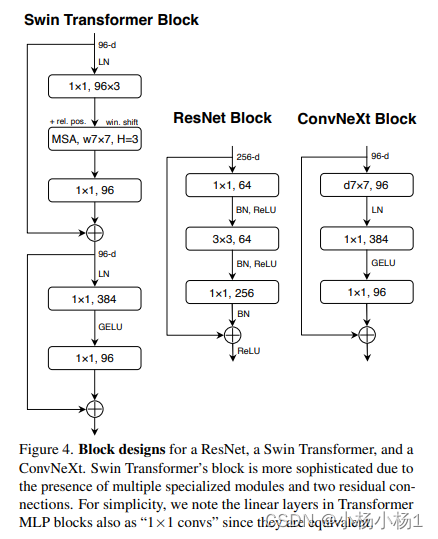
A ConvNet for the 2020s
做到极致的卷积

MAE:Masked Autoencoders Are Scalable Vision Learners
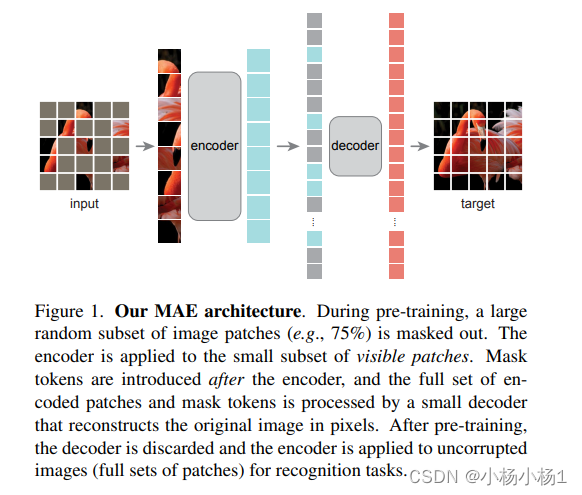
类似于bert,预测mask部分,自监督学习
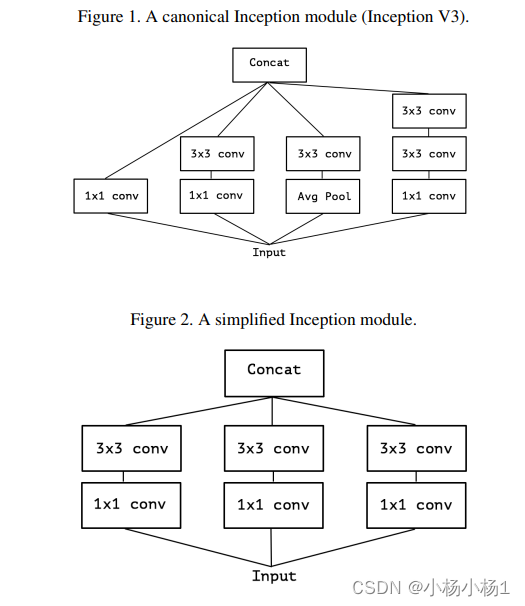
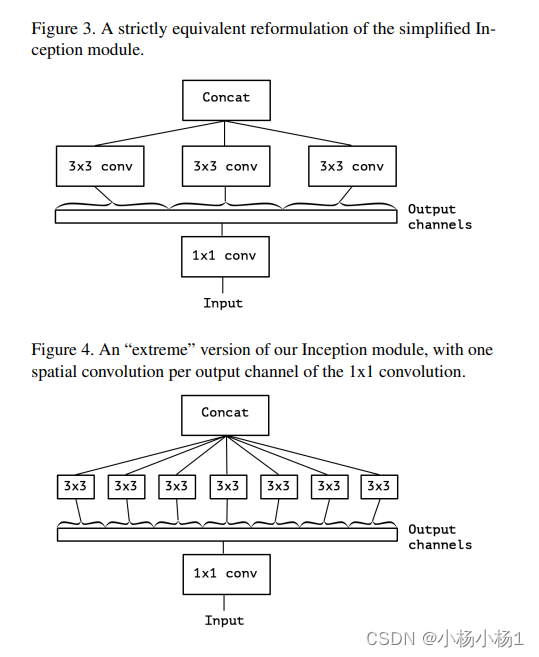
