电影推荐系统
一、项目介绍
项目以某科技公司电影网站真实业务数据架构为基础,基于阿里云ESC服务器,构建了包含了离线推荐与实时推荐体系的电影推荐系统,综合利用了协同过滤算法以及基于内容的推荐方法来提供混合推荐。提供了从前端应用、后台服务、算法设计实现、平台部署等多方位的闭环的业务实现。
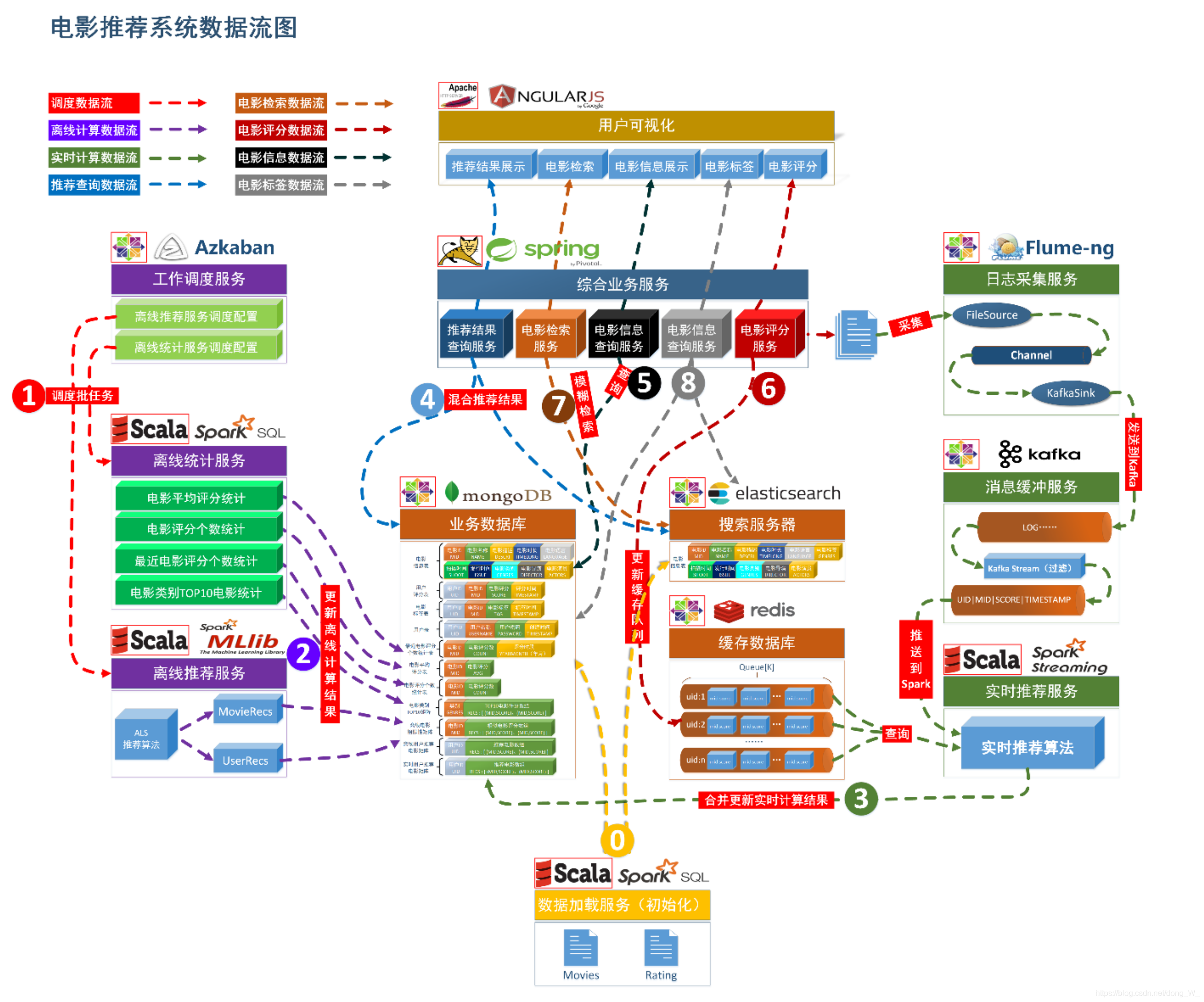
二、项目实现
开发环境:阿里云服务器CentOS6,本地Window 10
使用工具:IDea,Spark 2.3.4, MongoDB 3.4.2, ElasticSearch5.6.2
1. 软件安装
1.1 MongoDB安装
官网下载很慢,阿里云镜像安装
下载以下四个到服务器上 mongodb-org-3.4.3-1.el6.x86_64.rpm,mongodb-org-mongos-3.4.3-1.el6.x86_64.rpm,mongodb-org-server-3.4.3-1.el6.x86_64.rpm,mongodb-org-shell-3.4.3-1.el6.x86_64.rpm,mongodb-org-tools-3.4.3-1.el6.x86_64.rpm)
地址 http://mirrors.aliyun.com/mongodb/yum/redhat/6Server/mongodb-org/3.4/x86_64/RPMS/
wget下载到服务器,
rpm安装 rpm -ivh XXXX.rpm
配置要注意
net:
port: 27017
bindIp: 0.0.0.0 # Listen to local interface only, comment to listen on all interfaces.
1.2 ElasticSearch安装
镜像地址: https://thans.cn/mirror/elasticsearch.html
配置要注意
1)vim /etc/security/limits.conf,文末添加
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
2)vim /etc/security/limits.d/90-nproc.conf,修改
* soft nproc 2048 #将该条目修改成 2048
- vim /etc/sysctl.conf,文件末尾添加
vm.max_map_count=655360
- 执行 sudo sysctl -p
- 解压安装包
- 配置文件 vim ./config/elasticsearch.yml
cluster.name: es-cluster #设置集群的名称
node.name: es-node #修改当前节点的名称
path.data: /home/bigdata/cluster/elasticsearch-5.6.2/data #修改数据路径,路径要提前创建
path.logs: /home/bigdata/cluster/elasticsearch-5.6.2/logs #修改日志路径,路径要提前创建
bootstrap.memory_lock: false #设置 ES 节点允许内存交换
bootstrap.system_call_filter: false #禁用系统调用过滤器
network.host: linux #设置当前主机名称
discovery.zen.ping.unicast.hosts: ["linux"] #设置集群的主机列表
7)更改 vim ./config/jvm.options
-Xms512m
-Xmx512m
否则可能会虚拟机内存不够报错
Java HotSpot™ 64-Bit Server VM warning: INFO: os::commit_memory(0x00000000c5330000, 986513408, 0) failed; error=‘Cannot allocate memory’ (errno=12)
8)启动一定不能用root用户(创建新用户,赋予权限)
./bin/elasticsearch