Xception: Deep Learning with Depthwise Separable Convolutions
方法
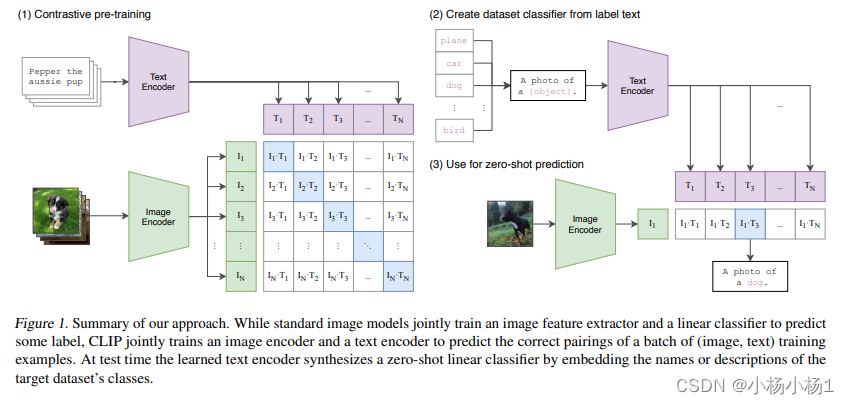
CLIP:Learning Transferable Visual Models From Natural Language Supervision
方法
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
方法
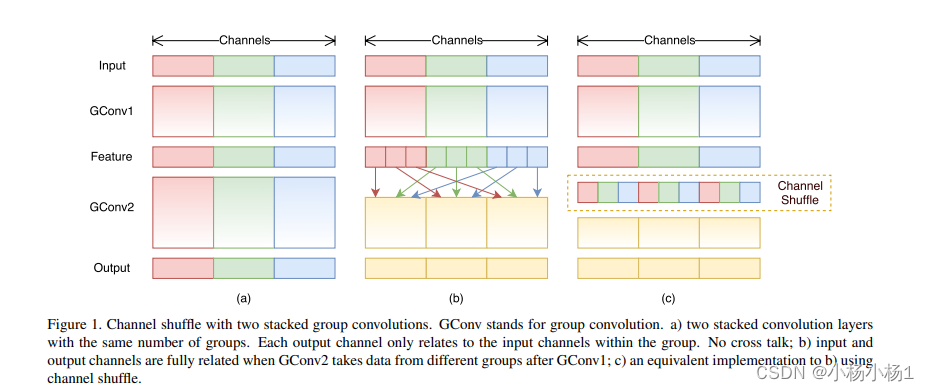
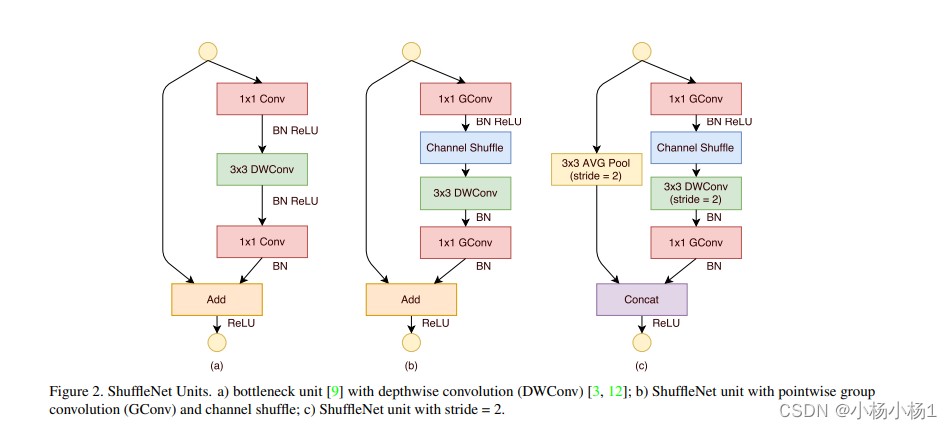
分组卷积并混合
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
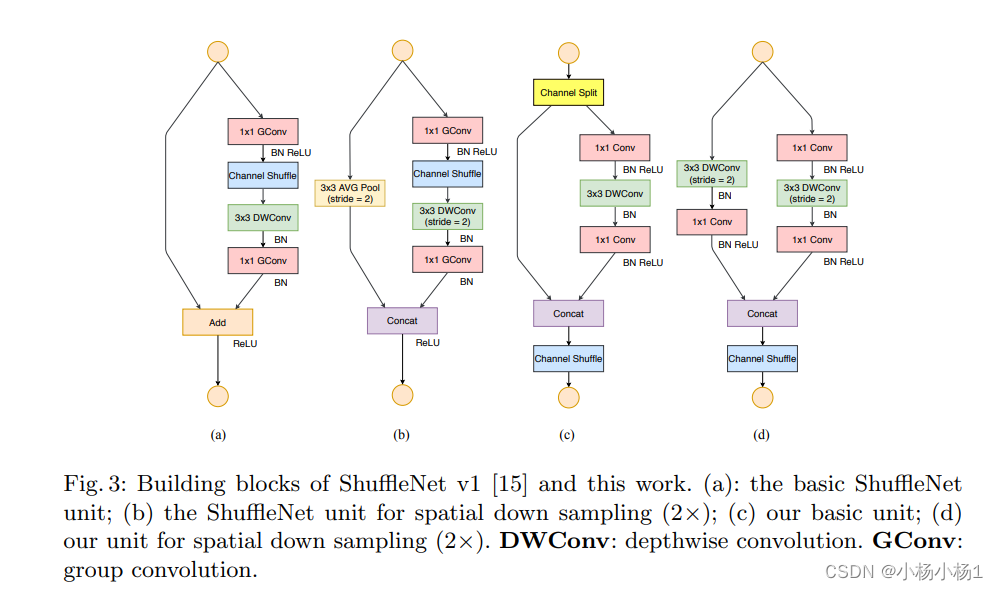
方法
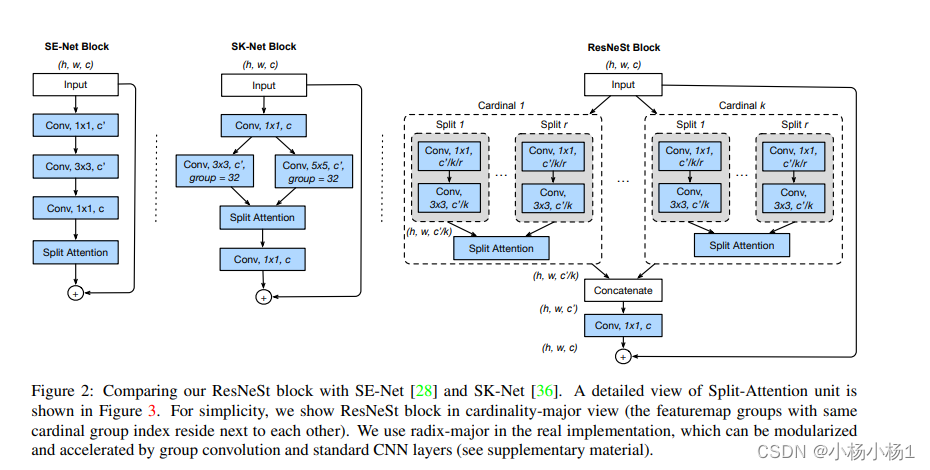
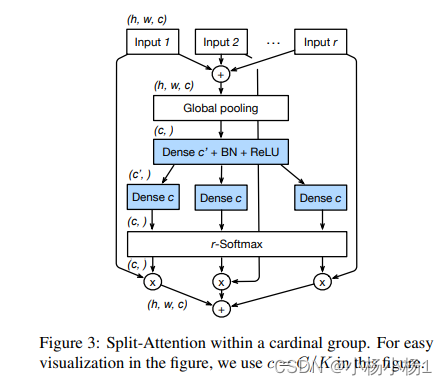
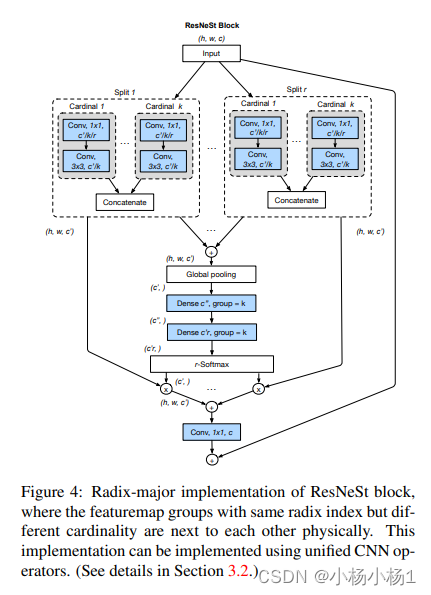
ResNeSt: Split-Attention Networks
本文方法